字节跳动开源云原生机器学习平台 Klever
Posted 火山引擎云原生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字节跳动开源云原生机器学习平台 Klever相关的知识,希望对你有一定的参考价值。
字节跳动基础架构团队基于火山引擎机器学习平台 Clever 及其丰富的行业落地经验,推出开源项目 Klever,以工程化的方式降低智能技术落地门槛,助力企业快速打造智能业务。
发布 | 火山引擎云原生
作者 | 陈军(字节跳动)
项目 | https://github.com/kleveross
近年来,智能技术不论是在学术界还是工业界都取得了突破性进展。机器学习、深度学习开始在各行各业扮演重要角色:业务上,帮助企业优化运营、提高效率、改善客户体验;管理上,参与后台自动化运营,完成数据处理和提取等任务。
然而,随着越来越多企业开始尝试落地智能技术,一个严峻的问题也逐渐暴露出来:从算法技术选型到模型最终上线,这个过程涉及大量工程化任务对接。
算法工程师们掌握着丰富的先进算法,但算法能力的实现通常离不开底层计算资源和系统架构的支撑,如何实现从开发、模型训练、模型管理、模型服务全链路高效、敏捷、自动化管理,进而实现企业的智能化转型,仍是当前智能技术领域亟待解决的问题之一。
针对上述问题,字节跳动基础架构团队多年来就智能技术的工程化问题进行了长期探索。
2020 年,字节跳动旗下的数字服务与智能科技品牌火山引擎携我们的技术实践落地国内某金融机构,使其模型上线效率提升了 10 倍,GPU 资源使用率提高 50%,自主创新能力大幅提高。
这类落地最佳实践让我们深刻认识到了智能技术对企业业务持续增长的重要性,也让我们了解到缺乏工程化工具已经成为当下企业应用智能技术的一大掣肘。为此,
我们决定推出开源机器学习平台 Klever
。
Klever 是一个支持 OCI(Open Container Initiative)标准存储训练模型、支持在线模型服务部署的云原生机器学习平台。算法科学家可以使用 Klever 进行
模型管理
、
模型解析
、
模型转换
、
模型服务
,它已经解决了智能技术落地流程中的如下问题:
同时,基于字节跳动在机器学习和云原生开源社区的技术积累,Klever 提供强大、通用的开源技术标准,方便企业无缝迁移线上应用。未来,它还将进一步支持模型开发、模型训练等一系列智能模型开发和管理流程,降低技术落地门槛,助力企业快速打造智能业务、全面实现智能化转型。
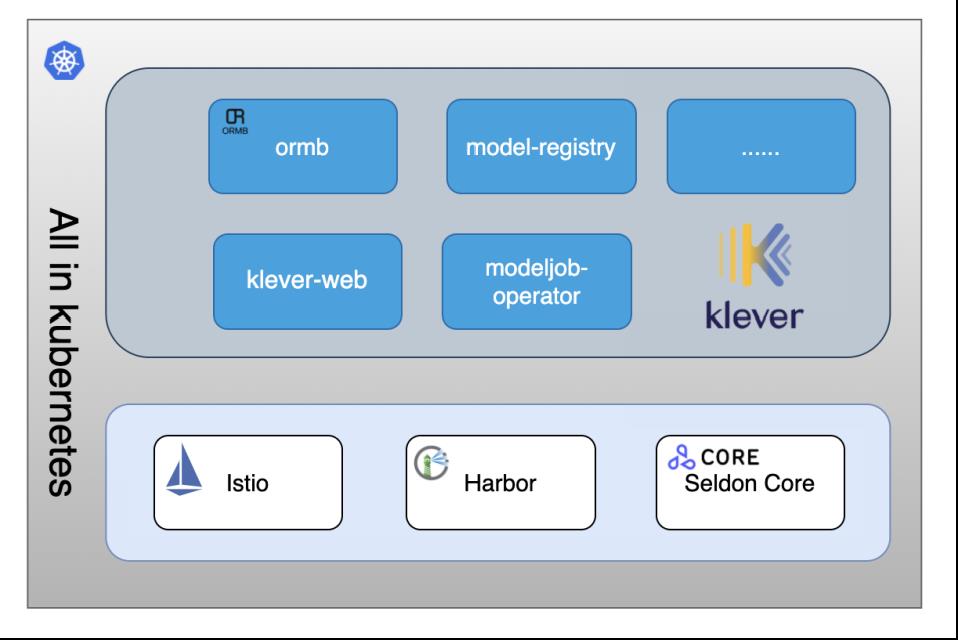
Klever 有四个自研发的组件,并依赖三个开源组件:
-
-
model-registry
:模型仓库及模型服务 API 管理层
-
modeljob-operator
:ModelJob controller,管理模型解析、模型转换任务
-
-
Istio
:开源服务网格组件,模型服务通过 Istio 对外暴露模型服务地址,实现模型服务按内容分流和按比例分流
-
Harbor
:模型底层存储组件,对模型配置和模型文件进行分层存储
-
Seldon Core
:开源模型服务管理的 Seldon Deployment CRD 的 controller,通过 SeldonDeployment CR 实现模型服务的管理
如前所述,目前机器学习平台 Klever 率先实现的是从模型仓库到模型服务的自动化管理,具体来说,它可以支持以下两种应用场景:
-
-
开发的模型在团队内外、公司内外通过 ormb + Harbor 进行管理和分发
-
用户如果有现成的模型文件,但是不知道如何构建模型服务,那么可通过将模型导入系统,一键部署模型服务
-
模型服务
-
支持简单模型服务和基于流量比例及内容分流的高级模型服务
-
-
首先,通过与 Harbor 结合,它可以满足 OCI 标准的模型仓库管理,用户可以像使用 Docker 管理镜像一样管理机器学习模型。
其次,整个系统可通过容器化的方式部署在 Kubernetes 容器管理平台之上,用户无需管理模型解析、模型转换、模型服务实际运行在哪台物理机之上,系统会自动调度和运行资源充足的机器,并在模型服务负载较高时自动弹性伸缩。
最后,由于机器学习在不同训练过程中往往使用不同的数据集,会产生不同的模型,Klever 支持多种模型服务运行时,可将产生的模型用于提供生产环境可用的在线服务。

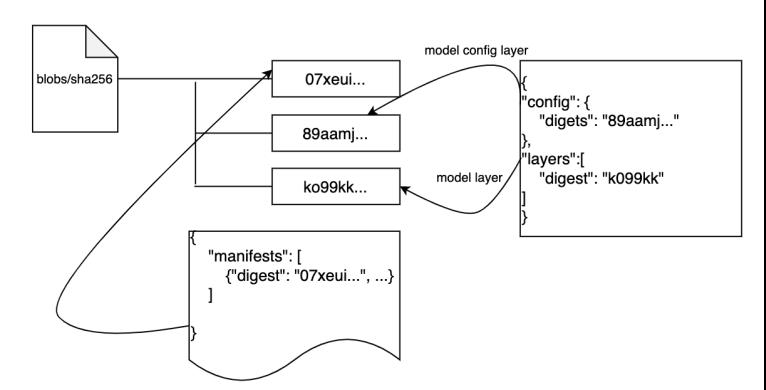
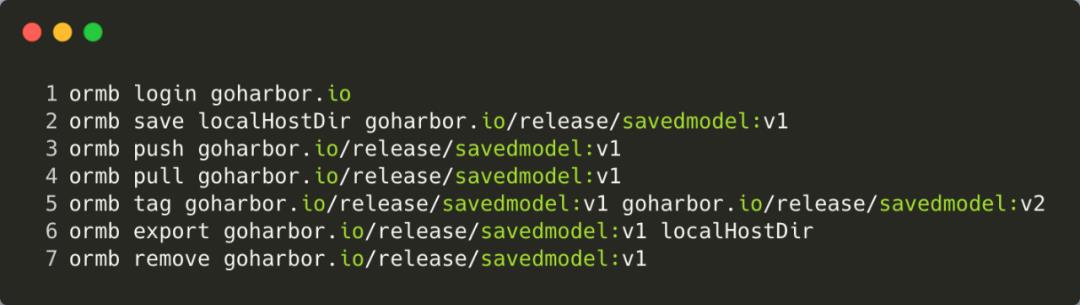
ORMB 是 Klever 下的一个命令行管理工具子项目,可以像 Docker 管理镜像一样管理模型。它支持 OCI 标准,可以对模型文件和模型属性进行分层存储管理。
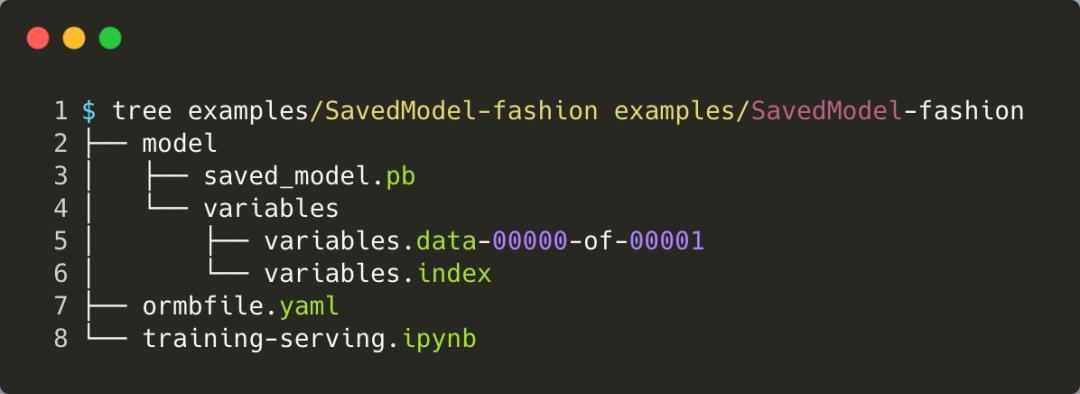
执行 ormb save 保存模型时,我们需要按照如下目录格式管理模型,其中 ormbfile.yaml 文件格式请参考 spec-v1alpha1.md
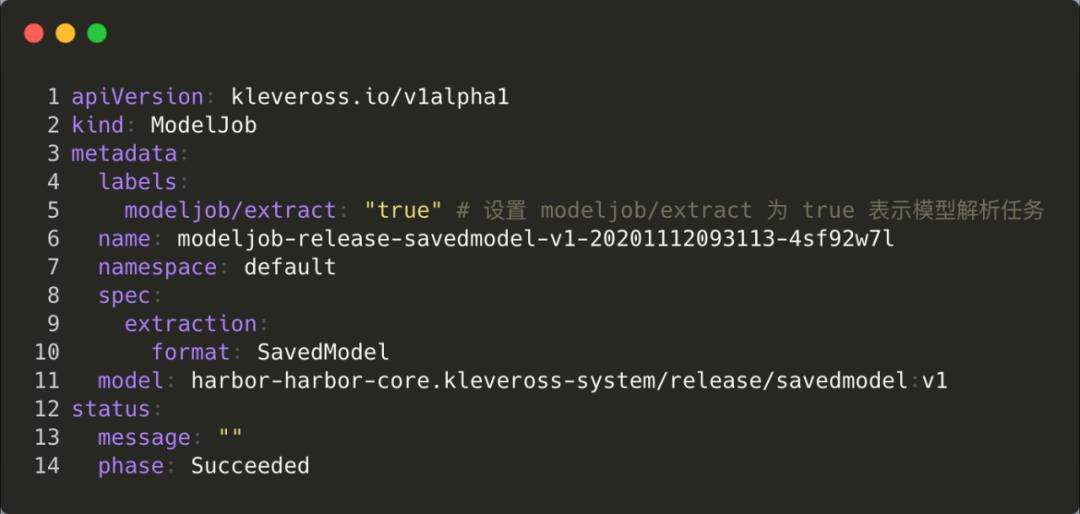
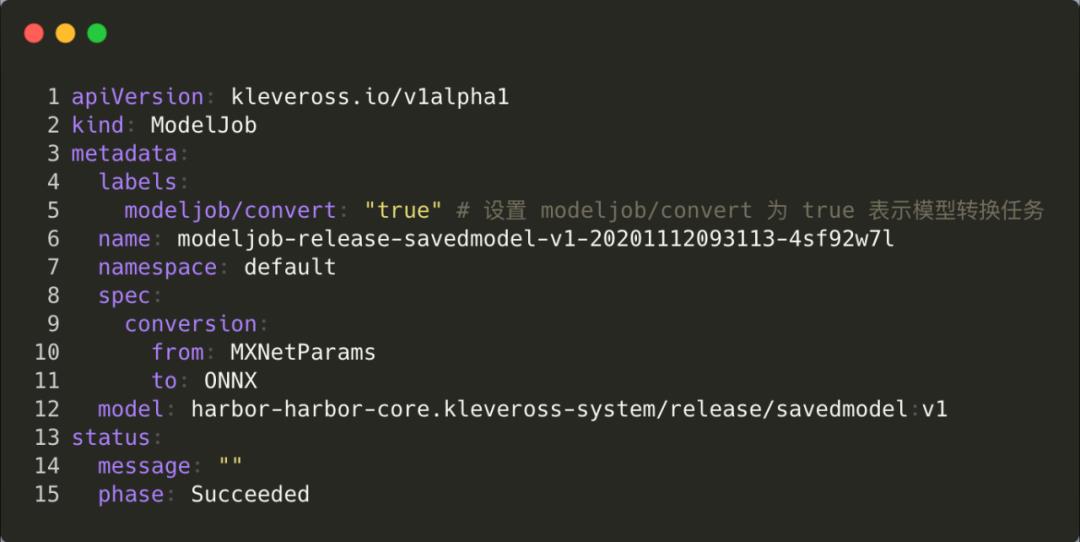
Klever 通过自动 ModelJob CR 进行模型解析和模型转换任务的管理,模型解析任务需要设置模型的格式及模型的 URI,模型转换任务则需要设置模型源模型格式、目标模型格式及模型 URI。
模型解析和转换的执行通过自定义脚本的方式实现,每种类型的模型解析和模型转换任务都有对应的脚本,脚本在 github.com/kleveross/klever-model-registry/tree/master/scripts 下集中管理。
解析内容主要包括 inputs、outputs、operators。任务通过 status 的 message 和 phase 字段可以返回给用户任务当前执行的状态,并在异常时返回异常信息。
模型解析和转换任务执行之前,需要将模型文件拉取到 Container 中并重新组织为模型服务器需要的目录格式,此过程通过扩展 ORMB 实现了一个 ormb-stororage-initializer 容器,该容器作为任务的 initContainer 存在,它将模型 pull & export 到 /mnt/input 目录下,模型解析和转换任务的容器和 initContainer 共享 /mnt/input 挂载点使用下载的模型。
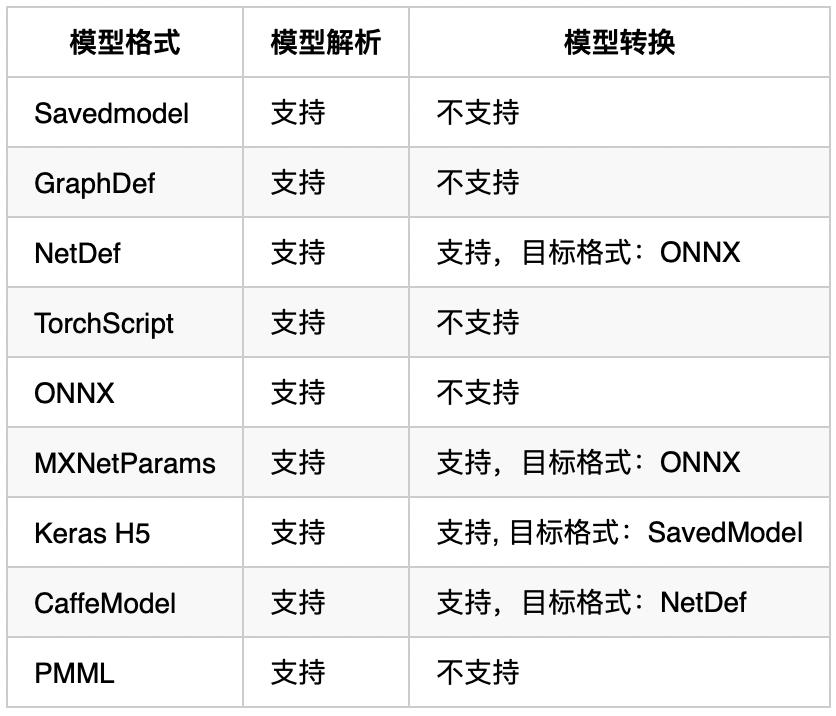
Klever 基于 Seldon-Core 实现模型服务,创建模型服务会首先创建一个Seldon Deployment,并在其Init Container中通过 ormb-storage-initializer 下载模型。
若模型为PMML格式,将使用 OpenScoring 镜像启动服务;若模型为其他 Triton Server 支持的模型格式,将使用 Triton Server 镜像启动服务.镜像中会自动通过ormbfile.yaml中的信息生成 Triton Server 所需要的 config.pbtxt 文件。
当前 Klever 已支持通过 Nvidia Triton Server 模型服务器部署深度学习模型服务,通过 OpenScoring 部署 PMML 格式的传统机器学习模型。我们还在完善对 Spark MLlib、MLFlow 及 XGBoost 模型服务器的支持,会在近期完成。
部署为模型服务之后,用户如何通过 API 接口进行模型服务的访问呢?对于 Nvidia Triton Server 渲染的模型服务,访问地址为:
对于 OpenScoring 渲染的模型服务,访问地址为:
其中,servingName 为模型服务的名称,在创建模型服务的时候需要指定该名称。
讲到这里,大家是否已经迫不及待地想安装和使用 Klever 了呢?Klever 提供一键部署安装的脚本,同时也支持详细的部署文档,你只需要有一个 Kubernetes 环境即可安装部署。

当前,在字节跳动内部,我们仍在基于各类实践完善云原生机器学习工程化平台的构建想法,丰富 Klever 的功能和内涵。在外部市场,火山引擎推出的商业化版机器学习平台 Clever 已在金融、制造、零售、能源等行业拥有成熟的解决方案,为各行业头部客户业务的持续增长提供赋能,也为 Klever 开源提供重要实战经验。
当前 Klever 仅支持模型文件及模型元数据的基本属性的存储和管理,以及支持在线模型服务的功能。但是 Klever 的使命远不止于此,未来它将完成从训练到模型、再到模型服务的全链路管理。
相关链接
https://github.com/kleveross/ormb
https://github.com/kleveross/klever-model-registry
https://github.com/kleveross/klever-web
https://github.com/istio/istio
https://github.com/goharbor/harbor
https://github.com/SeldonIO/seldon-core
火山引擎是字节跳动旗下的数字服务与智能科技品牌,基于公司服务数亿用户的大数据、人工智能和基础服务等能力,为企业客户提供系统化全链路解决方案,助力企业务实地创新,实现业务持续快速的增长。
以上是关于字节跳动开源云原生机器学习平台 Klever的主要内容,如果未能解决你的问题,请参考以下文章
揭秘字节跳动云原生Spark History 服务 UIService
cube开源一站式云原生机器学习平台-架构
内含福利|CSDN携手字节跳动:云原生Meetup北京站报名热烈启动,1月8日见!
内含福利|CSDN 携手字节跳动:云原生Meetup北京站报名热烈启动,1月8日见!
字节跳动推荐平台技术公开,项亮:底层架构有时比上层算法更重要
提速 10 倍!深度解读字节跳动新型云原生 Spark History Server