阿里分布式Dubbo架构
Posted JAVA烂猪皮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里分布式Dubbo架构相关的知识,希望对你有一定的参考价值。
一. Dubbo诞生背景
随着互联网的发展和网站规模的扩大,系统架构也从单点的垂直结构往分布式服务架构演进,如下图所示:
单一应用架构:一个应用部署所有功能,此时简化CRUD的ORM框架是关键
垂直应用架构:应用拆分为不相干的几个应用,前后端分离,此时用于加速前端页面开发的Web MVC框架是关键
分布式服务架构:抽取各垂直应用的核心业务作为独立服务,形成稳定的服务中心,此时用于提高业务复用及整合的分布式服务框架(RPC)是关键
流动计算架构:当服务越来越多,容量的评估、小服务资源的浪费等问题逐渐显现,此时用于提高机器利用率的实时资源调度和治理中心(SOA)是关键
当服务越来越多时,服务配置URL变的困难,F5硬件负载均衡的单点压力越来越大。此时需要服务注册中心,动态的注册和发现服务,使服务的位置透明。服务调用实现软负载均衡和Failover,降低对F5硬件负载均衡器的依赖
当服务间关系越来越复杂时,此时需要自动画出服务间的依赖关系图,来帮助架构师理清服务关系
当服务调用量越来越大时,服务需要多少台机器支撑,服务容量的问题就暴露出来了,此时需要统计服务每天的调用量、响应时间等性能指标作为容量规划的参考。其次,还可以动态调整权重,将某台机器权重一直加大,直到响应时间到阀值,按照此时的访问量反推服务的总容量
以上是Dubbo的基本需求,如下图所示:
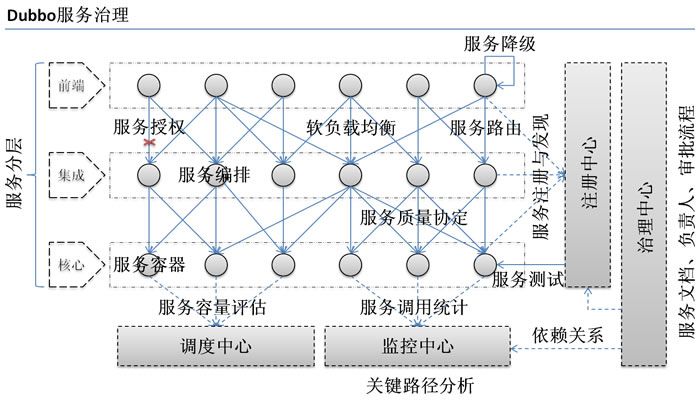
二. 整体架构
Dubbo的整体架构设计如图所示:
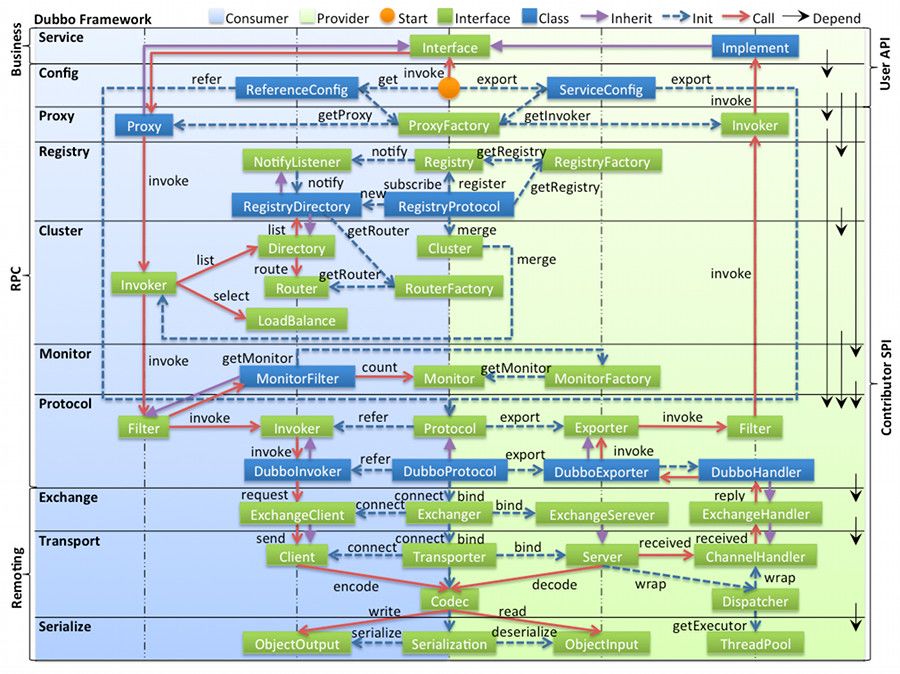
Dubbo框架一共分10层,各层单向依赖。最上面的 Service 和 Config 为API,其他均为 SPI。左边淡蓝色的为 consumer 使用的接口,右边淡绿色的为 provider 使用的接口,中间的为双方都用到的接口。
黑色箭头代表层之间的依赖关系;蓝色虚线为初始化过程,即启动时组装链;红色实线为方法调用过程;紫线为继承关系。线上的文字为调用的方法。
1、接口服务层(Service):该层与业务逻辑相关,根据 provider 和 consumer 的业务设计对应的接口和实现
2、配置层(Config):对外配置接口,以 ServiceConfig 和 ReferenceConfig 为中心
3、服务代理层(Proxy):服务接口透明代理,生成服务的客户端 Stub 和 服务端的 Skeleton,以 ServiceProxy 为中心,扩展接口为 ProxyFactory
5、路由层(Cluster):封装多个提供者的路由和负载均衡,并桥接注册中心,以Invoker 为中心,扩展接口为 Cluster、Directory、Router和LoadBlancce
6、监控层(Monitor):RPC调用次数和调用时间监控,以 Statistics 为中心,扩展接口为 MonitorFactory、Monitor和MonitorService
7、远程调用层(Protocal):封装 RPC 调用,以 Invocation 和 Result 为中心,扩展接口为 Protocal、Invoker和Exporter
8、信息交换层(Exchange):封装请求响应模式,同步转异步。以 Request 和 Response 为中心,扩展接口为 Exchanger、ExchangeChannel、ExchangeClient和ExchangeServer
9、网络传输层(Transport):抽象 mina 和 netty 为统一接口,以 Message 为中心,扩展接口为Channel、Transporter、Client、Server和Codec
10、数据序列化层(Serialize):可复用的一些工具,扩展接口为Serialization、 ObjectInput、ObjectOutput和ThreadPool
各层关系说明:
Portocol 是核心层,也就是只要有 Protocol + Invoker + Exporter 就可以完成非透明的 RPC 调用,然后在 Invoker 的主过程上 Filter 拦截点
Cluster 是外围概念,目的是将多个 Invoker 伪装为一个 Invoker,这样其它人只要关注 Protocol 层 Invoker 即可。只有一个 provider 时,是不需要 Cluster 的
Proxy 层封装了所有接口的透明化代理,而在其它层都以 Invoker 为中心,只有到了暴露给用户使用时,才用 Proxy 将 Invoker 转成接口,或将接口实现转成 Invoker,看起来像调本地服务一样调远程服务
Remoting 内部再划为 Transport 传输层和 Exchange 信息交换层:Transport 层只负责单向消息传输,是对 Mina, Netty, Grizzly 的抽象;而 Exchange 层是在传输层之上封装了 Request-Response 语义
Dubbo核心领域模型:
Protocol 是服务域,它是 Invoker 暴露和引用的主功能入口,它负责 Invoker 的生命周期管理
Invoker 是实体域,它是 Dubbo 的核心模型,其它模型都向它靠扰,或转换成它。它代表一个可执行体,可向它发起 invoke 调用,它有可能是一个本地的实现,也可能是一个远程的实现,也可能一个集群实现
Invocation 是会话域,它持有调用过程中的变量,比如方法名,参数等
Dubbo主要包括以下几个节点:
Provider:暴露服务的服务提供方
Consumer:调用远程服务的服务消费方
Registry:服务注册和发现的注册中心
Monitor:统计服务的调用次数和调用时间的监控中心
Container:服务运行容器
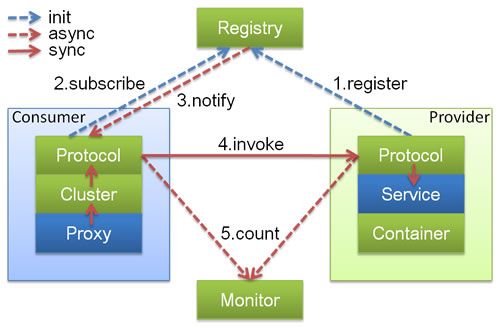
Consumer, Provider, Registry, Monitor代表逻辑部署节点。图中只包含 RPC 层,不包含 Remoting层,Remoting整体隐藏在 Protocol 中。
蓝色方框代表业务有交互,绿色方框代表只对Dubbo内部交互。蓝色虚线为初始化时调用,红色虚线为运行时异步调用,红色实线为运行时同步调用
0、服务在容器中启动,加载,运行Provider
1、Provider在启动时,向Registry注册自己提供的服务
2、Consumer在启动时,想Registry订阅自己所需的服务
5、Consumer和Provider,在内存中累计调用次数和时间,定时每分钟一次将统计数据发送到Monitor
将上面的服务调用流程展开,如下图所示:
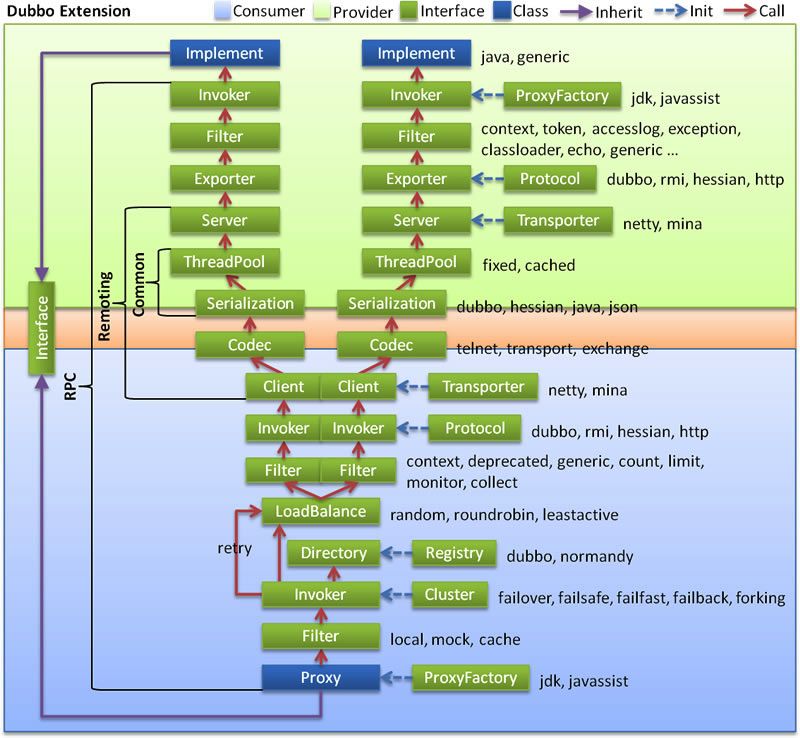
蓝色虚线为初始化过程,即启动时组装链;红色实线为方法调用过程,即运行时调用链;紫色实线为继承
三、实现细节
Invoker 是 Dubbo 领域模型中非常重要的一个概念,很多设计思路都是向它靠拢,这就使得 Invoker 渗透在整个实现代码里。下面用一个精简的图来说明最重要的两种 Invoker:服务提供 Invoker 和服务消费 Invoker:
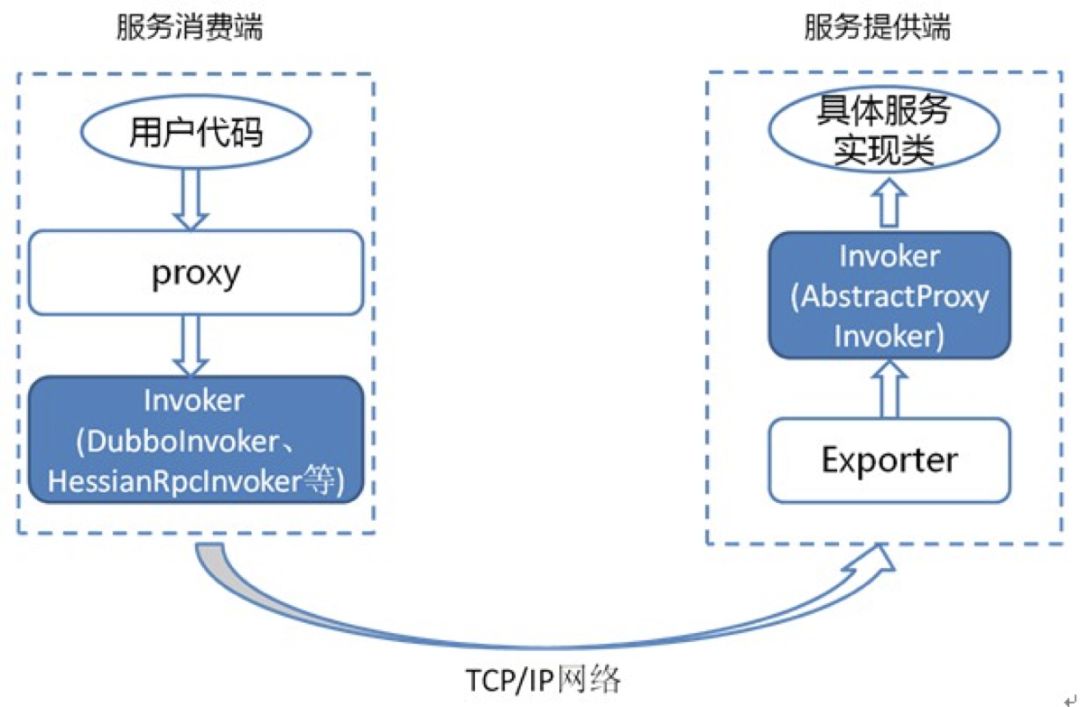
① 定义服务接口:

② 服务提供者代码:

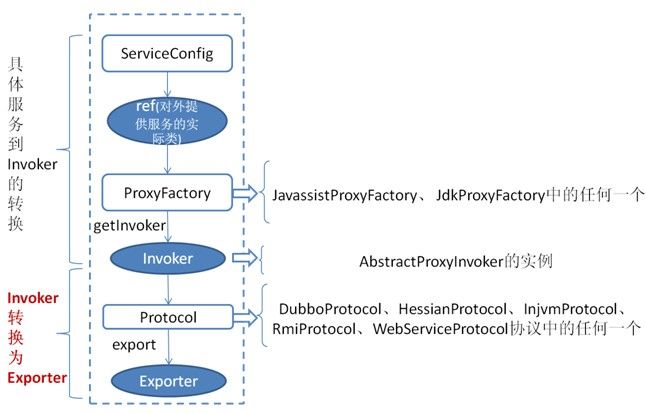
ServiceConfig 类拿到对外提供服务的实际类 ref(如:DemoServiceImpl)通过 ProxyFactory.getInvoker 方法使用 ref 生成一个 AbstractProxyInvoker 实例,然后 通过 Protocol.export 方法新生成一个 Exporter 实例
当网络通讯层收到一个请求后,会找到对应的 Exporter 实例,并调用它所对应的 AbstractProxyInvoker 实例,从而真正调用了服务提供者的代码
③ 服务消费者代码:

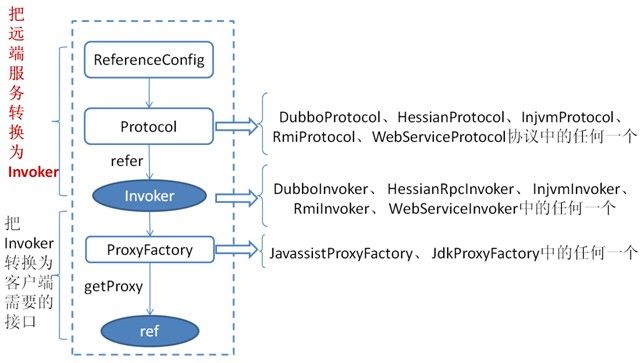
首先通过 ReferenceConfig.init 方法调用 Protocal.refer 方法生成 Invoker 实例,接下来通过 ProxyFactory.getProxy 方法将 Invoker 转换为客户端需要的接口(如:DemoService)
DemoService 就是 consumer 端的 proxy,用户代码通过这个 proxy 调用其对应的 Invoker,通过 Invoker 实现真正的远程调用
四. 功能特性
1. 配置
Dubbo可以采用全Spring的配置方式,基于Spring的Schema扩展进行加载,接入对业务透明,无API侵入。配置项可参考:schema 配置参考手册
除了Spring配置,也可以使用API配置、属性配置和注解配置方式。
配置之间的关系,如下图所示:
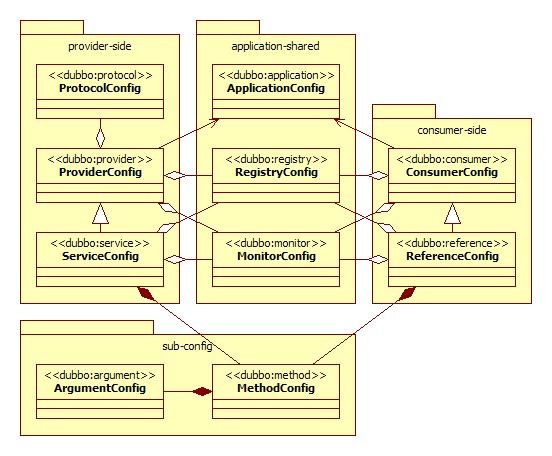
provider side:
<dubbo:protocol/>:协议配置。用于配置提供服务的协议信息,协议由provider指定,consumer被动接受<dubbo:service/>: 服务配置。暴露一个service,定义service的元信息,一个service可以用多个协议暴露,也可以注册到多个注册中心<dubbo:provider/>:提供方配置【可选】。当 ProtocolConfig 和 ServiceConfig 某属性没有配置时,采用此缺省值
consumer side:
<dubbo:reference/>:引用配置。用于创建一个远程服务代理,一个引用可以指向多个注册中心<dubbo:consumer/>:消费方配置【可选】。当 ReferenceConfig 某属性没有配置时,采用此缺省值
application shared:
<dubbo:application/>:应用配置。配置应用信息,包括provider和consumer<dubbo:registry/>:注册中心配置。配置连接注册中心相关信息<dubbo:monitor/>:监控中心配置【可选】。配置连接监控中心相关信息
sub-config:
<dubbo:method/>:方法配置。用于 ServiceConfig 和 ReferenceConfig 指定方法级的配置信息<dubbo:argument/>:参数配置。用于指定方法参数配置
2. 集群容错
服务调用时的过程如下图:
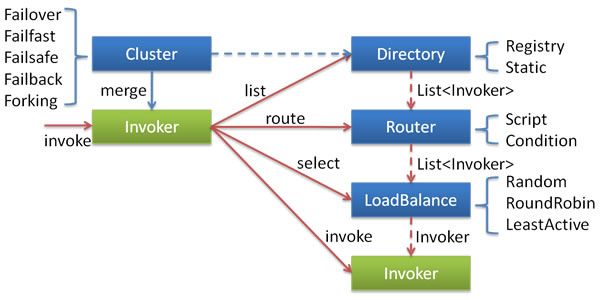
Directory:代表多个Invoker,可将它看为List<Invoker>,它的值是动态变化的,比如注册中心推送变更
Cluster:将Directory的多个Invoker伪装为一个Invoker,对上层透明。伪装过程中包括容错逻辑,例如:一个Invoker调用失败后重试另一个Invoker
Router:从多个Invoker中按路由规则选出子集,例如:读写分离、应用隔离等
LoadBlance:从多个Invoker中选出具体的一个Invoker用于本次调用,选的过程包括负载均衡算法,调用失败后需要重选
当Cluster集群调用失败时,Dubbo提供了多种容错方案:
Failover【默认】:失败时自动切换,重试其它服务器。通常用于读操作,可通过 retries="2" 来设置重试次数(不含第一次)
Failfast:快速失败,只调用一次,失败立即报错。通常用于非幂等的写操作,比如:新增记录
Failsafe:失败安全,失败时直接忽略。通常用于写入审计日志等操作
Failback:失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知等操作
Forking:并行调用多个服务器,只要一个成功即返回。通常用于实时性较高的读操作,但浪费更多服务资源。可通过 forks="2" 设置最大并行数
Broadcast:广播调用者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新本地资源信息,如缓存、日志等
3. 路由规则
路由规则决定一次dubbo服务调用的目标服务器,分为脚本路由规则和条件路由规则,支持可扩展。向注册中心写入路由规则的操作通常由治理中心的页面完成
脚本路由规则:支持JDK脚本引擎的所有脚本,例如:javascript, groovy 等
4. 负载均衡
如上图 LoadBlance 模块所示:在集群负载均衡时,Dubbo提供了不同的策略:
Random【默认】:随机,按权重设置随机概率。调用量越大越均匀,有利于动态调整权重
RoundRobin:轮询,按公约后的权限设置轮询比率。如果有台机器很慢,但没挂,当请求到那一台时就卡在那儿,久而久之,所有请求都卡在那台机器上
LeastActive:最少活跃调用数,活跃数指调用前后计数差,越慢的provider的调用前后计数差越大,使得慢的provider收到更少请求
ConsistentHash:一致性Hash,相同参数的请求发往同一台provider,当一台provider挂掉时,原本发往该机器的请求,基于虚拟节点会平摊到其他机器,不会引起剧烈变动
5. 线程派发模型
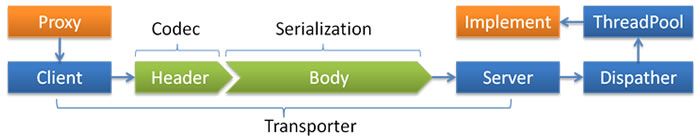
如果事件处理的逻辑能迅速完成,并且不发生新的IO请求(例如在内存中记个标识),则在IO线程上处理更快,因为减少了线程池调度
如果事件处理的逻辑较慢,或需要发起新的IO请求(例如需要查询数据库),则必须派发到线程池,否则 IO 线程阻塞,将导致不能接受其他请求
因此需要不同的派发策略和不同的线程池组合来应对不同的场景:
Dispatcher:
all:所有消息派发到 ThreadPool,包括请求、响应、连接事件、断开事件、心跳等
direct:所有消息不派发 ThreadPool,全在 IO 线程上执行
message:只有请求响应消息派发到 ThreadPool,其他连接事件、断开事件、心跳等,在 IO 线程上执行
execution:只请求消息派发到 ThreadPool,其他事件包括响应事件、连接断开事件、心跳等消息,在 IO 线程上执行
connection:在 IO 线程上,将连接断开事件放入队列,有序逐个执行,其他时间派发到 ThreadPool
ThreadPool:
fixed【默认】:固定大小线程池,启动时建立线程,一直持有不关闭
cached:缓存线程池,空闲一分钟自动删除,需要时重建
limited:可伸缩线程池,线程数只增长不收缩,目的是为了避免收缩时大流量引起的性能问题
eager:优先创建Worker线程池,corePoolSize < 任务数量 < maximumPoolSize时,优先创建 Worker 处理任务。任务数量 > maximumPoolSize时,任务放入阻塞队列中,阻塞队列充满时抛出 RejectExecutionException
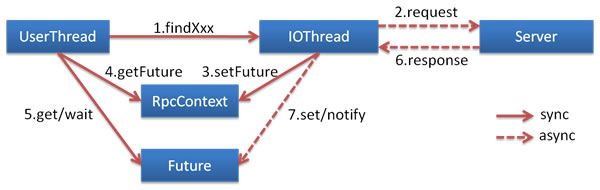
6. 上下文信息和隐式参数
上下文中存放着当前调用过程中所需的环境信息。RpcContext 是一个 ThreadLocal 的临时状态记录器,当接收或发起 RPC 请求时,RpcContext 都会发生变化。比如:A调用B,B调用C,在B调C之前,B机器上 RpcContext 记录的是A调用B的信息。
通过 RpcContext 的 setAttachment 和 getAttachment 可以在 provider 和 consumer 之间进行参数的隐式传递

7. 异步调用
基于NIO的非阻塞实现并行调用,客户端不需要启动多线程即可完成多个远程服务的并行调用,相对比多线程开销较小
8. 注册中心
对于 provider,它需要发布服务,而且由于应用系统的复杂性,服务的数量、类型也不断膨胀;对于 consumer,它最关心如何获取到它所需要的服务,而面对复杂的应用系统,需要管理大量的服务调用
服务注册中心通过特性协议将服务统一管理起来,有效的优化内部应用对服务发布/使用的流程。Dubbo提供的注册中心有如下几种类型可供选择:
① ZooKeeper注册中心
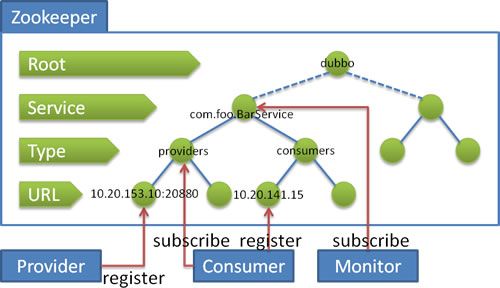
ZK是一个树形的服务目录,支持变更推送,适合作为Dubbo服务的注册中心。流程如下:
当 provider 出现断电等异常停机时,注册中心能自动删除 provider 信息。当注册中心重启、或会话过期时,能自动恢复注册数据和订阅请求
② Multicase注册中心
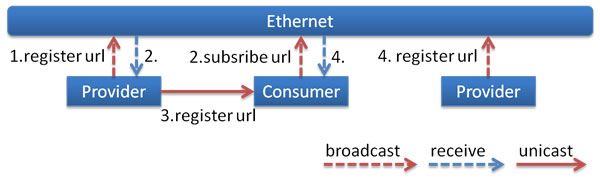
consumer 启动时广播订阅请求
组播受网络结构限制,只适合小规模应用或开发阶段
③ Redis注册中心

使用 redis 的 Key/Map 结构存储数据结构:
主 Key 为服务名和类型
Map 中的 Value 为过期时间,用于判断脏数据,脏数据由监控中心删除
调用过程:
并向 Channel:/dubbo/com.foo.BarService/providers 发送 register 事件
并从 Channel:/dubbo/com.foo.BarService/providers 订阅 register 和 unregister 事件
服务监控中心启动时,从 Channel:/dubbo/* 订阅 register 和 unregister,以及 subscribe 和 unsubscribe 事件
在此谢谢大家的关注支持~~~~
以上是关于阿里分布式Dubbo架构的主要内容,如果未能解决你的问题,请参考以下文章
阿里P8架构师谈:Dubbo的详细介绍设计思路以及4大适用场景