dubbo源码-客户端调用-地址选取
Posted 小鱼堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了dubbo源码-客户端调用-地址选取相关的知识,希望对你有一定的参考价值。
简介
ReferenceConfig创建出invoker被包装进代理对象后,就可以对服务端发起调用了。
真正调用是这个inovker对象的invoker方法。主要用处是在服务器列表中选择一个发起远程调用。
本文讨论他的选取过程。
涉及对象
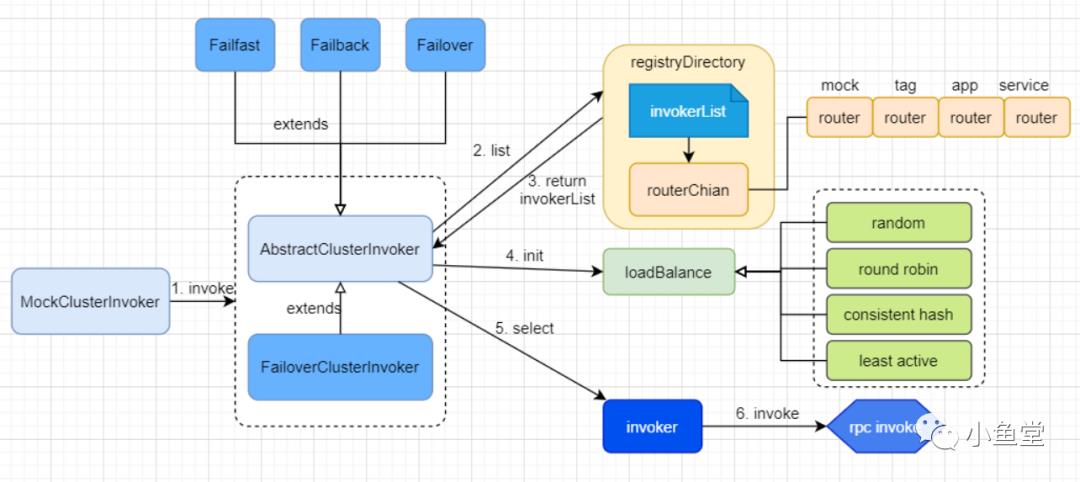
MockClusterInvoker 入口Invoker对象
RegistryDirectory 存放服务器列表 invokerList
Router接口 路由RegistryDirectory中的invokerList,过滤符合提交的invokerList
LoadBalance接口 负载均衡器,用于在一堆invokerList中按一定规则选取一个invoker。不同的实现有不同的选取规则
FailoverClusterInvoker 默认的ClusterInvoker。失败重试Invoker。在发起调用失败后执行重试策略。和他类似的有Failback, Failfast等等,实现了不同的执行策略。
调用过程
MockClusterInvoker
代理类的inovker是MockClusterInvoker。()最后的对象图如下
MockClusterInvoker内部的invoker对象默认是FailoverClusterInvoker。我们从MockClusterInvoker的invoker方法入手。
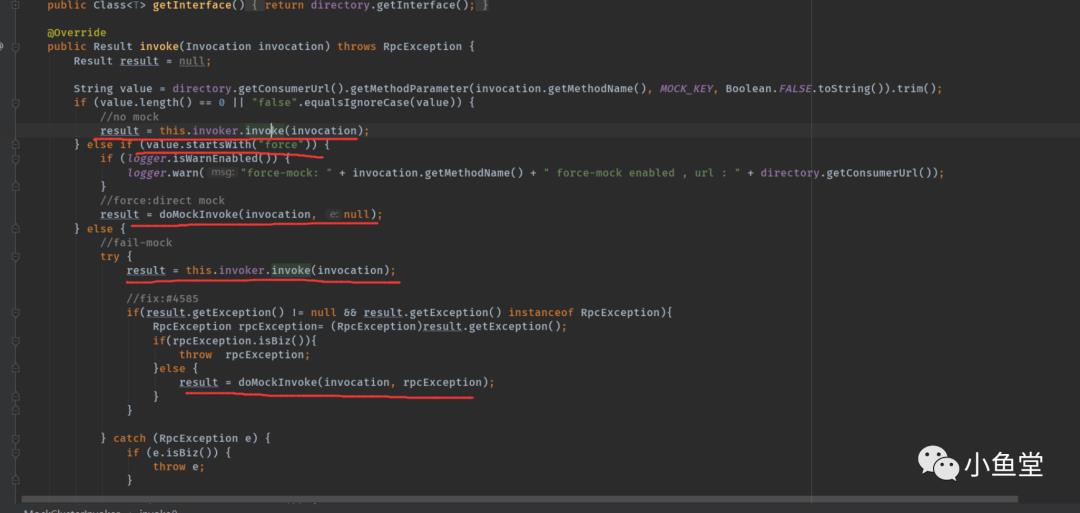
入参invocation是调用的上下文。包括接口名,参数类型,参数值等调用相关的数据。会在整个调用过程中一直向下传递
MockClusterInvoker主要实现的就是mock功能。主线业务逻辑传递给他自己属性invoker(FailoverClusterInvoker)的invoker方法。
如果配置了mock的方式,会使用mock的结果。方便开发调试场景。或者是先调用业务方法,异常了再用mock。
AbstractClusterInvoker
FailoverClusterInvoker继承AbstractClusterInvoker。作用是在一堆Invoker中,怎样找出合适的invoker以怎样的方式去执行。
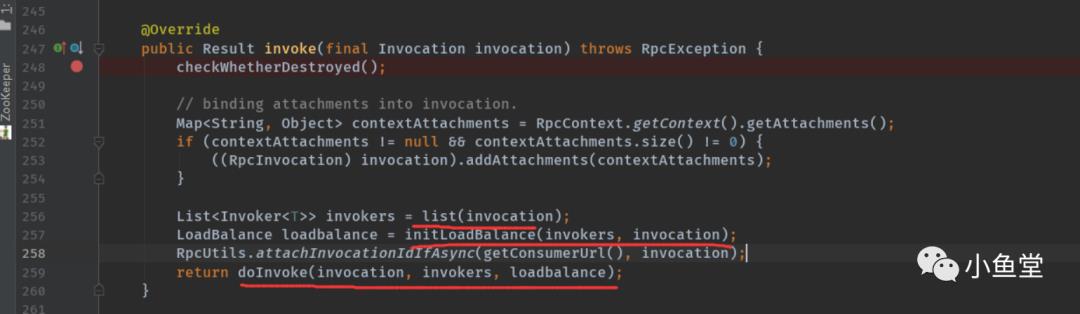
list获取到可以执行的invokers列表。这个invokers就是指向每台服务提供者的机器
初始化一个负载均衡器。
调用子类的doInvoke。传入可用的invokers列表和负载均衡器,选择invoker并调用
list

list方法是调用directory.list。
这个directory是XXX里面讲RegistryDirectory说的另一个核心方法。获取可用的invokersList。
RegistryDirectory里存放了所有的invokersList。且有一个路由链routerChain属性。通过routerChain.route的过滤,返回符合条件的invokersList。
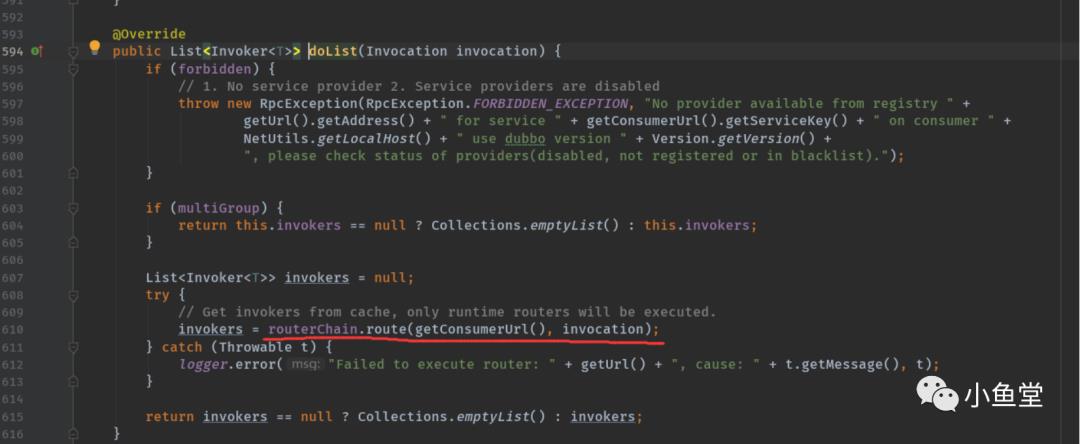
routerChain默认有mock, tag, app, service4个,通过SPI的@Activate创建出来()。
另外routerChain也会随着RegistryDirectory监听zk的router节点上的url而更新,动态添加新的路由过滤逻辑。
loadBalance
负载均衡包括以下几个实现

默认使用随机random。当然也可以配置成其他的方式。有兴趣的可以看看实现方法。并不是简单粗暴的随机值或者取模。
doInvoker
doInvoker交給子类实现。包括出错了要怎样处理,要调用几次,结果怎么处理。(因为一个调用同一个RPC服务,这些服务会有多台机器)。
虽然doInvoker由子类实现,但子类主要处理不同场景下失败调用,或者对结果特殊处理等逻辑。核心选择invoker的逻辑(select)还是在父类AbstractClusterInvoker中实现。
默认实现是FailoverClusterInvoker。
和FailoverClusterInvoker平级,也继承了AbstractClusterInvoker的还有AvailableClusterInvoker,BroadcastClusterInvoker,FailbackClusterInvoker,FailfastClusterInvoker,FailoverClusterInvoker,MergeableClusterInvoker
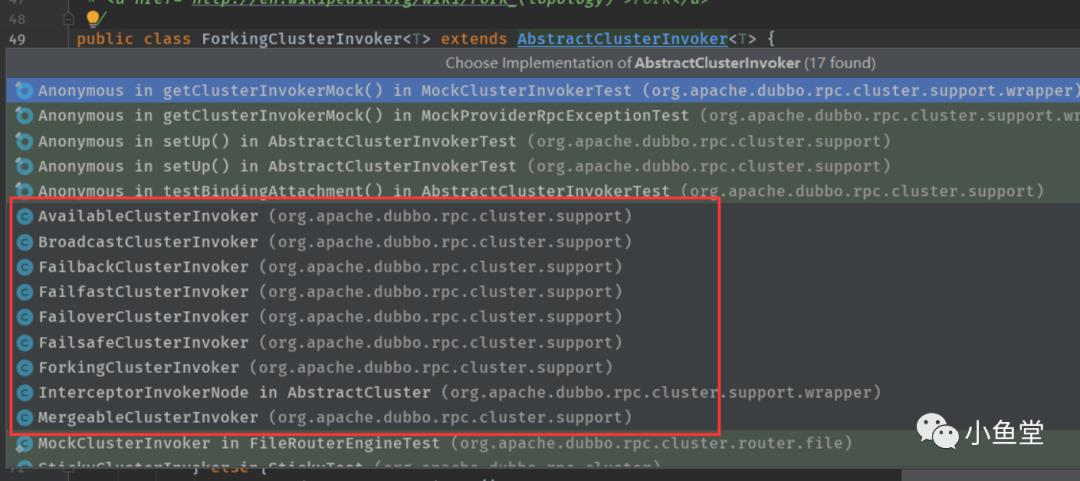
他们的功能可以总结如下:
FailfastCluster 快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
FailoverCluster 失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。可通过 retries="2" 来设置重试次数(不含第一次)
FailbackCluster 失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
FailsafeCluster 失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
BroadcastCluster 广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
ForkingCluster 并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks="2" 来设置最大并行数。
AvailableCluster 遍历所有的,只要一个有为true直接调用返回,否则就抛出异常
默认使用的是FailoverCluster。其实应该根据具体的业务场景,来配置不同的策略。
比如默认FailoverCluster是会重试的,在一些对性能要求高的地方,不想多次调用,只想一次拿到结果的场景,就不应该配置FailoverCluster,而是FailfastCluster 。
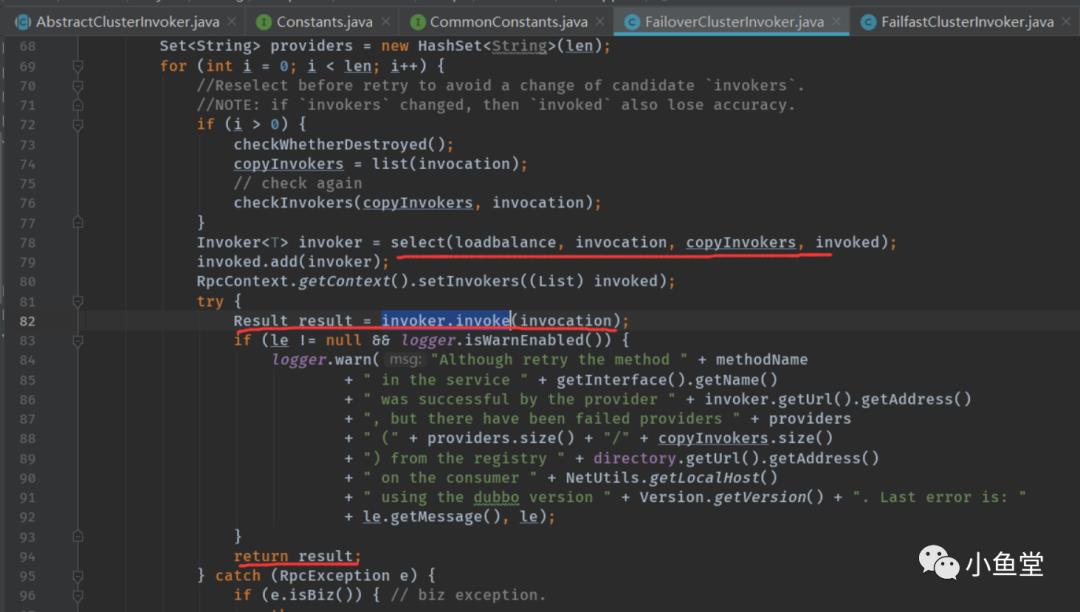
FailoverClusterInvoker
核心作用在于调用失败后会发起重试。
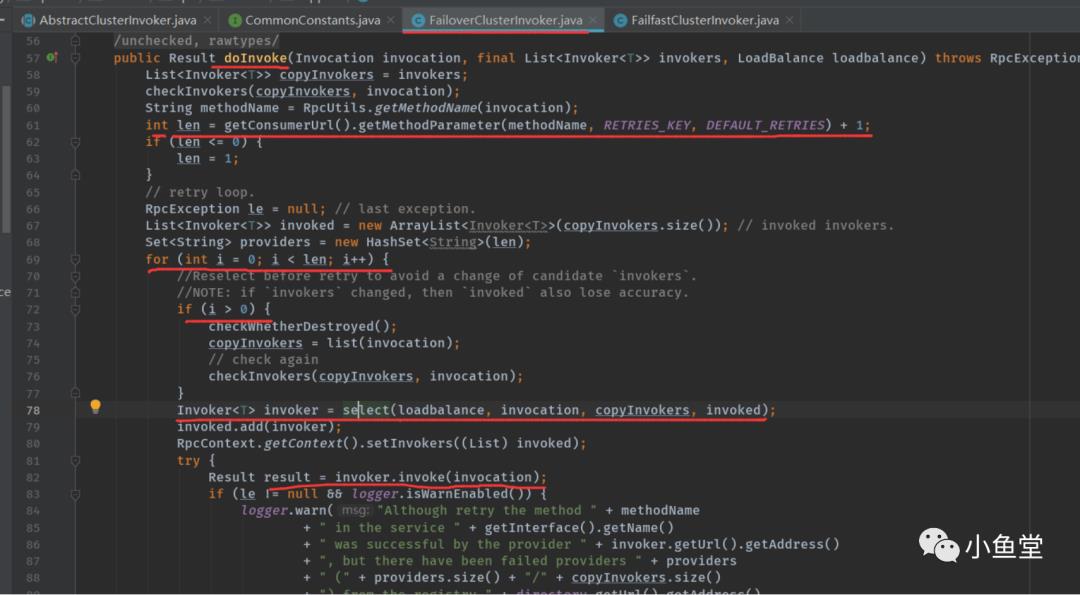
len 失败重试次数。默认2 + 1次。如果不成功,默认一共会调用3次。
select 通过负载均衡器,可用invokerList,已选择过的invokerList 三者的配合,来选取一个可执行的invoker
select
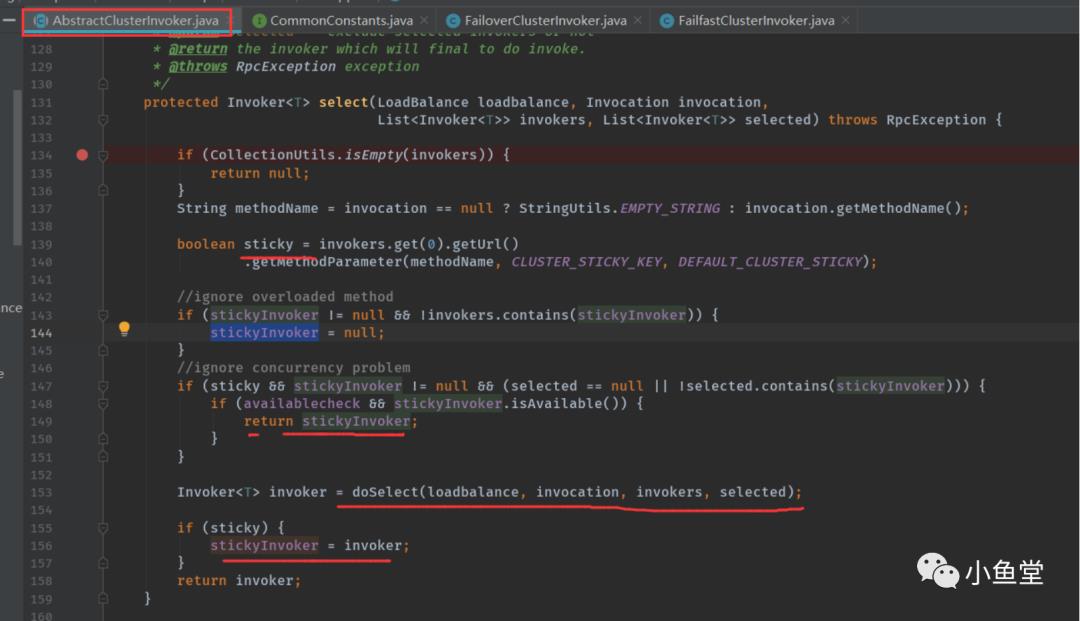
如果设置了sticky调用,这一直会使用选中的同一个invoker。方便在众多服务器中固定一个服务提供者。开发调试的时候方便指定固定机器。
真正的选择由doSelect实现。
doSelect
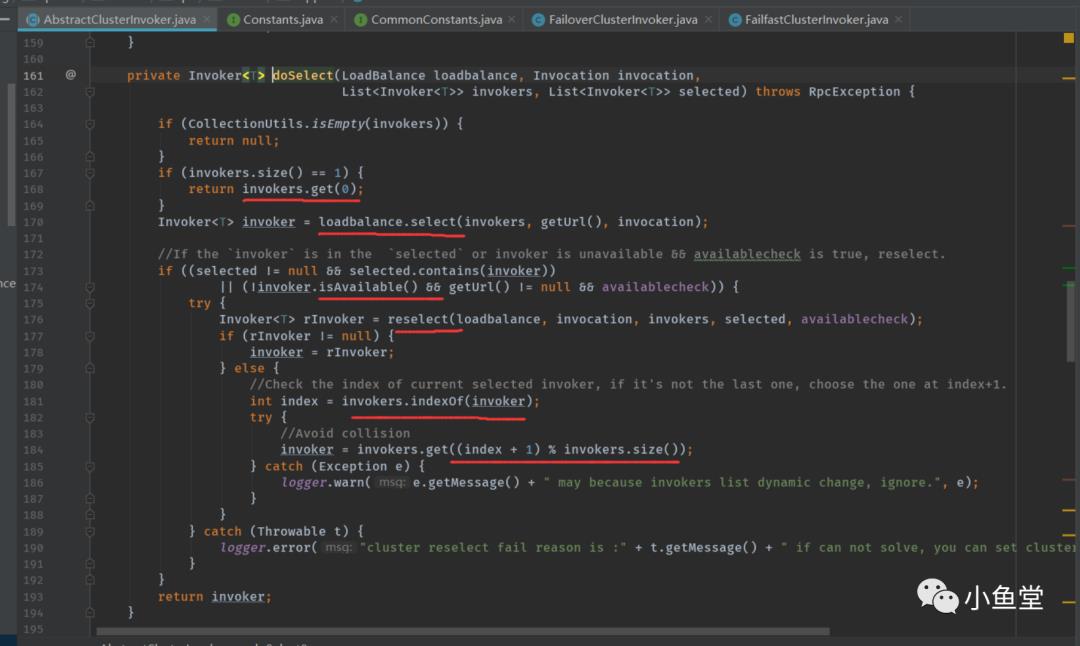
如果可选的只有一个,就直接返回
否则使用负载均衡器loadbalance(默认是random)进行选择。
选择出来的invoker如果已经被调用过,或者已经不可用,则会重新选择reselect。
注意:已经被调用过是指本次调用中被选择调用过的invoker,客户端业务bean多次请求的invoker是不相通的。比如FailoverCluster在一次调用中会发起重试,那么就会记录已经调用过的invoker。但是FailfastCluster只执行一次,所以这个已经被调用过的list对FailfastCluster就毫无意义。FailfastCluster的代码实现中selected为null。
如果重新选择的还是有问题,则会选择刚才被负载均衡器loadbalance选择的invoker的下一个。
reselect
基本也是按规则从可选的invokerList和已选的list中找一个可用的invoker。
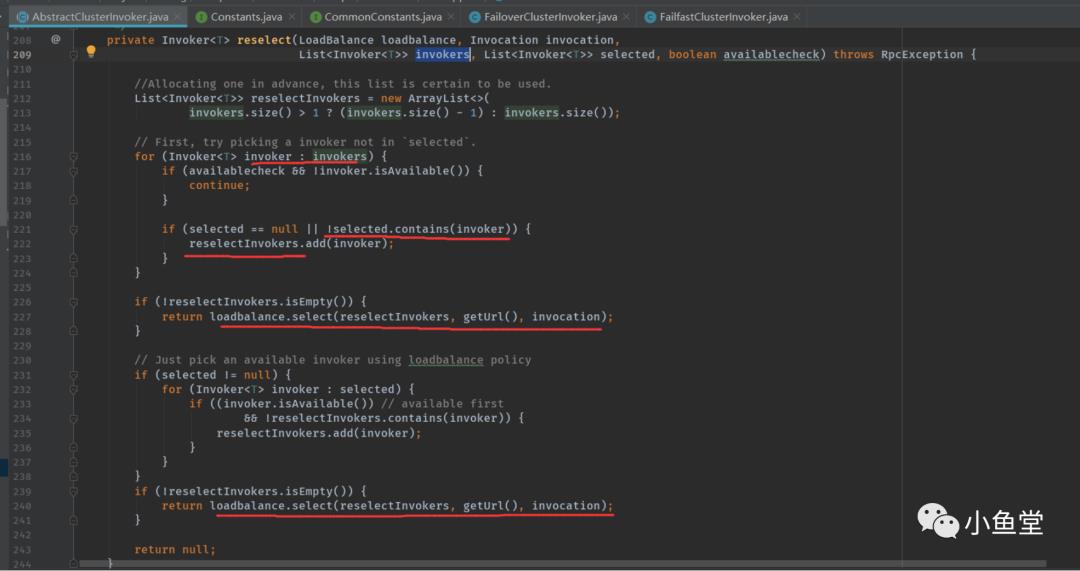
先从不在已选list的列表中选取invoker
如果没有,则从已选的list中获取invoker
获取的逻辑都通过负载均衡器loadbalance进行选择。
选取出invoker后,调用invoker.invoke发起远程调用
FailfastClusterInvoker
上面说的所有select的逻辑,全部在父类AbstractClusterInvoker中实现。
也就说其他子类只负责调用策略,或者处理失败的问题。
比如FailfastCluster:
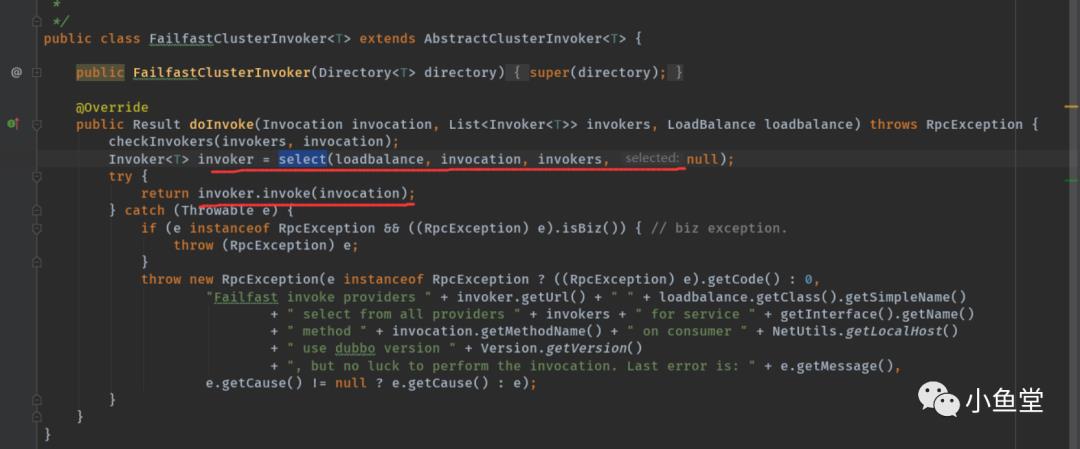
选择一个invoker后,直接调用。出错了直接抛出异常。(好像这才是更直接的调用方式)
他和FailoverCluster就在于对调用失败上的,FailoverCluster有重试的机制。
invoker
选取的invoker是被各种wrapper包装的dubboInvoker对象,由他通过netty发送远程通信,调用服务端的接口。(netty被包这么深)下期我们再讨论咯。
整体流程如下:
RandomLoadBalance
随机负载均衡器的选取策略并非完全平等随机,而是加入了权重。可以配置服务端每台机器不同的权重来分配随机的概率。
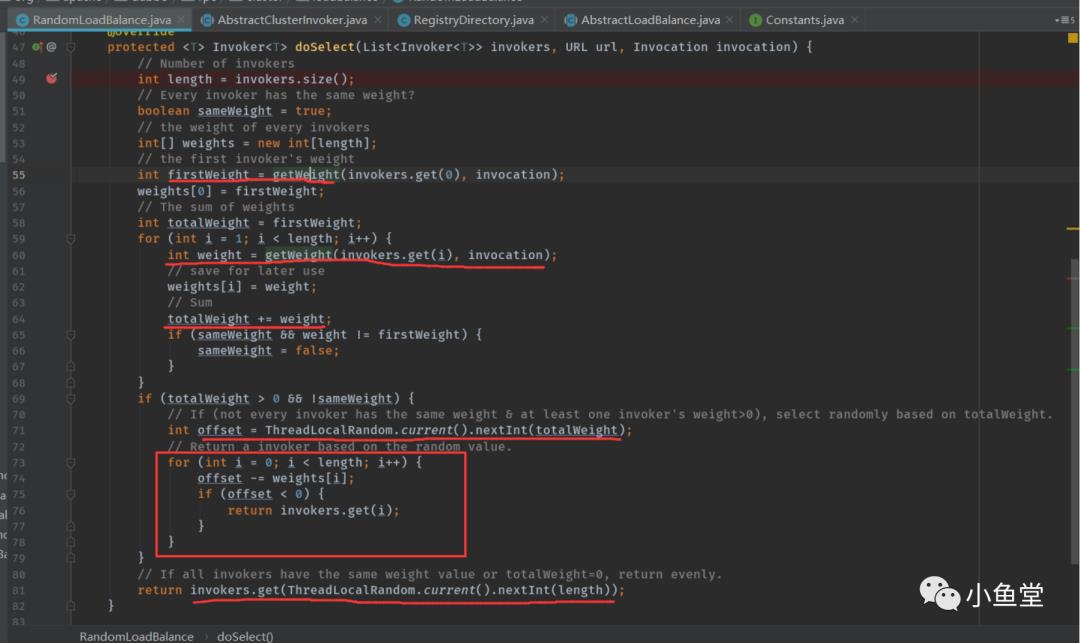
整体逻辑
先获取各个invoker的权重weight。如果权重都相同,则直接按list长度进行随机。(最后一行代码)
如果invoker的权重不同,计算出总权重值。按总权重随机一个值,看这个值在哪个invoker的区间,就选那个invoker。
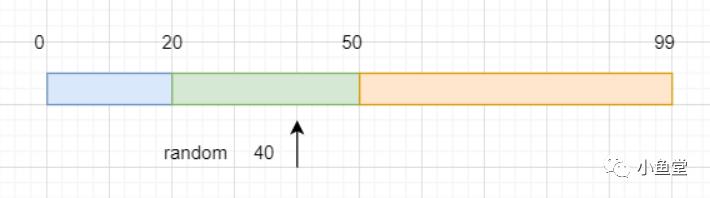
比如:3个权重是[20, 30, 50],则总权重是100。nextInt(totalWeight)出一个100以内的随机数。看这个数在0-100被20, 30, 50 拆分的哪个区间(0, 20), (21, 50), (51, 99)。(代码中红框的部分)
权重获取
获取每台服务器的权重除了配置以外,还配合了启动时间的预热机制。
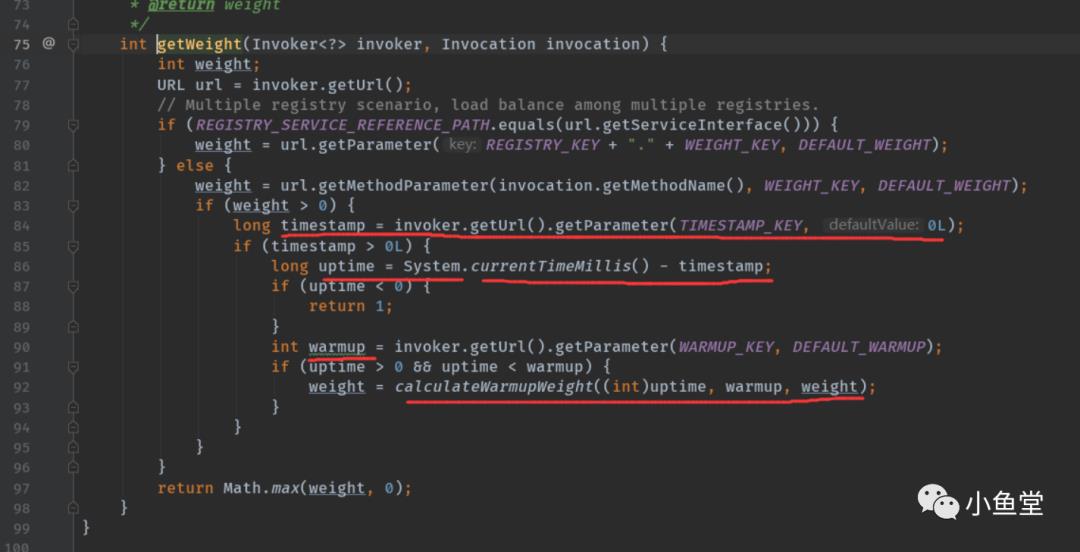
warmup默认是10分钟。
timestamp是服务器服务提供的时间。uptime算出这台服务已经启动多久了。
如果小于warmup,则会按启动时间的比例将weight打折。
比如:某台服务器只启动了5分钟,这时候就他的权重就会按50%参与random计算。
权重随机是一种纯算法,和dubbo没有必然联系。需要用随机算法的时候可以借鉴。同样也可以借鉴dubbo中实现的轮询,一致性hash,最小活跃等算法。这些算法的详细过程以后再讨论咯。
总结
ClusterInvoker会在registryDirectory的invokerList中选取一个执行器来发起远程调用
选取的逻辑由路由器routerChain,负载均衡器LoadBalance来控制
执行策略有各种失败情况处理FailXxx,有可执行即调用的AvailableClusterInvoker等等
觉得不错,订阅关注吧
以上是关于dubbo源码-客户端调用-地址选取的主要内容,如果未能解决你的问题,请参考以下文章