读源码-dubbo-奇技淫巧-HashedWheelTimer
Posted 小鱼堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读源码-dubbo-奇技淫巧-HashedWheelTimer相关的知识,希望对你有一定的参考价值。
简介
dubbo中有很多地方使用到了延时任务,比如注册失败后重试,连接失败后重连等等。作用是提交一个任务在给定的时间后执行。HashedWheelTimer正好满足这种要求。
HashedWheelTimer,包括相关的Timer, Timertask, Timeout接口其实都是netty的类。dubbo移植了过来,做了微小的改动。比如把mpscQueue改成了LinkedBlockQueue。但核心原理和使用功能没有太多变化。避免重复造轮子。
现在用dubbo的HashedWheelTimer来做以下几方面的分析
基本用法
结构原理
dubbo实战
基本用法
通过往timer里放入一个timerTask并设置延时时间,在延时时间达到后即可触发timerTask的run方法执行逻辑。

向timer放入一个task后,会返回一个timeout对象。timeout在对应的task执行的时候,会将其重新传到task中,类似一个上下文传递。可以看到主线程的timeout和子线程run task的timeout是同一个。
原理
接口关系
timer涉及3个核心的接口,关系如下
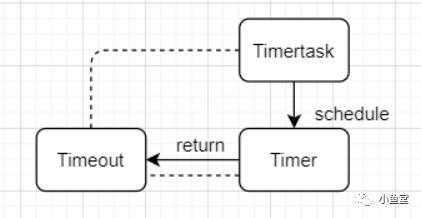
timer是执行器,负责接收执行任务
timertask是任务,是具体要执行的业务逻辑。需要实现run方法
每个timertask提交到timer后,会返回一个timeout对象。timeout会存放timer和对象timertask作为一个数据上下文的承载。
HashedWheelTimer实现
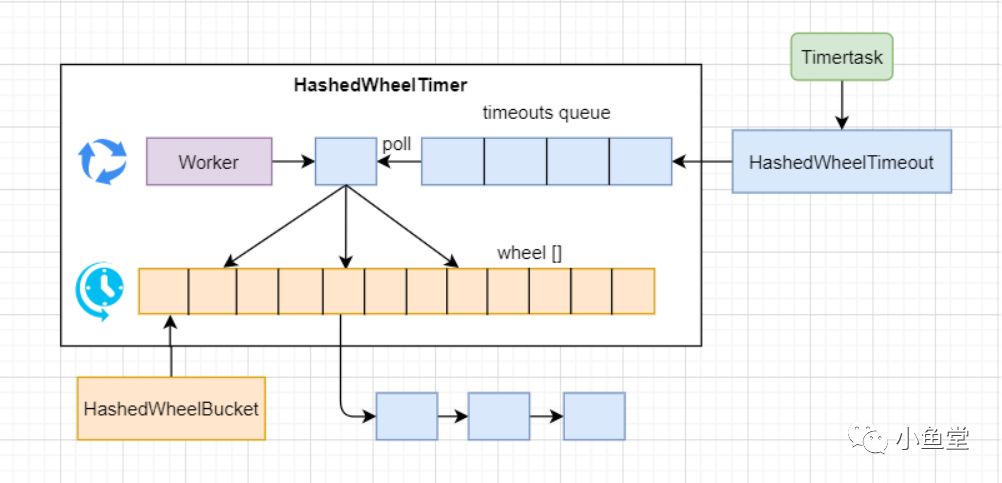
定义好了接口,来看具体的实现
HashedWheelTimer实现Timer接口,HashedWheelTimeout实现Timeout接口。
timetask提交到HashedWheelTimer。先用HashedWheelTimeout包装提交的timetask,将HashedWheelTimeout存放到HashedWheelTimer的一个队列中。
HashedWheelTimer的结构
一个timeouts queue用来接受提交过来的HashedWheelTimeout。HashedWheelTimeout中包含提交的timetask对象。
一个HashedWheelBucket数组组成一个环形的时间轮(本质是一个数组,只不过在循环使用)。数组中每一个元素HashedWheelBucket代表一个时间段(默认100ms),其中存放所有处于这个区间需要执行的Timeout对象。Timeout以链表的结构存放在HashedWheelBucket中。
HashedWheelTimer有一个线程在运行执行器worker,worker会一直执行。按时间间隔,worker会判断当前时间轮是否到达应该执行的时间,如果达到时间则会
把timeouts queue中的元素按时间分配到时间轮上指定的HashedWheelBucket中。
执行这个HashedWheelBucket中所有的任务,并把时间轮向前1格。
否则会sleep当前时间格还剩的时间,然后判断下次是否到达时间
比如提交了一个延时500ms的任务,wheel[]每块的间隔是100ms,那么这个任务就会被worker放到wheel[]的第5格。
详细结构
属性
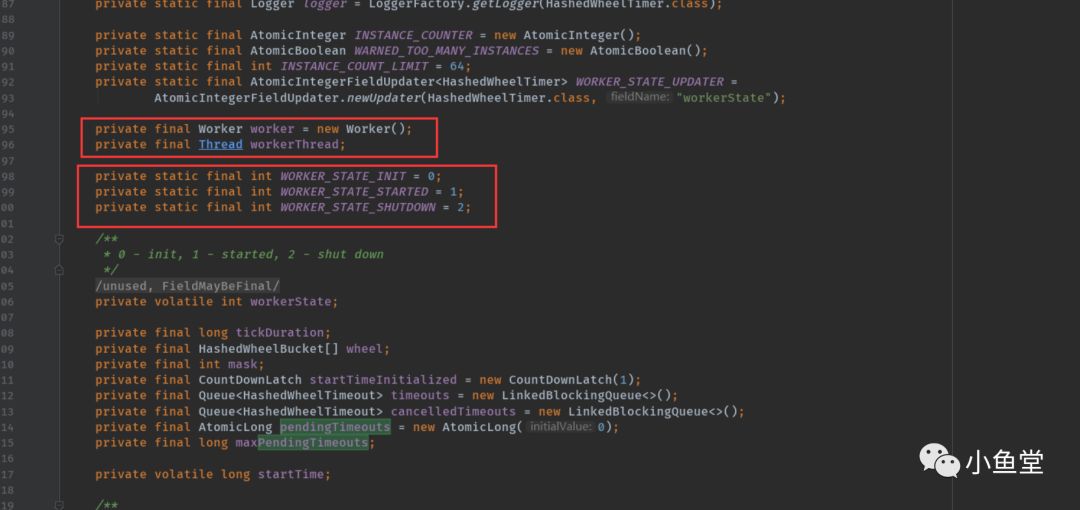
4个静态属性
INSTANCE_COUNTER timer对象创建个数的计数器。每new一个HashedWheelTimer数量会+1,每销毁一个,数量会-1
WARNED_TOO_MANY_INSTANCES 是否需要更多的timer实例
INSTANCE_COUNT_LIMIT 创建timer个数的限制,默认64个
WORKER_STATE_UPDATER 和workerState配合的一个原子更新器
INSTANCE_COUNTER ,WARNED_TOO_MANY_INSTANCES 和INSTANCE_COUNT_LIMIT 一起配合使用。全局timer的个数推荐在64个以下。防止乱new HashedWheelTimer()。当然你要创建64个以上个timer也没问题。在构造方法里会打印一个日志提示一下。
执行相关属性
worker HashedWheelTimer中核心执行逻辑的对象。他会一直执行
thread 执行worker的线程对象。可以看到执行的时候是单线程运作
workerState HashedWheelTimer的工作状态 3种 init started shutdown
数据结构相关属性
tickDuration 每个时间块的间隔 默认是100ms
wheel 时间格环。其实是用数组实现
mask = 时间片个数 -1 用来计算定位timeout对象去哪个块
startTimeInitialized 启动Time的一个锁。数据准备好了才执行start(),只会执行一次
timeouts 存放timeout对象的队列
cancelledTimeouts 存放取消任务timeout对象的队列
pendingTimeouts 当前还未执行的timeout个数,和maxPendingTimeouts配合使用。如果超过,则不能在加入task给timer了
maxPendingTimeouts 最大存在的task个数。-1表示没限制
startTime timer初始化的时间,所有时间计算都是以此时间作为锚点
构造函数
完成对wheel的结构构造
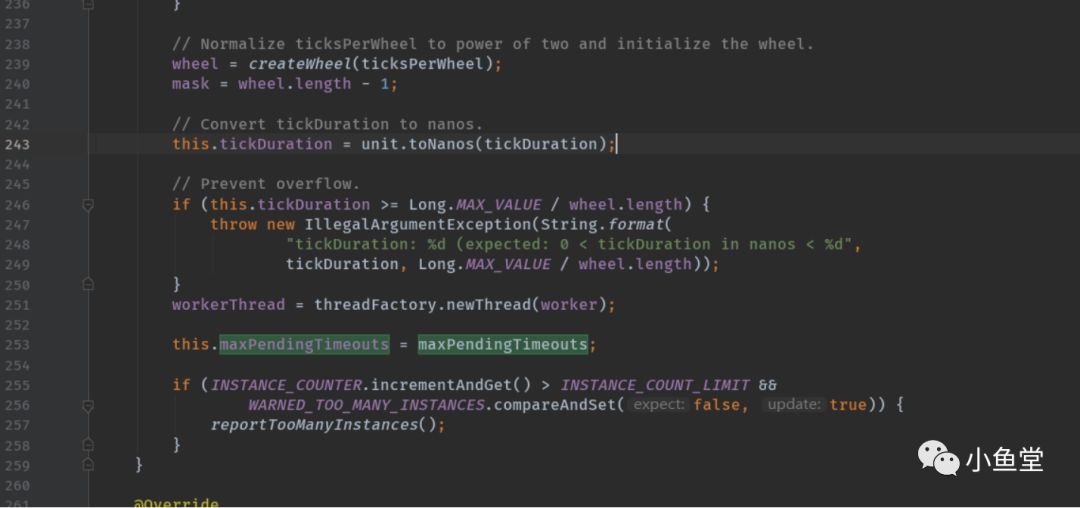
createWheel(ticksPerWheel)创建wheel数组。ticksPerWheel是长度,默认512,创建出一个512块的时间轮(其实是数组)
设置mask = length - 1。后面定位时间位使用
duration时间转换成纳秒,提高精度
创建一个线程,并提交woker任务
设置最大任务数和timer实例数+1
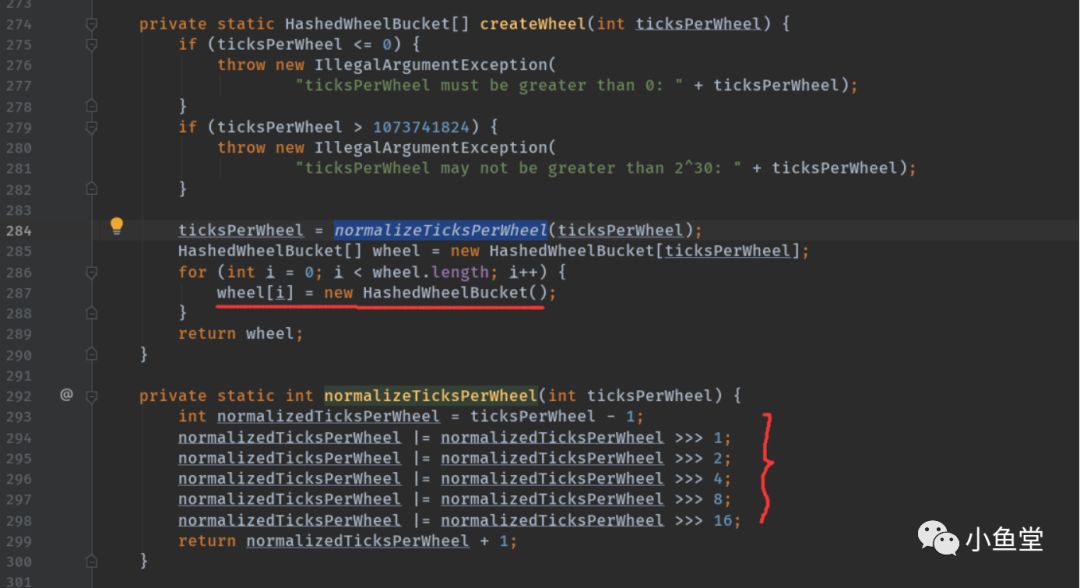
createWheel按传入的ticksPerWheel个数循环创建bucket.
normalizeTicksPerWheel 将传入的数量转换成2的指数的数字。比如50会变成64
添加task
通过newTimeout给timer添加任务并指定要执行的延时时间,timer会返回一个timeout对象。timeout对象包含了这次任务的对象和timer对象
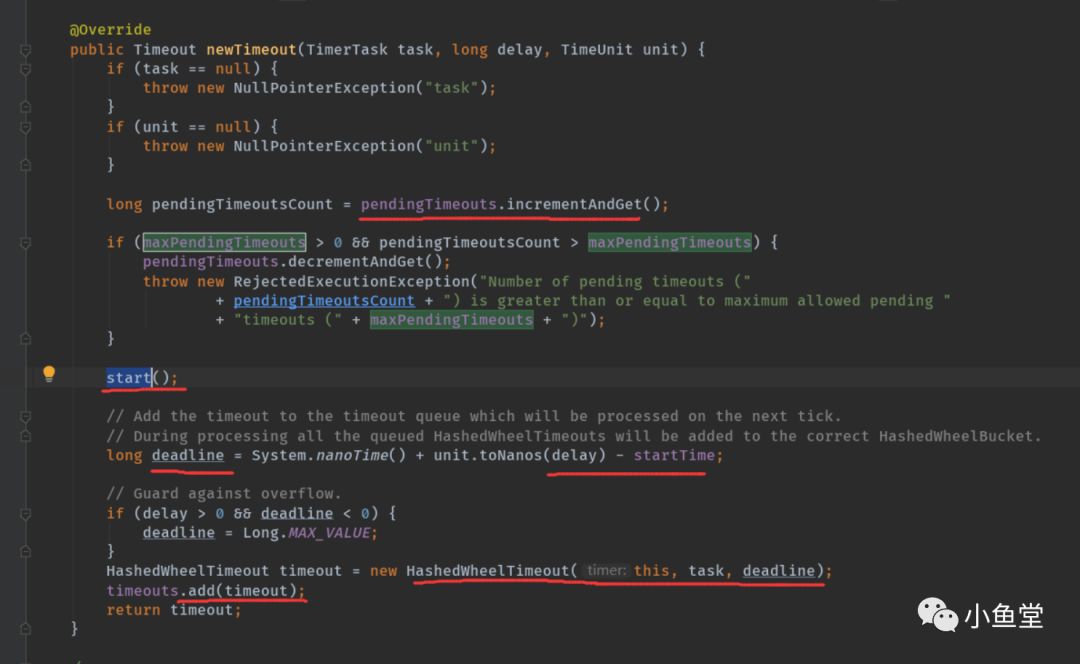
incrementAndGet 任务数量+1
start() 开启线程
deadline计算这个任务要执行的时间。以startTime为锚点。即startTime为零点
new一个Timeout对象,加入queue,并返回
start()
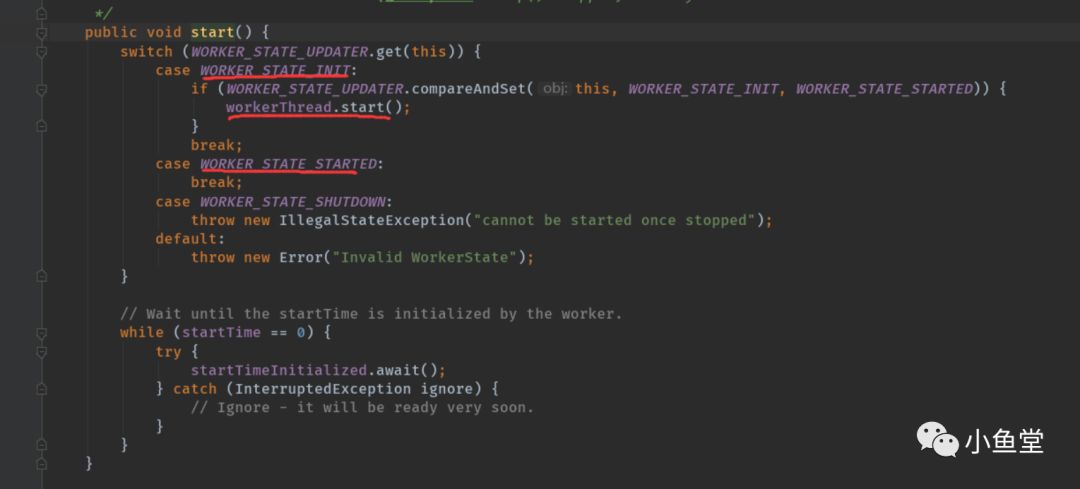
如果状态是init就启动子线程,否则就啥都不做或者抛出异常。start只会执行一次。
这里为了防止多线程提交任务,导致多次启动start。在case后,再加了一次原子的set方法。
子线程start后,就会执行已经在构造函数里面已经提交的woker任务
while循环等待startTime的赋值。startTime会在woker里面赋值。startTimeInitialized也只会阻塞一次,CountDown后释放。
work
work实现了runnable的run方法。被子线程调用执行。
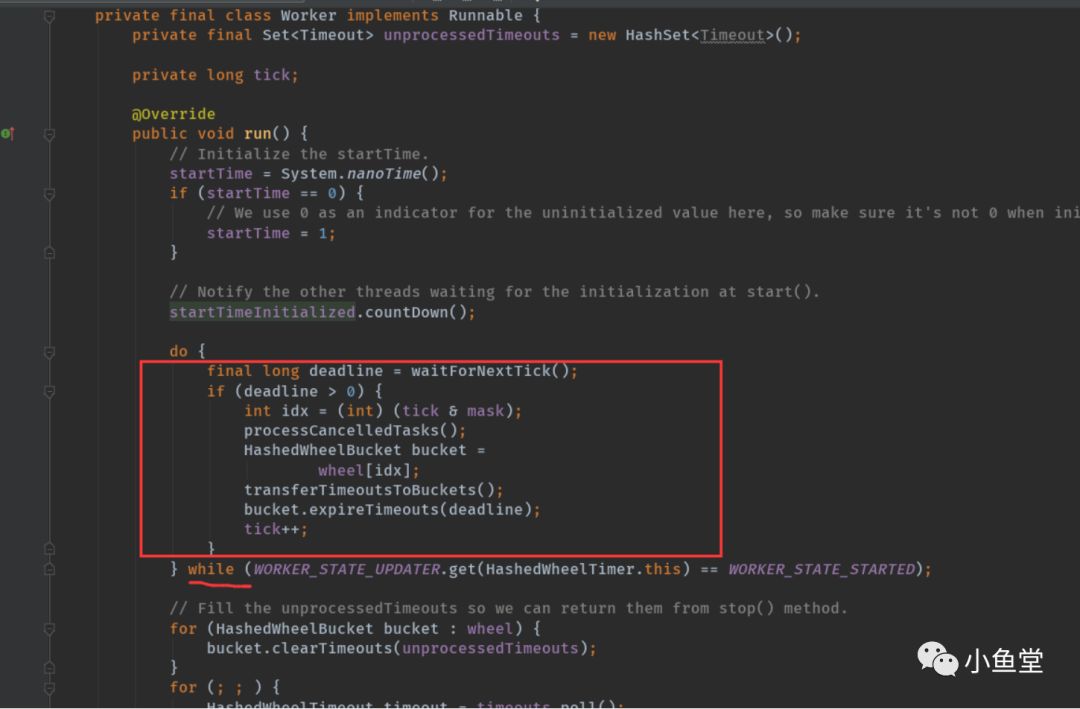
给startTime赋值初始值。作为整个timer计算时间的锚(零点)。同时打开countDown(),释放start()的阻塞。
work核心逻辑
判断是否执行
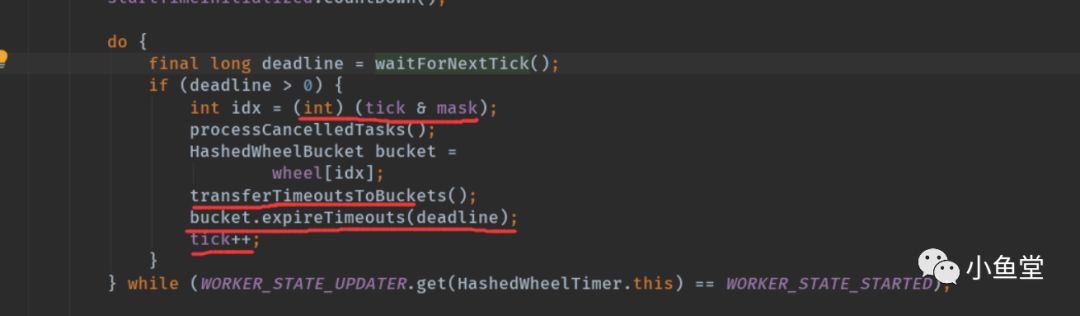
waitForNextTick()是核心方法。用来计算下个时间片的时间。
tick从0开始,外层deadline每符合>1一次就会+1。表示时间格往前走了一步。deadline就是当前走过的时间。比如每格是100ms,走了5次,deadline就是500ms。
currentTime是以startTime为0点的相对时间。startTime是timer启动的时间,都以这个时间为参考物。
deadline - currentTime小于等于0,表示当前时间已经达到或者超过本格的时间了,所以要执行本格时间的任务了。如果大于0表示时间还没到,就再等待剩下的时间,再下一次进行计算。
除以1000000是纳秒精度
简单来说就是在固定的512个格子上不断的循环,每个格式有100ms的时间范围。判断当前时间是否处于这个格子的时间段内。如果在就执行这个格子里面的任务,如果不在就等待剩余的时间,然后再次判断。
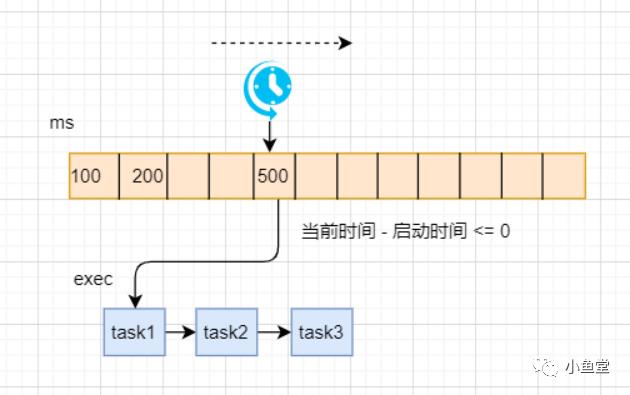
执行逻辑
当deadline符合条件后,执行本时间格的逻辑
找到要处理的时间格idx
processCancelledTasks 移除已经取消的任务
将全局的任务队列中的任务,移动到其该去的时间格
处理已达到时间的任务
时间格向前走一格
因为在时间轮上不断的循环,tick是无限自增的。但是数组的下标在到达length - 1就要回到0重新开始,模拟一个轮子的样子。所以使用tick & mask来找到idx下标。
tick是long型,有最大值。不过以100毫秒算,max(tick) * 0.1秒是这个timer能正常运行的最大时间。也是个long long time了。不太用担心爆掉的问题。
其实取模%一样可以实现,用&是因为这样计算效率比取模高,而且数组长度必须是2的指数个,构造函数对数组元素个数做了强制校验。netty中有很多这样&找下标的方式。
transferTimeoutsToBuckets
将存放任务的队列中的任务按延时时间分配到各自的时间格中
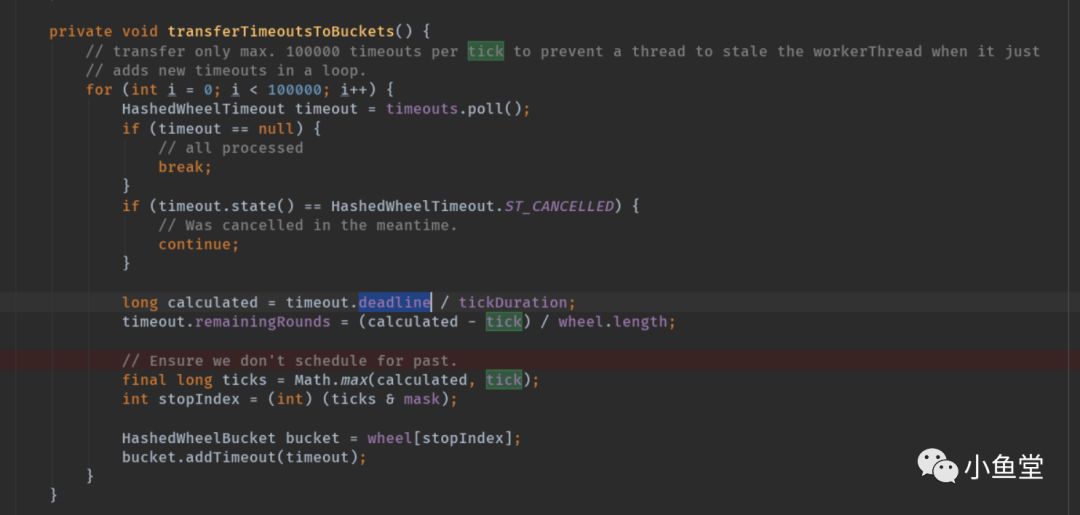
timeout.deadline是这个任务,要执行的时间点。除以tickDuration就得到了要放入时间格的下标。
因为可能延时的很长,所以可能放入第2轮,或者第3轮的同一个时间格。remainingRounds就是时间格的轮数。
按照相同取&的方式将任务add对应的时间格。
比如任务A延时500ms, 任务B延时51700ms
任务A calculated = 5 remainingRounds = 0 stopIndex = 5
任务B calculated = 517 remainingRounds = 1 stopIndex = 5
任务A任务B都进入了下标是5的时间格,但是他们的执行轮次不同。
addTimeout以链表结构维护所有的任务集合
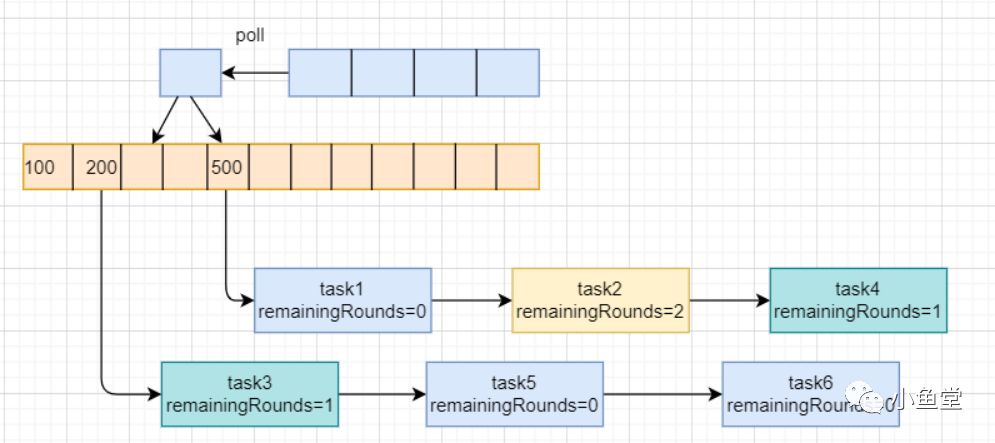
bucket.expireTimeouts
执行到时间的任务
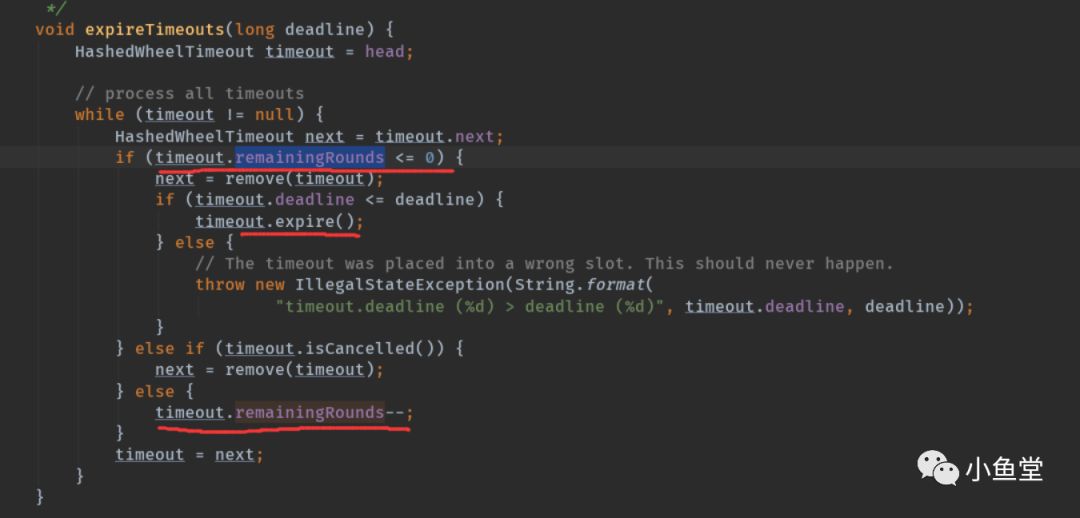
循环执行时间格下所有的任务。
只有在remainingRounds <= 0的本轮任务才会被执行
执行的任务会被移除链表
不在此轮次(remainingRounds > 0)的任务不会执行,且轮次会-1。以便后面减到零后能执行。
执行的方法是调用task的run方法。且吃掉了异常。
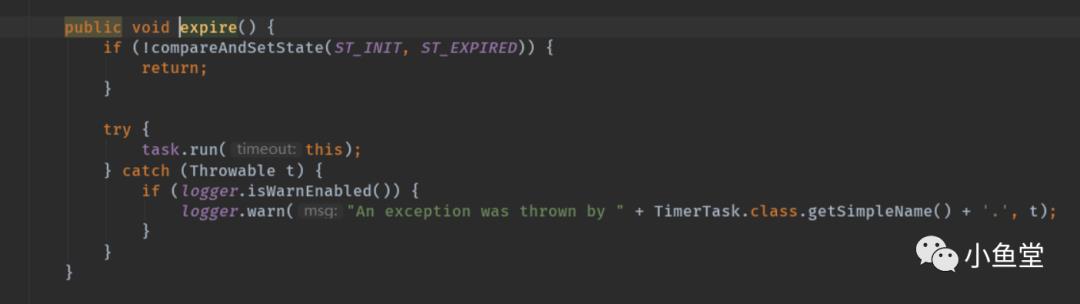
可以看到执行的所有步骤都是work对应的单线程进行的。所以即使不考虑精度,如果有任务特别耗时,后面的任务是可能不准时执行的。
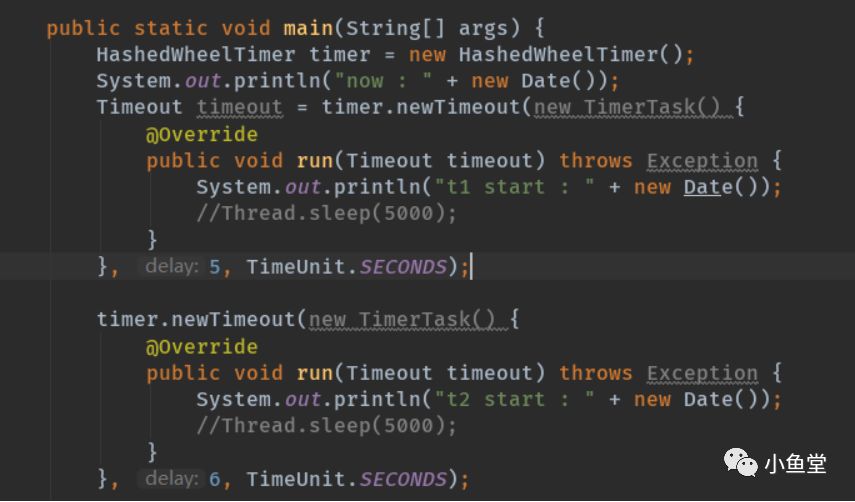
正常的执行结果

开放注释模拟执行时间后

dubbo实战
和zk打交道的ZookeeperRegistry类,有很多注册和通知的动作。他继承了FailbackRegistry。对于没成功的动作,会由FailbackRegistry来进行重试。重试的过程用到了HashedWheelTimer
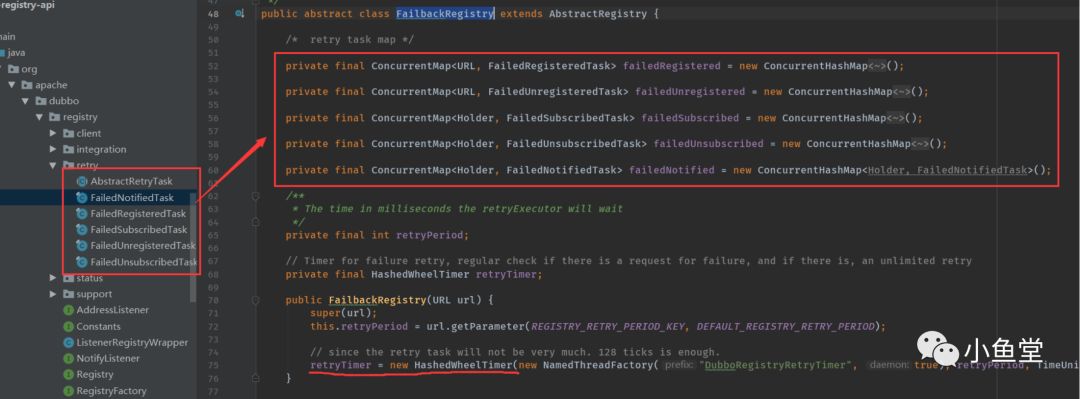
属性中定义了各种失败的任务集合。包括注册失败,通知失败等等。他们都实现了timertask类
构造方法中创建了HashedWheelTimer对象retryTimer
以注册失败为例
如果Registered方法异常,会将注册失败重试的任务提交给retryTImer
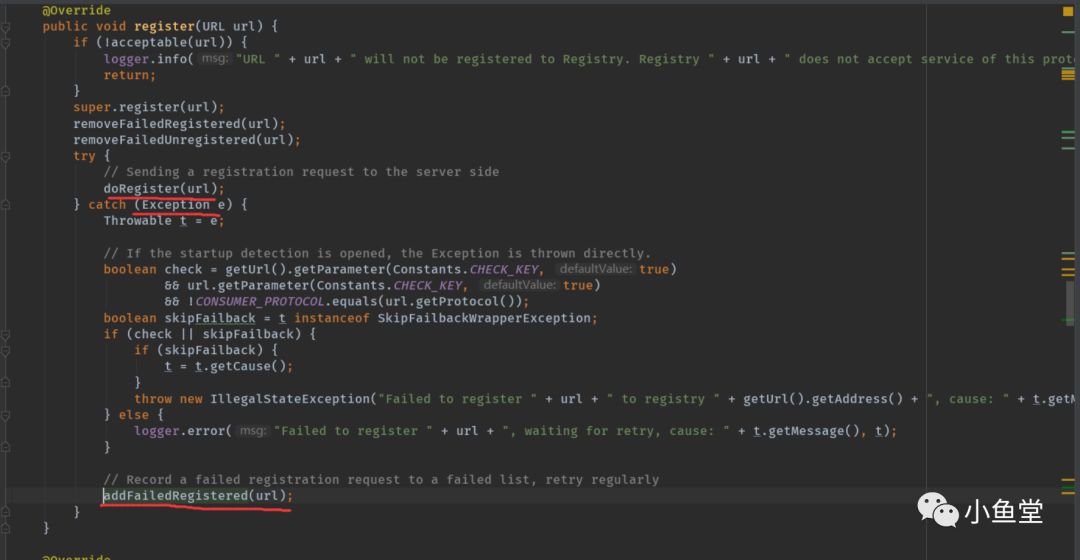
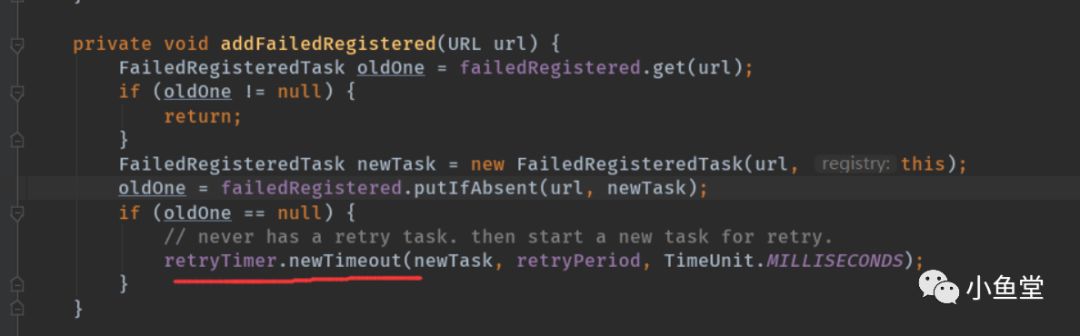
任务会在给定时间延时执行。执行任务逻辑如下:
执行前会先判断是否超过重复执行次数。默认是3次。如果重复执行3次将不会再重试。
如果执行失败,会reput再次提交给timer,并记录一次重复执行次数。
doRetry是子类实现的具体业务逻辑。
重新注册。如果成功便移除此任务。
总结
HashedWheelTimer实现了一个简单的异步延时执行器。
他用数组模拟环形的时间轮来计算时间,并没有将任务按照执行时间强制排序。
执行是单线程的。如果某些任务时间执行耗时,会导致后面任务延时时间不太精准。
以上是关于读源码-dubbo-奇技淫巧-HashedWheelTimer的主要内容,如果未能解决你的问题,请参考以下文章