大牛带你深入Dubbo,高性能RPC通信框架:Dubbo简介和总体大图
Posted 程序员高级码农
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大牛带你深入Dubbo,高性能RPC通信框架:Dubbo简介和总体大图相关的知识,希望对你有一定的参考价值。
Dubbo 简介
假设你正在参与公司一项非常重要的项目开发,在做需求沟通时,要求系统在分布式场景下实现高并发、高可扩展、自动容错和高可用,如果这个项目由你主导,你会怎么做呢?
在分布式场景下,可能最先想到的是分布式通信的问题,在Google或国内网站上搜索分布式RPC框架,就会搜索到Dubboo
一般熟悉一个框架,首先会查阅官网,然后下载最新代码,仔细阅读代码示例或新手指南,最后动手编写代码或打开示例代码,在开发工具中快速运行。如果已经有不错的编程经验,那么或许能顺利“跑通”,如果是编程新手则可能被一些配置或编译错误难倒。
编写分布式场景下高并发、高可扩展的系统对技能的要求很高,因为其中涉及序列化/反序
列化、网络、多线程、设计模式、性能优化等众多专业知识。Dubbo框架很好地将这些专业知
识做了更高层的抽象和封装,提供了各种开箱即用的特性,让用户可以“傻瓜式”地使用。
我们编写这本书的主要目的:Dubbo能够被更广泛地使用,让更多的开发人员真正理解里面的核心思想和实现原理。这里也包含关注点在业务领域,却没有足够的精力去研究框架,但是又有兴趣成为RPC领域专家的读者。从开源层面上来讲,我们也欢迎正在使用Dubbo的用户和对框架定制的开发者参与进来。
Dubbo提供了非常丰富的开箱即用的特性,我们会花费大部分时间来挖掘它的能力,Dubbo是一个分布式高性能的RPC服务框架,它的核心设计原则:微内核+插件体系,平等对待第三方。我们也会探讨Dubbo其他方面的内容,例如:
•Dubbo核心协议;
•扩展点SPI;
•线程模型;
•注册中心;
•关注点分离(解耦业务和框架)。
在本章中,首先从应用架构的整个演进过程开始,介绍Dubbo的历史和未来方向,然后讲解Dubbo的总体架构、核心组件及总体工作流程,在本章结束之后,就可以开始动手编写第一款基于Dubbo的分布式应用程序了。
前面介绍了应用服务的演进历史,那么Dubbo的出现是为了解决什么问题呢?本节将围绕Dubbo是什么、它的发展历史,以及未来的发展方向来讲解。
Dubbo的发展历史
2011年,阿里巴巴(简称阿里)宣布开源SOA服务化治理方案的核心框架——Dubbo 2.0.7。
Dubbo的设计思想在当时是非常超前的,因此一石激起千层浪,Dubbo立即被众多公司所使用。
很多公司也在Dubbo的设计思想与基础上,研发出属于自己公司的服务化框架。
2014年,当当网基于Dubbo现有的版本,“fbrk” 了一个分支并命名为Dubbox 2.8.0,支持了 HTTP REST协议。当年10月,阿里发布了 2.3.11版本后就没有继续维护该项目了,整个Dubbo项目处于停滞状态。但是依然有很多公司继续自己维护并使用该框架。后来Spring Cloud出现,很多公司逐渐转向Spring Cloud。
2017年9月,阿里官方宣布重启Dubbo维护,升级了所依赖的JDK及对应组件的版本,并以很快的速度发布了 2.5.4版本和2.5.5版本。当年Dubbo的Star数激增了 77%,瞬间达到18K并在不断增长,可见其受欢迎程度。从此社区生态开始不断发展。
2018年2月,阿里把Dubbo捐献给Apache基金会,进入Apache孵化器,尝试借助社区的力量来不断完善Dubbo生态。
2018年7月,Dubbo官网更新为Dubbo.apache.org,并开始使用新的Logo。
对于Dubbo大事件感兴趣的读者,可以在GitHub中搜索dubbo,并在其wiki页面查看详细内容。
Dubbo 是什么
Dubbo是阿里SOA服务化治理方案的核心框架,每天为2000多个服务提供30多亿次访问量支持,并被广泛应用于阿里集团的各成员站点。阿里重启开源计划主要有以下几个原因:
•战略,云栖大会宣布拥抱开源的发展策略;
•社区,社区反馈的问题得不到及时解决,聆听社区的声音能够激发灵感;
•生态,繁荣的生态普惠所有人;
•回馈,分享阿里在服务治理、大流量、超大规模集群方面的经验。
自从2017年7月重启Dubbo开源,Star数增长7428+, Fork数增长3072+, Watch数增加745+,同时社区生态也在不断壮大发展。Dubbo在GitHub Java类项目中Star数排名前10位(Star数为2L5K+ ,荣获开源中国2017年最受欢迎中国开源软件TOP3 Java类项目第一)。
在分布式RPC框架中,Dubbo是Java类项目中卓越的框架之一,它提供了注册中心机制,解耦了消费方和服务方动态发现的问题,并提供高可靠能力,大量采用微内核+富插件设计思想,包括框架自身核心特性都作为扩展点实现,提供灵活的可扩展能力。
在我们深入了解Dubbo框架之前,请仔细阅读框架的架构和关键特性,如图1.5所示。
其中有一些是技术性的,更多的是关于架构和设计哲学,在探索Dubbo的过程中,我们会多次探讨它们。
图1-5中Provider启动时会向注册中心把自己的元数据注册上去(比如服务IP和端口等),Consumer在启动时从注册中心订阅(第一次订阅会拉取全量数据)服务提供方的元数据,注册中心中发生数据变更会推送给订阅的Consumero在获取服务元数据后,Consumer可以发起RPC调用,在RPC调用前后会向监控中心上报统计信息(比如并发数和调用的接口)。
在了解Dubbo架构的工作原理前,我们先看一下Dubbo所包含的关键特性(包含设计理念),如表1-1所示。


Dubbo解决什么问题
随着互联网应用规模不断发展,单体和垂直应用架构已经无法满足需求,分布式服务架构及流动计算架构势在必行,需要一个治理系统确保架构不断演进,架构演进请参考图l-6。
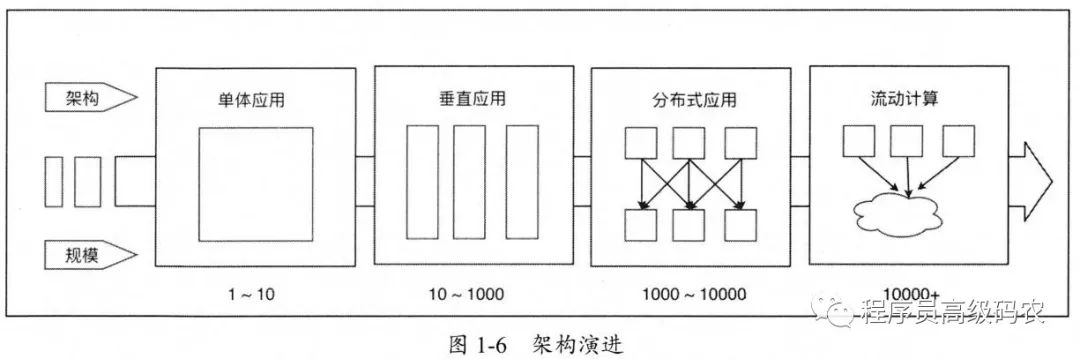
我们先来回顾一下不同应用架构之间的区别。
•单一应用架构:当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。此时,用于简化增删改查工作量的数据访问框架 ORM 是关键。
•垂直应用架构:当访问量逐渐增大时,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。此时,用于加速前端页面开发的Web框架(MVC 是关键。
分布式服务架构:当垂直应用越来越多时,应用之间的交互是不可避免的,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使应用能更快速地响应多变的市场需求。此时,用于提高业务复用及整合的分布式服务(RPC)框架是关键。
流动计算架构:当服务越来越多时,容量的评估、小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心是关键。
•高性能、透明的RPC调用。只要涉及服务之间的通信,RPC就必不可少。Dubbo可以让开发者像调用本地的方法一样调用远程服务,而不需要显式在代码中指定是远程调用。整个过程对上层开发者透明,Dubbo会自动完成后续的所有操作,例如:负载均衡、路由、协议转换、序列化等。开发者只需要接收对应的调用结果即可。
•服务的自动注册与发现。当服务越来越多时,服务URL配置管理变得非常困难,服务的注册和发现已经不可能由人工管理。此时需要一个服务注册中心,动态地注册和发现服务,使服务的位置透明。Dubbo适配了多种注册中心,服务消费方(消费者)可以通过订阅注册中心,及时地知道其他服务提供者的信息,全程无须人工干预。
。自动负载与容错。当服务越来越多时,F5硬件负载均衡器的单点压力也越来越大。Dubbo提供了完整的集群容错机制,可以实现软件层面的负载均衡,以此降低硬件的压力。Dubbo还提供了调用失败的各种容错机制,如Failover、Failfast、结果集合并等。
。动态流量调度。在应用运行时,某些服务节点可能因为硬件原因需要减少负载;或者某些节点需要人工手动下线;又或者需要实现单元化的调用、灰度功能。
Dubbo提供了管理控制台,用户可以在界面上动态地调整每个服务的权重、路由规则、禁用/启用,实现运行时的流量调度。
。依赖分析与调用统计。当应用规模进一步提升,服务间的依赖关系变得错综复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整地描述应用的架构关系。服务的调用量越来越大,服务的容量问题就暴露出来,这个服务需要多少机器支撑?什么时候该加机器?Dubbo可以接入三方APM做分布式链路追踪与性能分析,或者使用已有的独立监控中心来监控接口的调用次数及耗时,用户可以根据这些数据反推出系统容量。
谁在使用Dubbo
Dubbo从2017年7月重启开源并捐献给Apache, Dubbo拥有不断壮大的用户社区,并且保持相当高的活跃度,其中要包含很多大公司,比如阿里巴巴、网易、中国电信、金蝶和滴滴等,已知使用 Dubbo 的用户请参考:https://github.com/apache/incubator-dubbo/issues/1012。
除了使用Dubbo框架,还有很多公司针对Dubbo开发了跨语言的库并捐献给Dubbo生态,比如 dubbo2.js (Node.js)、dubbo-go> dubbo-client-py (Python)和 dubbo-php-framework 等,同时助力了 Dubbo社区的发展。
Dubbo后续的规划
我们在Dubbo官方的规划中,清楚地知道后续Dubbo的发展趋势。Dubbo的核心发展规划如下:
•模块化。解决通信层与服务治理层耦合严重的问题,为Dubbo Mesh做好准备。
•大流量。通过熔断、隔离、限流等手段来提升集群整体稳定性,定位故障节点。
•元数据。服务治理数据和服务注册数据的分离,解决元数据冗长的问题,为对接注册中心、配置中心做好准备。
•大规模。超大规模集群应对服务注册发现、内存占用、CPU消耗带来的挑战。
•路由策略。引入在阿里内部广泛实践的路由策略:多机房、灰度、参数路由等智能化味:峪。
•异步化。CompletableFuture支持,跨进程的Reactive支持,提升分布式系统整体的吞吐率和CPU利用率。
•生态扩展。在API、注册、集群容错等各个层次,兼容并适配现有主流的开源组件,如 Spring Boot、Hystrix 等。
•生态互通。Dubbo在未来还会发布各种其他语言的client,如PHP、Python> Node.jso
•云原生。Dubbo后续会向Dubb。Mesh方向发展,让服务治理能力下沉,成为平台的基础能力,应用无须与特定的语言技术栈绑定,让Dubbo Mesh成为数据面板。
•多语言支持。通过将服务治理能力sidecar化,支持多种语言的RPC已经成为可能,这也是Spring Cloud方案的最大短板。
Dubbo总体大图
本节首先介绍整个Dubbo的总体大图,讲解Dubbo的分层结构,每一层所做的事情,让读者对整个Dubbo的框架有个初步了解。然后介绍Dubbo现有的一些核心组件及总体流程。
Dubbo总体分层
Dubbo的总体分为业务层(Biz)、RPC层、Remote H层。如果把每一层继续做细分,那么一共可以分为十层。其中,Monitor层在最新的官方PPT中并不再作为单独的一层。如图1-7所示,图中左边是具体的分层, 右边是该层中比较重要的接口。
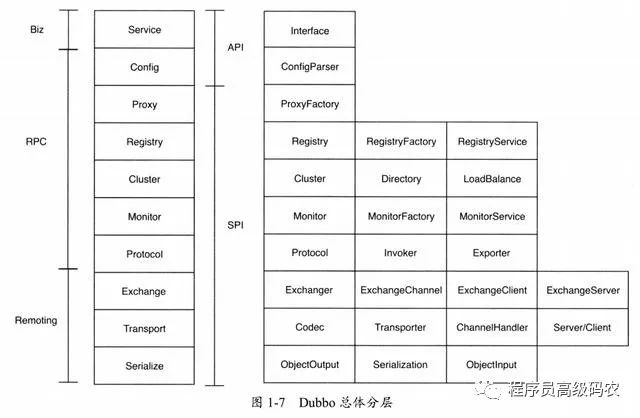
Service和Config两层可以认为是API层,主要提供给API使用者,使用者无须关心底层的实现,只需要配置和完成业务代码即可;后面所有的层级合在一起,可以认为是SPI层,主要提供给扩展者使用,即用户可以基于Dubb。框架做定制性的二次开发,扩展其功能。Dubbo的扩展能力非常强,这也是Dubbo一直广受欢迎的原因之一。后续会有专门的章节介绍Dubbo的扩展机制。
每一层都会有比较核心的接口来支撑整个层次的逻辑,后续如果读者需要阅读源码,则可以从这些核心接口开始,梳理整个逻辑过程。在后面的章节中,我们会围绕不同的层次对其原理进行讲解。
Dubbo核心组件
Dubbo框架中的分层代表了不同的逻辑实现,它们是一个个组件,这些组件构成了整个Dubbo体系,在使用方角度更多接触到的可能是配置,更多底层构件被抽象和隐藏了,同时提供了非常高的扩展性。Dubbo框架之所以能够做到高扩展性,受益于各个组件职责分明的设计,每个组件提供灵活的扩展点,如表1-2所示。
Dubbo总体调用过程
或许有读者目前还不能理解整个组件串起来的工作过程,因此我们先介绍一下服务的暴露过程。首先,服务器端(服务提供者)在框架启动时,会初始化服务实例,通过Proxy组件调用具体协议(Protocol ),把服务端要暴露的接口封装成Invoker (真实类型是AbstractProxylnvoker ,然后转换成Exporter,这个时候框架会打开服务端口等并记录服务实例到内存中,最后通过Registry把服务元数据注册到注册中心。这就是服务端(服务提供者)整个接口暴露的过程。读者可能对里面的各种组件还不清楚,下面就讲解组件的含义:
•Proxy组件:我们知道,Dubbo中只需要引用一个接口就可以调用远程的服务,并且只需要像调用本地方法一样调用即可。其实是Dubbo框架为我们生成了代理类,调用的方法其实是Proxy组件生成的代理方法,会自动发起远程/本地调用,并返回结果,整个过程对用户完全透明。
•Protocol:顾名思义,协议就是对数据格式的一种约定。它可以把我们对接口的配置,根据不同的协议转换成不同的Invoker对象。例如:用DubboProtocol可以把XML文件中一个远程接口的配置转换成一个Dubbolnvoker。
•Exporter:用于暴露到注册中心的对象,它的内部属性持有了 Invoker对象,我们可以认为它在Invoker上包了 一层。
•Registry:把Exporter注册到注册中心。
以上就是整个服务暴露的过程,消费方在启动时会通过Registry在注册中心订阅服务端的元数据(包括IP和端口)。这样就可以得到刚才暴露的服务了。
下面我们来看一下消费者调用服务提供者的总体流程,我们此处只介绍远程调用,本地调用是远程调用的子集,因此不在此展开。Dubbo组件调用总体流程如图1-8所示。
首先,调用过程也是从一个Proxy开始的,Proxy持有了一个Invoker对象。然后触发invoke调用。在invoke调用过程中,需要使用Cluster, Cluster负责容错,如调用失败的重试。Cluster在调用之前会通过Directory获取所有可以调用的远程服务Invoker列表(一个接口可能有多个
节点提供服务)。由于可以调用的远程服务有很多,此时如果用户配置了路由规则(如指定某些
方法只能调用某个节点),那么还会根据路由规则将Invoker列表过滤一遍。
然后,存活下来的Invoker可能还会有很多,此时要调用哪一个呢?于是会继续通过
LoadBalance方法做负载均衡,最终选出一个可以调用的Invokero这个Invoker在调用之前又会
经过一个过滤器链,这个过滤器链通常是处理上下文、限流、计数等。
接着,会使用Client做数据传输,如我们常见的Netty Client等。传输之前肯定要做一些私
有协议的构造,此时就会用到Codec接口。构造完成后,就对数据包做序列化(Serialization ,
然后传输到服务提供者端。服务提供者收到数据包,也会使用Codec处理协议头及一些半包、
粘包等。处理完成后再对完整的数据报文做反序列化处理。
随后,这个Request会被分配到线程池 ThreadPool 中进行处理oServer会处理这些Request,
根据请求查找对应的Exporter 它内部持有了 Invoker 0 Invoker是被用装饰器模式一层一层套
了非常多Filter的,因此在调用最终的实现类之前,又会经过一个服务提供者端的过滤器链。
最终,我们得到了具体接口的真实实现并调用,再原路把结果返回。
至此,一个完整的远程调用过程就结束了。详细的远程调用的原理机制会在第6章中讲解。
小结
本章我们介绍了整个应用框架的演进历史,以及Dubbo框架的历史背景和未来发展方向,同时介绍了 Dubbo提供的特性。我们了解了国内有很多大公司都在使用Dubbo,目前Dubbo又重启维护,社区不断在成长与壮大。
然后,我们概述了 Dubbo的总体架构图和核心组件,并把所有核心组件合在一起,讲解Dubbo的一次总体调用的过程。
觉得文章不错的话,可以转发关注小编一下,之后持续更新干货文章!
下一篇我们会探讨Dubbo的API和编程模型的知识,会编写第一款分布式应用程序。
以上是关于大牛带你深入Dubbo,高性能RPC通信框架:Dubbo简介和总体大图的主要内容,如果未能解决你的问题,请参考以下文章