妹妹问我:Dubbo集群容错负载均衡
Posted 三太子敖丙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了妹妹问我:Dubbo集群容错负载均衡相关的知识,希望对你有一定的参考价值。
前言
相信经过前面几篇之后,大家已经对 Dubbo 整体流程已经清晰了,包括服务是如何暴露的,服务是什么时候注册到注册中心的,以及服务是怎么引入的,服务整体的调用过程等等。
不过还有一个很重要的点没有深入的讲过,就是 Dubbo 的集群容错功能。
线上的服务肯定都是集群部署的,至少得来个两台,互相做 backup,那么问题来了,服务消费者要选用哪一台提供者进行调用呢?调用失败了怎么办呢?
这时候集群容错功能就派上用场了,今天咱们就来深入分析一波 Dubbo 的集群容错。
invoker 是什么?
其实这个在之前就说过了,今天再来复习一遍,因为真的很关键。
在 Dubbo 中 invoker 其实就是一个具有调用功能的对象,在服务暴露端封装的就是真实的服务实现,把真实的服务实现封装一下变成一个 invoker。
在服务引入端就是从注册中心得到服务提供者的配置信息,然后一条配置信息对应封装成一个 invoker,这个 invoker 就具备远程调用能力,当然要是走的是 injvm 协议那真实走的还是本地的调用。
然后还有个 ClusterInvoker ,它也是个 invoker ,它封装了服务引入生成的 invoker 们,赋予其集群容错等能力,这个 invoker 就是暴露给消费者调用的 invoker。
所以说 Dubbo 就是搞了个统一模型,将能调用的服务的对象都封装成 invoker。
我们今天主要讲的是服务消费者这边的事情,因为集群容错是消费者端实现的。
服务目录到底是什么?
服务目录也就是 Directory,其实之前也介绍过的,但不是单独拎出来讲的,可能大伙儿还不太清晰,今儿咱再来盘一下。
服务目录到底是个什么东西呢,看名字好像就是服务的目录,通过这个目录来查找远程服务?
对了一半!可以通过服务目录来查找远程服务,但是它不是"目录",实际上它是一堆 invoker 的集合,
前面说到服务的提供者都会集群部署,所有同样的服务会有多个提供者,因此就搞个服务目录来聚集它们,到时候要选择的时候就去服务目录里挑。
而服务提供者们也不是一成不变的,比如集群中加了一台服务提供者,那么相应的服务目录就需要添加一个 invoker,下线了一台服务提供者,目录里面也需要删除对应的 invoker,修改了配置也一样得更新。
所以这个服务目录其实还实现了监听注册中心的功能(指的是 RegistryDirectory )。
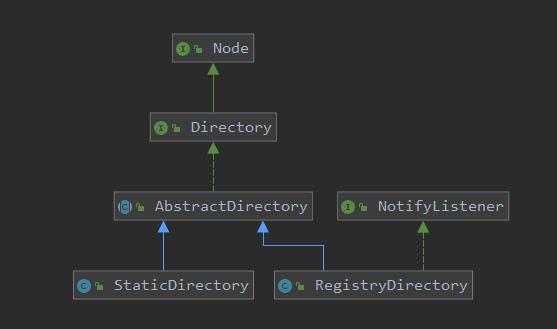
这个 Node 就不管了,主要是看 Directory ,正常操作搞一个抽象类来实现 Directory 接口,抽象类会实现一些公共方法,并且定义好逻辑,然后具体的实现由子类来完成,可以看到有两个子类,分别是 StaticDirectory 和 RegistryDirectory。
RegistryDirectory
我们先来看下 RegistryDirectory ,它是一个动态目录,我们来看一下具体的结构。
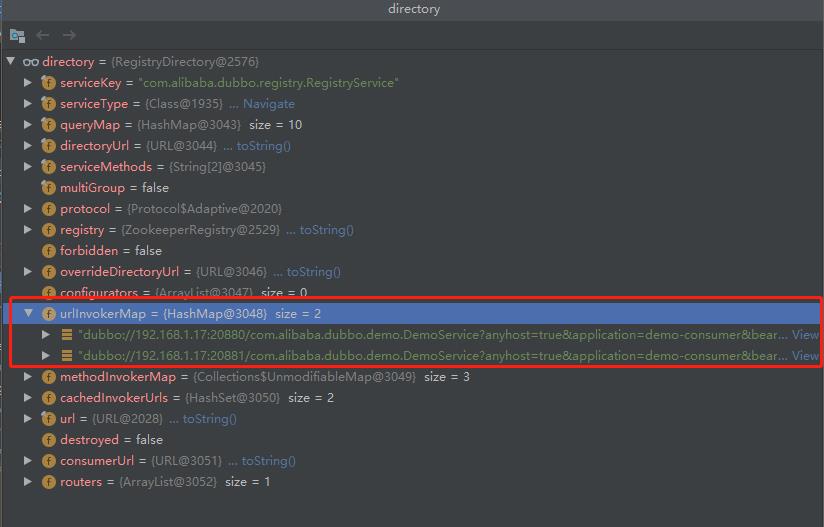
从截图可以看到 RegistryDirectory 内部存储了 DemoService 的两个服务提供者 url 和对应的 invoker。
而且从上面的继承结构也可以看出,它实现了 NotifyListener 接口,所以它可以监听注册中心的变化,当服务中心的配置发生变化之后, RegistryDirectory 就可以收到变更通知,然后根据配置刷新其 Invoker 列表。
所以说 RegistryDirectory 一共有三大作用:
-
获取 invoker 列表 -
监听注册中心的变化 -
刷新 invokers。
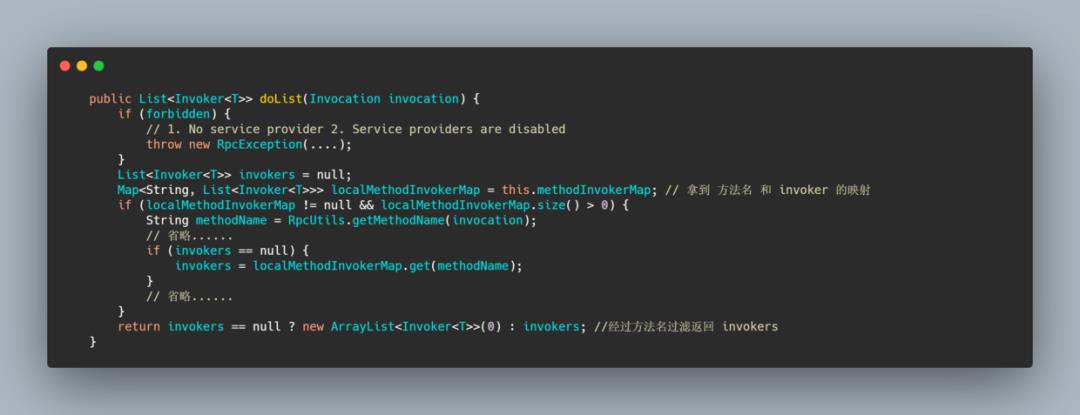
获取 invoker 列表,RegistryDirectory 实现的父类抽象方法 doList,其目的就是得到 invoker 列表,而其内部的实现主要是做了层方法名的过滤,通过方法名找到对应的 invokers。
监听注册中心的变化,通过实现 NotifyListener 接口能感知到注册中心的数据变更,这其实是在服务引入的时候就订阅的。
public void subscribe(URL url) {
setConsumerUrl(url);
registry.subscribe(url, this); //订阅
}
RegistryDirectory 定义了三种集合,分别是 invokerUrls 、routerUrls 、configuratorUrls 分别处理相应的配置变化,然后对应转化成对象。
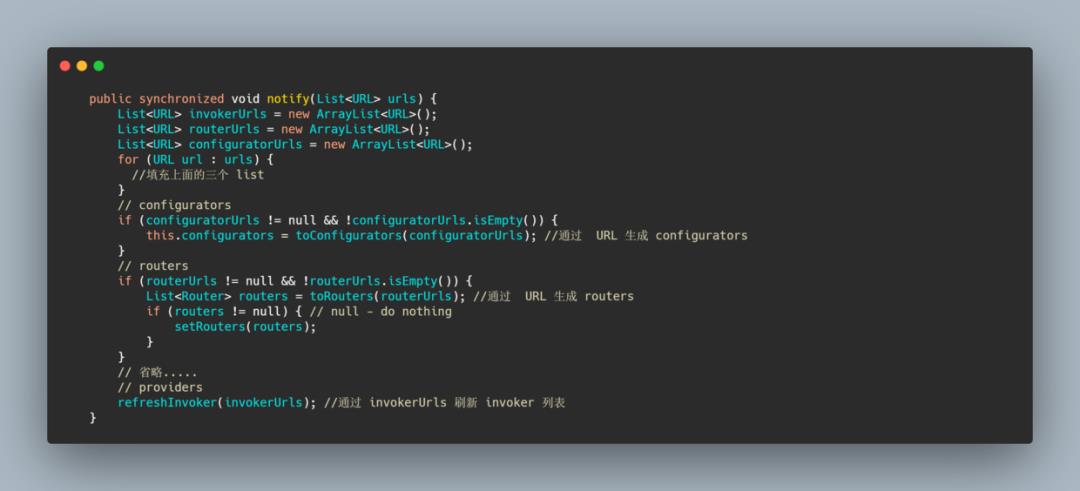
刷新 Invoker 列表,其实就是根据监听变更的 invokerUrls 做一波操作,refreshInvoker(invokerUrls), 根据配置更新 invokers。
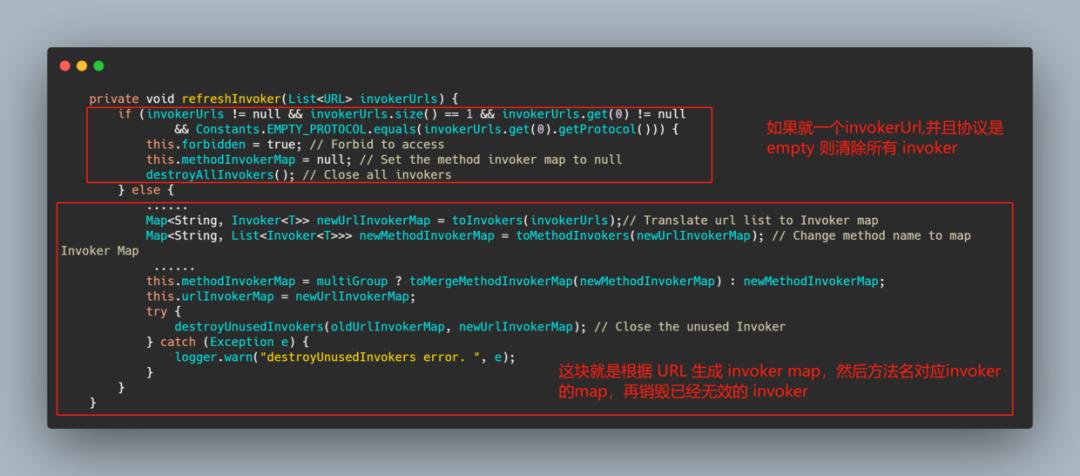
简单的说就是先根据 invokerUrls 数量和协议头是否是 empty,来决定是否禁用所有 invokers,如果不禁用,则将 url 转成 Invoker,得到 <url, Invoker> 的映射关系。
然后再进行转换,得到 <方法名, Invoker 列表> 映射关系,再将同一个组的 Invoker 进行合并,并将合并结果赋值给 methodInvokerMap,这个 methodInvokerMap 就是上面 doList 中使用的那个 Map。
所以是在 refreshInvoker 的时候构造 methodInvokerMap,然后在调用的时候再读 methodInvokerMap,最后再销毁无用的 invoker。
StaticDirectory
StaticDirectory,这个是用在多注册中心的时候,它是一个静态目录,即固定的不会增减的,所有 Invoker 是通过构造器来传入。
可以简单的理解成在单注册中心下我们配置的一条 reference 可能对应有多个 provider,然后生成多个 invoker,我们将它们存入 RegistryDirectory 中进行管理,为了便于调用再对外只暴露出一个 invoker 来封装内部的多 invoker 情况。
那多个注册中心就会有多个已经封装好了的 invoker ,这又面临了选择了,于是我们用 StaticDirectory 再来存入这些 invoker 进行管理,也再封装起来对外只暴露出一个 invoker 便于调用。
之所以是静态的是因为多注册中心是写在配置里面的,不像服务可以动态变更。
StaticDirectory 的内部逻辑非常的简单,就是一个 list 存储了这些 invokers,然后实现父类的方法也就单纯的返回这个 list 不做任何操作。
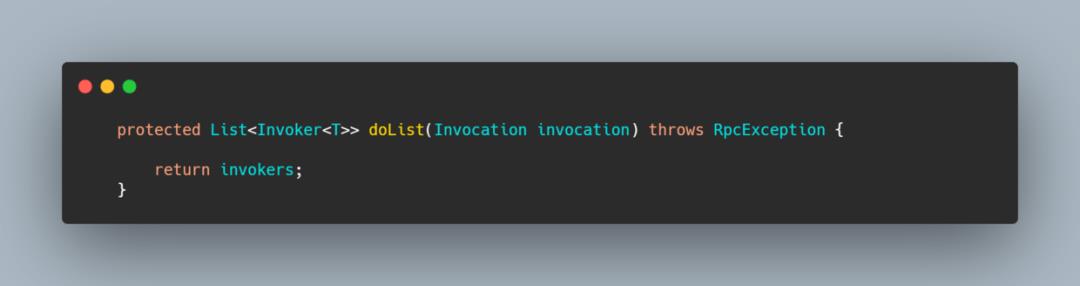
什么是服务路由?
服务路由其实就是路由规则,它规定了服务消费者可以调用哪些服务提供者,Dubbo 一共有三种路由分别是:条件路由 ConditionRouter、脚本路由 ScriptRouter 和标签路由 TagRouter。
最常用的就是条件路由,我们就分析下条件路由。
条件路由是两个条件组成的,是这么个格式 [服务消费者匹配条件] => [服务提供者匹配条件],举个例子官网的例子就是 host = 10.20.153.10 => host = 10.20.153.11。
该条规则表示 IP 为 10.20.153.10 的服务消费者只可调用 IP 为 10.20.153.11 机器上的服务,不可调用其他机器上的服务。
这就叫路由了。
路由的配置一样是通过 RegistryDirectory 的 notify 更新和构造的,然后路由的调用在是刷新 invoker 的时候,具体是在调用 toMethodInvokers 的时候会进行服务级别的路由和方法级别的路由。
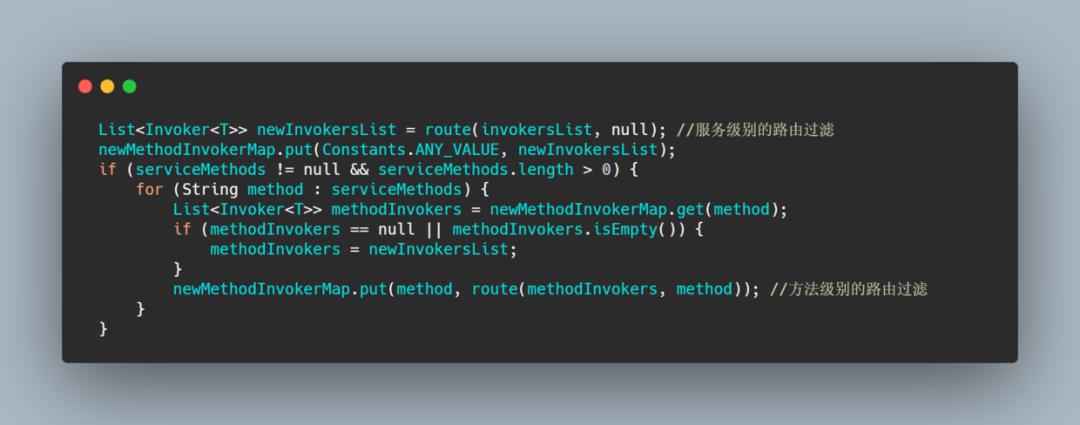
具体的路由匹配和表达式解析就不深入了,有兴趣的同学自行了解,其实知道这个功能是干嘛的差不多了,反正经过路由的过滤之后消费者拿到的都是能调用的远程服务。
Dubbo 的 Cluster 有什么用?
前面我们已经说了有服务目录,并且目录还经过了路由规则的过滤,此时我们手上还是有一堆 invokers,那对于消费者来说就需要进行抉择,那到底选哪个 invoker 进行调用呢?
假设选择的那个 invoker 调用出错了怎么办?前面我们已经提到了,这时候就是 cluster 登场的时候了,它会把这一堆 invoker 封装成 clusterInovker,给到消费者调用的就只有一个 invoker 了,
然后在这个 clusterInovker 内部还能做各种操作,比如选择一个 invoker ,调用出错了可以换一个等等。
这些细节都被封装了,消费者感受不到这个复杂度,所以 cluster 就是一个中间层,为消费者屏蔽了服务提供者的情况,简化了消费者的使用。
并且也更加方便的替换各种集群容错措施。
Dubbo 默认的 cluster 实现有很多,主要有以下几种:
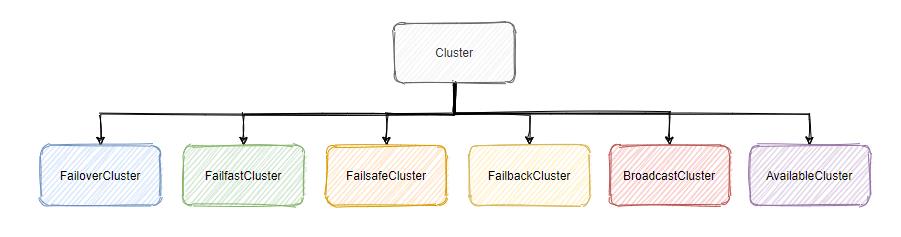
每个 Cluster 内部其实返回的都是 XXXClusterInvoker,我就举一下 FailoverCluster 这个例子。
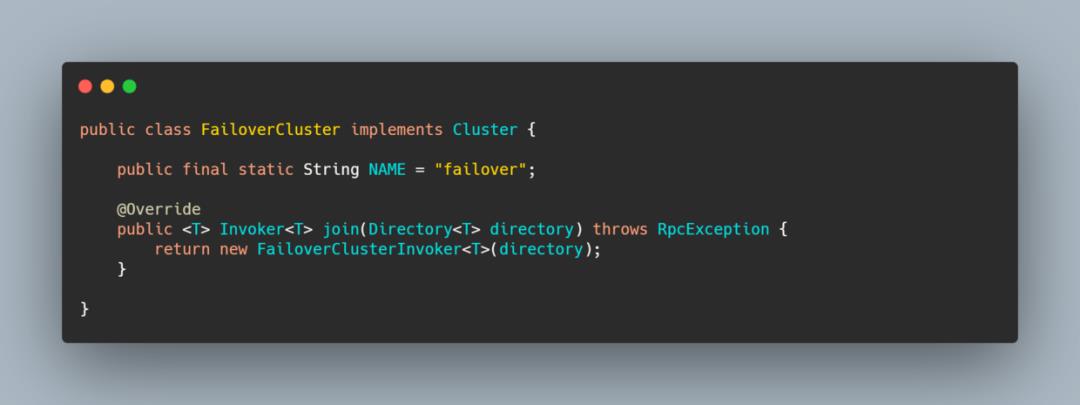
就下来我们就每个 Cluster 过一遍。
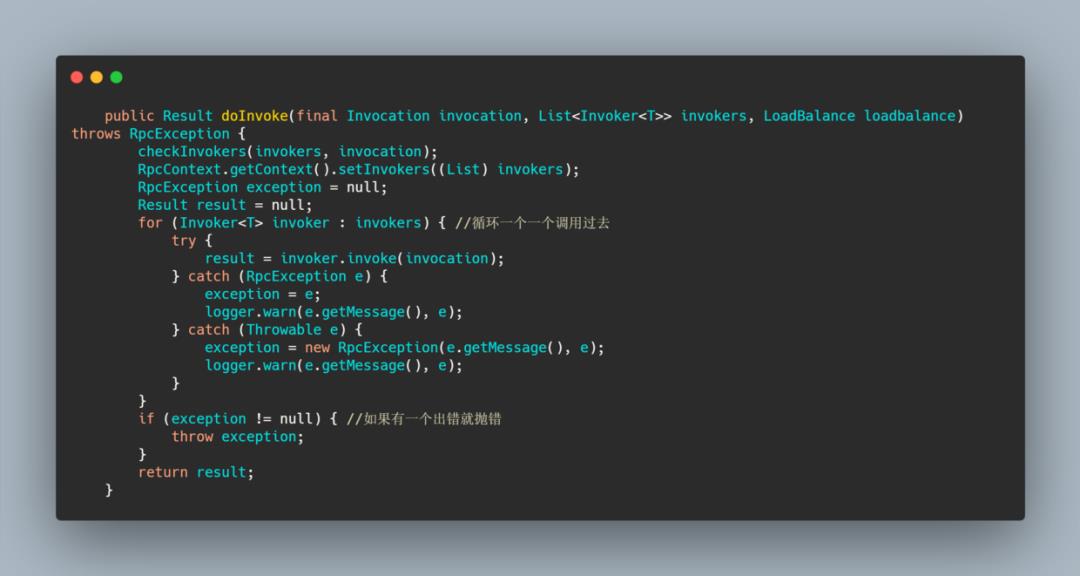
FailoverClusterInvoker
这个 cluster 实现的是失败自动切换功能,简单的说一个远程调用失败,它就立马换另一个,当然是有重试次数的。
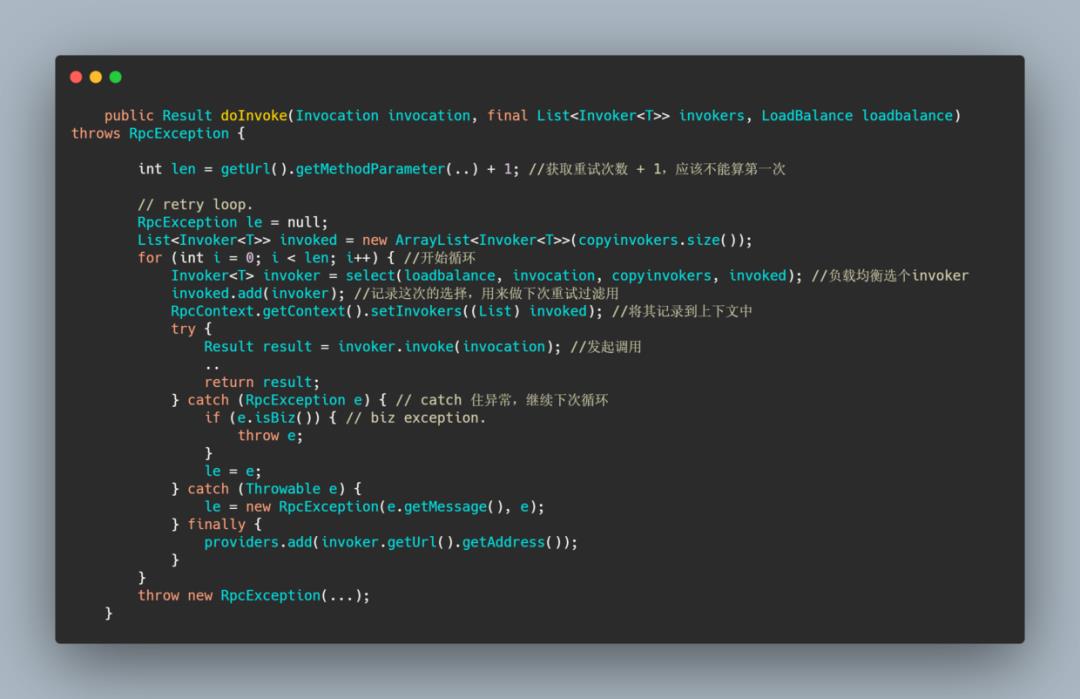
可以看到 doInvoke 方法首先是获取重试次数,然后根据重试次数进行循环调用,会 catch 住异常,然后失败后进行重试。
每次循环会通过负载均衡选择一个 Invoker,然后通过这个 Invoker 进行远程调用,如果失败了会记录下异常,并进行重试。
这个 select 实际上还进行了粘性处理,也就是会记录上一次选择的 invoker ,这样使得每次调用不会一直换invoker,如果上一次没有 invoker,或者上一次的 invoker 下线了则会进行负载均衡选择。
FailfastClusterInvoker
这个 cluster 只会进行一次远程调用,如果失败后立即抛出异常,也就是快速失败,它适合于不支持幂等的一些调用。
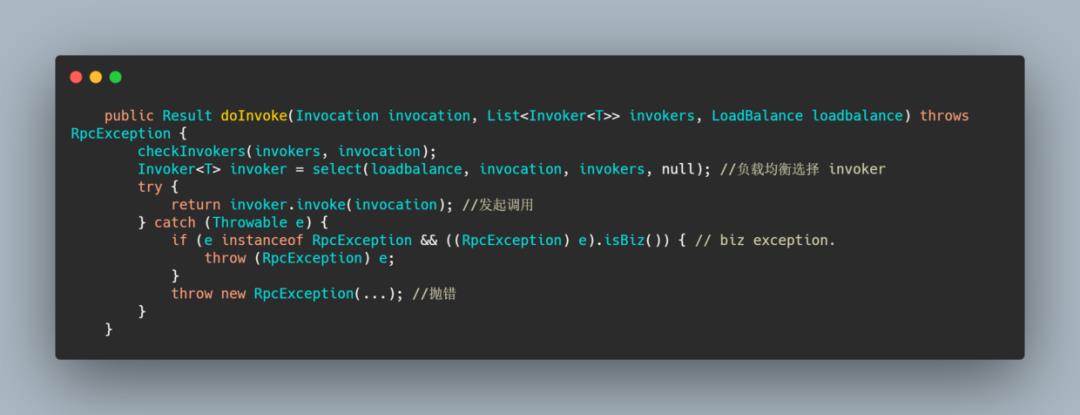
从代码可以看到,很简单还是通过负载均衡选择一个 invoker,然后发起调用,如果失败了就抛错。
FailsafeClusterInvoker
这个 cluster 是一种失败安全的 cluster,也就是调用出错仅仅就日志记录一下,然后返回了一个空结果,适用于写入审计日志等操作。
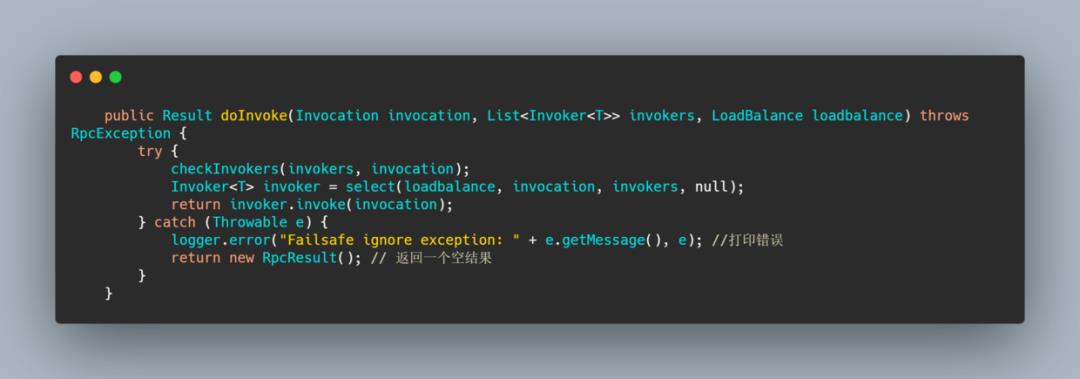
可以看到代码很简单,抛错就日志记录,返回空结果。
FailbackClusterInvoker
这个 cluster 会在调用失败后,记录下来这次调用,然后返回一个空结果给服务消费者,并且会通过定时任务对失败的调用进行重调。
适合执行消息通知等最大努力场景。
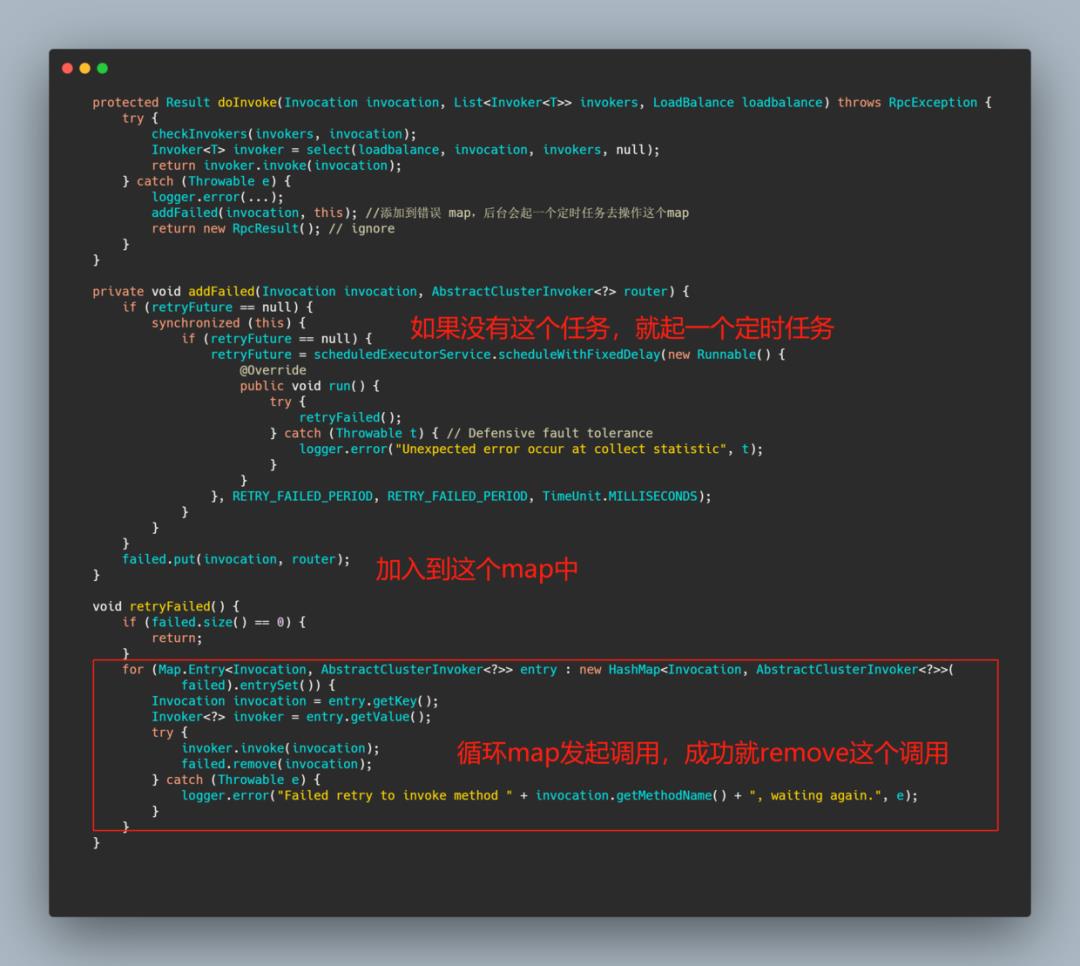
看起来好像代码很多,其实逻辑很简单。
当调用出错的时候就返回空结果,并且加入到 failed 中,并且会有一个定时任务会定时的去调用 failed里面的调用,如果调用成功就从 failed 中移除这个调用。
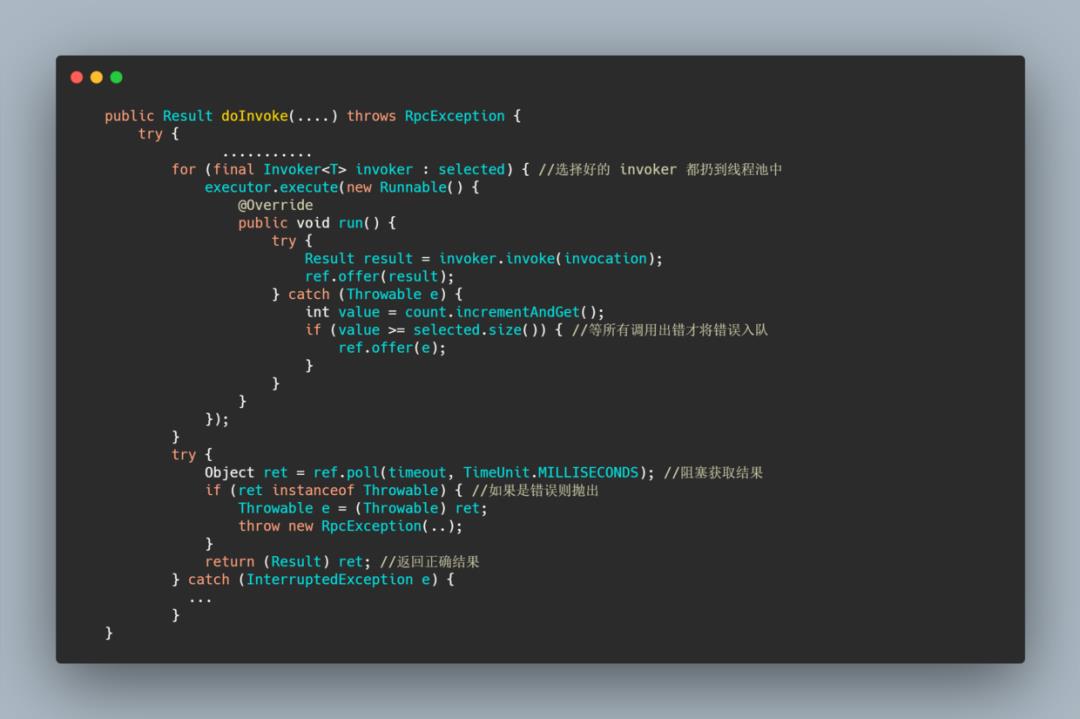
ForkingClusterInvoker
这个 cluster 会在运行时把所有 invoker 都通过线程池进行并发调用,只要有一个服务提供者成功返回了结果,doInvoke 方法就会立即结束运行。
适合用在对实时性要求比较高读操作。
BroadcastClusterInvoker
这个 cluster 会在运行时把所有 invoker 逐个调用,然后在最后判断如果有一个调用抛错的话,就抛出异常。
适合通知所有提供者更新缓存或日志等本地资源信息的场景。
AbstractClusterInvoker
这其实是它们的父类,不过 AvailableCluster 内部就是返回 AbstractClusterInvoker,这个主要用在多注册中心的时候,比较简单,就是哪个能用就用那个。
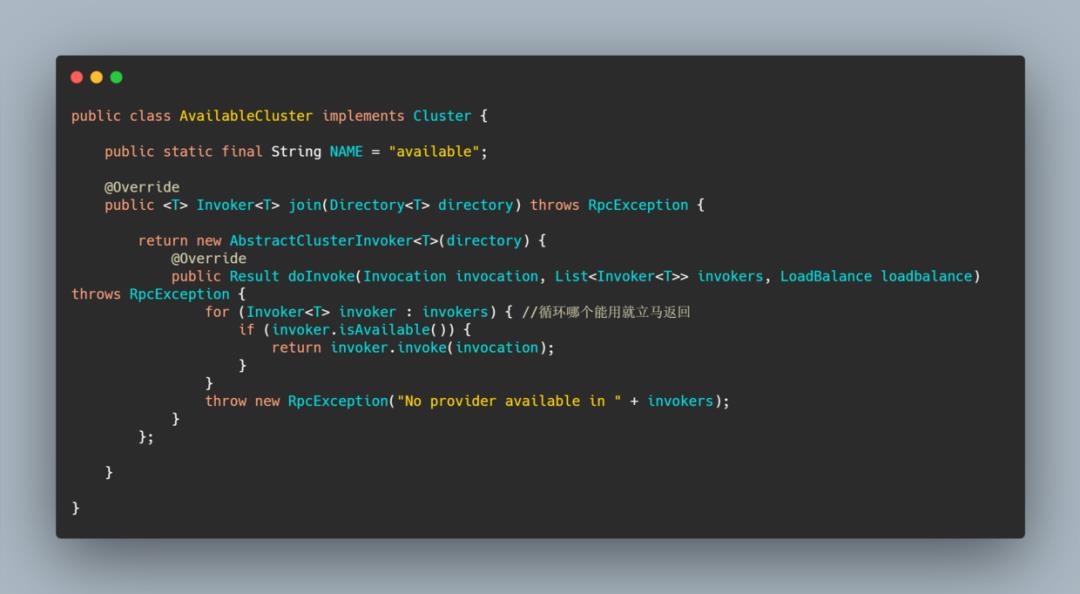
小结 Cluster
可以看到上面有很多种集群的实现,分别适用不同的场景,这其实就是很好的抽象,加了这个中间层向服务消费者屏蔽了集群调用的细节,并且可以在不同场景选择更合适的实现。
当然还能自定义实现,自己加以扩展来定制合适自己业务的链路调用方案。
Dubbo 中的负载均衡
负载均衡其实分为硬件负载均衡和软件负载均衡,大伙儿应该对软件负载均衡比较熟悉,例如 nginx。
而 Dubbo 也有自己的负载均衡,即 LoadBalance,前面我们提到服务提供者一般都是集群部署,这 cluster 虽然暴露出一个 invoker 给消费者调用,但是真的调用给到它的时候,它也得判断具体是要调用哪一个服务提供者,这时候负载均衡就上场了。
所以 Dubbo 中的负载均衡是用来选择出合适的服务提供者给消费者调用的,默认 Dubbo 提供了多种负载均衡算法:
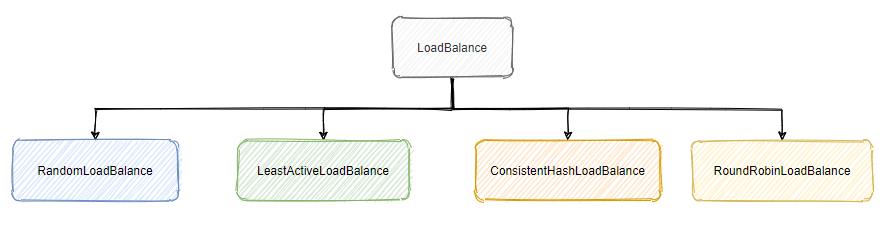
我们一个一个看过去,虽说这涉及到算法了,但是影响不大,大致懂个意思也是可以的,当然能全理解最好了。我们先来看看这些实现类的父类。
AbstractLoadBalance
这些实现类都继承于这个类,该类实现了 LoadBalance 接口,并封装了一些公共的逻辑,同样还是模板方法,熟悉的配方。
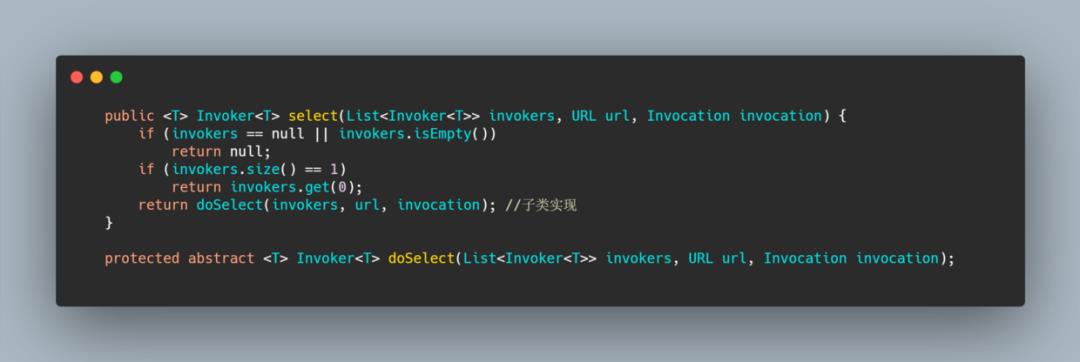
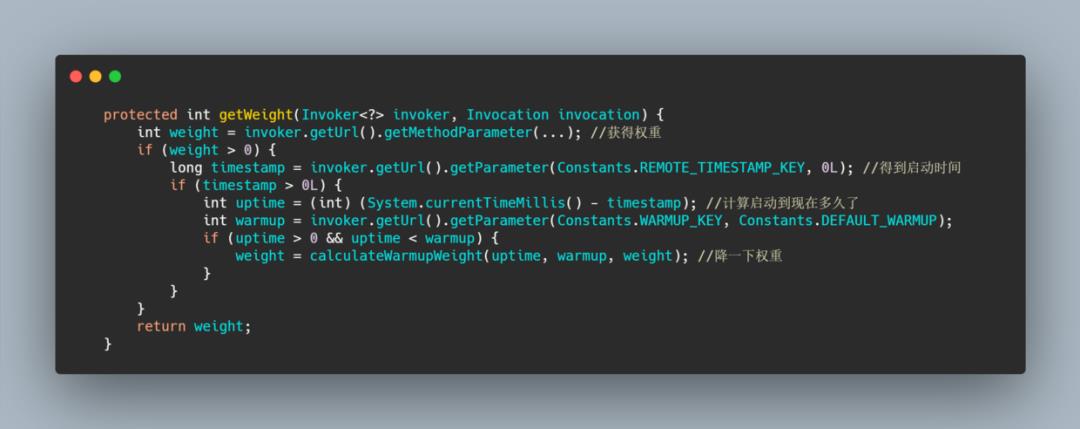
逻辑很简单,我们再来看一下计算权重的方法,这是个公共逻辑,其实是为了服务预热,我们知道缓存有预热,JIT 也有预热,反应到服务上就是服务需要预热。
当服务刚启动的时候不能一下次让它负载过高,得让它慢慢热身,再加上负载,所以这个方法会判断服务运行的时间,来进行服务的降权,这是一个优化手段。
RandomLoadBalance
这个算法是加权随机,思想其实很简单,我举个例子:假设现在有两台服务器分别是 A 和 B,我想让 70% 的请求落到 A 上,30% 的请求落到 B上,此时我只要搞个随机数生成范围在 [0,10),这个 10 是由 7+3 得来的。
然后如果得到的随机数在 [0,7) 则选择服务器 A,如果在 [7,10) 则选择服务器 B ,当然前提是这个随机数的分布性很好,概率才会正确。
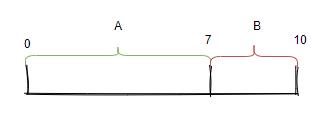
现在我们再来看看 Dubbo 是怎么实现的,思想就是上面的思想。
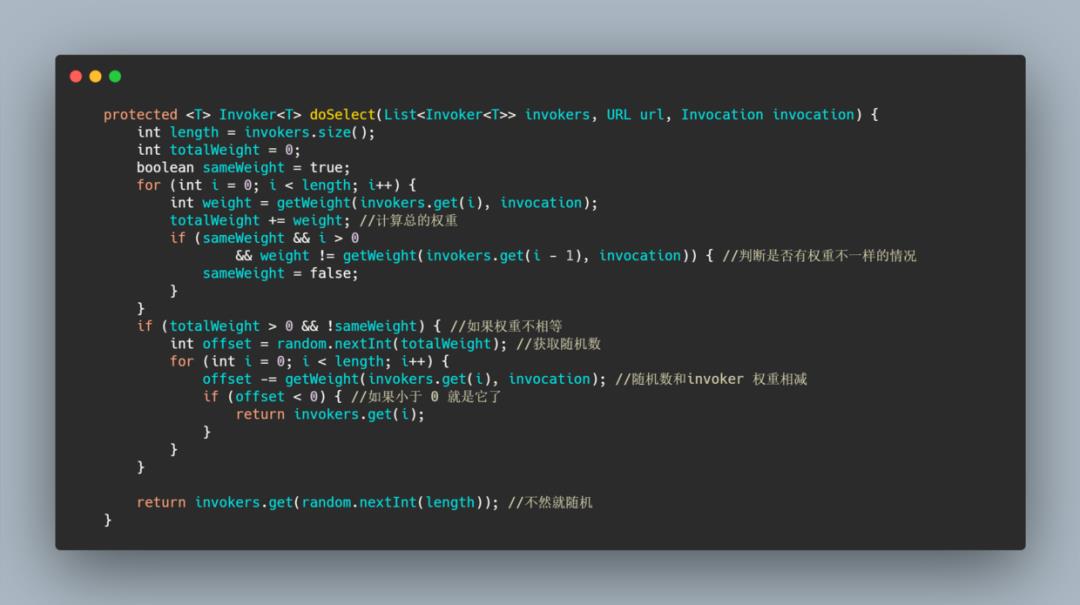
可以看到还是挺简单的,比如随机数拿到的是5,此时 5-7 < 0 所以选择了 A ,如果随机数是8, 那么 8-7 大于1,然后 1-3 小于0 所以此时选择了 B。
这是 Dubbo 默认采取的负载均衡实现。
LeastActiveLoadBalance
这个是最少活跃数负载均衡,从名字就可以知道选择现在活跃调用数最少的提供者进行调用,活跃的调用数少说明它现在很轻松,而且活跃数都是从 0 加起来的,来一个请求活跃数+1,一个请求处理完成活跃数-1,所以活跃数少也能变相的体现处理的快。
这其实就是最少活跃数的思想了,而 Dubbo 在活跃数相等的时候再通过权重来判断,这个权重其实就和 RandomLoadBalance 的实现一样了。
代码我就不贴了,简单的说下流程就是先遍历 invokers 列表,寻找活跃数最小的 Invoker,如果有多个 Invoker 具有相同的最小活跃数,则记录这些 invoker 的下标,并累加它们的权重来进行权重选择。
如果最小活跃数的 invoker 只有一个则直接返回即可。
ConsistentHashLoadBalance
这个是一致性 Hash 负载均衡算法,一致性 Hash 想必大家都很熟悉了,常见的一致性 Hash 算法是 Karger 提出的,就是将 hash值空间设为 [0, 2^32 - 1],并且是个循环的圆环状。
将服务器的 IP 等信息生成一个 hash 值,将这个值投射到圆环上作为一个节点,然后当 key 来查找的时候顺时针查找第一个大于等于这个 key 的 hash 值的节点。
一般而言还会引入虚拟节点,使得数据更加的分散,避免数据倾斜压垮某个节点,来看下官网的一个图。
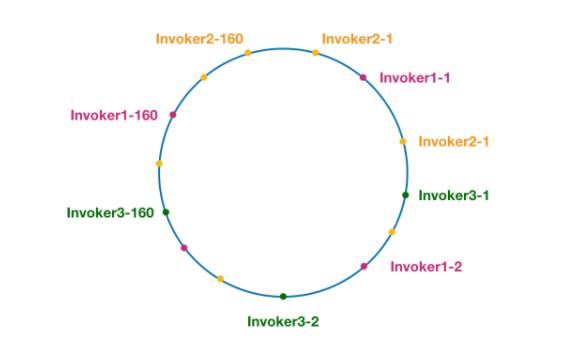
整体的实现也不难,就是上面所说的那个逻辑,而圆环这是利用 treeMap 来实现的,通过 tailMap 来查找大于等于的第一个 invoker,如果没找到说明要拿第一个,直接赋值 treeMap 的 firstEntry。
然后 Dubbo 默认搞了 160 个虚拟节点,整体的 hash 是方法级别的,即一个 service 的每个方法有一个 ConsistentHashSelector,并且是根据参数值来进行 hash的,也就是说负载均衡逻辑只受参数值影响,具有相同参数值的请求将会被分配给同一个服务提供者。
先来看下一致性 hash 的实现,这个 virtualInvokers 是 TreeMap。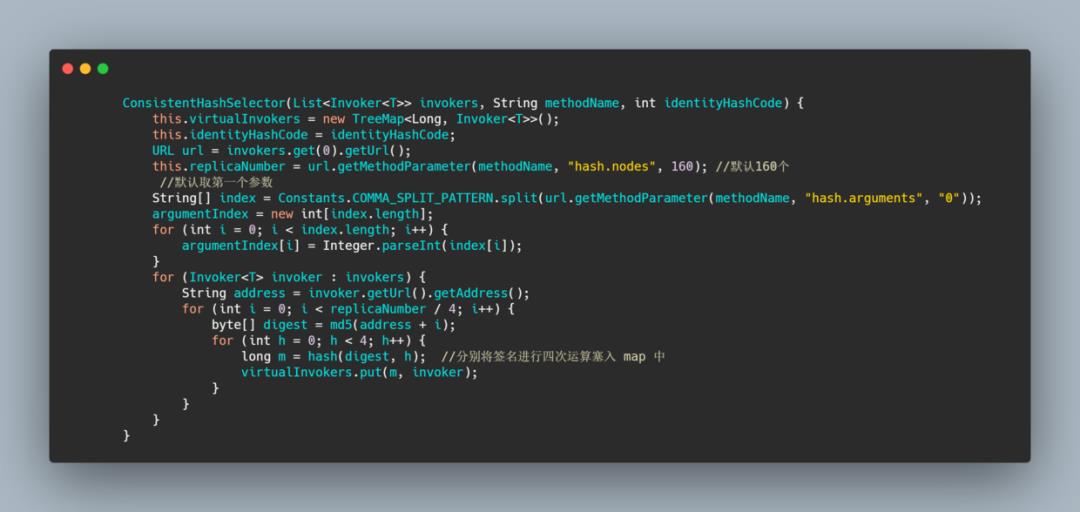
然后来看下如果通过一致性 hash 来获取 invoker 的。
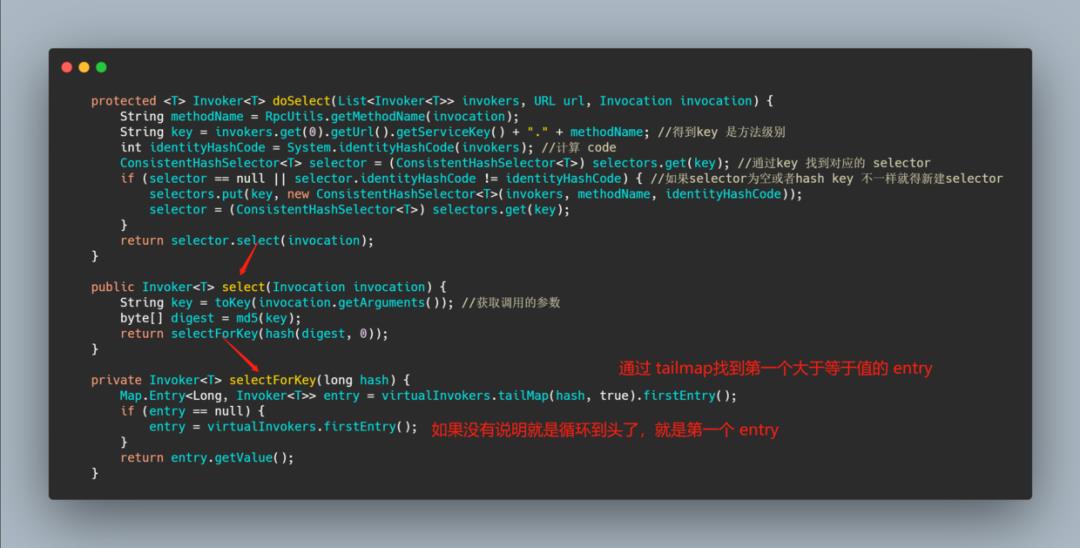
RoundRobinLoadBalance
这个是加权轮询负载均衡,轮询我们都知道,这个加权也就是加了权重的轮询,比如说现在有两台服务器 A、B,轮询的调用顺序就是 A、B、A、B....,如果加了权重,A比B 的权重是3:1,那现在的调用顺序就是 A、A、A、B、A、A、A、B....
加权的原因是个别服务器性能比较好,所以想轮询的多一些。
不过这种方式可以看到前三次都请求 A,然后再 B,不太均匀,假设是 90:80 这种,前 90 次都打到 A 上,A太繁忙,B 太空了。所以还需要平滑一下。
这种平滑的加权轮询比较好了,比如 A、B、A、A、B、A.....,简单的说就是打乱顺序的轮询。
Dubbo 的加权轮询就经历了上述的加权轮询到平滑加权轮询的过程。
具体的代码不做分析了,比较绕,反正就是这个意思, Dubbo 是参考 Nginx 做的平滑加权轮询。
我个人觉得这和第一个说的 RandomLoadBalance 差不多。
串联它们
至此包括服务目录、集群、负载均衡想必大家都已经知道是用来干嘛的了,然后还有 Dubbo 默认的这么些个实现类的区别和适用的场景,下面我就来串着来说一下这几个配合完成集群容错负载均衡功能。
先来看下官网的这一张图,很是清晰,然后我再用语言来阐述一遍。
首先在服务引入的时候,将多个远程调用都塞入 Directory 中,然后通过 Cluster 来封装这个目录,封装的同时提供各种容错功能,比如 FailOver、FailFast 等等,最终暴露给消费者的就是一个 invoker。
然后消费者调用的时候会目录里面得到 invoker 列表,当然会经过路由的过滤,得到这些 invokers 之后再由 loadBalance 来进行负载均衡选择一个 invoker,最终发起调用。
这种过程其实是在 Cluster 的内部发起的,所以能在发起调用出错的情况下,用上容错的各种措施。
最后
至此整个 Dubbo 体系应该了解的都差不多了,可以再回头看看之前的文章巩固一遍,脑海里再过一遍,这整个体系就在脑海中建立起来了,基本上稳了。
后续Dubbo我会出最后一个面试干货版本终结一下,其实写dubbo的这段时间对于我来说是很纠结的,因为写技术干货看的人真的很少,但是我还是想坚持写下去,说实话别说你们不喜欢看,我写起来也很干,有时候确实很难坚持,但是我想着你们以后想看的时候回头想起来敖丙好像写过,翻翻历史记录能看到也够了。
不在乎天长地久只在乎曾经拥有,爱过就好,我是敖丙,感谢各位的三连,你知道的越多,你不知道的越多,我们下期见。
以上是关于妹妹问我:Dubbo集群容错负载均衡的主要内容,如果未能解决你的问题,请参考以下文章