oracle语句 根据操作时间分组
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了oracle语句 根据操作时间分组相关的知识,希望对你有一定的参考价值。
一个用户有多次操作记录,想根据操作时间分下组
分组方法:前三笔操作时间间隔均在一小时之内,后三笔操作时间间隔也均在一小时之内,但是第三笔和第四笔操作间隔大于一小时,如何将他们分成两组,
请高手指教 万分感谢
用户 时间
用户 a 12:08
用户 a 12:09
用户 a 12:10
用户 a 14:08
用户 a 14:09
用户 a 14:11
希望结果
用户 时间 分组后组内排序
用户 a 12:08 1
用户 a 12:09 2
用户 a 12:10 3
用户 a 14:08 1
用户 a 14:09 2
用户 a 14:11 3
如果一笔业务的操作时间和上一笔的操作时间大于1小时,则改记录为下一组的开始时间
如果不用那么麻烦,直接就是按照小时分组,那么
select 用户,时间,rank()over(partition by 用户,substr(时间) order by 时间) from table
我不知道你的时间字段是怎么格式,所以直接写的substr可能还需要转化和具体的截取。这里只是写了一个大概的样子追问
时间是精确到秒的,如果再有一条记录为13:05,N那么他就和12点的那三条记录是一组的,我使用了lead函数,如果他和下一条记录相差一个多小时那么她就是该组的最后一条记录,同样它的下一条就是下一组的开始时间,我现在能取到每一组的开始时间和结束时间,再往后不知怎么处理了
追答有一个办法,不过感觉上麻烦的要死。
那么这个lead求出来应该是这样的,都是时间差大于一小时的。假设开始时间为1:00,结束时间为23:00
那么你的lead出来的表可能为
时间 lead时间
13:05 14:06
15:07 16:10
16:15 17:22
17:25 19:26
那么这个范围应该是小于等于13:05一部分,大于等于14:06且小于等于15:07
。。。。。。,最后是大于19:26
那么要改为
lead时间 时间 标注
1:00 13:05 1
14:06 15:07 2
16:10 16:15 3
17:22 17:25 4
19:26 23:00 5
就是通过min,max以及联立的方式得到
然后与原表关联,用户相等,用时间去卡,大于等于lead时间 and 小于等于时间,那么 就输出这个标注,这样形成新表,然后再利用标注和用户去分组编号。
我了个去,麻烦死了。大概写成存储过程更好一些。
SQL> select yh,to_char(sj,'HH24:SS') from testtab;
YH TO_CH
-------------------- -----
USERa 12:08
USERa 12:09
USERa 12:10
USERa 14:08
USERa 14:09
USERa 14:11
6 rows selected.
SQL> SELECT yh,to_char(sj,'HH24:SS'),rank() over(partition by to_char(sj,'HH24') order by sj) from testtab;
YH TO_CH RANK()OVER(PARTITIONBYTO_CHAR(SJ,'HH24')ORDERBYSJ)
-------------------- ----- --------------------------------------------------
USERa 12:08 1
USERa 12:09 2
USERa 12:10 3
USERa 14:08 1
USERa 14:09 2
USERa 14:11 3
6 rows selected.
SQL>追问
这个时间不一定都是12点和14点
也有可能是这样的情况
USERa 11:08 1
USERa 11:35 2
USERa 12:10 3
USERa 14:45 1
USERa 15:09 2
USERa 15:11 3
其他时间结果也可以的,你看下
参考技术B select t.*,row_number() over(partition by substr(时间,1,2) order by 时间) row_number from a toracle中查询多个字段并根据部分字段进行分组去重
说到分组和去重大家率先想到的肯定是group by和distinct,
1.distinct对去重数据是要根据所有要查询的字段去重,不能对查询结果部分去重。
例如:
select name ,age ,sex from user where sex = "男";
要是只根据name和age去重,这里无法使用distinct关键字了。
2.group by ,可以在mysql中进行分组查询
select name ,age ,sex from user where sex = "男" group by name,age;
但是在Oracle数据库中该sql语句是无法正常执行的,会报如下错误
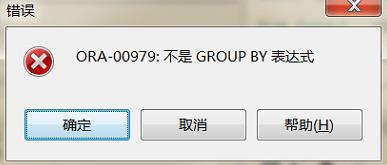
意思是在Oracle中,group by后的字段需要与select中查询的字段需要一一对应(函数除外);
3.使用over()分析函数
首先看原始sql
SELECT t3.* FROM ( SELECT t1.cateid, t1.product_id, t1.user_type, t2.expire_time FROM ( SELECT cfg.cateid, cfg.product_id, cfg.user_type FROM xshe_product_cfg cfg WHERE cfg.product_id IN (1080005002, 1100000001, 1100000002) ) t1 LEFT JOIN ( SELECT * FROM xshe_stock WHERE status = \'04\' AND expire_time >= sysdate ) t2 ON t1.cateid = t2.cateid ) t3
得到的数据结果集
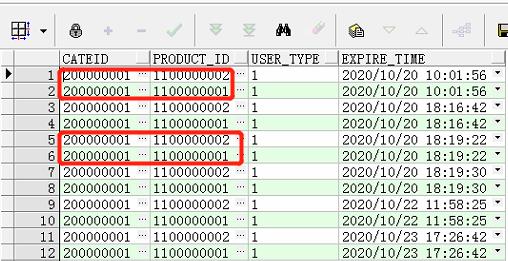
我们想根据cateid和product_id查询出有效期离得最近的一条记录,这里把重复数据都查询出来了
这里我们使用row_number() over()函数进行去重
SELECT t3.* FROM ( SELECT t1.cateid, t1.product_id, t1.user_type, t2.expire_time, ROW_NUMBER() OVER (PARTITION BY t1.cateid, t1.product_id ORDER BY t2.expire_time ASC) AS ROW_NUM FROM ( SELECT cfg.cateid, cfg.product_id, cfg.user_type FROM xshe_product_cfg cfg WHERE cfg.product_id IN (1080005002, 1100000001, 1100000002) ) t1 LEFT JOIN ( SELECT * FROM xshe_stock WHERE status = \'04\' AND expire_time >= sysdate ) t2 ON t1.cateid = t2.cateid ) t3 WHERE t3.ROW_NUM = 1
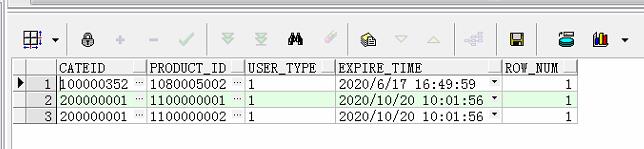
这里我们就对数据进行了完整的去重操作。
以上是关于oracle语句 根据操作时间分组的主要内容,如果未能解决你的问题,请参考以下文章