Go语言构建千万级在线的高并发消息推送系统实践
Posted IT技术精选文摘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Go语言构建千万级在线的高并发消息推送系统实践相关的知识,希望对你有一定的参考价值。
1、前言
Go语言的渗透率越来越高,同时大家对Go语言实战经验的关注度也越来越高。Go语言在高并发、通信交互复杂、重业务逻辑的分布式系统中非常适用,具有开发体验好、一定量级下服务稳定、性能满足需要等优势。
2、Go语言在基础服务开发领域的优势

机器性能方面,该系统的单机在测试环境下,如果只挂长连接(系统参数调优之后),数据往往取决于掉线率。在连接稳定的情况下发出广播,心跳时间不受影响,内部QPS在一个可接受的状态达到300W长连接的压测。线上单机实际使用最高160W长连接,分两个实例。QPS的线上场景跟出口带宽、协议轻重程度、接入端网络状况及业务逻辑有关,但只要关闭影响I/O的因素,不通过加密的协议纯性能去抓数据,QPS可达2~5万,但如果加密较多,QPS会下降。
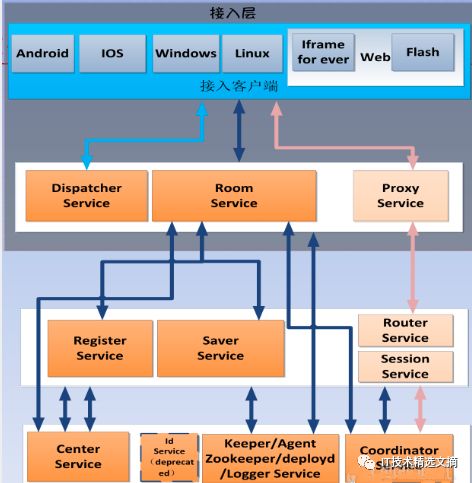
另外,该消息推送系统重逻辑,整个系统由图片交互完成整个推送功能。接入端流程主要由客户端提供的各SDK接入Dispatcher服务器,在客户端进行选入时,会对Dispatcher服务器上传一些数据,根据传入的相关状况进行选入服务,将Room Service的IP或者域名传送给相关客户端,客户端基于当前网络情况对IP做策略的缓存,再通过对缓存IP与当前的Room Service做一个长连接。
Room Service在未做业务和架构拆解之前逻辑非常重,基本要与后面所有的服务进行递进,而它本身还要承载上百万的长连接业务。这种Service的逻辑主要重在内部通信、外部通信及对外连接的交互上。
首先,用户接入长连接,长连接Room Service需要对用户的身份进行验证,还要支持公司各种产品、安全相关、回调相关业务的认证接入;其次,身份接受认证之后,要做后端的连接者Service,即内存存储做一个通信,将用户与他所在的Room和Room身份绑定(注册操作),单连接涉及到解绑、多次绑定、绑定多个用户等交互逻辑。


API接入层会有一个Center Service负责所有的App接入方,它们将通过Center Service做一些简单的认证,然后将消息发到集群内部。比如发一条单播给一个用户,先请求Register获取这个用户,Center获取到这个用户之后再与Router Service进行通信,获取注册的连接通道标识、服务器,然后与它进行通信再下发给长连接。Center Service比较重的工作如全国广播,需要把所有的任务分解成一系列的子任务,然后在所有的子任务里调用连接的Service、Saver Service获取在线和离线的相关用户,再集体推到Room Service,所以整个集群在那一瞬间压力很大。可见,整个系统通讯较复杂,架构拆解之后也有很重的逻辑。
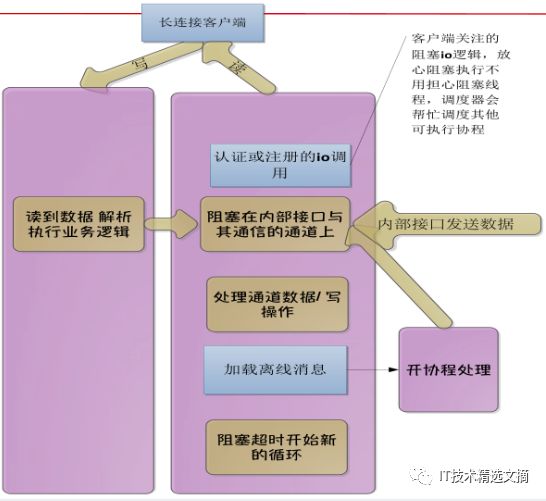
虽然它逻辑重,但程序基本是线性的。从上图可以看出,基本任务相当于对每个用户开协程。所有逻辑都是在两个循环内完成(如注册操作)。客户端要显示,该阻塞就阻塞。通常情况下,心跳响应要及时,心跳的主循环中要省心跳,这时要用非阻塞I/O,通过通道的方式集中控制、管理、操作,然后通过异步的方式再回来,整个循环的关键是要及时响应ping包的服务。因此,逻辑再好,基本上集中在两个协程之内,而且无论什么时侯读代码,它都是线性的。
3、Go与C开发体会的对比

当遇到瓶颈又不知道能用Go提高多少效率时,他们写了C语言的开发。用C语言要用Oneloop per thread原则,根据业务数据处理需求开一定量线程,由于每个线程的I/O不能阻塞,所以要采用异步I/O的方式,每个线程有一个eventloop。一个线程为几万用户服务会产生一个问题,要记录一个用户当前所在的状态(注册、加载消息、与Coordinator通信)并做维护,这时,写程序是在做状态的排列组合,如果程序是别人写的,就需要考虑新加的逻辑是否会影响之前排列组合的运行,是否能让之前正常运行的程序继续运行。所以,宁可使用Go语言通过优化之后性能降低一点,拆解架构让机制减少,也不能为了用C语言而写特别重的逻辑。
4、实践中遇到的挑战
遭遇的挑战:

遇到的问题:

5、可行的应对方式
1经验一
Go语言程序开发需要找到一种平衡,既利用协程带来的便利性又做适当集中化处理。当每一次请求都变成一个协程,那在每个协程之内是否有必要再去开一些协程解耦逻辑,这时使用任务池集中合并请求、连接池+Pipeline利用全双工特性提高QPS。
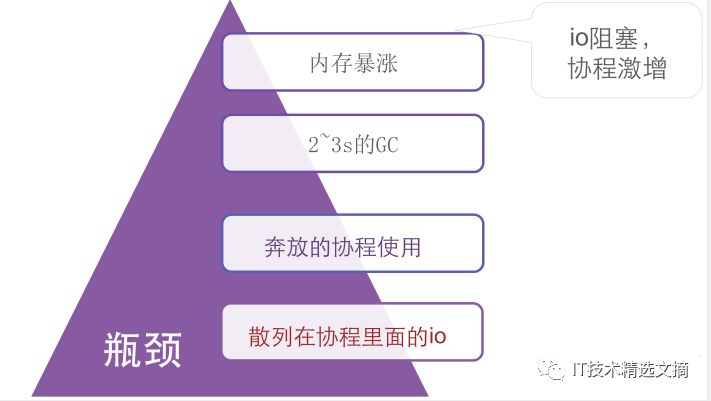
首先要改造通信库,在程序里直接调用一个I/O操作注册执行,不能用短连接。因为对系统性能参数做过优化,正常通讯的时候约10万个端口可用。虽然短连接通信本身没问题,但短连接会创建很多对象(编码Buffer、解码Buffer、服务端的编码Buffer、 Request对象、Response对象、服务端的Request对象、Response对象)。短连接还用了开源的RPC,用各种Buffer都会出现问题。
通信库做一版的迭代,第二版则用了一些值,相当于表面上阻塞的调用了I/O,但实际从连接池拿出一个请求Request,供服务端享用,然后拿到Response再把连接放回去。这样做很多资源(包括Buffer、Request、Response,Sever端、Client端)连接池可以复用。对所有对象做内存复用,但它实际是在线的,所以拿出一个连接往里面写数据等服务端响应,响应后再读取,这时服务端响应时间决定连接的占用时间。第三版要写一个Pipeline操作,Pipeline会带来一些额外的开销,这里的Pipeline指连接是全双工复用的,任何人都可以随时往里写,请求之后阻塞在相关通道上面,由底层去分配一个连接,最后这个连接释放留给其它人去写。整个可以用TCP的全双工特性把QPS跑满,经过集中化处理,RPC库会达到较好的效应,创业公司可以选择GRPC。对于像360消息推送的系统,如果不能控制每个环节就会出问题。如果代码不自己写,别人的代码再简单用起来也会非常困难,如用RPC判断错误类型、调整错误类型这种最简单的情况,返回的Error是个字符串,因此要分析到底是编码问题、网络问题,还是对波返回一个错误信息需要处理,这时业务逻辑层要对RPC做一个字符串的判断。

2经验二
Go语言开发追求开销优化的极限,谨慎引入其他语言领域高性能服务的通用方案。
主要关注内存池、对象池适用于代码可读性与整体效率的权衡。这种程序一定情况下会增加串行度。用内存一定要加锁,不加锁用原理操作有额外的开销,程序的可读性会越来越像C语言,每次要malloc,各地方用完后要free,free之前要reset,各种操作做完之后会发现问题。这里的优化策略是仿达达做的数据框架,然后做了一个仿Memorycache形式的内存池。
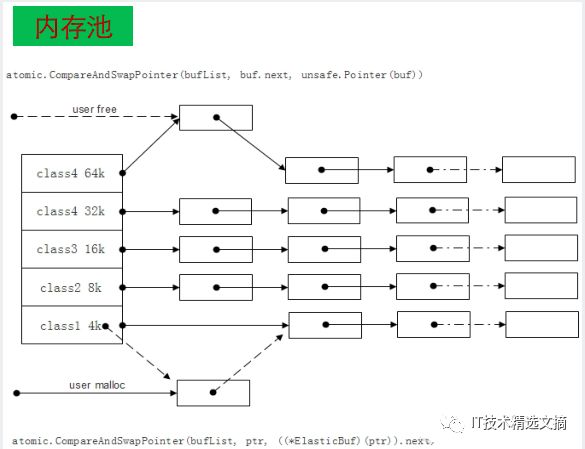
上图左边的数组实际上是一个列表,这个列表按大小将内存分块。在协议解期时不知道长度,需要动态计算长度,所以申请适配的大小不够,就把这块还回去再申请一个Bucket。加入内存池之后减少了一些机器的开销,但是程序的可读性严重降低。
对象池策略本身有一个Sync库的API,在申请对象的时候要做清理操作,包括通道的清理,防止有障数据,增加开销。其实CPU大部分时间是空闲的,只有在广播的时候比较高,加上这两个策略之后,程序的串行度提高,内存的机器时间加长,但QPS不一定上升。
6、具有Go特色的运维
依托Go语言做一些常规的运维工作需要一些常识。线上处理就是看一下协程在F上是否有协程疏漏、高阻塞。因为有时看不到,所以他们对线上的实例监控做了一个统一的管理和可视化操作。Go语言提供配套的组合工具做一些更方便开发调试的机制。第一点是Profiling可视化,可以从中发现历史记录,出现问题时的峰值、协程数,可以比较两次上线完之后进程到了什么样的状态。比如运维的时候做一个分析群,然后把一部分的产品分到一个单独集群上,发现这个集群总比另一个集群多4到5个内存(程序是同一个),直接打开图就非常明了地显示。在一个Buffer中,这个集群明显较大的原因是两年前做了一个策略防止重新拷贝。当时写的逻辑针对每个产品开Buffer,开了一百万。这个集群就是一个开源平台,上面有上万个App,数值提供的时候明显不是同一个图,它的Buffer更大。各种问题都可以通过对Go语言提供的Profiling、协程、本机机器时间、相关数量进行监控。

另外,通讯可视化,长连接调用基本是RPC调用,RPC库、Redis的库、mysql库给力,整个系统就可控。所以要对RPC库、Redis的库做各种代码内嵌,要统计它的QPS、网络带宽占用、各种出错情况。然后再通过各种压测手段,发现要做的优化对性能是否有影响。如果一个系统不可评估就无法优化,而如果可评估就会发现一些潜在的问题。通讯可视化是在RPC库和Redis库植入自己的代码。其实选择RPC库并不重要,重要的是能够对它改造、监控。
可视化还可以做压测。由于压测不能出实时的数据,可选一百台机器,对一台进行压测,通过后台看各种性能参数,然后通过RPC库的结构判断各数据。压测完后,每一个压测的进程要汇总统计数据,业务的QPS数量、协议版本、连接建立成功的时间和每秒钟建立连接数量,这些细节的性能参数决定系统的潜在问题,因此,压测平台最好要做统计数据的功能。360的团队做了一个简单的压测后台,可以选定一些机器进行压测。一台机器压测由于网络问题和机器本身的CPU线路无法测出问题。因此,压测时最好选十几台机器,每台机器开10段连接做压测。
运维对线上进行拆分,可以减少机器时间,但运维压力变大。通过开协程的方式解决相当于把这台机器转嫁到各个进程上,虽然机器时间短,但频繁次数多,所以问题并未得到解决。开多进程可以节省时间,但卡顿时间和体量变成渐进性。系统根据使用的各种资源不同可做一个横向拆分,按业务拆分(助手、卫士、浏览器)、功能拆分(push、聊天、嵌入式产品)和IDC拆分(zwt、bjsc、bjdt、bjcc、shgt、shjc、shhm、Amazon Singapore),拆解后带来管理成本,引入(ZooKeeper+deployd)/(Keeper+Agent)对各节点进行管理。
正常情况下,运维都采用ZooKeeper管理各个进程的动态配置文件。第二部分相当于Profiling数据,用后台去各个进程中请求,实时监控各个接口,通讯录的数据也通过后台进行请求,这时Keeper的节点要配置,后台也要配置。这种功能可以抽象一下,理论上期望客户端有个SDK,中心节点有个Keeper,然后可以对配置文件进行管理,对Profiling、自己写的各种库的信息进行收集,再汇总,放到本地数据或者文件夹,通过接口对后台提供服务。服务通过网络进行启动,管理层集中在Keeper上而不是在后台和Keeper上,所以Keeper的同步会考虑用一些开源的东西。360团队写了一些工具把正常的配置文件用Key-Value的形式支持一些Map结构,反序相当于写了一个Convert工具。剩下的用Profiling,相当于跟Keeper和节点进行通信,所以Profiling会很高。Keeper的启动相当于用一个Agent启动进程,然后指定Keeper中心节点端口把信息传过去,当Keeper正好配了这个节点就能把配置发过去,如果没有配就丢失。
以上是关于Go语言构建千万级在线的高并发消息推送系统实践的主要内容,如果未能解决你的问题,请参考以下文章
使用kafka消息队列中间件实现跨进程,跨服务器的高并发消息通讯