Let's Go | Go语言初探:函数式编程
Posted QichaoOnAir
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Let's Go | Go语言初探:函数式编程相关的知识,希望对你有一定的参考价值。

Author:Qichao Ying

Let's Go
(二)
函数式编程
Go语言初探系列二,今天主要说说Go的函数式编程(封装、扩展、闭包),都是比较基本的内容。
前言:有小伙伴说(一)的逻辑太乱了,看完的感觉就两个:跟Java好像长差不多、有管道这么个东西。。。好吧~(所以说上一期是赶工的你们不要不信呀),那么这一期我花了更长的时间来整理逻辑,然后用更多的代码来尝试一下把事情讲清楚一些吧~ 还有小伙伴说我很闲,不务正业,呵呵呵。。。(没有吧,白天还是要干正经事的)


封装

/* 这种在“最近更新—七夕”里出现的素材我这单身dog只能用在Go语言上了,气啊(╯▔皿▔)╯ */
先看看Go里的面向“对象”,也就是“Class”
——很遗憾Go只有struct。。
一看到struct,
又想起了当年被C语言支配的恐惧
。
。。
。。。
。。。。
。。。。。
。。。。。。
Go语言struct的地位跟Java里的class应当是比较接近的,至少到目前为止感觉如此。不过区别也是比较明显的,首先Go语言没有继承,也没有多态,只支持对函数做封装~《Go语言并发编程实战》作者说这是为了给程序员更大的自由,好吧,虽然会有一点不太适应。
这次就先不在channel里爬爬爬了,
说说不用并行计算的时候
直接上一道题来感受一下~
https://leetcode.com/problems/kth-largest-element-in-an-array/description/
这道题特别简单,给一个乱序的序列,返回里面第K大的数。当然了,像Arrays.sort这种函数是不让用的,也就是自己实现一下排序,排序中有很多算法必须要会的,所以这道题根本没有Medium的难度。一般我会选择Easy难度的用Go写写看,这两天发现一般也是可以比较轻松写出来的,所以这题也适合用来演示Go里struct的封装。
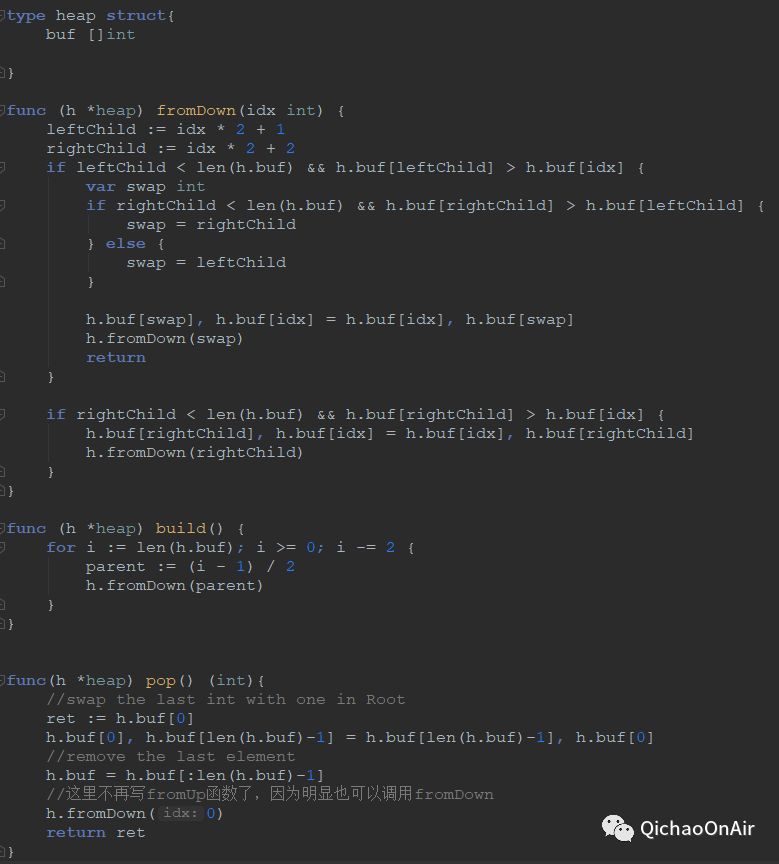
搞不懂人家公共号上面可以左右滑动的文本框是怎么实现出来的,反正今天在秀米上找了好久没找到这样的东西,滑动布局手动输入文字是可以拖动的,但我从GoLand上把代码粘贴进来就又给我强制换行了,无语。。。所以只好截图,凑合着看一看啦~
上面就实现了一下堆排序,下面这个main函数可以作为程序的入口~只要手动输入nums的值就可以了~堆排序是最常选择的排序,唯一不足之处可能就是稳定性不好了。这里的稳定指的是如果a原本在b前面,而a=b,那么排序之后a仍然在b的前面(同样条件的人没法“弯道超车”了)。
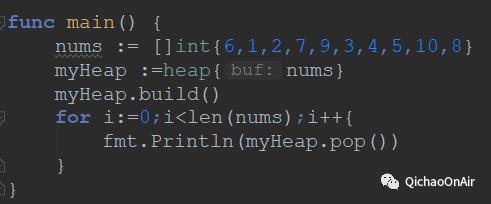
而且即使传递了指针进来,也不需要 p->..... 这样的写法,编译器在编译p时,自己会在指针、值中进行切换,比如上面 h.buf 也是可以直接访问那个struct数组的。
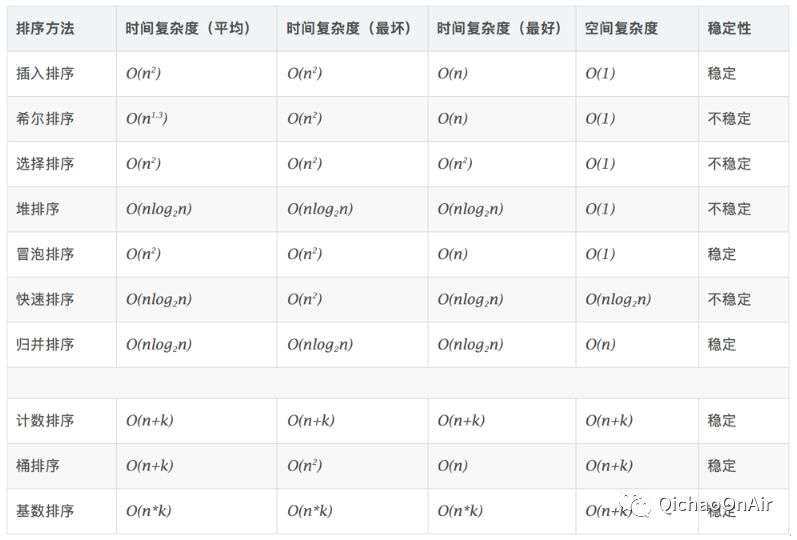
下面这张表顺便就温习一下比较重要的算法~上面7个方法是通过比较来决定元素间的相对次序,由于其时间复杂度“暂时”不能突破O(nlogn),因此称为非线性时间比较类排序。下面3个稍微小众一点点,它们不通过比较来决定元素间的相对次序,可以突破基于比较排序的时间下界,以线性时间运行,因此称为线性时间非比较类排序。

Go语言在运行这件事上做得很好,Java能从IDE直接给结果的东西要写在static void main里面,如果要调试,只能要么需要把所有待调试函数全加上static,变成静态方法,要么就要把要调试的东西包装在另一个class里,让main去生成一个对象,再去调用里面的方法,就会花一些额外的时间。Go就不需要,只要包名是main,有func main()就可以直接跑啦~
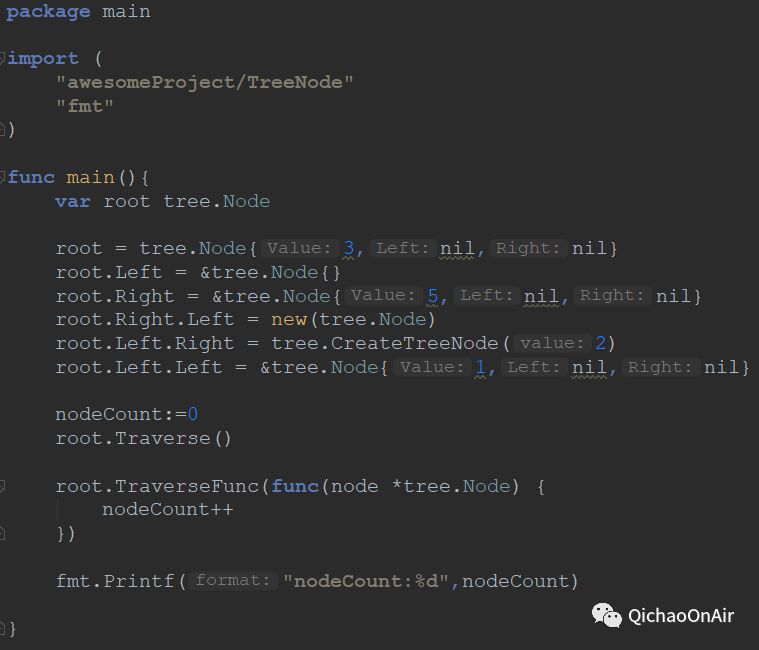
好的~那么这个例子告一段落~不知道是否比(一)讲得清楚一些些。。那么再上一个例子~~这个例子是要在Go里面实现自己的binary TreeNode。注意啦,struct名如果定义为大写,那么同project下其他包也可以调用它,创建它的实例,但如果是小写,呵呵呵。。。

这个struct的定义跟我们常规的Java定义树节点一致,两个自身类型的子节点和自己的值。下面的Traverse和TraverseFunc一起完成了中序遍历的任务。
注意这里的Traverse向TraverseFunc传递了一个匿名函数,TraverseFunc将接收到的这个函数命名为f,并在希望执行这个函数的时候可以直接调用 f(node)即可!在Go里面,函数绝对是“一等公民”,而不是像Java一样必须要依附在类里面或者对象里面,也就是说,函数不依赖谁了,可以自己就作为一个变量。当然了函数自己成为变量,不能把后面参数传递的那个()也带上,不然就成为传递这个函数的运行结果了。

在(一)里,应该还记得goroutine的定义是在一个函数前面添加go关键字,(一)里主要的做法是给一个匿名函数附上go关键字即可,因为这些函数都是进协程的,名字也不是很重要,当然了,在这个例子里,
go node.Left.TraverseFunc(f)
这样的写法肯定也是没问题的,但问题是由于goroutine之间的“异步关系”,这句语句加了go后,就不一定在 f(node)之前执行了,也就导致最终输出错误。这跟在一句语句前面开了一个线程的道理一样。
接下去,在另一个带main函数的main包里调用这个中序遍历,得到正确的遍历结果~
扩展
没了继承,好不方便啊。。
好在Go可以用扩展来完成继承的任务~
看如下代码,上面我们有了一个可以给其它包调用的Tree Node结构体,但里面没有实现后序遍历,自己去这么定义
func (node *tree.Node) Traverse()
编译也不给过,那就先用一下扩展的方法,定义一个更大的struct把它包起来
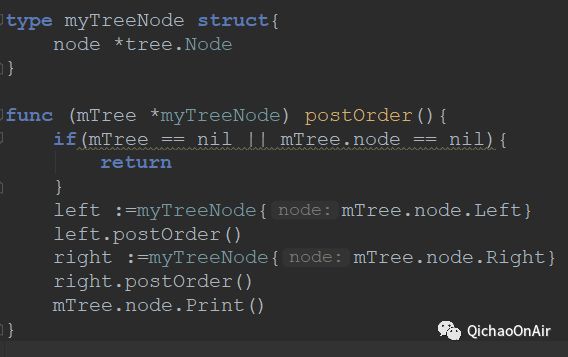
这样,我们就不仅可以自己实现postOrder这个函数,还可以通过mTree.node.xx来访问别人包里定义的内容,就这样使用而言,其实跟继承也很接近~不过这样的扩展也完全可以让一个struct包含多个其它struct的指针,然而Go就免了“组合”、“多继承”这种概念,好像很一目了然哦。
闭包
对于写Java的人,这个概念应当生疏一些了,Java 1.8中的一个新特性是实现了Function<E,E>的接口,这样可以把一个函数模拟成接口,也就可以模拟“闭包”。毕竟,Java 1.8开始才给出了lambda表达式,可以用一下匿名函数,个人认为那主要还是因为“函数在Java面向对象的语言里地位极低”的原因导致的。
然而讲到函数式编程不讲闭包,就跟耍流氓没什么区别。。所以只能靠残存的记忆、C++的浅陋认识和这两天极快的自学,大致来讲述一下闭包是怎么一回事,主要是要干什么。
还是来看例子,下面是闭包“老祖宗”应用之一——斐波那契数列的Go实现~
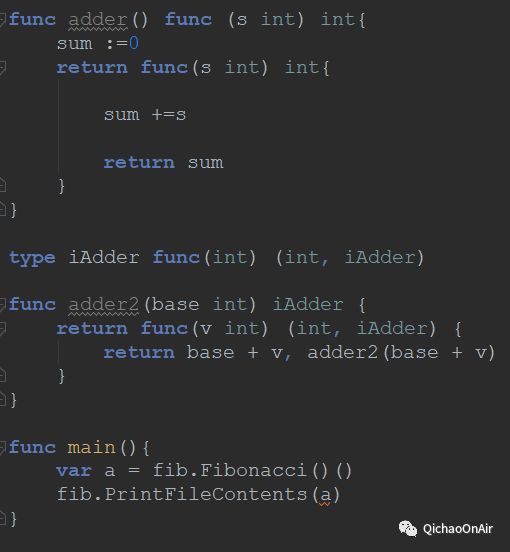
这串代码里有些东西是有点剧透的(主要是这里“莫名其妙”蹦出来一个Read函数,还有error),今天不会讲到。我们关心的闭包主要就是开头的7行内容。在我看来,“闭包”要做的就是一件事:自己维护自己。“闭”字说明了闭包里的东西外界是访问不到的(或者说不能直接访问到),“包”字说明了intGen这个函数不仅仅返回一个function这么简单,它还有自己的一个“小包裹”,又是只归自己管理的。
这样做的好处有很多,我们调用Fibonacci()函数,它会返回我们每次执行完不同的结果,然而外人没法直接查询a执行到了几,也就是说,内部运行状态被很好保护了起来,只给user提供一个结果。这当然还是很重要的。
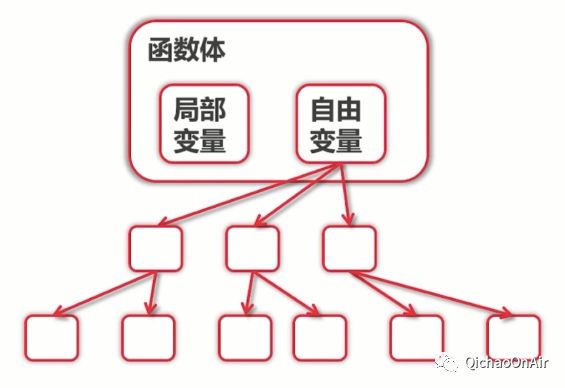
闭包的结构大致上就长这个样子,自由变量自己去相互连接,逐渐得到所有需要参与运算的变量,这样的话函数就自己维护了当前包的“状态”。
吃
饭
好了,今天内容就这些了~(三)中将要介绍的是Go语言的面向接口~如果你对Go语言感兴趣,请给我提一些建议让后面的分享能做得更好~
谢谢阅读~
打这么多字不容易,点赞支持一下呗~
以上是关于Let's Go | Go语言初探:函数式编程的主要内容,如果未能解决你的问题,请参考以下文章