go语言项目优化(经验之谈)
Posted Golang语言社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了go语言项目优化(经验之谈)相关的知识,希望对你有一定的参考价值。
我的课题主要分为以下三章,斗鱼在GO的应用场景,GO在业务中如何优化,我们在GO中踩过了哪些坑。
1 Go的应用场景
在斗鱼我们将GO的应用场景分为以下三类,缓存类型数据,实时类型数据,CPU密集型任务。这三类应用场景都有着各自的特点。
缓存类型数据在斗鱼的案例就是我们的首页,列表页,这些页面和接口的特点是不同用户在同一段时间得到的数据都是一样的,通常这些缓存类型数据的包都比较大,并且这些数据没有用户态,具有一定价值,很容易被爬虫爬取。
实时类型数据在斗鱼的案例就是视频流,关注数据,这些数据的特点是每次请求获取的数据都不一样。并且容易因为某些业务场景导流,例如主播开播提醒,或者某个大型赛事开赛,会在短时间内同时涌入大量用户,导致服务器流量陡增。
CPU密集型任务在斗鱼的案例就是我们的列表排序引擎。斗鱼的列表排序数据源较多,算法模型复杂。如何在短时间算完这些数据,提高列表的导流能力对于我们也是一个比较大的挑战。
针对这三种业务场景如何做优化,我们也是走了不少弯路。而且跟一些程序员一样,容易陷入到特定的技术和思维当中去。举个简单的例子。早期我们在优化GO的排序引擎的时候,上来就想着各种算法优化,引入了跳跃表,归并排序,看似优化了不少性能,benchmark数据也比较好看。但实际上排序的算法时间和排序数据源获取的时间数量级差别很大。优化如果找不对方向,业务中的优化只能是事倍功半。所以在往后的工作中,我们基本上是按照如下图所示的时间区域,找到业务优化的主要耗时区域。
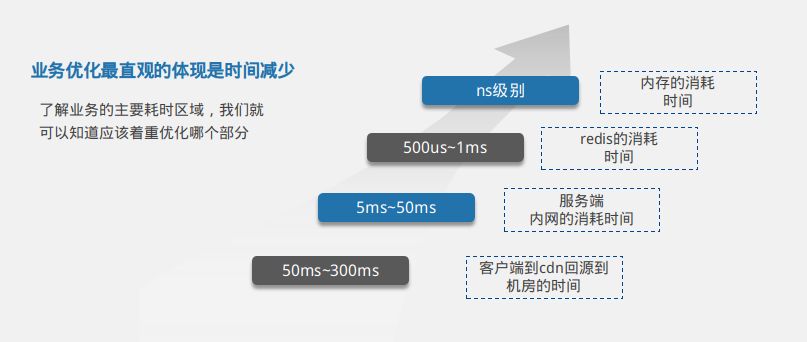
从图中,我们主要列举了几个时间分布,让大家对这几个数值有所了解。从客户端到CDN回源到机房的时间大概是50ms到300ms。机房内部服务端之间通信大概是5ms到50ms。我们访问的内存数据库redis返回数据大概是500us到1ms。GO内部获取内存数据耗时ns级别。了解业务的主要耗时区域,我们就可以知道应该着重优化哪个部分。
2 Go的业务优化
2.1 缓存数据优化
对于用户访问一个url,我们假定这个url为/hello。这个url每个用户返回的数据结构都是一样的。我们通常有可能会向下面示例这样做。对于开发而言,代码是最直观最可控的。但这种方式通常只是实现功能,但并不能够提升用户体验。因为对于缓存数据我们没有必要每次让CDN回源到源站机房,增加用户访问的链路时间。
// Echo instance
e := echo.New()
e.Use(mw.Cache) // Routers
e.GET("/hello", handler(HomeHandler))2.1.1 添加CDN缓存
所以接下来,对于缓存数据,我们不会用go进行缓存,而是在前端cdn进行缓存优化。CDN链路如下所示
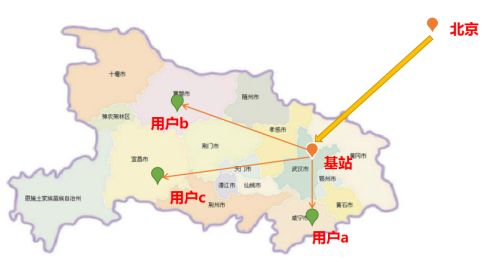
为了让大家更好的了解CDN,我先问大家一个问题。从北京到深圳用光速行驶,大概要多久(7ms)。所以如图所示,当一个用户访问一个缓存数据,我们要尽量的让数据缓存在离用户近的CDN节点,这种优化方式称为CDN缓存优化。通过该技术,CDN节点会把附件用户的请求,聚合到一起统一回源到源站机房。这样可以不仅节省机房流量带宽,并且从物理层面上减少了一次链路。使得用户可以更快的获取到缓存数据。
为了更好的模拟CDN的缓存,我们拿nginx+go来描述这个流程。nginx就相当于图中的基站,go服务就相当于北京的源站机房。
nginx 配置如下所示:
server { listen 8088; location ~ /hello { access_log /home/www/logs/hello_access.log; proxy_pass http://127.0.0.1:9090; proxy_cache vipcache; proxy_cache_valid 200 302 20s; proxy_cache_use_stale error timeout invalid_header updating http_500 http_502 http_503 http_504 http_403 http_404; add_header Cache-Status "$upstream_cache_status";
}
}go 代码如下所示
package main
import ( "fmt"
"io"
"net/http")
func main() {
http.Handle("/hello", &ServeMux{})
err := http.ListenAndServe(":9090", nil) if err != nil {
fmt.Println("err", err.Error())
}
}
type ServeMux struct {
}
func (p *ServeMux) ServeHTTP(w http.ResponseWriter, r *http.Request) {
fmt.Println("get one request")
fmt.Println(r.RequestURI)
io.WriteString(w, "hello world")
}启动代码后,我们可以发现。
第一次访问
hello,nginx和go都会收到请求,nginx的响应头里cache-status中会有个miss内容,说明了nginx请求穿透到go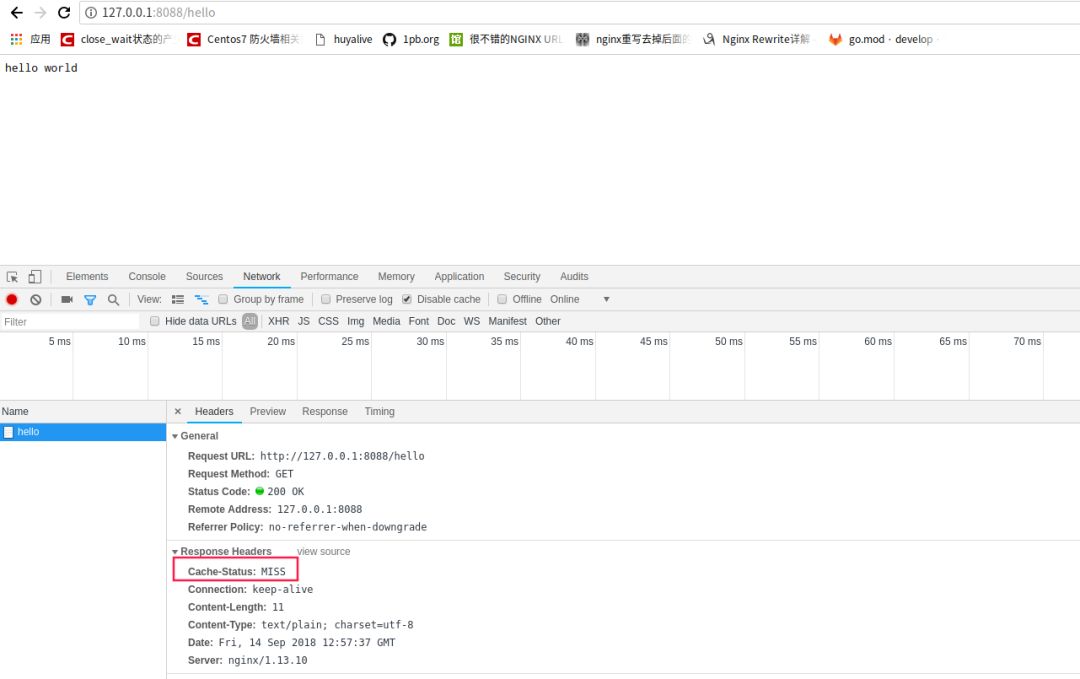

第二次再访问
hello,nginx会收到请求,go这个时候就不会收到请求。nginx里响应头里cache-status会与个hit内容,说明了nginx请求没有回源到go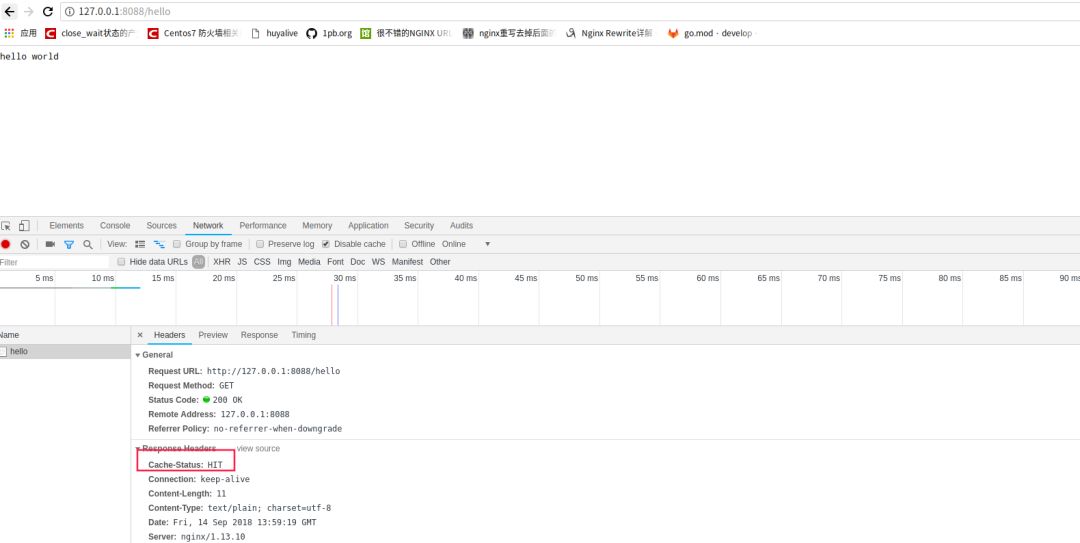
顺带提下nginx这个配置,还有额外的好处,如果后端go服务挂掉,这个缓存url
hello任然是可以返回数据的。nginx返回如下所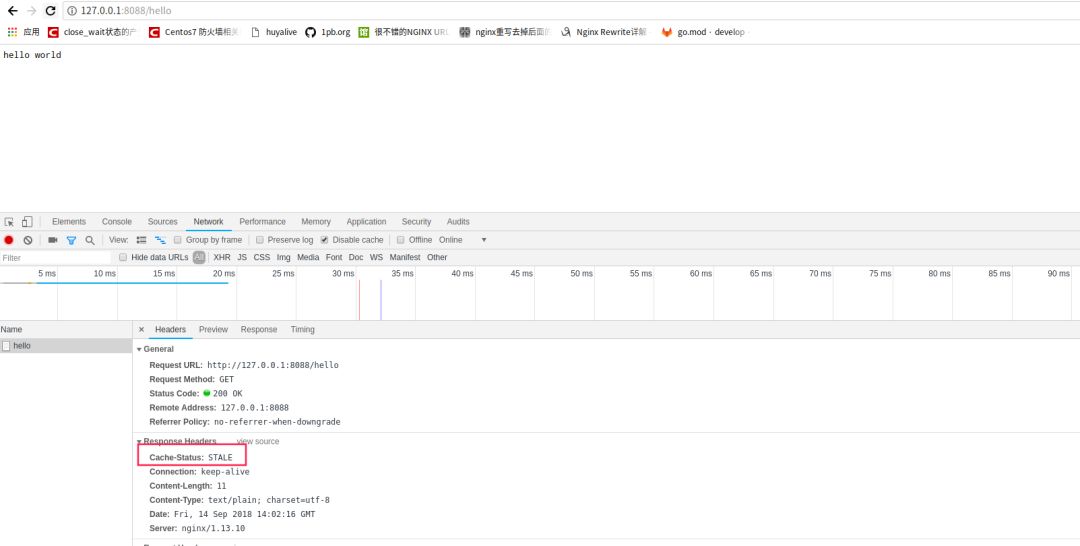
2.1.2 CDN去问号缓存
正常用户在访问hellourl的时候,是通过界面引导,然后获取hello数据。但是对于爬虫用户而言,他们为了获取更加及时的爬虫数据,会在url后面加各种随机数hello?123456,这种行为会导致cdn缓存失效,让很多请求回源到源站机房。造成更大的压力。所以一般这种情况下,我们可以在CDN做去问号缓存。通过nginx可以模拟这种行为。nginx配置如下:
server { listen 8088; if ( $request_uri ~* "^/hello") { rewrite /hello? /hello? break;
} location ~ /hello { access_log /home/www/logs/hello_access.log; proxy_pass http://127.0.0.1:9090; proxy_cache vipcache; proxy_cache_valid 200 302 20s; proxy_cache_use_stale error timeout invalid_header updating http_500 http_502 http_503 http_504 http_403 http_404; add_header Cache-Status "$upstream_cache_status";
}
}2.1.3 大流量上锁
之前我们有讲过如果突然之间有大型赛事开播,会出现大量用户来访问。这个时候可能会出现一个场景,缓存数据还没有建立,大量用户请求仍然可能回源到源站机房。导致服务负载过高。这个时候我们可以加入proxy_cache_lock和proxy_cache_lock_timeout参数
server { listen 8088; if ( $request_uri ~* "^/hello") { rewrite /hello? /hello? break;
} location ~ /hello { access_log /home/www/logs/hello_access.log; proxy_pass http://127.0.0.1:9090; proxy_cache vipcache; proxy_cache_valid 200 302 20s; proxy_cache_use_stale error timeout invalid_header updating http_500 http_502 http_503 http_504 http_403 http_404; proxy_cache_lock on; procy_cache_lock_timeout 1; add_header Cache-Status "$upstream_cache_status";
}
}2.1.4 数据优化
在上面我们还提到斗鱼缓存类型的首页,列表页。这些页面接口数据通常会返回大量数据。在这里我们拿Go模拟了一次请求中获取120个数据的情况。将slice分为三种情况,未预设slice的长度,预设了slice长度,预设了slice长度并且使用了sync.map。代码如下所示。这里面每个goroutine相当于一次http请求。我们拿benchmark跑一次数据
package slice_testimport ( "strconv" "sync" "testing")// go test -bench="."type Something struct {
roomId int
roomName string}func BenchmarkDefaultSlice(b *testing.B) {
b.ReportAllocs() var wg sync.WaitGroup for i := 0; i < b.N; i++ {
wg.Add(1) go func(wg *sync.WaitGroup) { for i := 0; i < 120; i++ {
output := make([]Something, 0)
output = append(output, Something{
roomId: i,
roomName: strconv.Itoa(i),
})
}
wg.Done()
}(&wg)
}
wg.Wait()
}func BenchmarkPreAllocSlice(b *testing.B) {
b.ReportAllocs() var wg sync.WaitGroup for i := 0; i < b.N; i++ {
wg.Add(1) go func(wg *sync.WaitGroup) { for i := 0; i < 120; i++ {
output := make([]Something, 0, 120)
output = append(output, Something{
roomId: i,
roomName: strconv.Itoa(i),
})
}
wg.Done()
}(&wg)
}
wg.Wait()
}func BenchmarkSyncPoolSlice(b *testing.B) {
b.ReportAllocs() var wg sync.WaitGroup var SomethingPool = sync.Pool{
New: func() interface{} {
b := make([]Something, 120) return &b
},
} for i := 0; i < b.N; i++ {
wg.Add(1) go func(wg *sync.WaitGroup) {
obj := SomethingPool.Get().(*[]Something) for i := 0; i < 120; i++ {
some := *obj
some[i].roomId = i
some[i].roomName = strconv.Itoa(i)
}
SomethingPool.Put(obj)
wg.Done()
}(&wg)
}
wg.Wait()
}得到以下结果。可以从最慢的12us降低到1us。
2.2 实时数据优化
2.2.1 减少io操作
上面我们提到了在业务突然导流的情况下,我们服务有可能在短时间内涌入大量流量,如果不对这些流量进行处理,有可能会将后端数据源击垮。还有一种情况在突发流量下像视频流这种请求如果耗时较长,用户在长时间得不到的数据,有可能进一步刷新页面重新请求接口,造成二次攻击。所以我们针对这种实时接口,进行了合理优化。
我们对于量大的实时数据,做了三层缓存。第一层是白名单,这类数据主要是通过人工干预,预设一些内存数据。第二层是通过算法,将我们的一些比较重要的房间信息放入到服务内存里,第三层是通过请求量动态调整。通过这三层缓存设计。像大型赛事,大主播开播的时候,我们的请求是不会穿透到数据源,直接服务器的内存里已经将数据返回。这样的好处不仅减少了IO操作,而且还对流量起到了镇流的作用,使流量平稳的到达数据源。
其他量级小的非实时数据,我们都是通过etcd进行推送
2.2.2 对redis参数调优
要充分理解redis的参数。只有这样我们才能根据业务合理调整redis的参数。达到最佳性能。maxIdle设置高点,可以保证突发流量情况下,能够有足够的连接去获取redis,不用在高流量情况下建立连接。maxActive,readTimeout,writeTimeout的设置,对redis是一种保护,相当于go服务对redis这块做的一种简单限流,降频操作。
redigo 参数调优
maxIdle = 30
maxActive = 500
dialTimeout = "1s"
readTimeout = "500ms"
writeTimeout = "500ms"
idleTimeout = "60s"2.2.3 服务和redis调优
因为redis是内存数据库,响应速度比较块。服务里可能会大量使用redis,很多时候我们服务的压测,瓶颈不在代码编写上,而是在redis的吞吐性能上。因为redis是单线程模型,所以为了提高速度,我们通常做的方式是采用pipeline指令,增加redis从库,这样go就可以根据redis数量,并发拉取数据,达到性能最佳。以下我们模拟了这种场景。
package redis_testimport ( "sync" "testing" "time" "fmt")// go testfunc Test_OneRedisData(t *testing.T) {
t1 := time.Now() for i := 0; i < 120; i++ {
getRemoteOneRedisData(i)
}
fmt.Println("Test_OneRedisData cost: ",time.Since(t1))
}func Test_PipelineRedisData(t *testing.T) {
t1 := time.Now()
ids := make([]int,0, 120) for i := 0; i < 120; i++ {
ids = append(ids, i)
}
getRemotePipelineRedisData(ids)
fmt.Println("Test_PipelineRedisData cost: ",time.Since(t1))
}func Test_GoroutinePipelineRedisData(t *testing.T) {
t1 := time.Now()
ids := make([]int,0, 120) for i := 0; i < 120; i++ {
ids = append(ids, i)
}
getGoroutinePipelineRedisData(ids)
fmt.Println("Test_GoroutinePipelineRedisData cost: ",time.Since(t1))
}func getRemoteOneRedisData(i int) int { // 模拟单个redis请求,定义为600us
time.Sleep(600 * time.Microsecond) return i
}func getRemotePipelineRedisData(i []int) []int {
length := len(i) // 使用pipeline的情况下,单个redis数据,为500us
time.Sleep(time.Duration(length)*500*time.Microsecond) return i
}func getGoroutinePipelineRedisData(ids []int) []int {
idsNew := make(map[int][]int, 0)
idsNew[0] = ids[0:30]
idsNew[1] = ids[30:60]
idsNew[2] = ids[60:90]
idsNew[3] = ids[90:120]
resp := make([]int,0,120) var wg sync.WaitGroup for j := 0; j < 4; j++ {
wg.Add(1) go func(wg *sync.WaitGroup, j int) {
resp = append(resp,getRemotePipelineRedisData(idsNew[j])...)
wg.Done()
}(&wg, j)
}
wg.Wait() return resp
}
从图中,我们可以看出采用并发拉去加pipeline方式,性能可以提高5倍。
redis的优化方式还有很多。例如
1.增加redis从库2.对批量数据,根据redis从库数量,并发goroutine拉取数据3.对批量数据大量使用pipeline指令4.精简key字段5.redis的value解码改为msgpack3 GO的踩坑经验
3.1 指针类型串号
3.2 多重map上锁问题
3.3 channel使用问题
4 相关文献
坑踩得多,说明书看的少。
https://stackoverflow.com/questions/18435498/why-are-receivers-pass-by-value-in-go/18435638
以上问题都可以在相关文献中找到原因,具体原因请阅读文档。
When are function parameters passed by value?
As in all languages in the C family, everything in Go is passed by value. That is, a function always gets a copy of the thing being passed, as if there were an assignment statement assigning the value to the parameter. For instance, passing an int value to a function makes a copy of the int, and passing a pointer value makes a copy of the pointer, but not the data it points to. (See a later section for a discussion of how this affects method receivers.)
Map and slice values behave like pointers: they are descriptors that contain pointers to the underlying map or slice data. Copying a map or slice value doesn’t copy the data it points to. Copying以上是关于go语言项目优化(经验之谈)的主要内容,如果未能解决你的问题,请参考以下文章