Go 语言调度: goroutine 调度器
Posted Golang语言社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Go 语言调度: goroutine 调度器相关的知识,希望对你有一定的参考价值。
介绍
上一篇文章我对操作系统级别的调度进行了讲解,这对理解 Go 语言的调度器是很重要的。这篇文章,我将解释下 Go 语言的调度器是如何工作的。依旧专注在上层抽象的基本概念上,不深入到具体如何实现的,因为 Go 调度器是非常复杂的而且内部机制的一些细节是无关紧要的。重要的是我们要对 goroutine 是如何被调度和工作的有一个简单的心理模型。这对我们做工程决策时有很大的帮助。
程序启动
当你的 Go 程序启动之初,它会被分配一个逻辑处理器(P),这是为这台机器定义的一个虚拟 CPU Core。如果你的 CPU 的每个核带有多个hardware thread(Hyper-Threading),每一个 hardware 都会对应 Go 语言中的一个虚拟 core。为了更好的理解这一点,看一看我的 macbook pro 的配置。

硬件配置
可以看见我有一个 4 core 处理器。但这里没有给出的是一个物理 core 有多少个 hardware thread。Intel Core i7 处理器拥有 Hyper-Threading,表示一个 core 上可以同时跑 2 个线程。这就表示 Go 程序里有 8 个虚拟 core(P) 可以使用,来让系统线程并行。
来测试一下:
1package main
2
3import (
4 "fmt"
5 "runtime"
6)
7
8func main() {
9
10 // NumCPU returns the number of logical
11 // CPUs usable by the current process.
12 fmt.Println(runtime.NumCPU())
13}
当我在自己的机器上运行这个程序, NumCPU() 函数的结果是 8。我机器上运行的任何一个 Go 程序均会有 8 个 P 可以使用。
每一个 P 会被分配一个系统线程(M)。这个 M 会被操作系统调度,操作系统仍然负责将线程(M)放到一个 CPU Core 上去执行。这意味着当我在我的机器上运行程序,我有 8 个线程可以使用去执行我的操作,每个线程都被绑定上了一个独立的 P。
每一个 Go 程序也被赋予了一个初始的 goroutine(G),它是 Go 程序的执行路径。一个 Goroutine 本质上就是一个 Coroutine,只不过因为在 Go 语言里,就改了个名字。你可以认为 Goroutine 是应用级别的线程,它在很多方面跟系统的线程是相似的。就像系统线程不断的在一个 core 上做上下文切换一样,Goroutine 不断的在 M 上做上下文切换。
最后一个难题就是运行队列。在 Go 调度器中有 2 个不同的执行队列:全局队列(Global Run Queue, 简称 GRQ)和本地队列(Local Run Queue,简称 LRQ)。每一个 P 都会有一个 LRQ 来管理分配给 P 上的 Goroutine。这些 Goroutine 轮流被交付给 M 执行。GRQ 是用来保存还没有被分配到 P 的 Goroutine。会有一个逻辑将 Goroutine 从 GRQ 上移动到 LRQ 上,这个我们后面讨论。
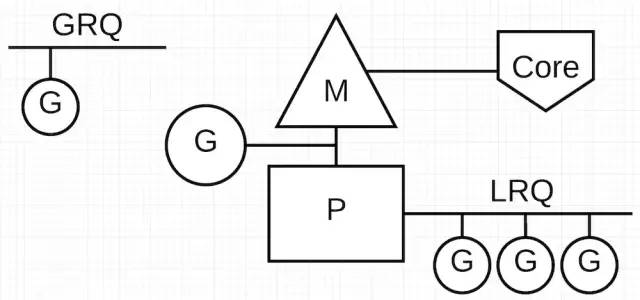
M,P,G 的关系
合作调度
正如上一篇文章讨论的,系统调度器的行为是抢占式的。本质上就意味着你不能够预测调度器将会做什么。系统内核决定了一切,而这一切都是不可确定的。运行在系统上的应用无法控制内核中的调度逻辑,除非使用互斥锁之类的操作。
Go 调度器是 Go 运行时的一部分,Go 运行时被编译到了你的程序里。这就表示 Go 调度器是运行在用户态的,在内核之上。当前版本的 Go 调度器实现并不是抢占式的,而是一个协同调度器。这就意味着调度器需要明确定义用户态事件来指定调度决策。
非抢占式调度器的精彩之处在于,它看上去是抢占式的。你不能预知 Go 调度器将会做什么。因为调度器的调度决策权并没有交给开发者,而是在运行时里。
Goroutine 状态
就像线程,Goroutine 也拥有同样的 3 个高级状态。这决定了他们在 Go 调度器中扮演的角色。一个 Goroutine 有 3 中状态:阻塞态,就绪态,运行态
阻塞态: 这表示 Goroutine 被暂停了,要等待一些事情发生了才能继续。有可能是因为要等待系统调用或者互斥调用(atomic 和 mutex 操作)。这些情况导致性能不佳的根因。
就绪态: 这代表 Goroutine 想要一个 M 来执行分配给它的指令。如果你有很多 Goroutine 都需要 M,那么 Goroutine 就需要等较长的时间。并且,每个 Goroutine 被分配的执行时间也就更短了。这种情况也会导致性能下降。
运行态:这表示 Goroutine 被交给了一个 M 执行,正在执行它的指令。这是每个人都希望的。
上下文切换
Go 调度器需要有明确定义的用户态事件和代码安全点,来实现切换操作。这些事件和安全点通过函数调用表现的。函数调用对 Go 调度器是至关重要的。今天(Go1.11或更低版本),如果你运行一个死循环,循环内不做任何函数调用,你将在进程调度和垃圾回收上出现延迟;因为它没有给调度器机会对它进行切换。函数调用在合理的范围内发生是至关重要的。
注意: 对于 1.12 版本有一个建议,在 Go 调度器中增加抢占式调度机制,来允许高速循环被抢占。
有 4 种事件会引起 Go 程序触发调度。这不意味着每次事件都会触发调度。Go 调度器会自己找合适的机会。
1、使用关键字 go
2、垃圾回收
3、系统调用/
4、同步互斥操作,也就是 Lock() , Unlock() 等
使用 go 关键字
关键字 go 是用来创建 Goroutine 的,一旦一个新的 Goroutine 被创建了,它就会引起 Go 调度器进行调度。
垃圾回收
因为 GC 操作是使用自己的一组 Goroutine 来执行的,这些 Goroutine 需要一个 M 来运行。所以 GC 会导致调度混乱。但是,因为调度器是知道 Goroutine 要做什么的,所以它可以做出明智的决策。其中一个明智的决策是,在 GC 过程中,暂停那些需要访问堆空间的 Goroutine,运行那些不需要访问堆空间的。
系统调用
如果一个 Goroutine 执行了系统调用,就会导致 Goroutine 把 M 给阻塞了(就是运行这个 Goroutine 的 M 进入了阻塞态),有时调度器有能力把 Goroutine 从 M 上拿走,把一个新的 Goroutine 放到这个 M 上;但有时候新的 M 需要被创建出来,来保证 P 队列中其他的 Goroutine 能被执行。这块内容后面会详细说明。
同步互斥
如果 atomic, mutex, 或者 channel 操作 导致了 Goroutine 阻塞。调度器可以切换一个新的 Goroutine 去执行。一旦 Goroutine 在此可以执行了(进入就绪态)。它会被重新放到队列中,最终被 M 执行。
异步系统调用
如果你的操作系统有能力异步处理系统调用,那么 network poller 可以更有效的来完成系统调用。这方面在 kqueue(MacOS),epoll(Linux) 或 iocp(Windows) 中都有不同方式的实现。
现在我们用的大多数操作系统,在网络调用上都是可以被异步执行的。这就是 network poller 名字的由来,因为他的主要用途就是处理网络请求的。通过使用 network poller 完成网络系统调用,调度器可以避免 Goroutine 在执行系统调用时把 M 阻塞住。这使得 M 可以去运行 P 的 LRQ 中其他的 Goroutine,而不需要再创建一个新的 M。这就减少了 OS 层面上的负载。
理解它是如何运作的最好方式就是通过例子。
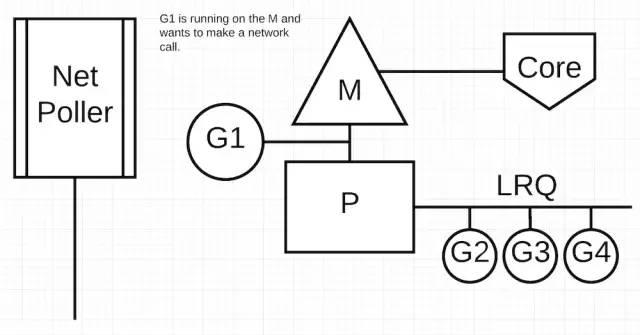
上图展示了我们基础的调度轮廓。G1 在 M 上执行,同事其他 3 个 Goroutine 在 LRQ 中等待 M。现在 network poller 没有事情可做。
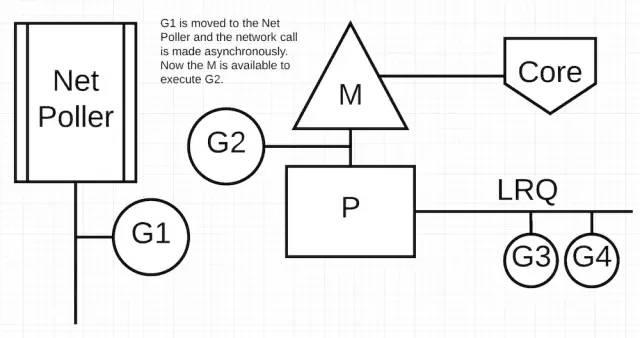
上图中,G1 要执行一个网络调用,所以 G1 被移动到了 network poller 上,等待完成网络系统调用。一旦 G1 被移到了 network poller 中,M 现在就可以去执行 LRQ 中其他的 Goroutine 了。在这里例子中,G2 被切换到了 M 上。
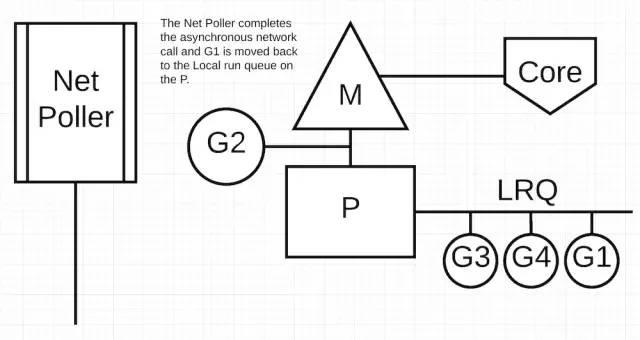
异步网络系统调用完成后,G1 又被放回到了 P 的 LRQ中。一旦 G1 可以被切换到 M 上,处理网络请求结果相关的 Go 代码又能被执行了。这里最大的优势在于,执行网络系统调用,不需要额外的 M。network poller 有一个系统线程处理,它可以高效的处理事件的轮询。
同步系统调用
如果 Goroutine 想要执行一个系统调用不能被异步执行时,会发生什么?这种情况,network poller 是用不了的。执行系统调用的 Goroutine 会导致 M 阻塞住。很不幸,但是没有其他办法可以阻止这种情况的发生。一个不能使系统调用异步执行的例子就是文件系统的调用。如果你用 CGO,可能还有其他调用 C 函数的场景导致 M 阻塞。
注意:Windows 系统有异步处理文件访问的系统调用。技术上讲,在 Windows 上运行时,是可以利用 network poller 的。
让我们来看一下同步的系统调用会发生什么。
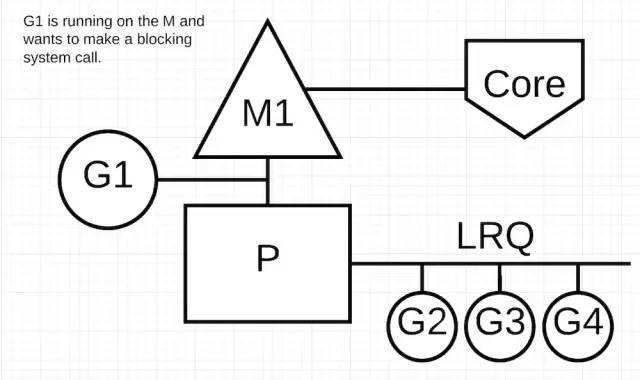
上图展示了我们基本的调度图,但是这次 G1 将要执行一个同步的系统调用,这将会阻塞 M1。
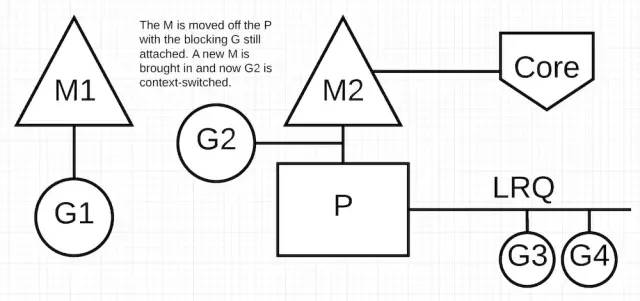
调度器有能力认出 G1 导致 M 阻塞了。这时,调度器会将 M 从 P 上分离出去,G1 依旧附在 M 上被一起分离了。然后调度器获取一个 M2 为 P 服务。此时,G2 会被选中切换到 M2 上执行。如果 M2 因为以前的切换操作已经存在了,那么这次转换就要比重新创建一个 M 要快。
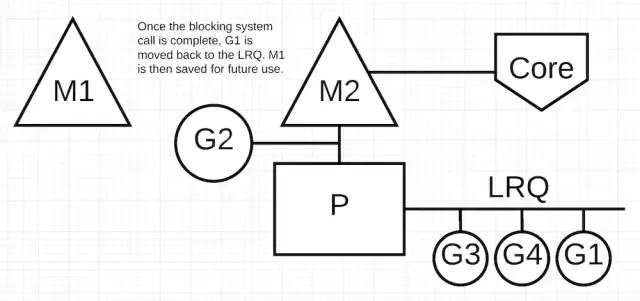
上图中,由 G1 执行的阻塞式系统调用完成了。此时,G1 可以被放回到 LRQ 并等待被 P 在此调度。M1 会放在一边等待以后使用,以防止这种情况在此发生。如果空闲 M 很多,调度器会主动让其退出。
工作窃取
调度器的另一部分就是,它是一个工作窃取机制。这保证在一些场景下能保证高效的调度。
让我们来看一个例子。
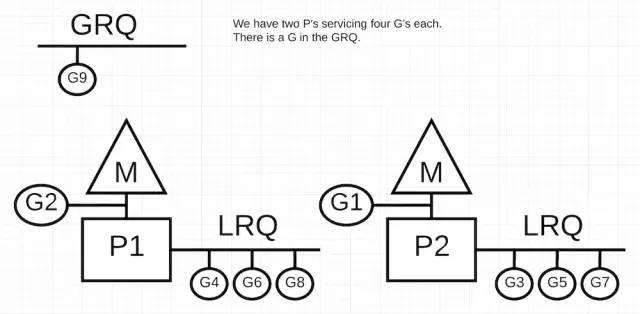
上图中,我们有一个多线程的 Go 程序带有 2 个 P,每个 P 都有 4 个 Goroutine 要执行,还有一个 Goroutine 在 GRQ 中。如果其中一个 P 很快的把所有的 Goroutine 都执行完了,会发生什么呢?
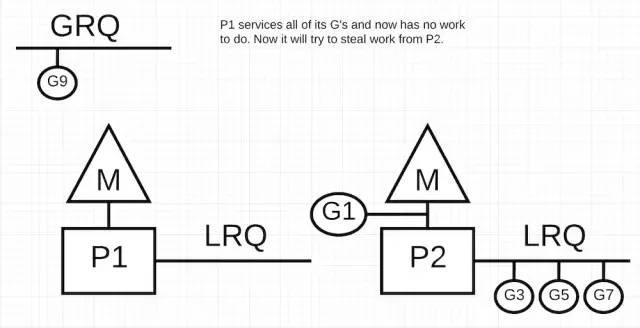
P1 没有 Goroutine 可以执行了,但是仍然有 Goroutine 是处于就绪态的等待被执行,P2 的 LRQ 和 GRQ 中都有。这是 P1 就需要窃取工作了。工作窃取的逻辑如下。
1runtime.schedule() {
2 // only 1/61 of the time, check the global runnable queue for a G.
3 // if not found, check the local queue.
4 // if not found,
5 // try to steal from other Ps.
6 // if not, check the global runnable queue.
7 // if not found, poll network.
8}
所以基于上述注释描述的逻辑,P1 需要检查 P2 的 LRQ 中的 Goroutine 列表,把其中一半的 Goroutine 拿到自己的队列中。
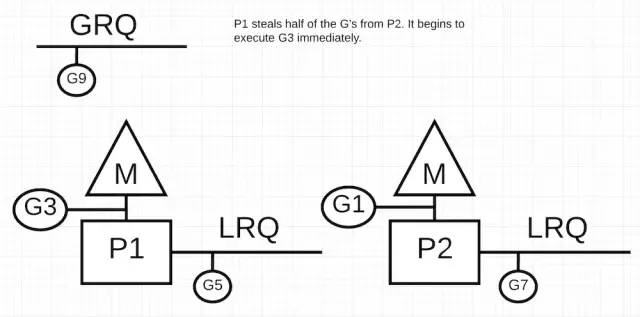
上图中,P2 里的一半的 Goroutine 被交给了 P1 执行。
如果 P2 执行完毕了所有的 Goroutine,同时 P1 的 LRQ 中也没有可执行的 Goroutine 了,怎么办呢?
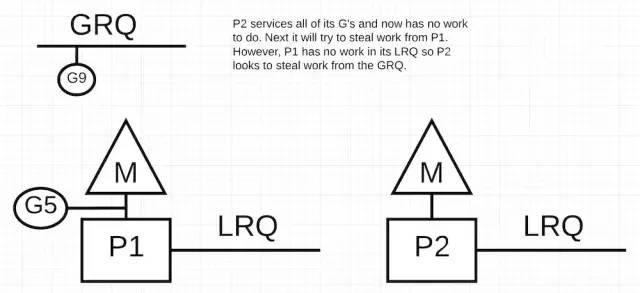
P2 完成了它的所有工作,现在需要窃取一些。首先它会检查一下 P1 的 LRQ,但是没有 Goroutine 可偷。下一步它会检查 GRQ。会找到 G9.
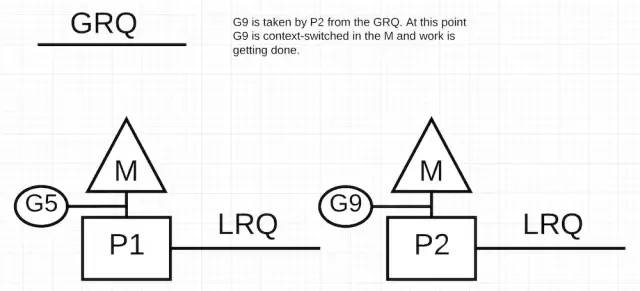
P2 从 GRQ 上偷窃了 G9,并开始执行。这一切工作窃取的好处就在于,它使 M 保持繁忙而不是空闲。这方面还有一些其他的好处,JBD 在它的博客中解释的很好。
练习
解释完了机制原理,我想向您展示如何将所有这些结合在一起,以使得 Go 调度器能在同样的时间完成更多工作。想象一个 C 语言写的多线程应用,程序的逻辑就是两个系统线程彼此互相传递消息。
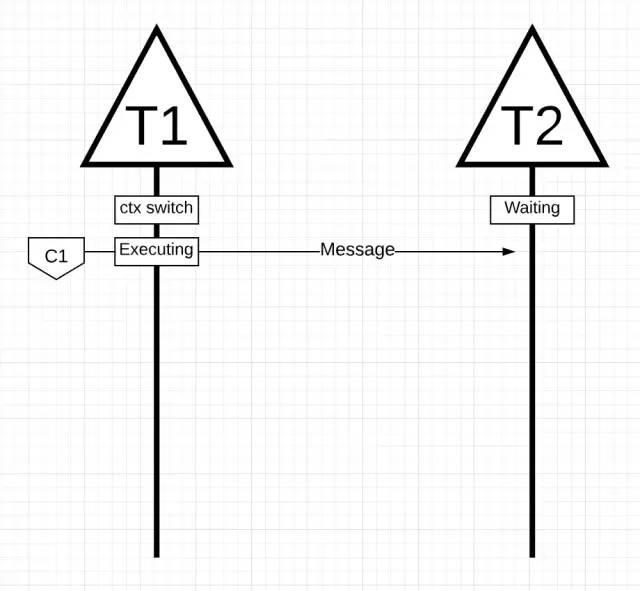
有 2 个线程正在互相传递消息。线程1 被切换都了 Core 1 上,现在正在执行,把他的消息发送给了线程2。
注意:消息是怎么被传递的不重要。重要的是这些线程在编排过程中的状态。
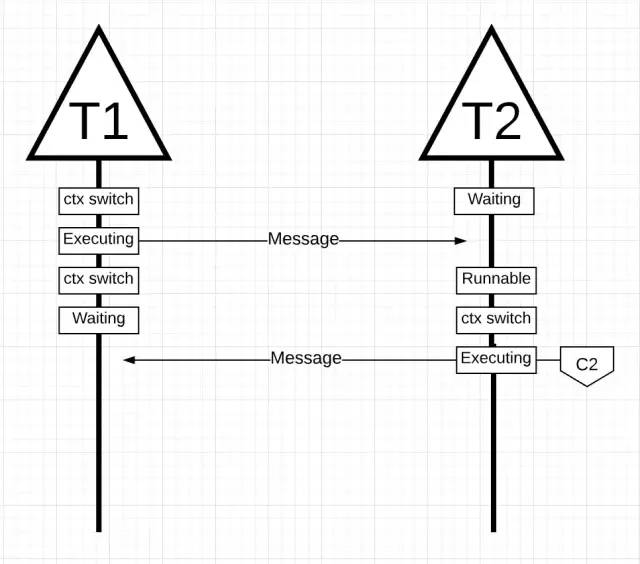
一旦线程1完成了发送消息,它就需要等待返回结果。这就导致了线程1会被从 Core 1 上切换下来,并置为阻塞态。一旦线程2收到了消息通知,它就变成就绪态。现在操作系统执行上下文切换,把线程2放到一个 Core 上执行,这放生在 Core 2 上。下一步,线程 2 处理消息把新的消息返回给线程1。
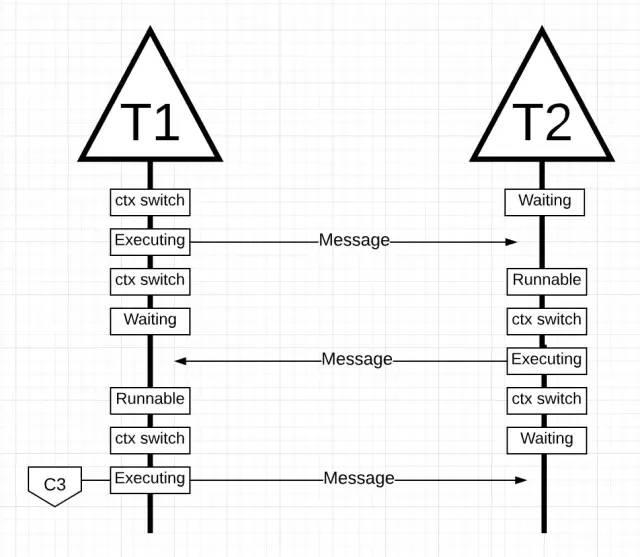
上图中,线程再一次被切换了,因为线程2的消息被线程1收到了。现在线程2从运行态切换到了阻塞态,线程1从阻塞态切换到运行态,最后再进入运行态,是它能够处理消息并发送新消息。
所有的这些上下文切换和状态转换都需要时间执行,这影响了工作被完成的速度。每次上下文切换都会导致 50 纳秒的延迟,并且如果硬件每秒钟能执行 12 条指令,那么大约就有 600 个指令,执行切换的期间是卡在那里的。因为这些线程被绑定在不同的核上,因缓存无法被命中而导致的额外的开销的可能性也很大。
让我们用 Go 调度器调度 Goroutine 来完成通用的操作。
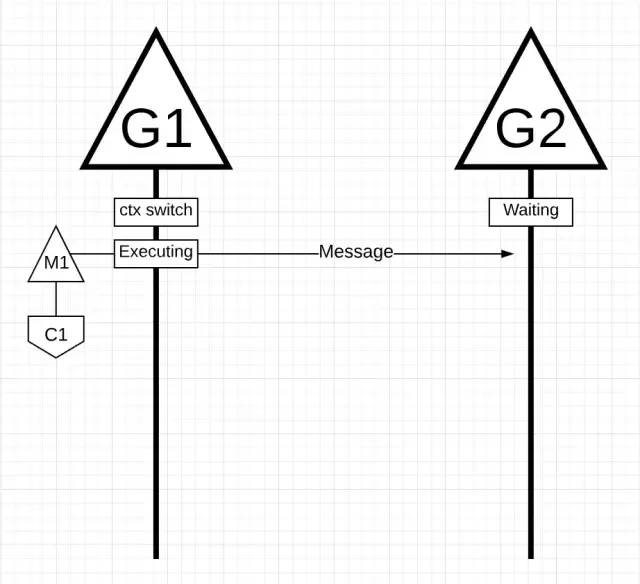
上图中,有 2 个 Goroutine 彼此直线通过互相消息来协同工作。G1 切换到 M1 上,M1 被调度到 Core 1 上,使得 G1 能执行工作,这个工作就是 G1 发送消息给 G2。
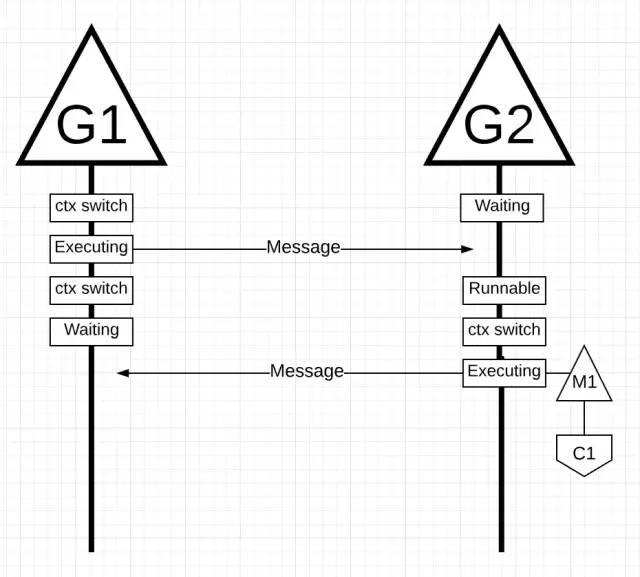
上图中,一旦 G1 结束了发送消息,它现在需要等待相应。这会导致 G1 从 M1 上切换下来,进入阻塞态。一旦 G2 收到了消息通知,它被置为就绪态。现在 Go 调度去可以执行一次切换,让 G2 在 M1 上执行,它将依旧在 Core 1 上执行。然后,G2 处理完消息后,发送新消息 G1。
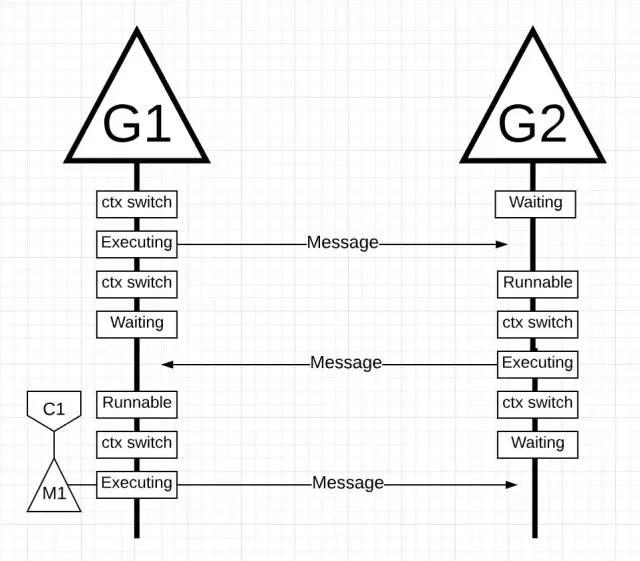
上图中,再次发生了上下文切换,因为 G2 发送的消息被 G1 收到了。现在 G2 从运行态切换到了阻塞态,G1 从阻塞态切换成了就绪态,最终再进入运行态,使得它可以运行并返回新消息。
表面上看没有什么不同。上下文切换和状态的改变,无论是线程还是 Goroutine 都是一样的。使用线程和 Goroutine 的一个主要的区别乍看上去不怎么明显。
在使用 Goroutine 的情况下,同一个系统线程和 Core 应用于整个处理流程中。这就表示,透过操作系统来看,系统线程从来没有被进入过阻塞态。结果我们因上下文切换中而损失的所有时间片,在使用 Goroutine 时都没有丢失。
本质上,Go 是在 OS 层面上,将 IO/阻塞操作转换成了 CPU 操作。因为所有的上下文切换都发生在应用层,我们没有丢掉每次切换造成的 600 个指令损失。调度器同时也增加了 cache-line 的命中几率和 NUMA 。在 Go 中,事情变得更高效,因为 Go 调度器试图用更少的线程,每个线程做更多的事情,帮助我们减少系统和硬件层的调度该校。
结论
Go 调度器的设计方面考虑到了操作系统和硬件的复杂情况。把系统层面的 IO/阻塞 操作转换成了 CPU密集 操作来最大化每个 CPU 的能力。这就是为什么你不需要超过虚拟核数的系统线程。你可以让每一个虚拟 Core 上都只跑一个线程来把所有事情做了,这是合理的。对于网络服务及其他不会阻塞系统线程的系统调用的服务来说,可以这样做。
作为一个开发者,你仍然需要理解你的应用要完成的哪一类型的工作。不要无节制的创建 Goroutine 以期望得到惊人的性能。少即是多,但是搞懂 Go 调度器的原理,你可以做出更好的工程决策。下一篇文章,我会探讨利用这些知识,来提升你的服务的性能,同时又能与代码的复杂度上保持一定的平衡。
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。
Golang语言社区
ID:Golangweb
www.GolangWeb.com
游戏服务器架构丨分布式技术丨大数据丨游戏算法学习
以上是关于Go 语言调度: goroutine 调度器的主要内容,如果未能解决你的问题,请参考以下文章