swagger怎么根据java生成json
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了swagger怎么根据java生成json相关的知识,希望对你有一定的参考价值。
参考技术A WebAPI文档工具列表Swagger——Swagger框架可以通过代码生成漂亮的在线API,甚至可以提供运行示例。支持Scala、Java、javascript、Ruby、php甚至Actionscript3。在线Demo。I/ODocs——I/ODocs是一个用于RESTfulWebAPIs的交互式文档系统本回答被提问者采纳基于HttpRunner,解析swagger数据,快速生成接口测试框架
使用 HttpRunner 默认生成的项目是这样的
命令:httprunner --startproject 项目名称
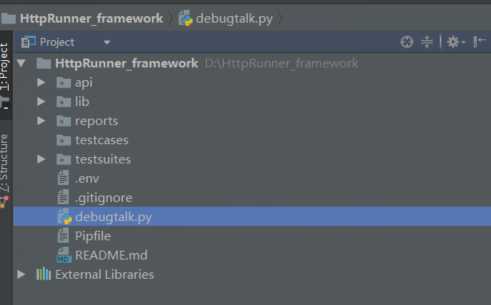
so,根据这个项目的目录结构,使用python解析swagger接口参数,可以快速生成api、testcases、testsuites文件夹中用到的json文件
运行后的目录是这样的
api目录
按swagger中的tags区分为多个文件夹,每个文件夹下包含各自的api文件
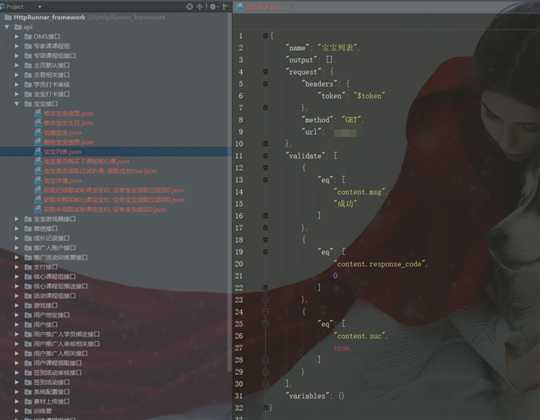
testcases目录
按swagger中的tags区分为不同的json文件,每个文件包含所有的api接口
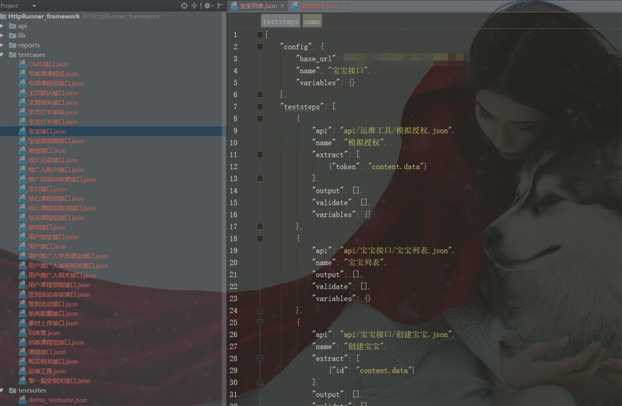
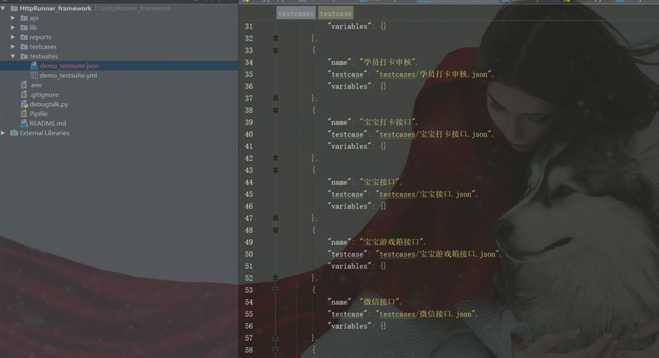
testsuites目录
测试用例集,组织运行所有的测试用例
这样,接口测试框架的简易架子就有了。接下来,需要补充api接口文件数据
略
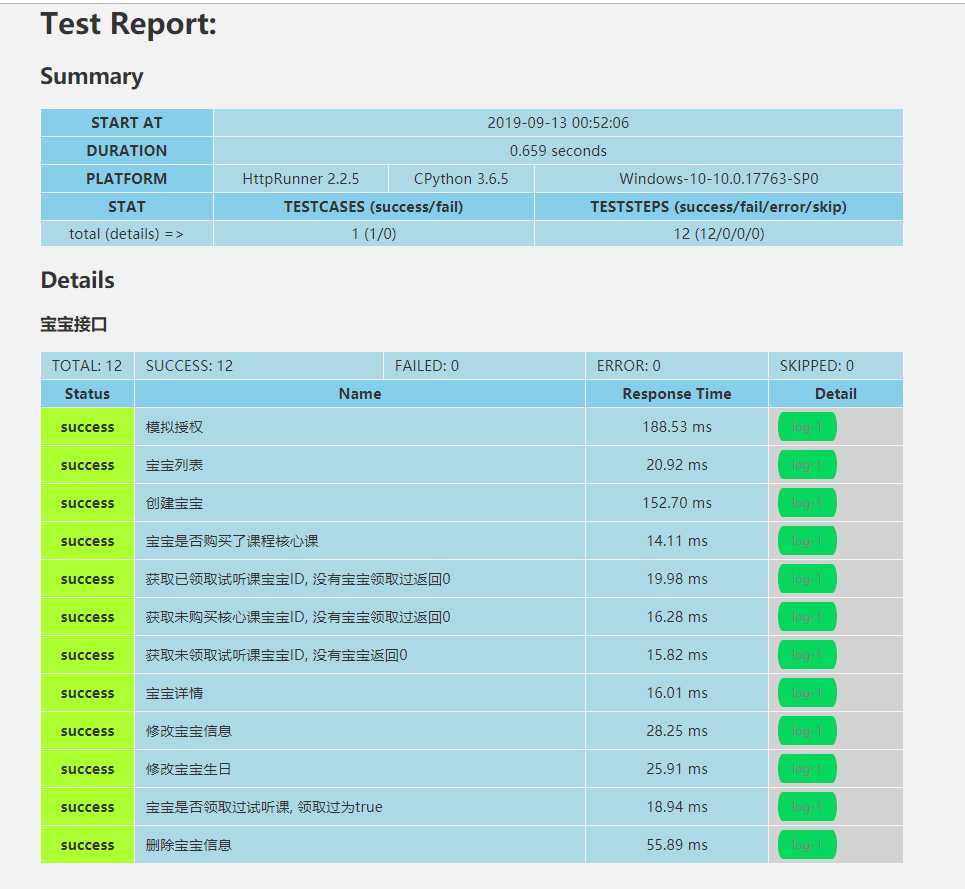
运行结果
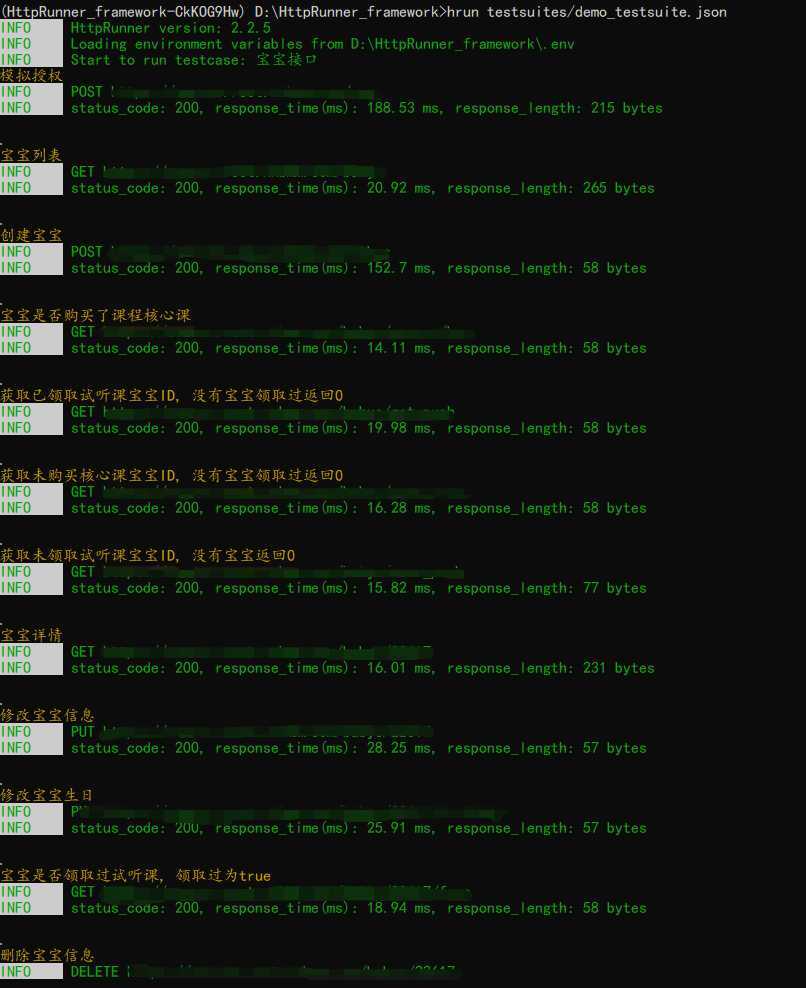
HttpRunner自带的report
附lib目录下的代码
swagger.py
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2019/9/9 15:17 # @Author : lixiaofeng # @Site : # @File : swagger.py # @Software: PyCharm import os, requests from httprunner import logger from lib.processingJson import write_data, get_json class AnalysisJson: """swagger自动生成测试用例""" def __init__(self, url): self.url = url self.interface = self.case_list = [] self.tags_list = [] self.http_suite = "config": "name": "", "base_url": "", "variables": , "testcases": [] self.http_testcase = "name": "", "testcase": "", "variables": def retrieve_data(self): """ 主函数 :return: """ try: r = requests.get(self.url + ‘/v2/api-docs?group=sign-api‘).json() write_data(r, ‘data.json‘) # r = get_json(‘D:\\HttpRunner_framework\\\\testcases\\data.json‘) except Exception as e: logger.log_error(‘请求swagger url 发生错误. 详情原因: ‘.format(e)) return ‘error‘ self.data = r[‘paths‘] # 接口数据 self.url = ‘https://‘ + r[‘host‘] self.title = r[‘info‘][‘title‘] self.http_suite[‘config‘][‘name‘] = self.title self.http_suite[‘config‘][‘base_url‘] = self.url self.definitions = r[‘definitions‘] # body参数 for tag_dict in r[‘tags‘]: self.tags_list.append(tag_dict[‘name‘]) i = 0 for tag in self.tags_list: self.http_suite[‘testcases‘].append("name": "", "testcase": "", "variables": ) self.http_suite[‘testcases‘][i][‘name‘] = tag self.http_suite[‘testcases‘][i][‘testcase‘] = ‘testcases/‘ + tag + ‘.json‘ i += 1 suite_path = os.path.join(os.path.abspath(os.path.join(os.path.dirname("__file__"), os.path.pardir)), ‘testsuites‘) testcase_path = os.path.join(suite_path, ‘demo_testsuite.json‘) write_data(self.http_suite, testcase_path) if isinstance(self.data, dict): for tag in self.tags_list: self.http_case = "config": "name": "", "base_url": "", "variables": , "teststeps": [] for key, value in self.data.items(): for method in list(value.keys()): params = value[method] if not params[‘deprecated‘]: # 接口是否被弃用 if params[‘tags‘][0] == tag: self.http_case[‘config‘][‘name‘] = params[‘tags‘][0] self.http_case[‘config‘][‘base_url‘] = self.url case = self.retrieve_params(params, key, method, tag) self.http_case[‘teststeps‘].append(case) else: logger.log_info( ‘interface path: , if name: , is deprecated.‘.format(key, params[‘description‘])) break api_path = os.path.join(os.path.abspath(os.path.join(os.path.dirname("__file__"), os.path.pardir)), ‘testcases‘) testcase_path = os.path.join(api_path, tag + ‘.json‘) write_data(self.http_case, testcase_path) else: logger.log_error(‘解析接口数据异常!url 返回值 paths 中不是字典.‘) return ‘error‘ def retrieve_params(self, params, api, method, tag): """ 解析json,把每个接口数据都加入到一个字典中 :param params: :param params_key: :param method: :param key: :return: replace(‘false‘, ‘False‘).replace(‘true‘, ‘True‘).replace(‘null‘,‘None‘) """ http_interface = "name": "", "variables": , "request": "url": "", "method": "", "headers": , "json": , "params": , "validate": [], "output": [] http_testcase = "name": "", "api": "", "variables": , "validate": [], "extract": [], "output": [] name = params[‘summary‘].replace(‘/‘, ‘_‘) http_interface[‘name‘] = name http_testcase[‘name‘] = name http_testcase[‘api‘] = ‘api//.json‘.format(tag, name) http_interface[‘request‘][‘method‘] = method.upper() http_interface[‘request‘][‘url‘] = api.replace(‘‘, ‘$‘).replace(‘‘, ‘‘) parameters = params.get(‘parameters‘) # 未解析的参数字典 responses = params.get(‘responses‘) if not parameters: # 确保参数字典存在 parameters = for each in parameters: if each.get(‘in‘) == ‘body‘: # body 和 query 不会同时出现 schema = each.get(‘schema‘) if schema: ref = schema.get(‘$ref‘) if ref: param_key = ref.split(‘/‘)[-1] param = self.definitions[param_key][‘properties‘] for key, value in param.items(): if ‘example‘ in value.keys(): http_interface[‘request‘][‘json‘].update(key: value[‘example‘]) else: http_interface[‘request‘][‘json‘].update(key: ‘‘) elif each.get(‘in‘) == ‘query‘: name = each.get(‘name‘) for key in each.keys(): if ‘example‘ in key: http_interface[‘request‘][‘params‘].update(name: each[key]) for each in parameters: # if each.get(‘in‘) == ‘path‘: # name = each.get(‘name‘) # for key in each.keys(): # if ‘example‘ in key: # http_interface[‘request‘][‘json‘].update(name: each[key]) # else: # # http_interface[‘request‘][‘json‘].update(name: ‘‘) if each.get(‘in‘) == ‘header‘: name = each.get(‘name‘) for key in each.keys(): if ‘example‘ in key: http_interface[‘request‘][‘headers‘].update(name: each[key]) else: if name == ‘token‘: http_interface[‘request‘][‘headers‘].update(name: ‘$token‘) else: http_interface[‘request‘][‘headers‘].update(name: ‘‘) for key, value in responses.items(): schema = value.get(‘schema‘) if schema: ref = schema.get(‘$ref‘) if ref: param_key = ref.split(‘/‘)[-1] res = self.definitions[param_key][‘properties‘] i = 0 for k, v in res.items(): if ‘example‘ in v.keys(): http_interface[‘validate‘].append("eq": []) http_interface[‘validate‘][i][‘eq‘].append(‘content.‘ + k) http_interface[‘validate‘][i][‘eq‘].append(v[‘example‘]) http_testcase[‘validate‘].append("eq": []) http_testcase[‘validate‘][i][‘eq‘].append(‘content.‘ + k) http_testcase[‘validate‘][i][‘eq‘].append(v[‘example‘]) i += 1 else: http_interface[‘validate‘].append("eq": []) else: http_interface[‘validate‘].append("eq": []) if http_interface[‘request‘][‘json‘] == : del http_interface[‘request‘][‘json‘] if http_interface[‘request‘][‘params‘] == : del http_interface[‘request‘][‘params‘] api_path = os.path.join(os.path.abspath(os.path.join(os.path.dirname("__file__"), os.path.pardir)), ‘api‘) tags_path = os.path.join(api_path, tag) if not os.path.exists(tags_path): os.mkdir(tags_path) json_path = os.path.join(tags_path, http_interface[‘name‘] + ‘.json‘) write_data(http_interface, json_path) return http_testcase if __name__ == ‘__main__‘: AnalysisJson(‘1‘).retrieve_data()
简单的实现了功能,代码有些粗糙~~~
processingJson.py
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2019/9/9 15:18 # @Author : lixiaofeng # @Site : # @File : processingJson.py # @Software: PyCharm import json from httprunner import logger def get_json(path, field=‘‘): """ 获取json文件中的值,data.json和res.json可共用 :param path: :param field: :return: """ with open(path, ‘r‘, encoding=‘utf-8‘) as f: json_data = json.load(f) if field: data = json_data.get(field) return data else: return json_data def write_data(res, json_path): """ 把处理后的参数写入json文件 :param res: :param json_path: :return: """ if isinstance(res, dict) or isinstance(res, list): with open(json_path, ‘w‘, encoding=‘utf-8‘) as f: json.dump(res, f, ensure_ascii=False, sort_keys=True, indent=4) logger.log_info(‘Interface Params Total: ,write to json file successfully!\\n‘.format(len(res))) else: logger.log_error(‘ Params is not dict.\\n‘.format(write_data.__name__))
具体业务场景的测试,可以按照导入.har文件的方法快速生成,总之还是挺便捷的。
之前就有关注HttpRunner,终于有空花了一天时间,大致过了一遍中文文档,简单的记录下学习成果~~~
以上是关于swagger怎么根据java生成json的主要内容,如果未能解决你的问题,请参考以下文章
Swagger 可以根据现有的快速路由自动生成其 yaml 吗?