你需要知道的有关Selenium异常处理的都在这儿
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你需要知道的有关Selenium异常处理的都在这儿相关的知识,希望对你有一定的参考价值。
参考技术A什么是异常?
顾名思义,作为程序员的一种常用术语,“异常”与任何特定的编程语言无关。它属于程序因为突然中止,而未能交付出预期输出的事件。通常,引发异常出现的潜在因素往往来自如下方面:
· Java虚拟内存(JVM)的不足
· 请求访问的文件在目标系统中不存在
· 用户提供了无效的数据
· 在正常的通信过程中突然出现断网
Java中的异常类型
1. 已查明的异常(Checked Exceptions):编译器在编译的过程中,会检查到这些异常,并验证它们是否已被处理。如果未被处理,系统会报告编译错误。因此它们被通称为编译时异常(compile-time exceptions)。下面是一些常见的此类异常示例:
· SQLException:程序在基于 SQL 语法执行 数据库 查询时,可能会产生此类异常。
· IOException:程序在文件上执行无效的I/O流操作时,可能会产生此类异常。
· ClassNotFoundException:当JVM无法找到所需的Java类时,可能会产生此类异常。
2. 未查明的异常(Unchecked Exceptions):这些异常是在程序的执行期间发生的逻辑错误,因此通常称为运行时异常(Runtime Exceptions)。此类异常在编译时未被检查出来,或者在整个编译过程中已被忽略。下面是一些典型的此类异常示例:
· NullPointerException:当访问具有空值的对象时,可能会产生此类异常。
· ArrayIndexOutofBound:当使用无效的索引值去访问数组时,可能会产生此类异常。
· IllegalArgumentException:当程序将不正确的参数传递给方法时,可能会产生此类异常。
· NumberFormatException:当程序将字符串传递给无法转换为数字的方法时,可能会产生此类异常。
· ArithmeticException:当程序执行不正确的算术运算(例如将数字除以零)时,可能会产生此类异常。
异常处理标准
通过对异常处理能力的提升,我们不仅可以保持代码的整洁,而且能够增强其可维护性、可扩展性和可阅读性。当然,不同的面向对象编程(Object-Oriented Programming,OOP)语言,具有不同的异常处理方法。以下是一些常用的Java异常处理标准:
Try-Catch:该关键字组合可被用于捕获异常。其中,try块应当被放在开头,而catch块应被放在try块的末尾,以便捕获异常,并采取必要的行动。也就是说,我们可以在遇到异常时,创建异常类的对象,以便使用以下预定义的方法,来显示调试信息:
· printStackTrace():该函数可用于打印栈的跟踪、异常的名称、以及其他重要的异常信息。
· getMessage():此函数有助于获取针对异常的深入描述。
try
// Code
catch(Exception e)
// Code for Handling exception
同时,Try-Catch块也可以用其他高级方法来处理异常,例如,我们可能希望从单个代码块中捕获多个异常,那么就可以通过在try块之后的多个catch块,去处理不同的异常。而且,我们在try块之后,使用无限数量的catch块。
try
//Code
catch(ExceptionType1 e1)
//Code for Handling Exception 1
catch(ExceptionType2 e2)
//Code for Handling Exception 2
Throw/Throws:如果程序员想显式地抛出异常,那么可以使用throw关键字,与要在运行时处理的异常对象协同使用。
public static void exceptionProgram()throws Exception
try
// write your code here
Catch(Exception b)
// Throw an Exception explicitly
throw(b);
如果开发者想抛出多个异常,则可以通过在方法签名的子句中使用throws关键字来抛出,并且由方法的调用者去进行异常处理。
public static void exceptionProgram()throws ExceptionType1, ExceptionType2
try
// write your code here
catch(ExceptionType1 e1)
// Code to handle exception 1
catch(ExceptionType1 e2)
// Code to handle exception 2
finally:该个代码块往往是在try-catch块之后被创建的。也就是说,无论是否抛出异常,它都会被执行。
try
//Code
catch(ExceptionType1 e1)
//Catch block
catch(ExceptionType2 e2)
//Catch block
finally
//The finally block always executes.
Selenium中的常见异常
WebDriverException定义了Selenium中的多种异常,我们从中选取最常见的异常予以介绍,并配上简单的针对Selenium的异常处理方案:
1. NoSuchElementException
当WebDriver无法定位所需要元素时,Selenium可能会产生此类异常。此处的NoSuchElementException是NotFoundException类的子类,它通常出现在程序使用了无效的定位器时。
此外,如果WebDriver仍然停留在上一页、或正在加载下一页,而所需的定位器已到达了下一页时,就会因为该延迟而出现异常。为此,我们应当通过适当的等待处理 测试 ,最大限度地减少此类异常的发生。
当然,此类异常可以在catch块中被捕获到,并且可以在其中执行所需的操作,以继续完成自动化的测试。例如:
try driver.findElement(By.id("form-save")).click(); catch(NoSuchElementException e)
System.out.println(“WebDriver couldn’t locate the element”);
2. NoSuchWindowException
该异常也是NotFoundException类的子类。如果WebDriver尝试着切换到无效的 浏览器 窗口,那么WebDriver将抛出NoSuchWindowException。因此,要实现窗口切换的好方法是,首先获取活动窗口的会话,然后在对应的窗口上执行所需的操作。例如:
for(String windowHandle : driver.getWindowHandles())
try driver.switchTo().window(handle); catch(NoSuchWindowException e) System.out.println(“Exception while switching browser window”);
3. NoAlertPresentException
当WebDriver尝试着切换到某个不存在或无效的警报时,Selenium可能会产生此类异常。对此,我建议开发者使用显式、或适当的等待时间,来处理浏览器的各类警报。倘若仍然等不到警报的话,catch块可以捕获该异常。例如:
try
driver.switchTo().alert().accept(); catch(NoSuchAlertException e)
System.out.println(“WebDriver couldn’t locate the Alert”);
4. ElementNotVisibleException
该异常被定义为ElementNotInteractableException类的子类。当WebDriver尝试着对不可见的元素、或不可交互的元素执行各项操作时,Selenium可能会产生此类异常。对此,我建议开发者在的确需要之处,让Selenium进行适当的超时等待。例如:
try driver.findElement(By.id("form-save")).click(); catch(ElementNotVisibleException e)
System.out.println(“WebDriver couldn’t locate the element”);
5. ElementNotSelectableException
该异常属于InvalidElementStateException类的子类。在Selenium中,ElementNotSelectableException表明某个元素虽然存在于网页上,但是无法被WebDriver所选择。
catch块不但可以处理Selenium中的此类异常,而且可以使用相同或不同的 技术 ,重新选择相同的元素。例如:
try
Select dropdown = new Select(driver.findElement(By.id(“swift”))); catch(ElementNotSelectableException e)
System.out.println("Element could not be selected")
6. NoSuchSessionException
Selenium通过driver.quit()命令退出自动化的浏览器会话后,以及在调用某个测试方法时,会产生此类异常。当然,如果浏览器崩溃或出现断网,该异常也可能会发生。为了避免出现NoSuchSessionException,我们可以在测试套件结束时,退出浏览器,并确保用于 自动化测试 的浏览器版本的稳定性。例如:
private WebDriver driver;
@BeforeSuite
public void setUp() driver = new ChromeDriver();
@AfterSuite
public void tearDown() driver.quit();
7. StaleElementReferenceException
当DOM中不再存在程序所需的元素时,Selenium将抛出StaleElementReferenceException。当然,如果DOM未能被正确加载、或WebDriver被卡在错误的页面上时,也可能会产生这种异常。对此,您可以使用catch块捕获该异常,并且使用动态的XPath、或尝试着重新刷新页面。例如:
try driver.findElement(By.xpath(“//*[contains(@id,firstname’)]”)).sendKeys(“Aaron”);
catch(StaleElementReferenceException e)
System.out.println("Could not interact with a desired element")
8. TimeoutException
当WebDriver超过了执行下一步的等待时限时,Selenium中可能会产生此类异常。Selenium的各种等待通常被用于避免出现ElementNotVisibleException之类的异常。不过,即使在使用了适当的等待之后,如果元素仍然不可交互,那么TimeoutException也会被抛出。为此,我们必须通过执行手动测试,来检验元素的延时性,以便采取进一步的处理等待。
9. InvalidSelectorException
当使用无效的或不正确的选择器时,Selenium中会抛出此类异常。当然,类似情况也可能发生在创建XPATH时。对此,我们需要在将代码推送到主分支之前,检查测试脚本,并测试脚本的端到端流程。此外,SelectorHub和ChroPath等工具,也可以被用于验证定位器。
10. NoSuchFrameException
NoSuchFrameException属于NotFoundException类的子类。当WebDriver尝试着切换到当前网页上无效的、或不存在的框架时,Selenium可能会产生此类异常。为此,我们需要首先确保框架的名称或id是正确的;其次,应确保框架的加载不会过于消耗时间。当然,如果在网页上加载框架的确非常耗时的话,则需要修正相应的等待处理。例如:
try
driver.switchTo().frame("frame_1"); catch(NoSuchFrameException e)
System.out.println("Could not find the desired frame")
小结
综上所述,为了适应各种场景,异常处理对于任何自动化脚本和逻辑结构都是至关重要的。请您务必在了解每个异常特征的基础上,有选择性地在自动化脚本中使用上述十种有关Selenium的常用异常处理命令。
有关分库分表你想知道的,都在这儿了
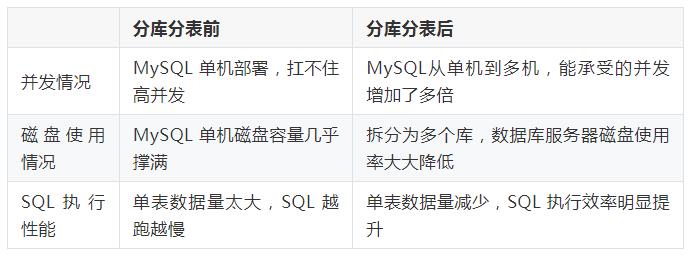
面试的时候,聊到高并发或者大数据,很多时候会聊到数据库分库分表相关的问题,因为你的数据库单机抗不了多少并发量,而且用户量上来之后,数据库容纳的数据量也是有限的。
如果单表数据量过大,SQL稍微复杂点,查询就会很慢。而且,现在稍微大点的互联网公司,分库分表都成为了标配。如果你现在出去面试,面试官问你分库分表相关的问题,你说你没做过,人家立马会觉得你没有高并发的经验,做的都是比较简单的业务系统。
MySQL单表通常500w条数据以内比较合适,不建议超过1000w,如果超过1000w了建议要做分库分表了。
比如常见的分库分表面试题:
为什么要分库分表?
用过哪些分库分表的中间件?
不同的分库分表中间件都有什么优缺点?
你们具体是如何对数据库进行进行垂直拆分或水平拆分的?
你们是如何把系统不停机迁移到分库分表的?
分库分表之后全局id咋生成?
一般开发一个新业务系统,由于需要快速打样,尽快上线,所以一开始基本都是单库系统。
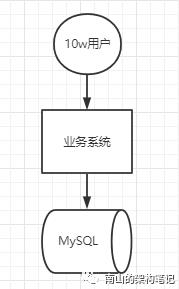
图1 单库
可能业务发展迅猛,过了几个月,使用用户就达到了 1000 万!每天活跃用户数 100 万!每天单表数据量 10 万条!高峰期每秒最大请求达到 1000QPS!
现在大家感觉压力已经有点大了,为啥呢?因为每天多 10 万条数据,一个月就新增300 万条数据,现在咱们单表已经几百万数据了,马上就破千万了。
目前用户量还在不断增长,每天新增的数据量也在不断变多,照目前这个势头,系统恐怕坚持不了多久。业务系统倒是可以很容易的增加一些机器。
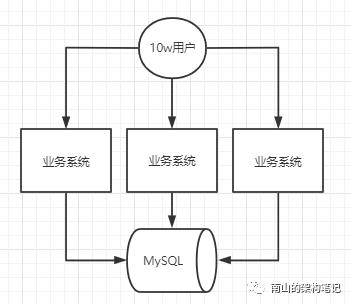
图2 业务系统增加机器
但大多数请求集中在20%的时间,80%的时间请求量还可以支撑。这20%时间段里,每秒并发量和在线用户量都达到峰值,对数据库的压力也是每天最大的时候。这时候,你可以在业务系统与MySQL数据库中间加一个MQ削峰,比如使用kafka,缓解一下过高的并发请求。假如高峰期每秒8000个请求,异步写系统每秒消费2000个请求。经过MQ削峰后,会在消息队列里缓存很多未执行的数据库操作,等待异步写系统慢慢的消费掉。
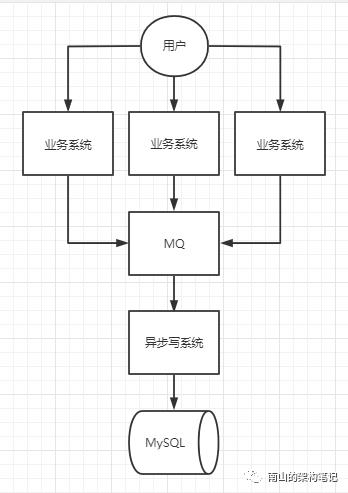
图3 MQ削峰
业务系统能够增加机器扩容,没什么问题,MQ削峰也能撑一撑,但瓶颈在于MySQL。主要有3个问题:
(1)MySQL单机扛不住高并发
(2)磁盘容量快慢了;
(3)SQL越跑越慢;
如果要让MySQL承担更高的并发,比如现在是8000请求/s,异步写系统也可以扩容到多台机器,MQ消费6000请求/s,这时候该怎么办?你首先得分库。
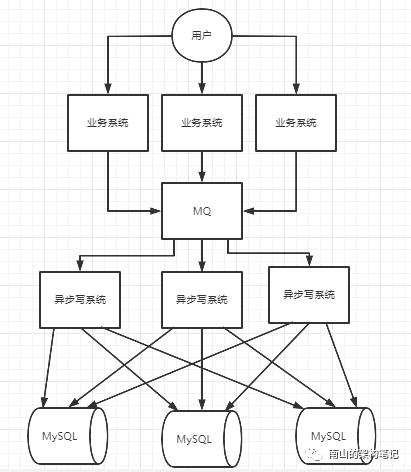
图4 分库
假如现在分了3个库,每个库的表和表结构都是一模一样的,MQ分为3个partition,每个异步写系统都只消费一个partition。每个异步写系统,会根据每条数据的某个id分发到各个数据库里去,比如是userId,每个userId相同的数据分发到同一台机器上去。
分库前单库每天可能增加100w数据,现在每个库增加30多万条数据。数据库可以承受的并发增加了3倍,数据库的磁盘使用率大大降低,本来一个库磁盘很快就写满了,现在大大降低了,同时SQL语句执行性能也提高了。
分库之后,每个表的数据库依旧很多,SQL语句执行起来性能依旧不高,所以还是要考虑分表,打造多库多表的系统。
千万不能因为技术原因制约了公司业务的发展。
分表
比如你单表都几千万数据了,你确定你能扛住么?肯定不行,单表数据量太大,会极大影响你的SQL执行的性能,大量的连接卡在MySQL等待执行,不仅会把你MySQL数据库拖垮,还会产生连锁反应,把你的业务系拖垮。一般来说,单表到几百万的时候,性能就会越来越差,你就得分表了。
分表是啥意思?
就是把一个表的数据放到多个表中,然后查询的时候你就查一个表。比如按照用户 id 来分表,将一个用户的数据就放在一个表中。然后操作的时候你对一个用户就操作那个表就好了。这样可以控制每个表的数据量在可控的范围内,比如每个表就固定在500万以内。
分库
分库是啥意思?就经验而言,单库最多支撑到并发2000,一定要扩容了,而且一个健康的单库并发值最好保持在每秒1000以内,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
常用的分库分表中间件以及优缺点
ShardingSphere (Sharding-jdbc)
Mycat
Sharding-Sphere是一套开源的分布式数据库中间件解决方案,属于client端方案,也就是你的业务系统只需要引用它的jar包,就可以使用了。Sharding-Sphere目前社区也还一直在开发和维护,还算是比较活跃,个人认为算是一个现在也可以选择的方案。
mycat是基于Cobar改造的,属于 proxy 层方案,支持的功能非常完善,而且目前应该是非常火的而且不断流行的数据库中间件,社区很活跃,也有一些公司开始在用了。但是确实相比于 Sharding jdbc 来说,年轻一些,经历的锤炼少一些。
比较:
Sharding-Sphere这种client端方案的优点在于不用部署,运维成本低,不需要代理层的二次转发请求,性能很高,但是如果遇到升级啥的需要各个业务系统都重新升级版本再发布,各个系统都需要耦合Sharding-Sphere即可。
Mycat 这种proxy层方案的缺点在于需要单独部署,自己运维一套中间件,运维成本高,但是好处在于对于各个项目是透明的,如果需要升级只需要单独升级mycat就行了。
通常来说,这两个方案其实都可以选用,但是个人建议中小型公司选用 Sharding-Sphere,client 层方案轻量级,而且维护成本低,不需要额外增派人手去维护,而且中小型公司系统复杂度会低一些,项目也没那么多。
但是中大型公司最好还是选用Mycat这类proxy层方案,因为可能大公司系统和项目非常多,团队很大,人员充足,那么最好是专门弄个人来研究和维护Mycat,然后各个项目直接透明使用即可。
你们是如何对数据库进行垂直拆分或水平拆分的?
水平拆分的意思,就是把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。水平拆分的意义,就是将数据均匀放更多的库里,然后用多个库来扛更高的并发,还有就是用多个库的存储容量来进行扩容。
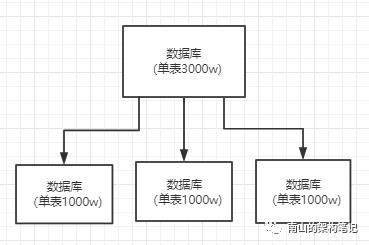
图5 水平拆分
垂直拆分,就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。
一般来说,会将访问频率很高的字段放到一个表里去,然后将访问频率很低的字段放到另外一个表里去。因为数据库是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个一般在表层面做的较多一些。
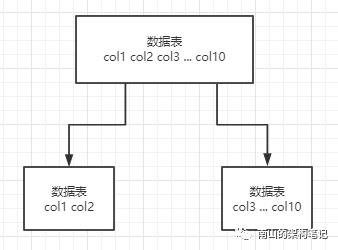
图6 垂直拆分
假如有600w数据,现在要分库分表,综合来看分库分表可能是这样的:
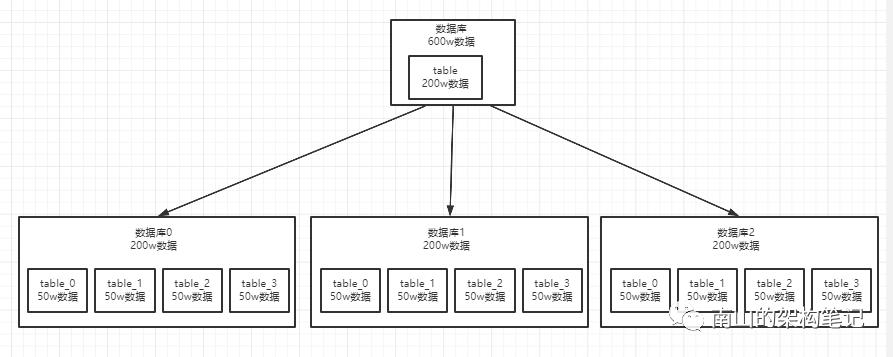
图7 分库分表示意图
常见的分库分表是,是根据某个id取模先定位到库,再定位到表的。可以根据userId和orderId取模。也可以根据数据的range去分库分表,比如根据数据的创建时间。
引入了分库分表中间件,那么我们的系统就不用自己考虑每条数据路由到哪个库哪张表了。就可以直接将SQL丢给分库分表中间件,由它根据配置,路由到相应的库和表里去,此时MQ和异步写系统也可以去掉了,因为分库分表后,相当于每个业务系统承担的压力就大大减小了。
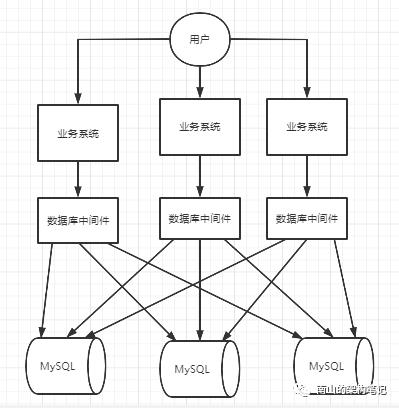
图8 分库分表示意图
总结
本文分享了分库分表的由来,业务不断发展的驱动下,改造系统分库分表是架构升级的必经之路。同时讲了业内常用的分库分表中间件ShardingSphere和Mycat以及他们的优缺点,最后分享了如何对数据库进行垂直拆分和水平拆分,以及具体分库分表数据路由方法。
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号

好文章,我在看❤️
以上是关于你需要知道的有关Selenium异常处理的都在这儿的主要内容,如果未能解决你的问题,请参考以下文章
Java新特性Lambda表达式典型案例,你想要的的都在这儿了!!