Java源码分析——String
Posted 卷小毛的干货分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java源码分析——String相关的知识,希望对你有一定的参考价值。
作为Java 中八种基本类型之一的char 的封装类型,String 类可以说是Java程序员每天打交道最多的一个类了。所以,了解String 类的实现与原理是十分有必要的。
注:本文基于jdk_1.8.0_144
在分析String的源码之前,打算先介绍一点关于JVM的内存分布,这样有助于我们更好地去理解String的设计:
常量池(constant pool)指的是在编译期被确定,并被保存在已编译的.class文件中的一些数据。它包括了关于类、方法、接口等中的常量,也包括字符串常量。Java把内存分为堆内存跟栈内存,前者主要用来存放对象,后者用于存放基本类型变量以及对象的引用。
继承关系
先看一下文档中的注释。
Strings are constant; their values can not be changed after they are created.
Stringbuffers support mutable strings.Because String objects are immutable they can be shared. Forexample:String 字符串是常量,其值在实例创建后就不能被修改,但字符串缓冲区支持可变的字符串,因为缓冲区里面的不可变字符串对象们可以被共。
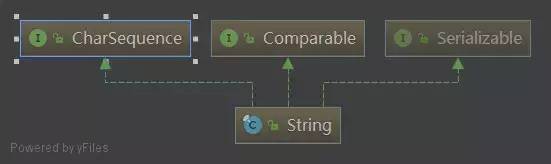
通过注释跟继承关系,我们知道String被final修饰,而且一旦创建就不能更改,并且实现了CharSequence,Comparable以及Serializable接口。
final:
修饰类:当用final修饰一个类时,表明这个类不能被继承。也就是说,String类是不能被继承的,
修饰方法:把方法锁定,以防任何继承类修改它的含义。
修饰变量:修饰基本数据类型变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。
String类通过final修饰,不可被继承,同时String底层的字符数组也是被final修饰的,char属于基本数据类型,一旦被赋值之后也是不能被修改的,所以String是不可变的。
CharSequence
CharSequence翻译过来就是字符串,String我们平常也是叫作字符串,但是前者是一个接口,下面看一下接口里面的方法:
int length();
char charAt(int index);
CharSequence subSequence(int start, int end);
public String toString();
}方法很少,并没有看到我们常见的String的方法,这个类应该只是一个通用的接口,那么翻一翻它的实现类
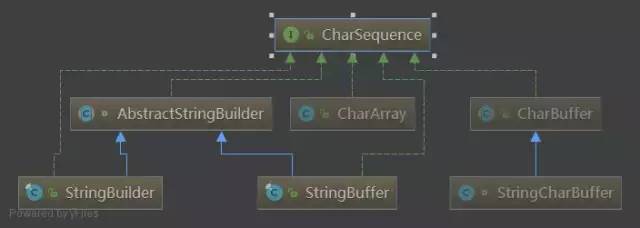
CharSequence的实现类里面出现了我们很常见的StringBuilder跟StringBuffer,先放一放,一会儿再去研究他们俩。
成员变量
private final char value[];//final字符数组,一旦赋值,不可更改
private int hash; //缓存String的 hash Code,默认值为 0
private static final ObjectStreamField[] serialPersistentFields =new ObjectStreamField[0];//存储对象的序列化信息构造方法
空参数初始化
public String(){
this.value = "".value;
}
//将数组的值初始化为空串,此时在栈内存中创建了一个引用,在堆内存中创建了一个对象
//示例代码
String str = new String()
str = "hello";1.先创建了一个空的String对象
2.接着又在常量池中创建了一个"hello",并赋值给第二个String
3.将第二个String的引用传递给第一个String
这种方式实际上创建了两个对象
String初始化
public String(String original){
this.value = original.value;
this.hash = original.hash;
}
//代码示例
String str=new String("hello")创建了一个对象
字符数组初始化
public String(char value[]){
//将传过来的char拷贝至value数组里面
this.value = Arrays.copyOf(value, value.length);
}字节数组初始化
不指定编码
public String(byte bytes[]){
this(bytes, 0, bytes.length);
}
public String(byte bytes[], int offset, int length){
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(bytes, offset, length);
}
static char[] decode(byte[] ba, int off, int len){
String csn = Charset.defaultCharset().name();
try{ //use char set name decode() variant which provide scaching. return decode(csn, ba, off, len);
} catch(UnsupportedEncodingException x){
warnUnsupportedCharset(csn);
}
try{
//默认使用 ISO-8859-1 编码格式进行编码操作 return decode("ISO-8859-1", ba, off, len); } catch(UnsupportedEncodingException x){
//异常捕获}指定编码
String(byte bytes[], Charset charset)
String(byte bytes[], String charsetName)
String(byte bytes[], int offset, int length, Charset charset)
String(byte bytes[], int offset, int length, String charsetName)byte 是网络传输或存储的序列化形式,所以在很多传输和存储的过程中需要将 byte[] 数组和String进行相互转化,byte是字节,char是字符,字节流跟字符流之间转化肯定需要指定编码,不然很可能会出现乱码, bytes 字节流是使用 charset 进行编码的,想要将他转换成 unicode 的 char[] 数组,而又保证不出现乱码,那就要指定其解码方式
通过"SB"构造
···
public String(StringBuffer buffer) {
synchronized(buffer) {
this.value = Arrays.copyOf(buffer.getValue(), buffer.length());
}
}
public String(StringBuilder builder) {
this.value = Arrays.copyOf(builder.getValue(), builder.length());
}
···
很多时候我们不会这么去构造,因为StringBuilder跟StringBuffer有toString方法,如果不考虑线程安全,优先选择StringBuilder。
equals方法
public boolean equals(Object anObject) { if (this == anObject) { return true;
} if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length; if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false;
i++;
} return true;
}
} return false;
}2.再判断是否是String类型
3.如果都是String类型,就先比较长度是否相等,然后在比较值
hashcode方法
public int hashCode() {
int h = hash; if (h == 0 && value.length > 0) {
char val[] = value; for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
} hash = h;
} return h;
}1.如果String的length==0或者hash值为0,则直接返回0
2.上述条件不满足,则通过算法s[0]31^(n-1) + s[1]31^(n-2) + ... + s[n-1]计算hash值
我们知道,hash值很多时候用来判断两个对象的值是否相等,所以需要尽可能保证唯一性,前面在分析HashMap原理的时候曾经提到过,冲突越少查询的效率也就越高。
intern方法
public native String intern();Returns a canonical representation for the string object. A pool of strings, initially empty, is maintained privately by the class . When the intern method is invoked, if the pool already contains a string equal to this object as determined by the method, then the string from the pool is returned. Otherwise, this object is added to the pool and a reference to this object is returned. It follows that for any two strings { s} and { t}, { s.intern() == t.intern()} is { true}if and only if {s.equals(t)} is { true}.
返回一个当前String的一个固定表示形式。String的常量池,初始化为空,被当前类维护。当此方法被调用的时候,如果常量池中包含有跟当前String值相等的常量,这个常量就会被返回。否则,当前string的值就会被加入常量池,然后返回当前String的引用。如果两个String的intern()调用==时返回true,那么equals方法也是true.
翻译完了,其实就是一句话,如果常量池中有当前String的值,就返回这个值,如果没有就加进去,返回这个值的引用,看起来很厉害的样子。
String对“+”的重载
我们知道,"+"跟"+="是Java中仅有的两个重载操作符,除此之外,Java不支持其它的任何重载操作符,下面通过反编译来看一下Java是如何进行重载的:
public static void main(String[] args) {
String str1="wustor";
String str2= str1+ "android";
}反编译Main.java,执行命令 javap -c Main,输出结果
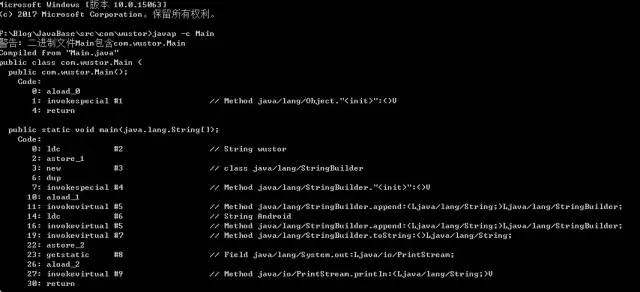
可能看不懂所有的代码,但是我们看到了StringBuilder,然后看到了wustor跟Android,以及调用了StringBuilder的append方法。既然编译器已经在底层为我们进行优化,那么为什么还要提倡我们有StringBuilder呢?
我们仔细观察一下上面的第三行代码,new 了一个StringBuilder对象,如果有是在一个循环里面,我们使用"+"号进行重载的话就会创建多个StringBuilder的对象,而且,即时编译器都帮我们优化了,但是编译器事先是不知道我们StringBuilder的长度的,并不能事先分配好缓冲区,也会加大内存的开销,而且使用重载的时候根据java的内存分配也会创建多个对象,那么为什么要使用StringBuilder呢,我们稍后会分析。
switch
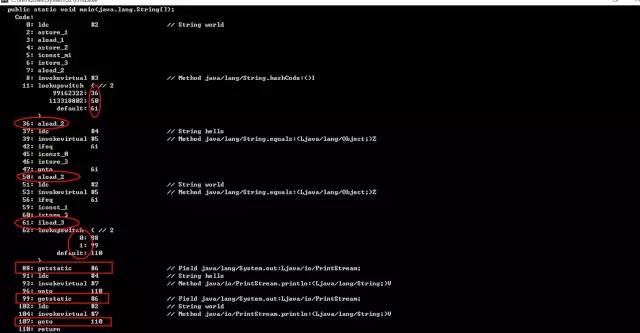
1.首先调用String的HashCode方法,拿到相应的Code
2.通过这个code然后给每个case唯一的标识
3.通过标识来执行相应的操作
我觉得挺好奇,所以接着查看一下如果是char类型的看看switch是怎么转换的
public static void main(String[] args) {
char ch = 'a';
switch (ch) { case 'a':
System.out.println("hello"); break; case 'b':
System.out.println("world"); break;
default: break;
}
}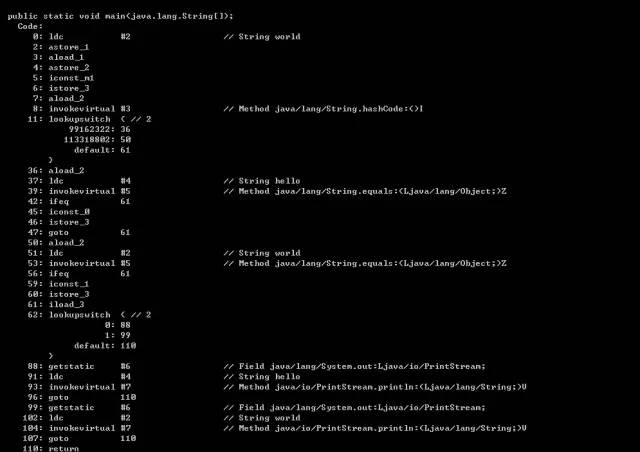
基本上跟String差不多,就不多解释了,由此可以看出,Java对String的Switch支持实际上也还是对int类型的支持。
StringBuilder
由于String对象是不可变的,所以在重载的时候会创建多个对象,而StringBuilder对象是可变的,可以直接使用append方法来进行拼接,下面看看StringBuilder的拼接。
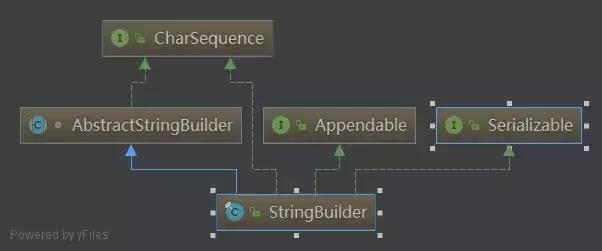
public final class StringBuilder extends AbstractStringBuilder
implements java.io.Serializable, CharSequence
{
// 空的构造方法
public StringBuilder () {
super(16);
}
//给予一个初始化容量
public StringBuffer(int capacity) {
super(capacity);
}
//使用String进行创建
public StringBuffer(String str) {
super(str.length() + 16);
append(str);
}
@Override
public StringBuilder append(CharSequence s) {
super.append(s); return this;
}我们看到StringBuilder都是在调用父类的方法,而且通过继承关系,我们知道它是AbstractStringBuilder 的子类,那我们就继续查看它的父类,AbstractStringBuilder 实现了Appendable跟CharSequence 接口,所以它能够跟String相互转换
成员变量
char[] value;//字符数组
int count;//字符数量构造方法
AbstractStringBuilder() {
}
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}可以看到AbstractStringBuilder只有两个构造方法,一个为空实现,还有一个为指定字符数组的容量,如果事先知道String的长度,并且这个长度小于16,那么就可以节省内存空间。他的数组和String的不一样,因为成员变量value数组没有被final修饰所以可以修改他的引用变量的值,即可以引用到新的数组对象。所以StringBuilder对象是可变的
append方法
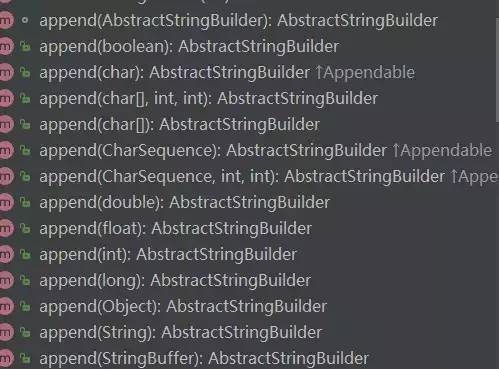
通过图片可以看到,append有很多重载方法,其实原理都差不多,我们拿char举例子
@Override
public AbstractStringBuilder append(char c) {
ensureCapacityInternal(count + 1);//检测容量
value[count++] = c; return this;
}
//判断当前字节数组的容量是否满足需求
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code if (minimumCapacity - value.length > 0)
//目前所需容量超出value数组的容量,进行扩容
expandCapacity(minimumCapacity);
}
//开始扩容
void expandCapacity(int minimumCapacity) {
//将现有容量扩充至value数组的2倍多2
int newCapacity = value.length * 2 + 2; if (newCapacity - minimumCapacity < 0)
//如果扩容后的长度比需要的长度还小,则跟需要的长度进行交换
newCapacity = minimumCapacity; if (newCapacity < 0) { if (minimumCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
//将数组扩容拷贝
value = Arrays.copyOf(value, newCapacity);
}insert方法
insert也有很多重载方法,下面同样以char为例
public AbstractStringBuilder insert(int offset, char c) { //检测是否需要扩容 ensureCapacityInternal(count + 1); //拷贝数组 System.arraycopy(value, offset, value, offset + 1, count - offset); //进行赋值 value[offset] = c; count += 1; return this; }
StringBuffer
跟StringBuilder差不多,只不过在所有的方法上面加了一个同步锁而已,不再赘述。
equals与==
| 创建方式 | 对象个数 | 引用指向 |
|---|---|---|
| String a="wustor" | 1 | 常量池 |
| String b=new String("wustor") | 1 | 堆内存 |
| String c=new String() | 1 | 堆内存 |
| String d="wust"+"or" | 3 | 常量池 |
| String e=a+b | 3 | 堆内存 |
其他常用方法
valueOf() 转换为字符串
trim() 去掉起始和结尾的空格
substring() 截取字符串
indexOf() 查找字符或者子串第一次出现的地方
toCharArray()转换成字符数组
getBytes()获取字节数组
charAt() 截取一个字符
length() 字符串的长度
toLowerCase() 转换为小写
总结
String被final修饰,一旦被创建,无法更改
String类的所有方法都没有改变字符串本身的值,都是返回了一个新的对象。
如果你需要一个可修改的字符串,应该使用StringBuilder或者 StringBuffer。
如果你只需要创建一个字符串,你可以使用双引号的方式,如果你需要在堆中创建一个新的对象,你可以选择构造函数的方式。
在使用StringBuilder时尽量指定大小这样会减少扩容的次数,有助于提升效率。
字符串内容判断,不要简单的使用
==,要使用"abc".equals(String)的形式。常量池的存在,提高了效率,减少了开销。
以上是关于Java源码分析——String的主要内容,如果未能解决你的问题,请参考以下文章
Java高频词之--String(从源码角度分析String 对象)
Android 插件化VirtualApp 源码分析 ( 目前的 API 现状 | 安装应用源码分析 | 安装按钮执行的操作 | 返回到 HomeActivity 执行的操作 )(代码片段
Android 逆向整体加固脱壳 ( DEX 优化流程分析 | DexPrepare.cpp 中 dvmOptimizeDexFile() 方法分析 | /bin/dexopt 源码分析 )(代码片段
Android 事件分发事件分发源码分析 ( Activity 中各层级的事件传递 | Activity -> PhoneWindow -> DecorView -> ViewGroup )(代码片段