转载JVM源码分析之String.intern()导致的YGC不断变长
Posted 非功能之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了转载JVM源码分析之String.intern()导致的YGC不断变长相关的知识,希望对你有一定的参考价值。
概述
之所以想写这篇文章,是因为YGC过程对我们来说太过于黑盒,如果对YGC过程不是很熟悉,这类问题基本很难定位,我们就算开了GC日志,也最多能看到类似下面的日志。
[GC (Allocation Failure) [ParNew: 91807K->10240K(92160K), 0.0538384 secs] 91807K->21262K(2086912K), 0.0538680 secs]
[Times: user=0.16 sys=0.06, real=0.06 secs]
只知道耗了多长时间,但是具体耗在了哪个阶段,是基本看不出来的,所以要么就是靠经验来定位,要么就是对代码相当熟悉,脑袋里过一遍整个过程,看哪个阶段最可能,今天要讲的这个大家可以当做今后排查这类问题的一个经验来使,这个当然不是唯一导致YGC过长的一个原因,但却是最近我帮忙定位碰到的发生相对来说比较多的一个场景。
Demo
先上一个demo,来描述下问题的情况,代码很简单,就是不断创建UUID,其实就是一个字符串,并将这个字符串调用下intern方法:
我们使用的JVM参数如下:
-XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -Xmx2G -Xms2G -Xmn100M
这里特意将新生代设置比较小,老生代设置比较大,让代码在执行过程中更容易突出问题来,大量做ygc,期间不做CMS GC,于是我们得到的输出结果类似下面的:
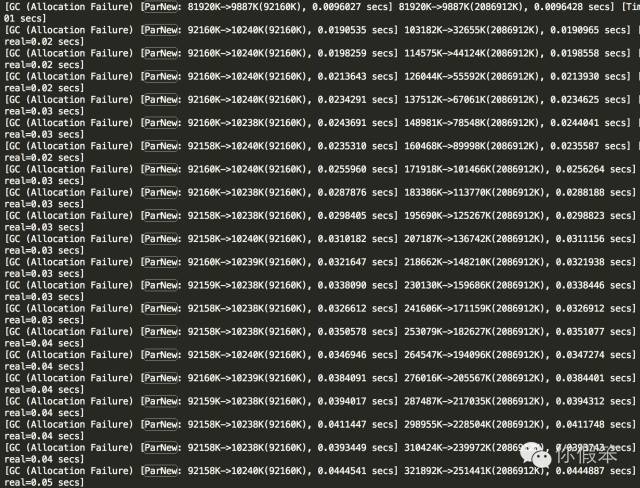
有没有发现YGC不断发生,并且发生的时间不断在增长,从10ms慢慢增长到了40ms,甚至还会继续涨下去。
String.intern方法
从上面的demo我们能挖掘到的可能就是intern这个方法了,那我们先来了解下intern方法的实现,这是String提供的一个方法,jvm提供这个方法的目的是希望对于某个同名字符串使用非常多的场景,在jvm里只保留一份,比如我们不断new String(“a”),其实在java heap里会有多个String的对象,并且值都是a,如果我们只希望内存里只保留一个a,或者希望我接下来用到的地方都返回同一个a,那就可以用String.intern这个方法了,用法如下:
String a = "a".intern();
...
String b = a.intern();这样b和a都是指向内存里的同一个String对象,那JVM里到底怎么做到的呢?
我们看到intern这个方法其实是一个native方法,具体对应到JVM里的逻辑是:
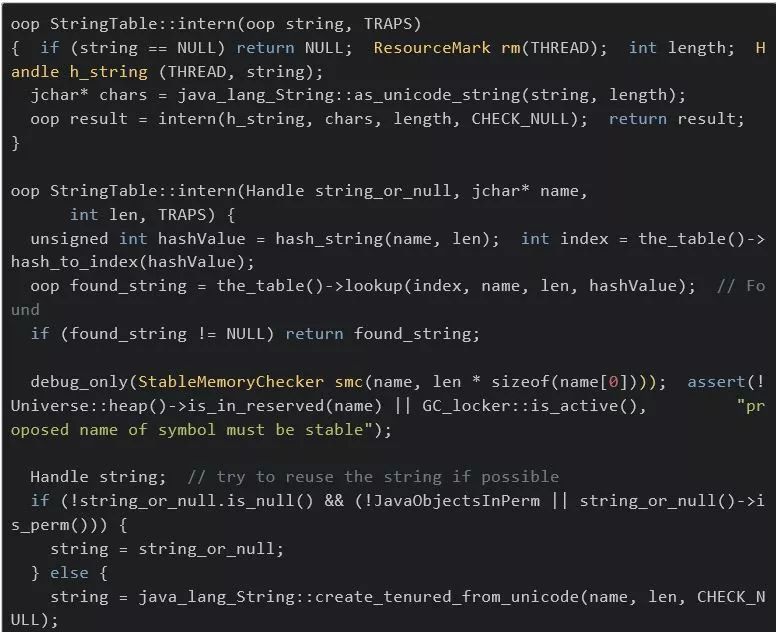
也就是说是其实在JVM里存在一个叫做StringTable的数据结构,这个数据结构是一个Hashtable,在我们调用String.intern的时候其实就是先去这个StringTable里查找是否存在一个同名的项,如果存在就直接返回对应的对象,否则就往这个table里插入一项,指向这个String对象,那么再下次通过intern再来访问同名的String对象的时候,就会返回上次插入的这一项指向的String对象。
至此大家应该知道其原理了,另外我这里还想说个题外话,记得几年前tomcat里爆发的一个HashMap导致的hash碰撞的问题,这里其实也是一个Hashtable,所以也还是存在类似的风险,不过JVM里提供一个参数专门来控制这个table的size,-XX:StringTableSize,这个参数的默认值如下:
product(uintx, StringTableSize, NOT_LP64(1009) LP64_ONLY(60013),
"Number of buckets in the interned String table")
另外JVM还会根据hash碰撞的情况来决定是否做rehash,比如你从这个StringTable里查找某个字符串是否存在,如果对其对应的桶挨个遍历,超过了100个还是没有找到对应的同名的项,那就会设置一个flag,让下次进入到safepoint的时候做一次rehash动作,尽量减少碰撞的发生,但是当恶化到一定程度的时候,其实也没啥办法啦,因为你的数据量实在太大,桶子数就那么多,那每个桶再怎么均匀也会带着一个很长的链表,所以此时我们通过修改上面的StringTableSize将桶数变大,可能会一定程度上缓解,但是如果是java代码的问题导致泄露,那就只能定位到具体的代码进行改造了。
StringTable为什么会影响YGC
YGC的过程我不打算再这篇文章里细说,因为我希望尽量保持每篇文章的内容不过于臃肿,有机会可以单独写篇文章来介绍,我这里将列出ygc过程里StringTable这块的具体代码:
因为YGC过程不涉及到对perm做回收,因此collecting_perm_gen是false,而JavaObjectsInPerm默认情况下也是false,表示String.intern返回的字符串是不是在perm里分配,如果是false,表示是在heap里分配的,因此StringTable指向的字符串是在heap里分配的,所以ygc过程需要对StringTable做扫描,以保证处于新生代的String代码不会被回收掉。
至此大家应该明白了为什么YGC过程会对StringTable扫描。
有了这一层意思之后,YGC的时间长短和扫描StringTable有关也可以理解了,设想一下如果StringTable非常庞大,那是不是意味着YGC过程扫描的时间也会变长呢?
YGC过程扫描StringTable对CPU影响大吗
这个问题其实是我写这文章的时候突然问自己的一个问题,于是稍微想了下来跟大家解释下,因为大家也可能会问这么个问题。
要回答这个问题我首先得问你们的机器到底有多少个核,如果核数很多的话,其实影响不是很大,因为这个扫描的过程是单个GC线程来做的,所以最多消耗一个核,因此看起来对于核数很多的情况,基本不算什么。
StringTable什么时候清理
YGC过程不会对StringTable做清理,这也就是我们demo里的情况会让Stringtable越来越大,因为到目前为止还只看到YGC过程,但是在Full GC或者CMS GC过程会对StringTable做清理,具体验证很简单,执行下jmap -histo:live <pid>,你将会发现YGC的时候又降下去了。
本文写作时间
利用午饭前的一点时间写下 2016/11/06 12:00~12:40
另外如果觉得文章对您有收获,请点赞并分享,这是让我一直写下去的动力所在,谢谢!
以上是关于转载JVM源码分析之String.intern()导致的YGC不断变长的主要内容,如果未能解决你的问题,请参考以下文章