蚂蚁金服分布式链路跟踪组件 SOFATracer 数据上报机制和源码分析 | 剖析
Posted 金融级分布式架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了蚂蚁金服分布式链路跟踪组件 SOFATracer 数据上报机制和源码分析 | 剖析相关的知识,希望对你有一定的参考价值。
SOFA
Scalable Open Financial Architecture
是蚂蚁金服自主研发的金融级分布式中间件,包含了构建金融级云原生架构所需的各个组件,是在金融场景里锤炼出来的最佳实践。
SOFATracer 是一个用于分布式系统调用跟踪的组件,通过统一的 TraceId 将调用链路中的各种网络调用情况以日志的方式记录下来,以达到透视化网络调用的目的,这些链路数据可用于故障的快速发现,服务治理等。
本文为《剖析 | SOFATracer 框架》第二篇。《剖析 | SOFATracer 框架》系列由 SOFA 团队和源码爱好者们出品,项目代号:<SOFA:TracerLab/>,目前领取已经完成,感谢大家的参与。
SOFATracer:
https://github.com/alipay/sofa-tracer
0、前言
在《》一文中已经对 SOFATracer 进行了概要性的介绍。从对 SOFATracer 的定义可以了解到,SOFATracer 作为一个分布式系统调用跟踪的组件,是通过统一的 TraceId 将调用链路中的各种网络调用情况以数据上报的方式记录下来,以达到透视化网络调用的目的。
本篇将针对SOFATracer的数据上报方式进行详细分析,以帮助大家更好的理解 SOFATracer 在数据上报方面的扩展。
1、Reporter 整体模型
本节将对 SOFATracer 的 Report 模型进行整体介绍,主要包括两个部分:
1、Reporter 的接口设计及实现;
2、数据上报流程。
1.1、Reporter 的接口设计及实现
数据上报是 SofaTracer 基于 OpenTracing Tracer 接口扩展实现出来的功能;Reporter 实例作为 SofaTracer 的属性存在,在构造 SofaTracer 实例时,会初始化 Reporter 实例。
1.1.1、Reporter 接口设计
Reporter 接口是 SOFATracer 中对于数据上报的顶层抽象,核心接口方法定义如下:
//获取 Reporter 实例类型
String getReporterType();
//输出 span
void report(SofaTracerSpan span);
//关闭输出 span 的能力
void close();
Reporter 接口的设计中除了核心的上报功能外,还提供了获取 Reporter 类型的能力,这个是因为 SOFATracer 目前提供的埋点机制方案需要依赖这个实现。
1.1.2、Reporter 接口实现
Reporter 的类体系结构如下: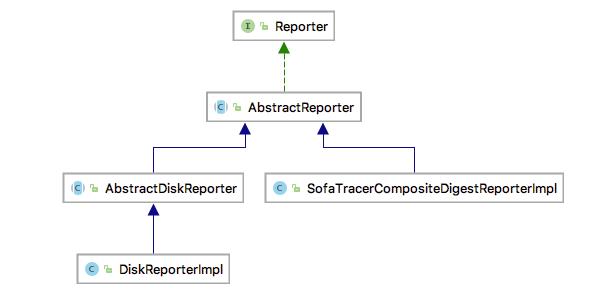
Reporter 的实现类有两个,SofaTracerCompositeDigestReporterImpl 和 DiskReporterImpl :
SofaTracerCompositeDigestReporterImpl:
组合摘要日志上报实现,上报时会遍历当前 SofaTracerCompositeDigestReporterImpl 中所有的 Reporter ,逐一执行 report 操作;可供外部用户扩展使用。
DiskReporterImpl:
数据落磁盘的核心实现类,也是目前 SOFATracer 中默认使用的上报器。
1.2、数据上报流程分析
数据上报实际都是由不同的链路组件发起,关于插件扩展机制及埋点方式不是本篇范畴,就不展开了。这里直接来看数据上报的入口。
在 Opentracing 规范中提到,Span#finish 方法是 span 生命周期的最后一个执行方法,也就意味着一个 span 跨度即将结束。那么当一个 span 即将结束时,也是当前 span 具有最完整状态的时候。所以在 SOFATracer 中,数据上报的入口就是 Span#finish 方法,这里贴一小段代码:
//SofaTracerSpan#finish
@Override
public void finish(long endTime) {
this.setEndTime(endTime);
//关键记录:report span
this.sofaTracer.reportSpan(this);
SpanExtensionFactory.logStoppedSpan(this);
}
在 finish 方法中,通过 SofaTracer#reportSpan 将当前 span 进行了上报处理。以这个为入口,整个数据上报的调用链路如下图所示:
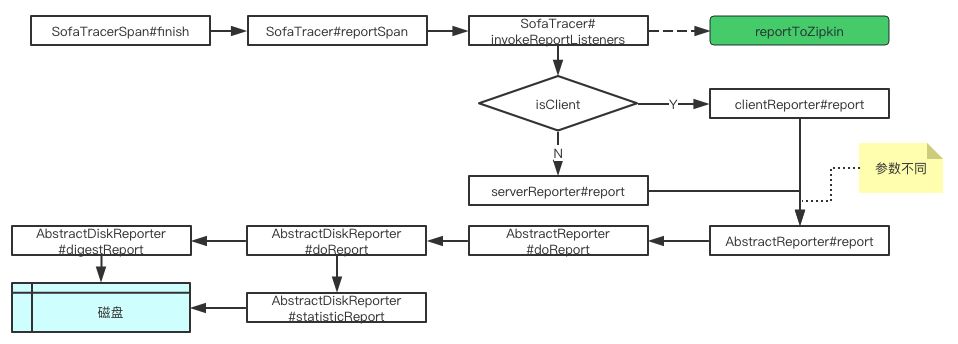
整个上报调用流程其实并不是很难,这里留两个问题:
如何构造 clientRportor 和 serverReporter 的,依据是什么?
摘要日志和统计日志是怎么落盘的?
第一个问题会在插件埋点解析篇中给出答案;第二个问题下面来看。
2、日志落盘
前面已经提到,SOFATracer 本身提供了两种上报模式,一种是落到磁盘,另外一种是上报到zipkin。在实现细节上,SOFATracer 没有将这两种策略分开以提供独立的功能支持,而是将两种上报方式组合在了一起,然后再通过配置参数来控制是否进行具体的上报逻辑,具体参考下图: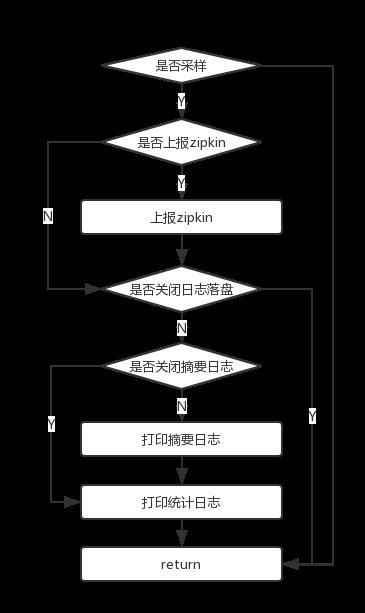
本节将来剖析下日志落盘的实现细节。日志落盘又分为摘要日志落盘 和 统计日志落盘;摘要日志是每一次调用均会落地磁盘的日志;统计日志是每隔一定时间间隔进行统计输出的日志。
2.1、摘要日志落盘
摘要日志落盘是基于 Disruptor 高性能无锁循环队列实现的。SOFATracer 中,AsyncCommonDigestAppenderManager 类对 disruptor 进行了封装,用于处理外部组件的 Tracer 摘要日志打印。
关于 Disruptor 的原理及其自身的事件模型此处不展开分析,有兴趣的同学可以自行查阅相关资料。这里直接看下 SOFATracer 中是如何使用 Disruptor 的。
2.1.1、消息事件模型
SOFATracer 使用了两种不同的事件模型,一种是 SOFATracer 内部使用的 StringEvent,一种是外部扩展使用的 SofaTacerSpanEvent。详见:SofaTracerSpanEvent & StringEvent 。
2.1.2、Consumer 消费者
Consumer 是 AsyncCommonDigestAppenderManager 的内部类;实现了 EventHandler 接口,这个 Consumer 作为消费者存在,监听事件,然后通过 TraceAppender 将 span 数据 flush 到磁盘。详见:AsyncCommonDigestAppenderManager
2.1.3、Disruptor 的初始化
Disruptor 的构建:在 AsyncCommonDigestAppenderManager 的构造函数中完成的。
//构建disruptor,使用的是 ProducerType.MULTI
//等待策略是 BlockingWaitStrategy,考虑到的是CPU的使用率和一致性
disruptor = new Disruptor<SofaTracerSpanEvent>(new SofaTracerSpanEventFactory(),
realQueueSize, threadFactory, ProducerType.MULTI, new BlockingWaitStrategy());
异常处理:如果在消费的过程中发生异常,SOFATracer 将会通过自定义的 ConsumerExceptionHandler 异常处理器把异常信息打到 tracer-self.log 中。
对于打印相关的参数条件设定,比如是否允许丢弃消息、是否记录丢失日志的数量、是否记录丢失日志的 TraceId 和 RpcId、丢失日志的数量达到某阈值进行一次日志输出等。
2.1.4、启动 Disruptor
Disruptor 的启动委托给了 AsyncCommonDigestAppenderManager#start 方法来执行。
public void start(final String workerName) {
this.threadFactory.setWorkName(workerName);
this.ringBuffer = this.disruptor.start();
}
查看调用栈,看下 SOFATracer 中具体是在哪里调用这个 start 的:
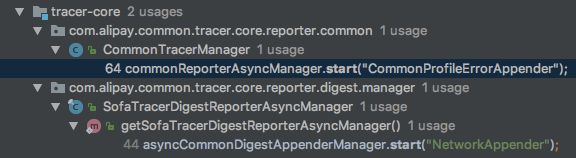
CommonTracerManager : 这里面持有了 AsyncCommonDigestAppenderManager 类的一个单例对象,并且在 static 静态代码块中调用了 start 方法;这个用来输出普通中间件日志。
SofaTracerDigestReporterAsyncManager:这里类里面也是持有了AsyncCommonDigestAppenderManager 类的一个单例对像,并且提供了getSofaTracerDigestReporterAsyncManager 方法来获取该单例,在这个方法中调用了 start 方法;该对象用来输出摘要日志。
2.1.5、发布事件
发布事件,也就意味着当前需要产生一个 span 记录,这个过程也是在 finish 方法的调用栈中,也就是上图中DiskReporterImpl#digestReport 这个方法。
AsyncCommonDigestAppenderManager asyncDigestManager = SofaTracerDigestReporterAsyncManager
.getSofaTracerDigestReporterAsyncManager();
// ...
asyncDigestManager.append(span);
// ...
这里将 span 数据 append 到环形缓冲区,根据 AsyncCommonDigestAppenderManager 的初始化属性,如果允许丢弃,则使用 tryNext 尝试申请序列,申请不到抛出异常;否则使用 next() 阻塞模式申请序列。下面是一个简易的模拟图: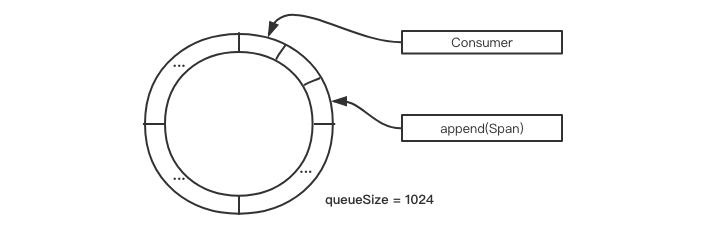
2.1.6、小结
摘要日志的落盘依赖于 Disruptor 的事件模型,当 span#finish 方法执行时,触发 SofaTracer 的 report 行为;report 最终会将当前 span 数据放入 Disruptor 队列中去,发布一个 SofaTracerSpanEvent 事件。Disruptor 的消费者 EventHandler 实现类 Consumer 会监听当前队列事件,然后在回调函数 onEvent 中将 span 数据刷新到磁盘中。
2.2、统计日志落盘实现
统计日志的作用是为了监控统计使用,其记录了当前跨度的调用次数、执行结果等数据。统计日志是每隔一定时间间隔进行统计输出的日志,因此很容易想到是使用定期任务来执行的。这里同样来跟踪下统计日志打印的方法调用过程。
2.2.1、统计日志的调用链路

AbstractSofaTracerStatisticReporter 的 doReportStat 方法是个抽象方法,那这里又是与插件扩展部分联系在一块的:

可以看到 AbstractSofaTracerStatisticReporter 的实现类均是在 SOFATracer plugins 包下,也就是说统计日志打印需要由不同的扩展插件来定义实现。但是实际上不同的插件在重写 doReportStat 方法时也并非是直接将 span 数据 flush 到磁盘的,而是将 SofaTracerSpan 转换成 StatMapKey 然后塞到了 AbstractSofaTracerStatisticReporter 中的一个 map 结构对象中。具体细节详见:AbstractSofaTracerStatisticReporter#addStat。
2.2.2、统计日志的打印模型
前面提到,统计日志的落盘具有一定的周期性,因此在统计日志落盘的设计上,SOFATracer 没有像摘要日志落盘那样依赖于 Disruptor 来实现。下面先通过一张简单的结构图来看下摘要日志的工作模型:
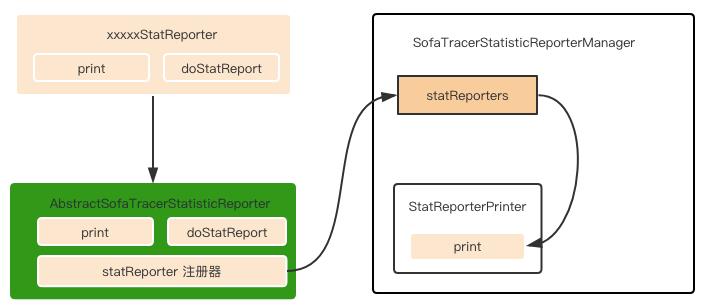
xxxxxStatReporter : 插件扩展方实现的统计日志 Reporter 类,重写了 doStatReport 和 print 两个方法。
AbstractSofaTracerStatisticReporter : 用于扩展的抽象类,xxxxxStatReporter 就是该类的子类;AbstractSofaTracerStatisticReporter 在其构造函数中,通过 SofaTracerStatisticReporterCycleTimesManager 将当前 statReporter 注册到 SofaTracerStatisticReporterManager 中,统一存放在 statReporters 集合中。
SofaTracerStatisticReporterManager : 统计日志 reporter 管理器,所有插件扩展的 reporter 都会被注册到这个manager 类里面来。其内部类 StatReporterPrinter 实现了runnable 接口,并在 run 方法中遍历 statReporters,逐一调用 print 方法将数据刷到磁盘中。
SofaTracerStatisticReporterManager 在构造函数中初始化了任务执行的周期、ScheduledExecutorService 实例初始化,并且将 StatReporterPrinter 提交到定时任务线程池中,从而实现了周期性输出统计日志的功能。
3、上报 Zipkin
前面对 SOFATracer 中的数据落盘进行了分析,最后再来看下 SOFATracer 中是如何把数据上报至 zipkin 的。
3.1.1、上报 zipkin 的流程
接着上面的分析,SOFATracer 中的数据上报策略是以组合的形式共存的,这里可以结合 第2节的第一张图 来看。这里先给出 zipkin 上报的流程,然后再结合流程展开分析:
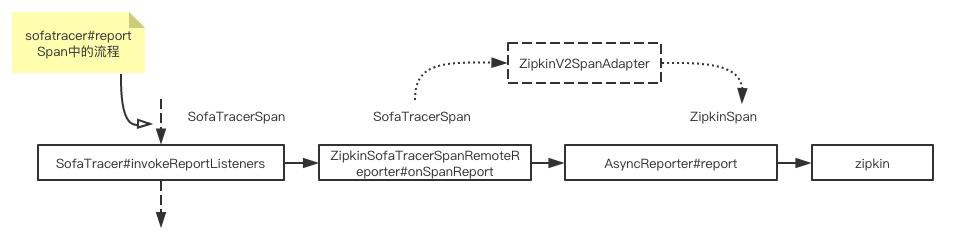
在SofaTracer#reportSpan 中有一个方法是 invokeReportListeners;该方法的作用就是遍历当前所有的SpanReportListener 实现类,逐一回调 SpanReportListener 的 onSpanReport 方法。
ZipkinSofaTracerSpanRemoteReporter 是 sofa-tracer-zipkin-plugin 插件中提供的一个实现了 SpanReportListener 接口的类,并在 onSpanReport 回调函数中通过 zipkin2.reporter.AsyncReporter 实例对象将 span 数据上报至 zipkin。
虽然 SOFATracer 和 zipkin 均是基于 OpenTracing 规范,但是在具体实现上 SOFATracer 做了很多扩展,因此需要通过一个 ZipkinV2SpanAdapter 将 SofaTracerSpan 适配成 zipkin2.Span。
zipkin2.reporter.AsyncReporter 是 zipkin 提供的一个数据上报抽象类,默认实现是 BoundedAsyncReporter,其内部通过一个守护线程 flushThread,一直循环调用 BoundedAsyncReporter 的 flush 方法,将内存中的 span 信息上报给 zipkin。
3.1.2、对非 SpringBoot 应用的上报支持
上报 zipkin 的能力做过一次改动,主要是对于在非SpringBoot应用(也就是Spring工程)的支持,具体参考 issue:建议不用spring boot也可以使用sofa-tracer并且上报zipkin 。
对于 SpringBoot 工程来说,引入 tracer-sofa-boot-starter 之后,自动配置类 SofaTracerAutoConfiguration 会将当前所有 SpanReportListener 类型的 bean 实例保存到 SpanReportListenerHolder 的 List 对象中。而SpanReportListener 类型的 Bean 会在 ZipkinSofaTracerAutoConfiguration 自动配置类中注入到当前 Ioc 容器中。这样 invokeReportListeners 被调用时,就可以拿到 zipkin 的上报类,从而就可以实现上报。
对于非 SpringBoot 应用的上报支持,本质上是需要实例化 ZipkinSofaTracerSpanRemoteReporter 对象,并将此对象放在 SpanReportListenerHolder 的 List 对象中。所以 SOFATracer 在 zipkin 插件中提供了一个ZipkinReportRegisterBean,并通过实现 Spring 提供的 bean 生命周期接口 InitializingBean,在ZipkinReportRegisterBean 初始化之后构建一个 ZipkinSofaTracerSpanRemoteReporter 实例,并交给SpanReportListenerHolder 类管理。
3.1.3、Zipkin 上报案例及展示
关于 SpringBoot 工程使用 zipkin 上报案例请参考:上报数据到 zipkin
关于 spring 应用中使用 zipkin 上报插件请参考:tracer-zipkin-plugin-demo
Services 展示

链路依赖展示

4、总结
4.1、SOFATracer 在数据上报模型上的考虑
了解或者使用过 SOFATracer 的同学应该知道, SOFATracer 目前并没有提供数据采集器和 UI 展示的功能;主要有两个方面的考虑:
SOFATracer 作为 SOFA 体系中一个非常轻量的组件,意在将 span 数据以日志的方式落到磁盘,以便于用户能够更加灵活的来处理这些数据
UI 展示方面,SOFATracer 本身基于 OpenTracing 规范实现,在模型上与开源的一些产品可以实现无缝对接,在一定程度上可以弥补本身在链路可视化方面的不足。
因此在上报模型上,SOFATracer 提供了日志输出和外部上报的扩展,方便接入方能够足够灵活的方式来处理上报的数据。
4.2、文章小结
通过本文大家对 SOFATracer 数据上报功能应该有了一个大体的了解,对于内部的实现细节,由于篇幅和文章阅读性等原因,不宜贴过多代码,希望有兴趣的同学可以直接阅读源码,对其中的一些细节进行了解。数据上报作为 SOFATracer 核心扩展能力之一,虽不同的上报途径对应不同的上报模型,但是整体结构上还是比较清晰的,所以理解起来不是很难。
最后感谢大家对 SOFATracer 的关注,如果您在了解和使用此组件的过程中有任何疑问,欢迎联系我们。
欢迎加入,参与 SOFATracer 源码解析【已领取完毕】
本文作为《剖析 | SOFATracer 组件系列》第一篇,主要还是希望大家对 SOFATracer 组件有一个认识和了解,之后,我们会逐步详细介绍每部分的代码设计和实现,预计会按照如下的目录进行:
分布式链路跟踪组件
SOFATracer概述【已完成】SOFATracer API组件埋点机制和源码分析【已完成】SOFATracer链路透传原理与SLF4J MDC的扩展能力分析【已领取】SOFATracer的采样策略和源码分析【已领取】SOFATracer数据上报机制和源码分析【已领取】
文中提到的链接:
Disruptor :
https://github.com/LMAX-Exchange/disruptor
SofaTracerSpanEvent:
https://github.com/alipay/sofa-tracer/blob/master/tracer-core/src/main/java/com/alipay/common/tracer/core/appender/manager/SofaTracerSpanEvent.java
StringEvent:
https://github.com/alipay/sofa-tracer/blob/master/tracer-core/src/main/java/com/alipay/common/tracer/core/appender/manager/StringEvent.java
AsyncCommonDigestAppenderManager:
https://github.com/alipay/sofa-tracer/blob/master/tracer-core/src/main/java/com/alipay/common/tracer/core/appender/manager/AsyncCommonDigestAppenderManager.java
[AbstractSofaTracerStatisticReporter#addStat]:
https://github.com/alipay/sofa-tracer/blob/master/tracer-core/src/main/java/com/alipay/common/tracer/core/reporter/stat/AbstractSofaTracerStatisticReporter.java
issue:建议不用spring boot也可以使用sofa-tracer并且上报zipkin:
https://github.com/alipay/sofa-tracer/issues/32
上报数据到 zipkin:
https://www.sofastack.tech/sofa-tracer/docs/ReportToZipkin
tracer-zipkin-plugin-demo:
https://github.com/glmapper/tracer-zipkin-plugin-demo
长按关注,获取分布式架构干货
欢迎大家共同打造 SOFAStack https://github.com/alipay
以上是关于蚂蚁金服分布式链路跟踪组件 SOFATracer 数据上报机制和源码分析 | 剖析的主要内容,如果未能解决你的问题,请参考以下文章
蚂蚁金服黑科技:SOFA DTX分布式事务,保障亿级资金操作一致性
开源 |蚂蚁金服启动分布式中间件开源计划,用于快速构建金融级云原生架构
开源 | 蚂蚁金服分布式中间件开源第二弹:丰富微服务架构体系
蚂蚁金服启动分布式中间件开源计划,用于快速构建金融级云原生架构