微服务发现与注册之Eureka源码分析
Posted 架构师社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微服务发现与注册之Eureka源码分析相关的知识,希望对你有一定的参考价值。
作者:陌北有棵树,Java人,架构师社区合伙人!
【一】微服务之服务发现概述
关于微服务,近年来可谓是大火,业界也吹刮着一种实践微服务的风潮。本人有幸在去年参与到一个向微服务过渡的产品,再结合自己所学的一些知识做一个总结,同时也是一个继续学习的过程。
如果说在实施微服务的所有经验中,挑出最重要的一点,那么我觉得应该是:
基础设施的建设决定微服务的实施效果
后面可能会写一篇关于具体踩坑的总结,大多也是关于基础设施组件的。如果在实施微服务的过程中,相应的基础设施没有配套跟上,是极有可能从一个坑跳到另一个坑中去的。
服务治理包括服务的注册和发现,是实施微服务过程中最基本的基础设施之一了。目前可以用作服务发现的组件主要有Eureka,Zookeeper,Consul,Etcd,在我们的项目中由于混用了Spring Cloud和Dubbo两套框架,所以Eureka和Zookeeper都有用到,本文先对Eureka进行分析,由于Zookeeper不属于专门的服务发现组件,具有多种功能,所以会专门做分析。
一个服务发现的服务端需要满足的需求:
服务注册:针对Client端的服务提供者,在启动时将自己注册到Server端。
服务发现:针对Client端的服务消费者,查询可用的服务列表。
服务列表保存:针对Server端,记录各个微服务的相关信息。
跨节点共享信息:针对Client端服务上线后,只会注册在一个服务端实例上,各个服务端之间要进行信息同步.
健康监测:监测已经注册的服务,如果长时间无法访问,则从列表中剔除。
我们现在提到的Eureka,总括了Netflix Eureka以及Spring Cloud Netflix包中对于Eureka的封装,但其实Netflix Eureka本身就已经是一套完整的基于REST的服务发现框架。Spring Cloud对于Eureka的集成,让它更容易的实施在微服务体系之中。
【二】Eureka源码分析
在阅读Eureka源码之前,我们尝试换一种思路,不像以往一样顺着流程去Debug,这次我们试着站在一个设计者的角度,假设这个服务注册中心是你接到的一个新需求,需要你完成从设计到实现,需求文档就是上一章节提到的,服务发现组件需要具备的功能。
首先,基本需求是必须实现的,也就是服务注册和发现,服务列表保存。我们把需要设计的点理顺清楚,再去看源码中是如何灵活运用各种技术提供了实现。
这样不单可以学到一些原理上的知识,更多的应该是学习为什么要这样设计,尽管是阅读别人的源码,也不要被动的接收,有主动思考的过程会更好。
那么我们首先梳理一下基本的注册流程如何实现?
首先,这个过程中有两种类型的三个角色,分别是Server和Client,Client又分为服务提供者,服务消费者,他们的交互关系如下图所示。
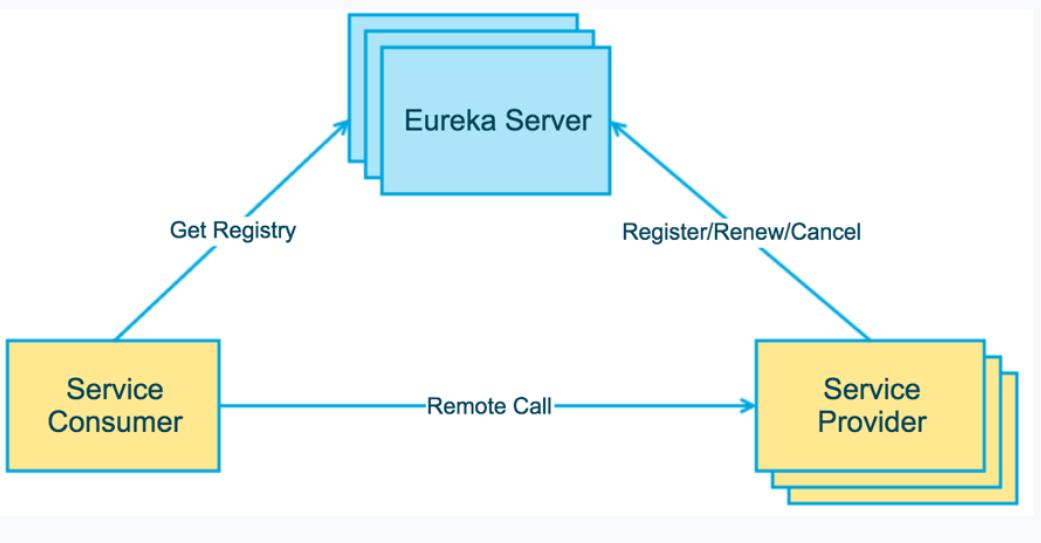
那么具体到每个步骤,我们应该有哪些设计思路呢?
Client端-服务提供者在启动时能注册到Eureka-Server中
客户端注册信息如何设计(Key-Value),key是serviceId,value是一个包含客户端信息的Object
客户端在启动时如何实例化这个对象,并注册到服务端
Server端保存服务信息,显然要设计为Map结构
Client端-服务消费者可以向Server获取服务列表,这里可以是服务端推送或者是客户端拉取的形式
【步骤一】服务提供者启动时注册
首先,我们在配置文件中做了一些Eureka相关的配置,所以【阅读目标一】如何读取这些配置。
然后,客户端是在启动过程中就完成了注册,所以【阅读目标二】如何结合SpringBoot的自动装配,完成启动过程中的初始化。
读取了配置并没有结束,是怎么在SpringBoot启动时完成了注册过程呢,所以【阅读目标三】启动时的注册过程。
接下来就开始这部分的源码阅读:
【阅读目标一】读取配置
SpringBoot的自动装配,一定会读取spring.factories文件,所以我们先来看spring-cloud-starter-netflix-eureka-client-2.1.2.RELEASE.jar的spring.factories文件
org.springframework.boot.autoconfigure.EnableAutoConfiguration=
org.springframework.cloud.netflix.eureka.config.EurekaClientConfigServerAutoConfiguration,
org.springframework.cloud.netflix.eureka.config.EurekaDiscoveryClientConfigServiceAutoConfiguration,
org.springframework.cloud.netflix.eureka.EurekaClientAutoConfiguration,
org.springframework.cloud.netflix.ribbon.eureka.RibbonEurekaAutoConfiguration,
org.springframework.cloud.netflix.eureka.EurekaDiscoveryClientConfiguration
org.springframework.cloud.bootstrap.BootstrapConfiguration=
org.springframework.cloud.netflix.eureka.config.EurekaDiscoveryClientConfigServiceBootstrapConfiguration【阅读目标二】SpringBoot自动装配
与Eureka自动装配有关的必然是org.springframework.cloud.netflix.eureka.EurekaClientAutoConfiguration
"eureka.instance.xxx"相关配置
在org.springframework.cloud.netflix.eureka.EurekaClientAutoConfiguration.EurekaClientConfiguration#eurekaApplicationInfoManager这个方法中,创建了InstanceInfo类型的实例,参数是EurekaInstanceConfig类型。
@Bean
@ConditionalOnMissingBean(value = ApplicationInfoManager.class, search = SearchStrategy.CURRENT)
public ApplicationInfoManager eurekaApplicationInfoManager(
EurekaInstanceConfig config) {
InstanceInfo instanceInfo = new InstanceInfoFactory().create(config);
return new ApplicationInfoManager(config, instanceInfo);
}EurekaInstanceConfig是一个接口,与Eureka相关的实现类是org.springframework.cloud.netflix.eureka.EurekaInstanceConfigBean,我们会看到在这里完成了自动装配,会构建"eureka.instance"这个实例需要的所有信息。
@ConfigurationProperties("eureka.instance")
public class EurekaInstanceConfigBean
implements CloudEurekaInstanceConfig, EnvironmentAware{
......
}"eureka.client.xxx"相关配置
在org.springframework.cloud.netflix.eureka.EurekaClientAutoConfiguration.RefreshableEurekaClientConfiguration#eurekaClient方法中创建了EurekaClient实例,把ApplicationInfoManager和EurekaClientConfig传入
@Bean(destroyMethod = "shutdown")
@ConditionalOnMissingBean(value = EurekaClient.class, search = SearchStrategy.CURRENT)
@org.springframework.cloud.context.config.annotation.RefreshScope
@Lazy
public EurekaClient eurekaClient(ApplicationInfoManager manager,
EurekaClientConfig config, EurekaInstanceConfig instance,
@Autowired(required = false) HealthCheckHandler healthCheckHandler) {
ApplicationInfoManager appManager;
if (AopUtils.isAopProxy(manager)) {
appManager = ProxyUtils.getTargetObject(manager);
}
else {
appManager = manager;
}
CloudEurekaClient cloudEurekaClient = new CloudEurekaClient(appManager,
config, this.optionalArgs, this.context);
cloudEurekaClient.registerHealthCheck(healthCheckHandler);
return cloudEurekaClient;
}【阅读目标三】启动时的注册过程
随着源码来到com.netflix.discovery.DiscoveryClient#DiscoveryClient
@Inject
DiscoveryClient(ApplicationInfoManager applicationInfoManager, EurekaClientConfig config, AbstractDiscoveryClientOptionalArgs args,
Provider<BackupRegistry> backupRegistryProvider, EndpointRandomizer endpointRandomizer) {
......
try {
// default size of 2 - 1 each for heartbeat and cacheRefresh
scheduler = Executors.newScheduledThreadPool(2,
new ThreadFactoryBuilder()
.setNameFormat("DiscoveryClient-%d")
.setDaemon(true)
.build());
heartbeatExecutor = new ThreadPoolExecutor(
1, clientConfig.getHeartbeatExecutorThreadPoolSize(), 0, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
new ThreadFactoryBuilder()
.setNameFormat("DiscoveryClient-HeartbeatExecutor-%d")
.setDaemon(true)
.build()
); // use direct handoff
cacheRefreshExecutor = new ThreadPoolExecutor(
1, clientConfig.getCacheRefreshExecutorThreadPoolSize(), 0, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
new ThreadFactoryBuilder()
.setNameFormat("DiscoveryClient-CacheRefreshExecutor-%d")
.setDaemon(true)
.build()
); // use direct handoff
......
// 初始化所有的 schedule tasks
initScheduledTasks();
}关于 @Inject注解,如果在构造方法使用,那么构造方法中的参数,将由IOC容器提供。
忽略一些参数判断的代码,我们看到定义了一些线程池,
然后,执行com.netflix.discovery.DiscoveryClient#initScheduledTasks方法,
private void initScheduledTasks() {
......
// Heartbeat timer
scheduler.schedule(
new TimedSupervisorTask(
"heartbeat",
scheduler,
heartbeatExecutor,
renewalIntervalInSecs,
TimeUnit.SECONDS,
expBackOffBound,
new HeartbeatThread()
),
renewalIntervalInSecs, TimeUnit.SECONDS);
......
}接下来我们以心跳线程池heartbeatExecutor为例分析,是如何向Server端注册的。
有一个new HeartbeatThread(),打开它的源码:
private class HeartbeatThread implements Runnable {
public void run() {
if (renew()) {
lastSuccessfulHeartbeatTimestamp = System.currentTimeMillis();
}
}
}乍一看似乎没有什么,但是小心有坑,有时秘密往往藏在不起眼的地方,就在com.netflix.discovery.DiscoveryClient#renew方法中。
/**
* Renew with the eureka service by making the appropriate REST call
*/
boolean renew() {
EurekaHttpResponse<InstanceInfo> httpResponse;
try {
httpResponse = eurekaTransport.registrationClient.sendHeartBeat(instanceInfo.getAppName(), instanceInfo.getId(), instanceInfo, null);
logger.debug(PREFIX + "{} - Heartbeat status: {}", appPathIdentifier, httpResponse.getStatusCode());
if (httpResponse.getStatusCode() == Status.NOT_FOUND.getStatusCode()) {
REREGISTER_COUNTER.increment();
logger.info(PREFIX + "{} - Re-registering apps/{}", appPathIdentifier, instanceInfo.getAppName());
long timestamp = instanceInfo.setIsDirtyWithTime();
boolean success = register();
if (success) {
instanceInfo.unsetIsDirty(timestamp);
}
return success;
}
return httpResponse.getStatusCode() == Status.OK.getStatusCode();
} catch (Throwable e) {
logger.error(PREFIX + "{} - was unable to send heartbeat!", appPathIdentifier, e);
return false;
}
}这个方法的流程是,先向服务端发起一次请求com.netflix.discovery.shared.transport.EurekaHttpClient#sendHeartBeat,如果当前实例没有被注册,会返回404,那么会执行com.netflix.discovery.DiscoveryClient#register进行注册。
【步骤二】Server端保存服务列表
想要了解Server端如何保存了服务列表,就要知道Server端如何接收Client端的HTTP请求。所以本步骤的阅读目标有两个,分别是服务提供者注册的后续部分,和Server端接收请求的部分。
【阅读目标一】走完客户端注册流程
如果想知道服务端是如何保存的,就需要进一步走完客户端的注册流程,之所以把最后的注册流程放在这里,是为了把一次HTTP请求-响应的过程放在一起。可想而知,客户端的注册会发送一个HTTP请求,将实例信息发送到服务端。
com.netflix.discovery.shared.transport.jersey.AbstractJerseyEurekaHttpClient#register,我们看到这里,使用了jersey框架,拼装了一个URL,发送了一个HTTP请求。
public EurekaHttpResponse<Void> register(InstanceInfo info) {
String urlPath = "apps/" + info.getAppName();
ClientResponse response = null;
try {
Builder resourceBuilder = jerseyClient.resource(serviceUrl).path(urlPath).getRequestBuilder();
addExtraHeaders(resourceBuilder);
response = resourceBuilder
.header("Accept-Encoding", "gzip")
.type(MediaType.APPLICATION_JSON_TYPE)
.accept(MediaType.APPLICATION_JSON)
.post(ClientResponse.class, info);
return anEurekaHttpResponse(response.getStatus()).headers(headersOf(response)).build();
} finally {
if (logger.isDebugEnabled()) {
logger.debug("Jersey HTTP POST {}/{} with instance {}; statusCode={}", serviceUrl, urlPath, info.getId(),
response == null ? "N/A" : response.getStatus());
}
if (response != null) {
response.close();
}
}
}【阅读目标二】Server端接收HTTP请求
先来看Server端的自动装配类,与之前的Client端类似,只是具体配置的内容不一样,先大概提一下,后面细说:
首先是spring-cloud-netflix-eureka-server-2.1.2.RELEASE.jar中的spring.factories文件
org.springframework.boot.autoconfigure.EnableAutoConfiguration=
org.springframework.cloud.netflix.eureka.server.EurekaServerAutoConfiguration我们猜想这里一定会注册一个Jersey客户端,用来接收HTTP请求,我们看到下面Jersey客户端被初始化为一个拦截器Bean放入Spring容器中。
@Bean
public FilterRegistrationBean jerseyFilterRegistration(
javax.ws.rs.core.Application eurekaJerseyApp) {
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new ServletContainer(eurekaJerseyApp));
bean.setOrder(Ordered.LOWEST_PRECEDENCE);
bean.setUrlPatterns(
Collections.singletonList(EurekaConstants.DEFAULT_PREFIX + "/*"));
return bean;
}处理HTTP请求的逻辑放在com.netflix.eureka.resources.InstanceResource类中,例如接收一个GET请求
@GET
public Response getInstanceInfo() {
InstanceInfo appInfo = registry
.getInstanceByAppAndId(app.getName(), id);
if (appInfo != null) {
logger.debug("Found: {} - {}", app.getName(), id);
return Response.ok(appInfo).build();
} else {
logger.debug("Not Found: {} - {}", app.getName(), id);
return Response.status(Status.NOT_FOUND).build();
}
}
关于如何分发处理请求,是通过Jersey框架完成的。这里类似于SpringMVC的dispatcherServlet,将接收到的请求首先到com.netflix.eureka.resources.ApplicationsResource,然后交由com.netflix.eureka.resources.ApplicationResource处理
@Path("{appId}")
public ApplicationResource getApplicationResource(
@PathParam("version") String version,
@PathParam("appId") String appId) {
CurrentRequestVersion.set(Version.toEnum(version));
return new ApplicationResource(appId, serverConfig, registry);
}接下来我们来到ApplicationResource的POST请求,看他在处理POST请求(注册一个实例)时具体做了什么。
@POST
@Consumes({"application/json", "application/xml"})
public Response addInstance(InstanceInfo info,
@HeaderParam(PeerEurekaNode.HEADER_REPLICATION) String isReplication) {
......
// handle cases where clients may be registering with bad DataCenterInfo with missing data
DataCenterInfo dataCenterInfo = info.getDataCenterInfo();
if (dataCenterInfo instanceof UniqueIdentifier) {
String dataCenterInfoId = ((UniqueIdentifier) dataCenterInfo).getId();
if (isBlank(dataCenterInfoId)) {
boolean experimental = "true".equalsIgnoreCase(serverConfig.getExperimental("registration.validation.dataCenterInfoId"));
if (experimental) {
String entity = "DataCenterInfo of type " + dataCenterInfo.getClass() + " must contain a valid id";
return Response.status(400).entity(entity).build();
} else if (dataCenterInfo instanceof AmazonInfo) {
AmazonInfo amazonInfo = (AmazonInfo) dataCenterInfo;
String effectiveId = amazonInfo.get(AmazonInfo.MetaDataKey.instanceId);
if (effectiveId == null) {
amazonInfo.getMetadata().put(AmazonInfo.MetaDataKey.instanceId.getName(), info.getId());
}
} else {
logger.warn("Registering DataCenterInfo of type {} without an appropriate id", dataCenterInfo.getClass());
}
}
}
registry.register(info, "true".equals(isReplication));
return Response.status(204).build(); // 204 to be backwards compatible
}忽略前面一些状态判断的代码,我们来关注核心的部分registry.register(info, "true".equals(isReplication));
随着代码一步步深入,到达的是com.netflix.eureka.registry.AbstractInstanceRegistry#register,这里就是注册的核心流程:
public void register(InstanceInfo registrant, int leaseDuration, boolean isReplication) {
try {
read.lock();
Map<String, Lease<InstanceInfo>> gMap = registry.get(registrant.getAppName());
REGISTER.increment(isReplication);
if (gMap == null) {
final ConcurrentHashMap<String, Lease<InstanceInfo>> gNewMap = new ConcurrentHashMap<String, Lease<InstanceInfo>>();
gMap = registry.putIfAbsent(registrant.getAppName(), gNewMap);
if (gMap == null) {
gMap = gNewMap;
}
}
//忽略掉中间代码
......
} finally {
read.unlock();
}
}
不出我们所料,我们看到了一个ConcurrentHashMap,留作纪念,我粘贴一下这个Server端保存实例信息的ConcurrentHashMap,标记到此一游~
private final ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry
= new ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>();【步骤三】客户端获取服务列表
com.netflix.discovery.DiscoveryClient.CacheRefreshThread刷新缓存,通过一个定时任务,定时向服务端获取服务信息,放在本地缓存中。
@VisibleForTesting
void refreshRegistry() {
try {
boolean isFetchingRemoteRegionRegistries = isFetchingRemoteRegionRegistries();
boolean remoteRegionsModified = false;
// This makes sure that a dynamic change to remote regions to fetch is honored.
String latestRemoteRegions = clientConfig.fetchRegistryForRemoteRegions();
if (null != latestRemoteRegions) {
String currentRemoteRegions = remoteRegionsToFetch.get();
if (!latestRemoteRegions.equals(currentRemoteRegions)) {
// Both remoteRegionsToFetch and AzToRegionMapper.regionsToFetch need to be in sync
synchronized (instanceRegionChecker.getAzToRegionMapper()) {
if (remoteRegionsToFetch.compareAndSet(currentRemoteRegions, latestRemoteRegions)) {
String[] remoteRegions = latestRemoteRegions.split(",");
remoteRegionsRef.set(remoteRegions);
instanceRegionChecker.getAzToRegionMapper().setRegionsToFetch(remoteRegions);
remoteRegionsModified = true;
} else {
logger.info("Remote regions to fetch modified concurrently," +
" ignoring change from {} to {}", currentRemoteRegions, latestRemoteRegions);
}
}
} else {
// Just refresh mapping to reflect any DNS/Property change
instanceRegionChecker.getAzToRegionMapper().refreshMapping();
}
}
boolean success = fetchRegistry(remoteRegionsModified);
if (success) {
registrySize = localRegionApps.get().size();
lastSuccessfulRegistryFetchTimestamp = System.currentTimeMillis();
}
......
} catch (Throwable e) {
logger.error("Cannot fetch registry from server", e);
}
}具体的拉取服务列表的逻辑在com.netflix.discovery.DiscoveryClient#fetchRegistry,基于上面的分析,我们基本可以知道,这里是通过一个Jersey客户端,发送一个HTTP的Get请求,这里大致的代码逻辑想必都可以猜想得到,这里就不再赘述。
至此,Eureka服务端,客户端请求接收和发送的基本流程,已经大体完成,但对于Eureka本身的分析还没有结束,还有一些Eureka作为服务注册中心为我们提供的特性,比如高可用,健康检查,是下一篇要研究的。
参考文献:《Spring微服务实战》,《Spring Cloud微服务之战》
长按订阅更多精彩▼
如有收获,点个在看,诚挚感谢
以上是关于微服务发现与注册之Eureka源码分析的主要内容,如果未能解决你的问题,请参考以下文章