防雪崩利器 hystrix-go 源码分析
Posted Go语言中文网
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了防雪崩利器 hystrix-go 源码分析相关的知识,希望对你有一定的参考价值。
阅读源码的过程,就像是在像武侠小说里阅读武功秘籍一样,分析高手的一招一式,提炼出精髓,来增强自己的内力。之前的帖子说了一下微服务的雪崩效应和常见的解决方案[1],太水,没有上代码怎么叫解决方案。github上有很多开源的库来解决雪崩问题,比较出名的是Netflix的开源库hystrix[2]。集流量控制、熔断、容错等于一身的java语言的库。今天分析的源码库是 hystrix-go[3],他是hystrix[4]的的go语言版,应该是说简化版本,用很少的代码量实现了主要功能。很推荐朋友们有时间读一读。
使用简单
hystrix的使用是非常简单的,同步执行,直接调用Do方法。
err := hystrix.Do("my_command", func() error {
// talk to other services
return nil
}, func(err error) error {
// do this when services are down
return nil
})
异步执行Go方法,内部实现是启动了一个gorouting,如果想得到自定义方法的数据,需要你传channel来处理数据,或者输出。返回的error也是一个channel
output := make(chan bool, 1)
errors := hystrix.Go("my_command", func() error {
// talk to other services
output <- true
return nil
}, nil)
select {
case out := <-output:
// success
case err := <-errors:
// failure
大概的执行流程图
其实方法Do和Go方法内部都是调用了hystrix.GoC方法,只是Do方法处理了异步的过程
func DoC(ctx context.Context, name string, run runFuncC, fallback fallbackFuncC) error {
done := make(chan struct{}, 1)
r := func(ctx context.Context) error {
err := run(ctx)
if err != nil {
return err
}
done <- struct{}{}
return nil
}
f := func(ctx context.Context, e error) error {
err := fallback(ctx, e)
if err != nil {
return err
}
done <- struct{}{}
return nil
}
var errChan chan error
if fallback == nil {
errChan = GoC(ctx, name, r, nil)
} else {
errChan = GoC(ctx, name, r, f)
}
select {
case <-done:
return nil
case err := <-errChan:
return err
}
}
自定义 Command 配置
在调用Do Go等方法之前我们可以先自定义一些配置
hystrix.ConfigureCommand("mycommand", hystrix.CommandConfig{
Timeout: int(time.Second * 3),
MaxConcurrentRequests: 100,
SleepWindow: int(time.Second * 5),
RequestVolumeThreshold: 30,
ErrorPercentThreshold: 50,
})
err := hystrix.DoC(context.Background(), "mycommand", func(ctx context.Context) error {
// ...
return nil
}, func(i context.Context, e error) error {
// ...
return e
})
我大要说了一下CommandConfig第个字段的意义:
-
Timeout: 执行 command 的超时时间。 默认时间是1000毫秒 -
MaxConcurrentRequests:command 的最大并发量 默认值是10 -
SleepWindow:当熔断器被打开后,SleepWindow 的时间就是控制过多久后去尝试服务是否可用了。 默认值是5000毫秒 -
RequestVolumeThreshold:一个统计窗口 10 秒内请求数量。达到这个请求数量后才去判断是否要开启熔断。 默认值是20 -
ErrorPercentThreshold:错误百分比,请求数量大于等于 RequestVolumeThreshold并且错误率到达这个百分比后就会启动熔断默认值是50
当然如果不配置他们,会使用默认值
讲完了怎么用,接下来就是分析源码了。我是从下层到上层的顺序分析代码和执行流程
统计控制器
每一个 Command 都会有一个默认统计控制器,当然也可以添加多个自定义的控制器。默认的统计控制器DefaultMetricCollector保存着熔断器的所有状态,调用次数,失败次数,被拒绝次数等等
type DefaultMetricCollector struct {
mutex *sync.RWMutex
numRequests *rolling.Number
errors *rolling.Number
successes *rolling.Number
failures *rolling.Number
rejects *rolling.Number
shortCircuits *rolling.Number
timeouts *rolling.Number
contextCanceled *rolling.Number
contextDeadlineExceeded *rolling.Number
fallbackSuccesses *rolling.Number
fallbackFailures *rolling.Number
totalDuration *rolling.Timing
runDuration *rolling.Timing
}
最主要的还是要看一下rolling.Number,rolling.Number才是状态最终保存的地方Number保存了 10 秒内的Buckets数据信息,每一个Bucket的统计时长为 1 秒
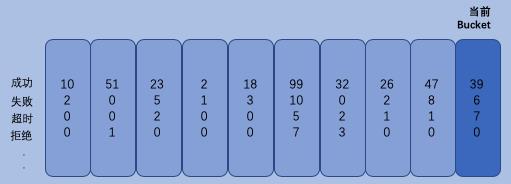
type Number struct {
Buckets map[int64]*numberBucket
Mutex *sync.RWMutex
}
type numberBucket struct {
Value float64
}
字典字段Buckets map[int64]*numberBucket 中的Key保存的是当前时间 可能你会好奇Number是如何保证只保存 10 秒内的数据的。每一次对熔断器的状态进行修改时,Number都要先得到当前的时间(秒级)的Bucket不存在则创建。
func (r *Number) getCurrentBucket() *numberBucket {
now := time.Now().Unix()
var bucket *numberBucket
var ok bool
if bucket, ok = r.Buckets[now]; !ok {
bucket = &numberBucket{}
r.Buckets[now] = bucket
}
return bucket
}
修改完后去掉 10 秒外的数据
func (r *Number) removeOldBuckets() {
now := time.Now().Unix() - 10
for timestamp := range r.Buckets {
// TODO: configurable rolling window
if timestamp <= now {
delete(r.Buckets, timestamp)
}
}
}
比如Increment方法,先得到Bucket再删除旧的数据
func (r *Number) Increment(i float64) {
if i == 0 {
return
}
r.Mutex.Lock()
defer r.Mutex.Unlock()
b := r.getCurrentBucket()
b.Value += i
r.removeOldBuckets()
}
统计控制器是最基层和最重要的一个实现,上层所有的执行判断都是基于他的数据进行逻辑处理的
上报执行状态信息
断路器-->执行-->上报执行状态信息-->保存到相应的Buckets
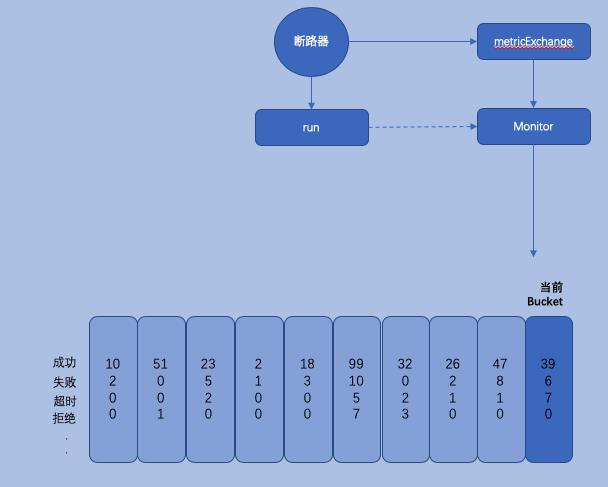
每一次断路器逻辑的执行都会上报执行过程中的状态,
// ReportEvent records command metrics for tracking recent error rates and exposing data to the dashboard.
func (circuit *CircuitBreaker) ReportEvent(eventTypes []string, start time.Time, runDuration time.Duration) error {
// ...
circuit.mutex.RLock()
o := circuit.open
circuit.mutex.RUnlock()
if eventTypes[0] == "success" && o {
circuit.setClose()
}
var concurrencyInUse float64
if circuit.executorPool.Max > 0 {
concurrencyInUse = float64(circuit.executorPool.ActiveCount()) / float64(circuit.executorPool.Max)
}
select {
case circuit.metrics.Updates <- &commandExecution{
Types: eventTypes,
Start: start,
RunDuration: runDuration,
ConcurrencyInUse: concurrencyInUse,
}:
default:
return CircuitError{Message: fmt.Sprintf("metrics channel (%v) is at capacity", circuit.Name)}
}
return nil
}
circuit.metrics.Updates 这个信道就是处理上报信息的,上报执行状态自信的结构是metricExchange,结构体很简单只有 4 个字段。要的就是
-
channel字段Updates他是一个有buffer的channel默认的数量是2000个,所有的状态信息都在他里面 -
metricCollectors字段,就是保存的具体的这个command执行过程中的各种信息
type metricExchange struct {
Name string
Updates chan *commandExecution
Mutex *sync.RWMutex
metricCollectors []metricCollector.MetricCollector
}
type commandExecution struct {
Types []string `json:"types"`
Start time.Time `json:"start_time"`
RunDuration time.Duration `json:"run_duration"`
ConcurrencyInUse float64 `json:"concurrency_inuse"`
}
func newMetricExchange(name string) *metricExchange {
m := &metricExchange{}
m.Name = name
m.Updates = make(chan *commandExecution, 2000)
m.Mutex = &sync.RWMutex{}
m.metricCollectors = metricCollector.Registry.InitializeMetricCollectors(name)
m.Reset()
go m.Monitor()
return m
}
在执行newMetricExchange的时候会启动一个协程 go m.Monitor()去监控Updates的数据,然后上报给metricCollectors 保存执行的信息数据比如前面提到的调用次数,失败次数,被拒绝次数等等
func (m *metricExchange) Monitor() {
for update := range m.Updates {
// we only grab a read lock to make sure Reset() isn't changing the numbers.
m.Mutex.RLock()
totalDuration := time.Since(update.Start)
wg := &sync.WaitGroup{}
for _, collector := range m.metricCollectors {
wg.Add(1)
go m.IncrementMetrics(wg, collector, update, totalDuration)
}
wg.Wait()
m.Mutex.RUnlock()
}
}
更新调用的是go m.IncrementMetrics(wg, collector, update, totalDuration),里面判断了他的状态
func (m *metricExchange) IncrementMetrics(wg *sync.WaitGroup, collector metricCollector.MetricCollector, update *commandExecution, totalDuration time.Duration) {
// granular metrics
r := metricCollector.MetricResult{
Attempts: 1,
TotalDuration: totalDuration,
RunDuration: update.RunDuration,
ConcurrencyInUse: update.ConcurrencyInUse,
}
switch update.Types[0] {
case "success":
r.Successes = 1
case "failure":
r.Failures = 1
r.Errors = 1
case "rejected":
r.Rejects = 1
r.Errors = 1
// ...
}
// ...
collector.Update(r)
wg.Done()
}
流量控制
hystrix-go对流量控制的代码是很简单的。用了一个简单的令牌算法,能得到令牌的就可以执行后继的工作,执行完后要返还令牌。得不到令牌就拒绝,拒绝后调用用户设置的callback方法,如果没有设置就不执行。结构体executorPool就是hystrix-go 流量控制的具体实现。字段Max就是每秒最大的并发值。
type executorPool struct {
Name string
Metrics *poolMetrics
Max int
Tickets chan *struct{}
}
在创建executorPool的时候,会根据Max值来创建令牌。Max 值如果没有设置会使用默认值10
func newExecutorPool(name string) *executorPool {
p := &executorPool{}
p.Name = name
p.Metrics = newPoolMetrics(name)
p.Max = getSettings(name).MaxConcurrentRequests
p.Tickets = make(chan *struct{}, p.Max)
for i := 0; i < p.Max; i++ {
p.Tickets <- &struct{}{}
}
return p
}
流量控制上报状态
注意一下字段 Metrics 他用于统计执行数量,比如:执行的总数量,最大的并发数 具体的代码就不贴上来了。这个数量也可以显露出,供可视化程序直观的表现出来。
令牌使用完后是需要返还的,返回的时候才会做上面所说的统计工作。
func (p *executorPool) Return(ticket *struct{}) {
if ticket == nil {
return
}
p.Metrics.Updates <- poolMetricsUpdate{
activeCount: p.ActiveCount(),
}
p.Tickets <- ticket
}
func (p *executorPool) ActiveCount() int {
return p.Max - len(p.Tickets)
}
一次 Command 的执行的流程
上面把 统计控制器、流量控制、上报执行状态讲完了,主要的实现也就讲的差不多了。最后就是串一次 command 的执行都经历了啥:
err := hystrix.Do("my_command", func() error {
// talk to other services
return nil
}, func(err error) error {
// do this when services are down
return nil
})
hystrix`在执行一次command的前面也有提到过会调用`GoC`方法,下面我把代码贴出来来,`篇幅问题去掉了一些代码`,主要逻辑都在。就是在`判断断路器是否已打开`,`得到Ticket`得不到就限流,`执行我们自己的的方法`,`判断context是否Done或者执行是否超时`
当然,每次执行结果都要`上报执行状态`,最后要`返还Ticket
func GoC(ctx context.Context, name string, run runFuncC, fallback fallbackFuncC) chan error {
cmd := &command{
run: run,
fallback: fallback,
start: time.Now(),
errChan: make(chan error, 1),
finished: make(chan bool, 1),
}
//得到断路器,不存在则创建
circuit, _, err := GetCircuit(name)
if err != nil {
cmd.errChan <- err
return cmd.errChan
}
//...
// 返还ticket
returnTicket := func() {
// ...
cmd.circuit.executorPool.Return(cmd.ticket)
}
// 上报执行状态
reportAllEvent := func() {
err := cmd.circuit.ReportEvent(cmd.events, cmd.start, cmd.runDuration)
// ...
}
go func() {
defer func() { cmd.finished <- true }()
// 查看断路器是否已打开
if !cmd.circuit.AllowRequest() {
// ...
returnOnce.Do(func() {
returnTicket()
cmd.errorWithFallback(ctx, ErrCircuitOpen)
reportAllEvent()
})
return
}
// ...
// 获取ticket 如果得不到就限流
select {
case cmd.ticket = <-circuit.executorPool.Tickets:
ticketChecked = true
ticketCond.Signal()
cmd.Unlock()
default:
// ...
returnOnce.Do(func() {
returnTicket()
cmd.errorWithFallback(ctx, ErrMaxConcurrency)
reportAllEvent()
})
return
}
// 执行我们自已的方法,并上报执行信息
returnOnce.Do(func() {
defer reportAllEvent()
cmd.runDuration = time.Since(runStart)
returnTicket()
if runErr != nil {
cmd.errorWithFallback(ctx, runErr)
return
}
cmd.reportEvent("success")
})
}()
// 等待context是否被结束,或执行者超时,并上报
go func() {
timer := time.NewTimer(getSettings(name).Timeout)
defer timer.Stop()
select {
case <-cmd.finished:
// returnOnce has been executed in another goroutine
case <-ctx.Done():
// ...
return
case <-timer.C:
// ...
}
}()
return cmd.errChan
}
dashboard 可视化 hystrix 的上报信息
代码中StreamHandler就是把所有断路器的状态以流的方式不断的推送到dashboard[5]. 这部分代码我就不用说了,很简单。需要在你的服务端加 3 行代码,启动我们的流服务
hystrixStreamHandler := hystrix.NewStreamHandler()
hystrixStreamHandler.Start()
go http.ListenAndServe(net.JoinHostPort("", "81"), hystrixStreamHandler)
dashboard我使用的是`docker`[6]版。
docker run -d -p 8888:9002 --name hystrix-dashboard mlabouardy/hystrix-dashboard:latest
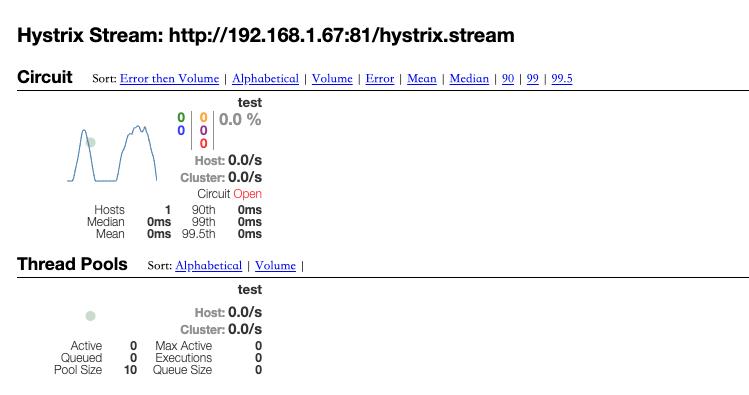
如果是集群可以使用Turbine[7]进行监控,有时间大家自己来看吧
出处:https://www.cnblogs.com/li-peng/p/11050563.html
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
参考资料
微服务的雪崩效应和常见的解决方案: https://www.cnblogs.com/li-peng/p/10997140.html
[2]hystrix: https://github.com/Netflix/Hystrix
[3]hystrix-go: https://github.com/afex/hystrix-go
[4]hystrix: https://github.com/Netflix/Hystrix
[5]dashboard: https://github.com/Netflix-Skunkworks/hystrix-dashboard
[6]docker: https://github.com/mlabouardy/hystrix-dashboard-docker
Turbine: https://github.com/Netflix/Turbine
推荐阅读
喜欢本文的朋友,欢迎关注“Go语言中文网”:
以上是关于防雪崩利器 hystrix-go 源码分析的主要内容,如果未能解决你的问题,请参考以下文章