golang map 从源码分析实现原理(go 1.14)
Posted 未秃的假程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了golang map 从源码分析实现原理(go 1.14)相关的知识,希望对你有一定的参考价值。
本文我们以源码和图片的方式来分析 golang map 的背后原理,文章有点长,但相信你可以有所收货,核心内容目录如下图
map 是什么
在计算机科学中,映射(Map),又称关联数组(Associative Array)、字典(Dictionary)是一个抽象的数据结构,它包含着类似于(键,值)的有序对。
当你需要实现快速查找,删除、添加、修改(注意 golang 中 map 不是并发安全的)
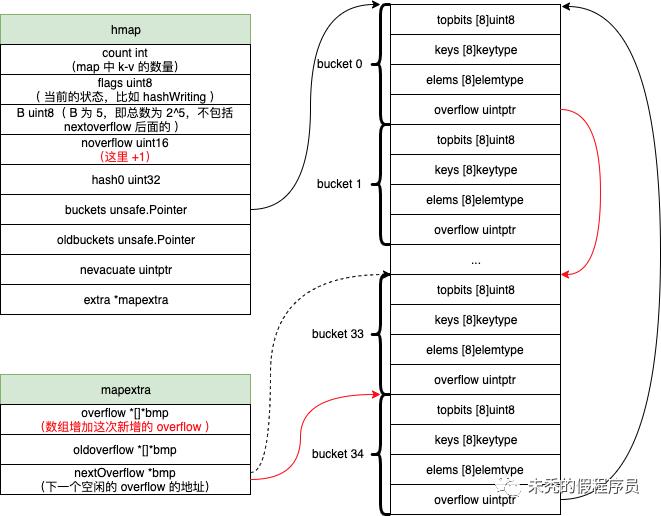
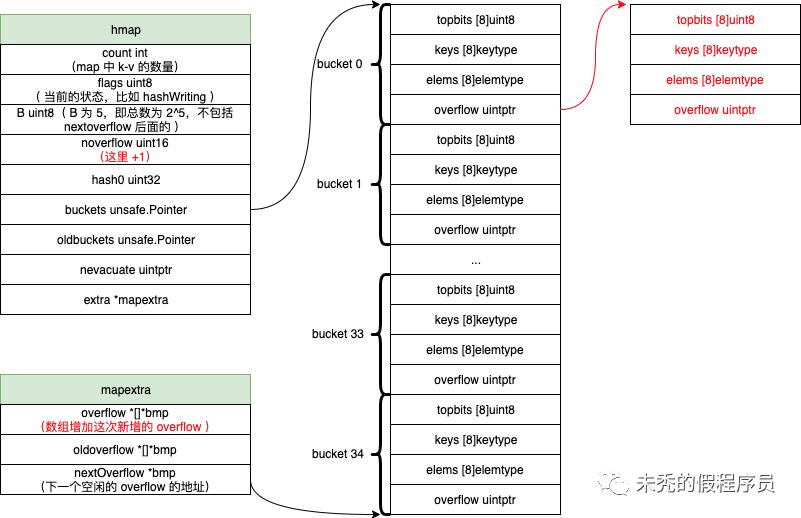
我们先提前了解下 hmap 的结构,我们以一张图片来表示 hmap 的结构(bucket 也可以按虚线的那样理解)
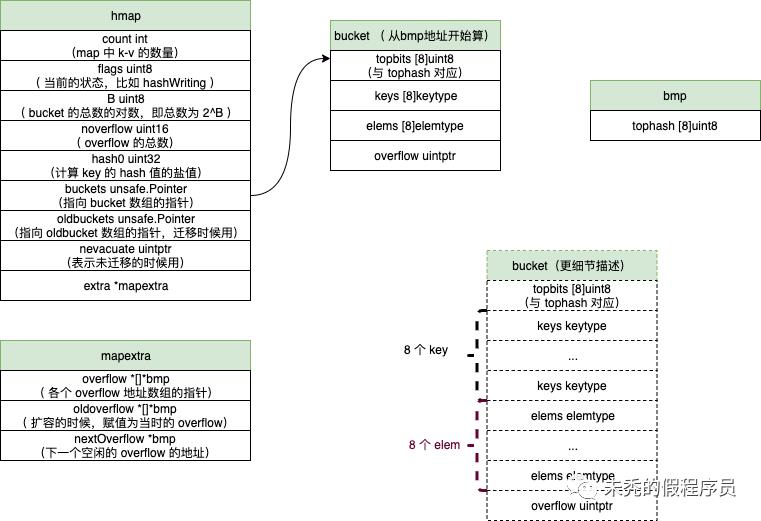
type hmap struct {count int // 存在 k-v 的数量flags uint8 // 表示 hmap 当前的状态,后续源码分析中会看见B uint8 // 即 bucket 数量为 2^Bnoverflow uint16 // overflow的数量hash0 uint32 // hash seed,用于 hash 使用buckets unsafe.Pointer // 指向具体的 bucket 指针,具体是 bucket 数组oldbuckets unsafe.Pointer // 与 buckets 一致,不过只有在迁移的时候才使用nevacuate uintptr // 表示转移的的进度,表示迁移完成的 bucket 数量为 nevacuate-1(后续源码分析也可以看到)extra *mapextra}//具体可以看下面的源码func hmap(t *types.Type) *types.Type {...bmap := bmap(t)fields := []*types.Field{ // 这里就是具体 hmap里面的 字段...makefield("buckets", types.NewPtr(bmap)), // 这里说明 bucket 是 bmap 结构,那具体的结构看bmap()makefield("oldbuckets", types.NewPtr(bmap)), // 与 buckets一致...}hmap := types.New(TSTRUCT)hmap.SetNoalg(true)hmap.SetFields(fields)dowidth(hmap)...return hmap}type mapextra struct {overflow *[]*bmap // 包含所有的 hmap.buckets 中的 overflowoldoverflow *[]*bmap // 包含所有的 hmap.oldbuckets 中的 overflownextOverflow *bmap //表示空闲 overflow bucket 空间的指针位置}const(bucketCnt = 1 << bucketCntBits // bucketCntBits 为 3 ,则 bucketCnt 为 8)// 虽然表面是以下的情况,但底层数据结构如后面type bmap struct {tophash [bucketCnt]uint8 // 即 [8]uint8}// 以下才是具体的 bucket 的内存里的结构,具体可以看后面 bmap 源码type bmap struct{tobits [8]uint8 // 与 tophash 对应keys [8]keytype // 这是针对key数据类型的数组elems [8]elemtype // 这是针对elem数据类型的数组overflow uintptr // 这是一个指针}// 可以看出来 bmap里面的具体字段结构func bmap(t *types.Type) *types.Type {...field := make([]*types.Field, 0, 5)// The first field is: uint8 topbits[BUCKETSIZE].arr := types.NewArray(types.Types[TUINT8], BUCKETSIZE)field = append(field, makefield("topbits", arr)) //topbits [8]uint8arr = types.NewArray(keytype, BUCKETSIZE)arr.SetNoalg(true)keys := makefield("keys", arr) // keys [8]keytypefield = append(field, keys)arr = types.NewArray(elemtype, BUCKETSIZE)arr.SetNoalg(true)elems := makefield("elems", arr) // elems [8]elemtypefield = append(field, elems)otyp := types.NewPtr(bucket)if !types.Haspointers(elemtype) && !types.Haspointers(keytype) {otyp = types.Types[TUINTPTR]}overflow := makefield("overflow", otyp) // overflow uintptrfield = append(field, overflow)// link up fieldsbucket.SetNoalg(true)bucket.SetFields(field[:])dowidth(bucket)...return bucket}
以上为整体模糊了解,后续我们会在源码分析的过程中补充细节
2.1 创建方式
方式1:m := map[int]int{1: 1, 2: 2}
func main() {// go tool compile -S -l -N main.gom := map[int]int{1: 1, 2: 2}m[3] = 4}
func main() {m := make(map[int]int)m[1] = 1fmt.Println(m) //这里导致 m 逃逸,所以会执行 makemap_small}
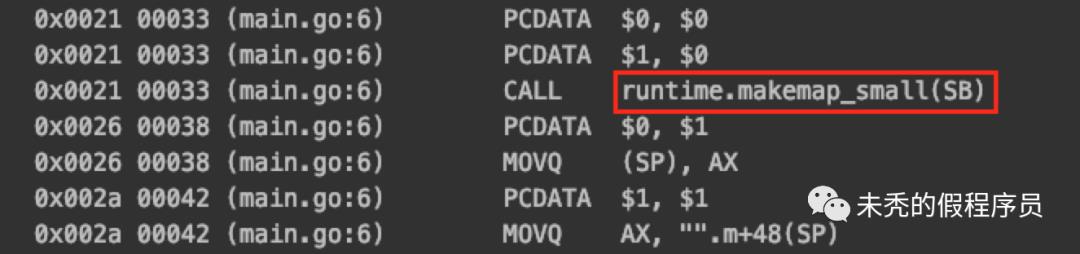
func main() {m := make(map[int]int, 9)m[1] = 1fmt.Println(m) // 这里导致m 逃逸,可以看到此时执行了 makemap}
func makemap64(mapType *byte, hint int64, mapbuf *any) (hmap map[any]any)func makemap(mapType *byte, hint int, mapbuf *any) (hmap map[any]any)func makemap_small() (hmap map[any]any)
// 位置在于 /cmd/compile/internal/gc/typecheck.gofunc typecheck1(n *Node, top int) (res *Node) {...ok := 0switch n.Op {...case OTMAP: // 这里是校验具体的 map 类型是否合理,有需要可以看源码,这里省略了...case OMAKE: // 这里是校验 make 语法中ok |= ctxExprargs := n.List.Slice() // make(map[int]int, 3),即 args 长度为2,第一是 map[int]int ,第二是 2if len(args) == 0 {yyerror("missing argument to make")n.Type = nilreturn n}n.List.Set(nil)l := args[0]l = typecheck(l, ctxType) // 这就是判断 map[int]int,接着会走上面的 case OTMAPt := l.Typeif t == nil {n.Type = nilreturn n}i := 1switch t.Etype {...case TMAP:if i < len(args) { // 这里判断 make 中的第二个参数l = args[i] //这里获取第二个参数i++... // 进行一些校验n.Left = l // Left 为 l} else { //如果没有第二个参数,则为0n.Left = nodintconst(0)}/*在syntax.go中,有 const 为const (...OMAKEMAP // make(Type, Left) (type is map)...)正好印证了 n.left 代表的是第二个参数*/n.Op = OMAKEMAP // 然后接下来走 OMAKEMAP...}...}...}
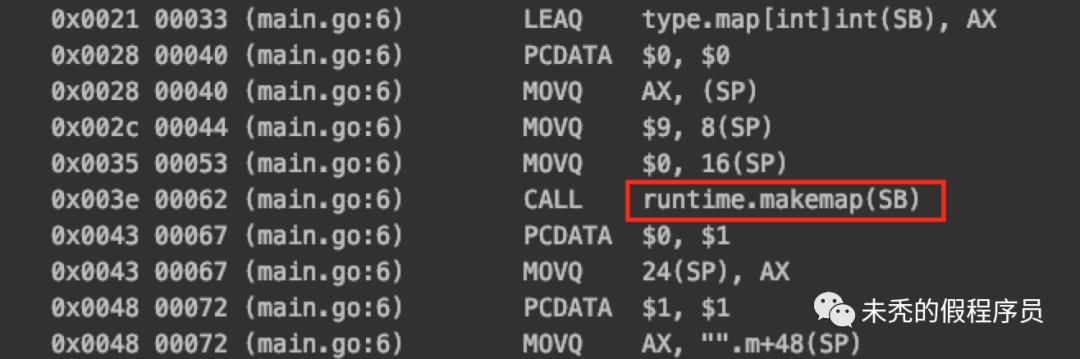
// 位置在于 cmd/compile/internal/gc/walk.gofunc walkexpr(n *Node, init *Nodes) *Node {opswitch:switch n.Op {...case OMAKEMAP:t := n.TypehmapType := hmap(t) //从这里可以知道,map 的底层结构是 hamphint := n.Left // 这里的 hint 表示第二个参数的值// var h *hmapvar h *Nodeif n.Esc == EscNone { // EscNone 表示不会逃逸到堆上的 map,例如 “初始化的方式1”,就不细说了,大家需要可以看源码...}if Isconst(hint, CTINT) && hint.Val().U.(*Mpint).CmpInt64(BUCKETSIZE) <= 0 { //如果 hint 是整型且值与 BUCKETSIZE 小,则走这里,这里的 BUCKETSIZE 为 8,因此当 hint 小于等于 8 的时候,会调用 makemap_smallif n.Esc == EscNone {...} else {fn := syslook("makemap_small")fn = substArgTypes(fn, t.Key(), t.Elem())n = mkcall1(fn, n.Type, init)}} else {...fnname := "makemap64"argtype := types.Types[TINT64]...if hint.Type.IsKind(TIDEAL) || maxintval[hint.Type.Etype].Cmp(maxintval[TUINT]) <= 0 {fnname = "makemap"argtype = types.Types[TINT]}fn := syslook(fnname) // 这里执行具体的函数,要么 makemap64,makemapfn = substArgTypes(fn, hmapType, t.Key(), t.Elem())n = mkcall1(fn, n.Type, init, typename(n.Type), conv(hint, argtype), h)}...}...}
2.3 makemap 源码解析
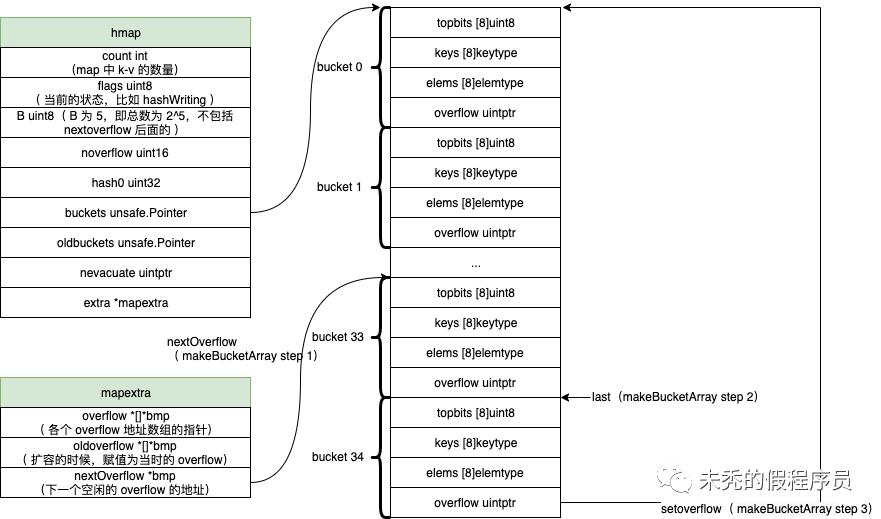
func makemap64(t *maptype, hint int64, h *hmap) *hmap {if int64(int(hint)) != hint { //判断是否溢出hint = 0}return makemap(t, int(hint), h)}// hint 的意义:make(map[k]v ,hint)func makemap(t *maptype, hint int, h *hmap) *hmap {mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size) //判断具体的 hint 乘以bucket 的大小是否会造成空间溢出,如果超过了,则将 hint 设置为0if overflow || mem > maxAlloc { //如果溢出,或者超出最大的请求空间大小,则将 hint 设置为0,先暂时不需要空间hint = 0}// initialize Hmapif h == nil { // 这里也能印证出底部的 h 是 hmaph = new(hmap)}h.hash0 = fastrand() //为后面的 key 的 hash 提供盐值B := uint8(0)for overLoadFactor(hint, B) { //当 hint 大于 8 的情况下,选一个合适的 B ,使 hint <=13*(2^B/2) 可以看下面源码部分B++}h.B = B // B 代表 bucket 的数量,为 2^B 个// 如果 B 为 0,可以后期再进行分配if h.B != 0 {//如果 B 不为 0 ,则直接初始化var nextOverflow *bmaph.buckets, nextOverflow = makeBucketArray(t, h.B, nil) //生成具体的bucketsif nextOverflow != nil { //如果不为nil,则在 extra 中 nextOverflow 也存一下位置h.extra = new(mapextra)h.extra.nextOverflow = nextOverflow}}return h}func overLoadFactor(count int, B uint8) bool { // 因此loadFactorNum*(bucketShift(B)/loadFactorDen)的意思是 13*(2^B/2)return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)}func bucketShift(b uint8) uintptr { // 这里的结果就是 2^breturn uintptr(1) << (b & (sys.PtrSize*8 - 1))}func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {base := bucketShift(b) // 即 2^bnbuckets := base //说明 buckets 的数量if b >= 4 { //如果 b>=4,则会添加额外的 bucketnbuckets += bucketShift(b - 4)// 新增 bucket 的数量为 2^(b-4)sz := t.bucket.size * nbuckets //最终整体的大小up := roundupsize(sz) // 返回系统当需要 sz 空间时分配的空间if up != sz {nbuckets = up / t.bucket.size //重新计算 nbuckets 的数量}}if dirtyalloc == nil {buckets = newarray(t.bucket, int(nbuckets)) //这里创建底层 bucket 数组} else {//表示要对应 dirtyalloc 的空间进行一次清空,后续在 mapclear 部分可以看到buckets = dirtyallocsize := t.bucket.size * nbucketsif t.bucket.ptrdata != 0 {memclrHasPointers(buckets, size)} else {memclrNoHeapPointers(buckets, size)}}// 处理额外添加 bucket 的情况if base != nbuckets { //即 b >=4 的时候,找到空闲的 bucket// 这里拿到了额外添加的起始位置nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize))) // step 1// 这里设置表示整体 buckets 的最后一个 bucketlast := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize))) // step 2last.setoverflow(t, (*bmap)(buckets)) // step 3 将最后一个的 bucket(为bmp) 的 overflow 指针指向头部}return buckets, nextOverflow}func (b *bmap) setoverflow(t *maptype, ovf *bmap) {// 这是将 ovf 赋值到 bmap 的 overflow 中*(**bmap)(add(unsafe.Pointer(b), uintptr(t.bucketsize)-sys.PtrSize)) = ovf}
if base != nbuckets { //此时 base 为 2^5 = 32 ,nbuckets 为 2^5 + 2^(5-4)=34nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize))) // step 1// 这里设置表示整体 buckets 的最后一个 bucketlast := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize))) //step 2last.setoverflow(t, (*bmap)(buckets))//step 3: 将最后一个的 bucket(为bmp) 的 overflow 指针指向头部}
最终 makeup 整体得到的结构如下图
func makemap_small() *hmap { //这里看到只是初始化了一个hash0,说明后续的初始化可能放在赋值中h := new(hmap)h.hash0 = fastrand()return h}
3. 赋值 (增/改)
3.1 赋值方式
func main() { // go tool compile -S -l -N main.gom := make(map[int]int)m[1] = 1}
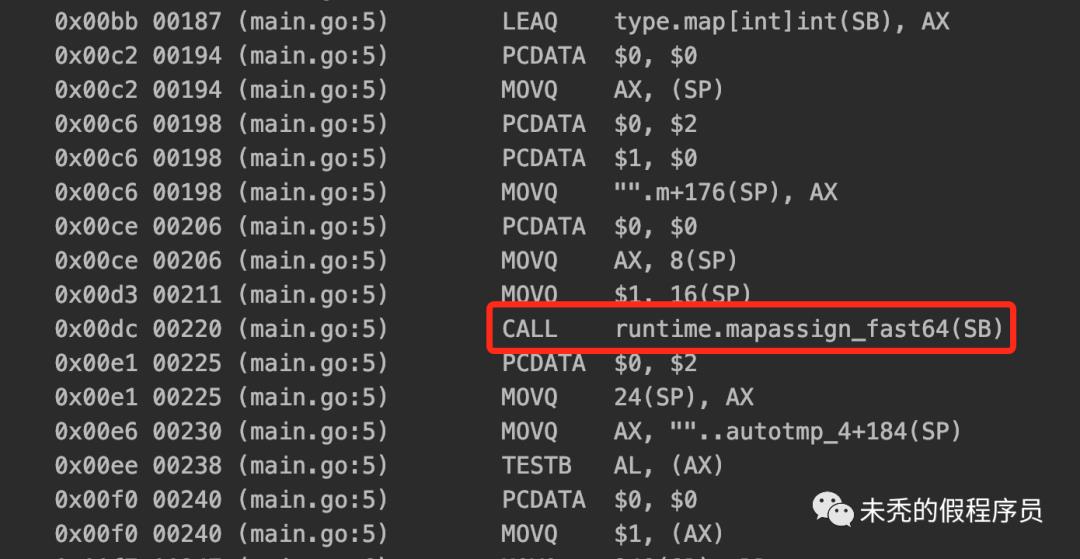
func mapassign(mapType *byte, hmap map[any]any, key *any) (val *any)func mapassign_fast32(mapType *byte, hmap map[any]any, key any) (val *any)func mapassign_fast32ptr(mapType *byte, hmap map[any]any, key any) (val *any)func mapassign_fast64(mapType *byte, hmap map[any]any, key any) (val *any)func mapassign_fast64ptr(mapType *byte, hmap map[any]any, key any) (val *any)func mapassign_faststr(mapType *byte, hmap map[any]any, key any) (val *any)
3.2 mapassign 源码解析
const(emptyRest = 0 // this cell is empty, and there are no more non-empty cells at higher indexes or overflows. 不仅说明当前 cell 是空的,而且后面的索引以及 overflows 都为空emptyOne = 1 // this cell is emptydataOffset = unsafe.Offsetof(struct {b bmapv int64}{}.v) // 表示 bmap 的大小,这里即表示了 [8]uint8 的大小hashWriting = 4 // hmap 中 flags 中对应写入位)func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {if h == nil {panic(plainError("assignment to entry in nil map"))}...if h.flags&hashWriting != 0 { //如果此时正在进行写入,则 throwthrow("concurrent map writes")}hash := t.hasher(key, uintptr(h.hash0))// 算出当前 key 的 hash 值h.flags ^= hashWriting // 将"写入位"置1 (^= 为异或,相应位数置相同,则置0,否则置1)if h.buckets == nil { // 如果没有,则初始化(与之前 makeup 部分 b < 4 对应)h.buckets = newobject(t.bucket) // 这里初始化具体的 buckets 第一个 bucket}again:// 寻找对应的 bucketbucket := hash & bucketMask(h.B) // 当前 hash 后 B-1 位为具体的 bucketIndex(寻找对应的 bucket)if h.growing() { // 这里判断当前 map 是否在迁移,如果正在迁移,则对应当前的 bucket 进行迁移操作growWork(t, h, bucket) // 对当前的 bucket 进行迁移处理(这个后续“迁移” 部分我们专门讲解)}b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))//找到对应的 buckettop := tophash(hash)// tophash 的意思就是获取 hash 的前8位,因为里面执行了 hash >> 56var inserti *uint8var insertk unsafe.Pointervar elem unsafe.Pointerbucketloop:for {for i := uintptr(0); i < bucketCnt; i++ { // for 循环当前 bucket 的 tophashif b.tophash[i] != top {if isEmpty(b.tophash[i]) && inserti == nil {// 如果为空的,先记录可以插入的位置inserti = &b.tophash[i]// dataOffset 可以看当前代码段的 const 部分insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) // 这里是对应可插入的 key 的位置elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))// 这里是对应的可插入的 elem 的位置}if b.tophash[i] == emptyRest { // 这里 emptyRest 算是一个优化,表示当前以及之后都不可能有值,即之前没有赋值过break bucketloop}continue}//如果找到对应的 top ,则进行覆盖k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))// ---- indirectkey 这部分感谢曹春晖大佬的解释----------// https://github.com/cch123/golang-notes/blob/master/map.md// -----------if t.indirectkey() {//如果是指针,则得到里面具体的地址k = *((*unsafe.Pointer)(k))}if !t.key.equal(key, k) { // 这里没对应上,可以理解为 hash 冲突的情况continue}// 如果需要覆盖 key ,则进行覆盖if t.needkeyupdate() {typedmemmove(t.key, k, key)}elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize)) // 找到对应的 elem 的位置goto done}ovf := b.overflow(t) //当前 bucket 没有,则从当前 bucket 的 overflow 寻找if ovf == nil { //如果 overflow 没有,则结束循环break}b = ovf}// 如果 map 中 k-v 数量过多或者 overflow 过多,会进行调整后,然后跳转到 again 重新走一遍流程,具体细节在 “迁移”中解析if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {hashGrow(t, h)goto again}if inserti == nil { //遍历了一遍,发现没有可以插入的位置,因此就重新生产一个 bucket ,用 overflow 来连接,并放置在新的 bucket 第 1 个位置newb := h.newoverflow(t, b)inserti = &newb.tophash[0] // 插入位置是新的 bucket 的第一个位置insertk = add(unsafe.Pointer(newb), dataOffset)elem = add(insertk, bucketCnt*uintptr(t.keysize))}if t.indirectkey() { // 如果 key 的结构是指针,则需要保存对应 key 对象的地址kmem := newobject(t.key)*(*unsafe.Pointer)(insertk) = kmeminsertk = kmem //这个是为了后续的 typedmemmove 操作的}if t.indirectelem() {//如果 elem 的结构是指针,需要保存对应 elem 的地址vmem := newobject(t.elem)*(*unsafe.Pointer)(elem) = vmem}typedmemmove(t.key, insertk, key)*inserti = top//将得到的top存储在对应 bucket 的 tophash 中h.count++done:if h.flags&hashWriting == 0 {throw("concurrent map writes")}h.flags &^= hashWriting // 将 "写入" 位置0( &^ 表示各个位与左边不同的保留,相同则为0)if t.indirectelem() { //如果 elem 是指针,则返回器对应的地址elem = *((*unsafe.Pointer)(elem))}return elem // 将elem的位置返回出去后,然后在外部通过 typedmemmove 给 elem 赋值,可以看后面的reflect_mapassign}func reflect_mapassign(t *maptype, h *hmap, key unsafe.Pointer, elem unsafe.Pointer) {p := mapassign(t, h, key)typedmemmove(t.elem, p, elem)}func (b *bmap) overflow(t *maptype) *bmap { //拿到当前 bucket 最后字段 overflow 的数据return *(**bmap)(add(unsafe.Pointer(b), uintptr(t.bucketsize)-sys.PtrSize))}func bucketMask(b uint8) uintptr {return bucketShift(b) - 1 // 2^b-1 // 即当b为3的时候,则为 2^3-1=7(二进制:111)}
if inserti == nil {newb := h.newoverflow(t, b) // 这里我们对应当前的 bucket 新建了一个 overflow,我们重点看看这里inserti = &newb.tophash[0] // 将插入在新的 overflow 第一个位置insertk = add(unsafe.Pointer(newb), dataOffset)elem = add(insertk, bucketCnt*uintptr(t.keysize))}
func (h *hmap) newoverflow(t *maptype, b *bmap) *bmap {var ovf *bmapif h.extra != nil && h.extra.nextOverflow != nil { // 如果 h.extra.nextOverflow 不为nilovf = h.extra.nextOverflowif ovf.overflow(t) == nil { //这里表示 ovf 不是 last(即上文 makeup 得到结构的 last),我们将 nextOverflow 的位置往后移动一个 bucketh.extra.nextOverflow = (*bmap)(add(unsafe.Pointer(ovf), uintptr(t.bucketsize)))} else { // 这里表示 ovf 是 lastovf.setoverflow(t, nil)// 要把 overflow 指向 buckets 起点的指针取消掉h.extra.nextOverflow = nil// 表示 h.extra.nextOverflow 已经没了}} else { //如果没有,则新建一个 bucketovf = (*bmap)(newobject(t.bucket))}h.incrnoverflow() //增加 hmap 的 overflow 的数量if t.bucket.ptrdata == 0 {h.createOverflow() //初始化数据*h.extra.overflow = append(*h.extra.overflow, ovf)//这次加入的 overflow 在全局 h.extra.overflow 留下记录}b.setoverflow(t, ovf)//然后将当前的 bucket 用 overflow 字段指向新增的 overflowreturn ovf}func (h *hmap) createOverflow() {if h.extra == nil {h.extra = new(mapextra)}if h.extra.overflow == nil {h.extra.overflow = new([]*bmap)}}
if h.growing() { // 这里判断当前 map 是否在迁移,如果正在迁移,则对应当前的 bucket 进行迁移操作growWork(t, h, bucket) // 对当前的 bucket 进行迁移处理}
func (h *hmap) growing() bool { //根据 hmap.oldbuckets 是否存在来判断是否在迁移return h.oldbuckets != nil}// growWork 在 mapassign 和 mapdelete 来调用func growWork(t *maptype, h *hmap, bucket uintptr) {evacuate(t, h, bucket&h.oldbucketmask()) //这里将当前 bucketIndex 对应的 oldBuckets 进行迁移if h.growing() { // 如果还没结束迁移,则将在 oldBuckets 中 h.nevacuate 的对应 bucket 位置进行迁移evacuate(t, h, h.nevacuate)}}func (h *hmap) oldbucketmask() uintptr {return h.noldbuckets() - 1}func (h *hmap) noldbuckets() uintptr {oldB := h.Bif !h.sameSizeGrow() { //如果不是等容的,即老的数量肯定是 2^(B-1),即 现数量/2oldB--}return bucketShift(oldB)}const (emptyRest = 0 // 当前位置为空,且后面的更高索引以及 overflow 都为空emptyOne = 1 // 当前位置为空evacuatedX = 2 // key/elem 有效,已经被迁移到 X 区evacuatedY = 3 // key/elem 有效,已经被迁移到 Y 区evacuatedEmpty = 4 // 当前位置为空,已经被迁移了minTopHash = 5 // minimum tophash for a normal filled cell.)func evacuate(t *maptype, h *hmap, oldbucket uintptr) {b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))//寻找到老 bucket 中的具体的bucketnewbit := h.noldbuckets() // 获取老 bucket 的总数if !evacuated(b) { // 判断当前 bucket 是否已经被迁移了// 如果 h.B +1 ,则 hash 位置多考虑了一位,则会根据多的一位是 0 还是 1 来判断是 x 还是 y// x 和 y 都是新的 bucket 的区域var xy [2]evacDstx := &xy[0]x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize))) // x 代表的是在新的 buckets 中的与 oldbuckets 一样 bucketIndex 的 bucketx.k = add(unsafe.Pointer(x.b), dataOffset) // 对应 bucket 的 key 的位置x.e = add(x.k, bucketCnt*uintptr(t.keysize))// 对应 bucket 的对应 key 的 elem 值if !h.sameSizeGrow() {// 如果空间要扩容迁移// 在新的 buckets ,根据 bucketIndex + 原来空间的大小(因为新容量为是原容量乘2),则是新的位置y := &xy[1]y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))y.k = add(unsafe.Pointer(y.b), dataOffset)y.e = add(y.k, bucketCnt*uintptr(t.keysize))}for ; b != nil; b = b.overflow(t) { //遍历 oldbuckets 对应的 bucket 以及 oveflowk := add(unsafe.Pointer(b), dataOffset)//获取当前 bucket 的 key 的起始位置e := add(k, bucketCnt*uintptr(t.keysize)) //获取当前 bucket 的 elem 的起始位置for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) {//这里是遍历当前 bucket 中 8 个 key,elemtop := b.tophash[i]if isEmpty(top) {//如果为空,则跳过b.tophash[i] = evacuatedEmptycontinue}if top < minTopHash { //如果小于 minTopHash ,则表示其已经被转移走了,则 throwthrow("bad map state")}k2 := kif t.indirectkey() { //如果存的是对应 key 的指针,则要获取 key 的地址k2 = *((*unsafe.Pointer)(k2))}var useY uint8if !h.sameSizeGrow() { //如果非等容迁移hash := t.hasher(k2, uintptr(h.hash0))//算出当前 key 的 hash 值if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) {// -----------这一部分感谢曹春晖大佬的文章------------// https://github.com/cch123/golang-notes/blob/master/map.md// 这里说明当在遍历的时候,且 t 不是 reflexivekey,而且 key 不等于 key// 比如 NaN,因此通过 top&1 有 50% 的机会随机分配 x、y// reflexivekey 解释:Most types are reflexive (k == k for all k of type t),//so don't bother calling equal(k, k) when the key type is reflexive.// -----------------------------------------useY = top & 1top = tophash(hash)} else {if hash&newbit != 0 { //根据这里判断分布到 x 还是 yuseY = 1}}}if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {throw("bad evacuatedN")}b.tophash[i] = evacuatedX + useY // 表示当前的 tophash 是去 x 还是 ydst := &xy[useY] // 表示迁移的目的地是 x 还是 yif dst.i == bucketCnt { //如果目标的 bucket(即新的bucket)满了,则新建一个overflowdst.b = h.newoverflow(t, dst.b)// 上面已有源码,就不重新分析了dst.i = 0dst.k = add(unsafe.Pointer(dst.b), dataOffset)dst.e = add(dst.k, bucketCnt*uintptr(t.keysize))}// -----这一部分将 oldBucket 的数据转移到新的 bucket---dst.b.tophash[dst.i&(bucketCnt-1)] = top // 将 top 放置对应 bucket 的 tophash 中if t.indirectkey() { //如果 key 是存指针,将地址存储*(*unsafe.Pointer)(dst.k) = k2 // copy pointer} else { //则直接将值拷贝typedmemmove(t.key, dst.k, k) // copy elem}if t.indirectelem() { //与 key 类似*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)} else {typedmemmove(t.elem, dst.e, e)}//-------------------------dst.i++dst.k = add(dst.k, uintptr(t.keysize))dst.e = add(dst.e, uintptr(t.elemsize))}}// 将 bucket 以及其 overflow 转移完成,则清理oldbuckets// 这里就是清理 oldsbuckets 对应 hash 位置的 bucketif h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 {b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))ptr := add(b, dataOffset)n := uintptr(t.bucketsize) - dataOffsetmemclrHasPointers(ptr, n) //帮助清理空间}}//如果 oldbucket == 已经迁移的数量标识,会将 nevacuate+1 ,这里的意思是 h.nevacuate 表示之前的oldBuckets 索引的 bucket 都已经迁移完毕if oldbucket == h.nevacuate {advanceEvacuationMark(h, t, newbit)}}func isEmpty(x uint8) bool {return x <= emptyOne}func evacuated(b *bmap) bool { //判断第一个位置是否已经被移走了h := b.tophash[0]return h > emptyOne && h < minTopHash}func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {h.nevacuate++stop := h.nevacuate + 1024if stop > newbit { // 这里的 newbit 表示 oldbucktes 中 bucket 的总数stop = newbit}for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) { //调整已经迁移完成的数量h.nevacuate++}if h.nevacuate == newbit { //如果迁移完成数量等于 oldBuckets 的总 bucket 数,说明迁移完成,将数据清空h.oldbuckets = nilif h.extra != nil {h.extra.oldoverflow = nil}h.flags &^= sameSizeGrow}}func bucketEvacuated(t *maptype, h *hmap, bucket uintptr) bool { //判断当前的bucket是否已经迁移过了b := (*bmap)(add(h.oldbuckets, bucket*uintptr(t.bucketsize)))return evacuated(b)}func (h *hmap) sameSizeGrow() bool { //判断是不是等容return h.flags&sameSizeGrow != 0}
4.2 hashGrow 源码分析
// growing、overLoadFactor 上文已经有解析,这里不重复了// 如果 map 中 k-v 数量过多或者 overflow 过多,会进行调整后,然后跳转到 again 重新走一遍流程if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {hashGrow(t, h)goto again}func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {if B > 15 { //如果大于15的,阈值就当15来算B = 15}// 判断overflow的数量是否过多,即是否大于等于 2^B,比如 B 为 2,如果 noverflow >=4,就说明过多了return noverflow >= uint16(1)<<(B&15)}func hashGrow(t *maptype, h *hmap) {bigger := uint8(1)if !overLoadFactor(h.count+1, h.B) {// 这里是判断具体是因为数量多导致还是overflow太多,如果是 overflow 太多,则不需要扩容bigger = 0h.flags |= sameSizeGrow}oldbuckets := h.bucketsnewbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil) // 这里上面有源码解析,就不解析了flags := h.flags &^ (iterator | oldIterator)//这里将 flags 中将"迭代标识“置 0if h.flags&iterator != 0 {// 如果新 bucket 正在迭代,则会将 oldBucket 的迭代也标识起来flags |= oldIterator}h.B += biggerh.flags = flagsh.oldbuckets = oldbuckets // 标识 growing()为 trueh.buckets = newbucketsh.nevacuate = 0h.noverflow = 0if h.extra != nil && h.extra.overflow != nil {if h.extra.oldoverflow != nil {//这说明有老的没处理完,则 throwthrow("oldoverflow is not nil")}h.extra.oldoverflow = h.extra.overflow //将当前的 overflow 放在变成 oldoverflowh.extra.overflow = nil}if nextOverflow != nil {if h.extra == nil {h.extra = new(mapextra)}h.extra.nextOverflow = nextOverflow //将 hmap.nextOverfloa 更新}// the actual copying of the hash table data is done incrementally// by growWork() and evacuate().// 这里说明真正的执行数据的拷贝在于 growWork() 和 evacuate()}
5. 查询
func main() {m := make(map[int]int)v := m[1]fmt.Println(v)}
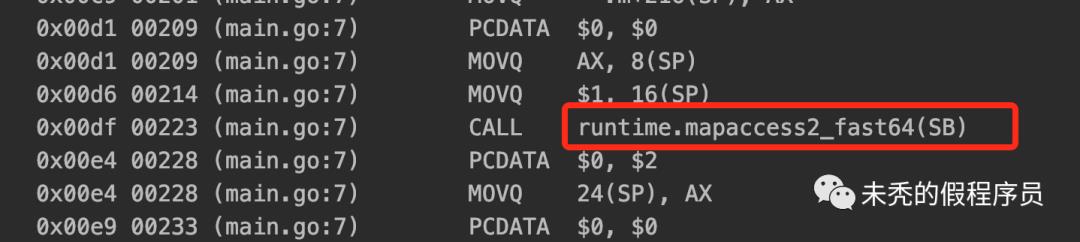
func main() {m := make(map[int]int)v, ok := m[1]fmt.Println(v, ok)}
func mapaccess1(mapType *byte, hmap map[any]any, key *any) (val *any)func mapaccess1_fast32(mapType *byte, hmap map[any]any, key any) (val *any)func mapaccess1_fast64(mapType *byte, hmap map[any]any, key any) (val *any)func mapaccess1_faststr(mapType *byte, hmap map[any]any, key any) (val *any)func mapaccess1_fat(mapType *byte, hmap map[any]any, key *any, zero *byte) (val *any)func mapaccess2(mapType *byte, hmap map[any]any, key *any) (val *any, pres bool)func mapaccess2_fast32(mapType *byte, hmap map[any]any, key any) (val *any, pres bool)func mapaccess2_fast64(mapType *byte, hmap map[any]any, key any) (val *any, pres bool)func mapaccess2_faststr(mapType *byte, hmap map[any]any, key any) (val *any, pres bool)func mapaccess2_fat(mapType *byte, hmap map[any]any, key *any, zero *byte) (val *any, pres bool)
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) {...if h == nil || h.count == 0 { //如果h没有初始化,则直接返回一个 zeroVal变量的位置,可以看出如果两个不同的 map 读取不存在的 key,返回的地址是一样的if t.hashMightPanic() {t.hasher(key, 0) // see issue 23734}return unsafe.Pointer(&zeroVal[0]), false}if h.flags&hashWriting != 0 { //判断是否有并发写,有则 throwthrow("concurrent map read and map write")}hash := t.hasher(key, uintptr(h.hash0))// 获取当前key的 hash 值m := bucketMask(h.B)b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + (hash&m)*uintptr(t.bucketsize)))//找到 buckets 对应 key 所对应的 bucketif c := h.oldbuckets; c != nil {//如果当前 map 正在迁移,则也要寻找 oldbucketif !h.sameSizeGrow() {// 如果非等容迁移,则只要将空间缩小一半m >>= 1}oldb := (*bmap)(unsafe.Pointer(uintptr(c) + (hash&m)*uintptr(t.bucketsize)))//通过 key 在 oldBuckets 中对应的 bucketif !evacuated(oldb) {//如果对应的 oldb 没迁移好,则说明还在老的部分b = oldb}}top := tophash(hash) //算出对应的 top,即 hash 前8位bucketloop:for ; b != nil; b = b.overflow(t) {//遍历对应 bucket 以及 overflowfor i := uintptr(0); i < bucketCnt; i++ {//遍历 bucket 各个keyif b.tophash[i] != top {if b.tophash[i] == emptyRest { // 这里就是表示这个bucket后面都不可能存在了,直接结束break bucketloop}continue //如果不相同,则跳过}k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))//寻找对应 bucket 对应的key的起始位置if t.indirectkey() {k = *((*unsafe.Pointer)(k))}if t.key.equal(key, k) {// 校验下 key 是否正确,如果正确,则获取到 elem,否则可能是 hash 冲突e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))if t.indirectelem() {e = *((*unsafe.Pointer)(e))}return e, true}}}return unsafe.Pointer(&zeroVal[0]), false}
6. 删除
func main() { // go tool compile -S -l -N main.go,这里没有 "-N" 的话则是 mapclearm := make(map[int]int)for k:=range m{delete(m,k)}}
func mapdelete(mapType *byte, hmap map[any]any, key *any)func mapdelete_fast32(mapType *byte, hmap map[any]any, key any)func mapdelete_fast64(mapType *byte, hmap map[any]any, key any)func mapdelete_faststr(mapType *byte, hmap map[any]any, key any)func mapclear(mapType *byte, hmap map[any]any) // 这个是通过编译器优化所以执行的
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {...if h == nil || h.count == 0 { //如果 hmap 没有初始化,则直接返回if t.hashMightPanic() {t.hasher(key, 0) // see issue 23734}return}if h.flags&hashWriting != 0 { //如果正在进行写入,则 throwthrow("concurrent map writes")}hash := t.hasher(key, uintptr(h.hash0)) //算出当前key 的hashh.flags ^= hashWriting //将“写入位”置1bucket := hash & bucketMask(h.B) //算出对应的 bucketIndex// 这里上文有源码分析,就不细说了if h.growing() {growWork(t, h, bucket)}b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize))) //寻找到对应的 bucketbOrig := btop := tophash(hash) //找到对应的 topsearch:for ; b != nil; b = b.overflow(t) { // 遍历当前的 bucket 以及 overflowfor i := uintptr(0); i < bucketCnt; i++ {if b.tophash[i] != top {if b.tophash[i] == emptyRest {//如果是 emptyReset,说明之后都不存在了,直接breakbreak search}continue}//找到了对应的位置k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))k2 := kif t.indirectkey() {k2 = *((*unsafe.Pointer)(k2))}if !t.key.equal(key, k2) { // hash 冲突了continue}// 这里清理空间 key 的空间if t.indirectkey() {*(*unsafe.Pointer)(k) = nil} else if t.key.ptrdata != 0 {memclrHasPointers(k, t.key.size)}// elem 与上面 key 同理e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))if t.indirectelem() {*(*unsafe.Pointer)(e) = nil} else if t.elem.ptrdata != 0 {memclrHasPointers(e, t.elem.size)} else {memclrNoHeapPointers(e, t.elem.size)}b.tophash[i] = emptyOne // emptyOne表示曾经有过,然后被清空了// ----这里判断当前位置之后是否还有数据存储过----if i == bucketCnt-1 {if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {goto notLast}} else {if b.tophash[i+1] != emptyRest {goto notLast}}// ----------// 到这里就说明当前的 bucket 的 topIndex 以及之后索引包括 overflow 都没有数据过,准备从后向前进行一波整理for {b.tophash[i] = emptyRest //则将当前的 top 设置为 emptyRestif i == 0 {//由于是i==0 ,则要寻找到上一个bucketif b == bOrig {break // beginning of initial bucket, we're done.}c := bfor b = bOrig; b.overflow(t) != c; b = b.overflow(t) {//找到当前 bucket 的上一个 bucket}i = bucketCnt - 1} else {//寻找上一个topi--}if b.tophash[i] != emptyOne {break}}notLast:h.count--break search}}if h.flags&hashWriting == 0 {throw("concurrent map writes")}h.flags &^= hashWriting //将“写入位”置0}
func mapclear(t *maptype, h *hmap) {...if h == nil || h.count == 0 {return}if h.flags&hashWriting != 0 {throw("concurrent map writes")}h.flags ^= hashWriting // "写入位"置1h.flags &^= sameSizeGrow //将 sameSizeGrow 清0h.oldbuckets = nilh.nevacuate = 0h.noverflow = 0h.count = 0// Keep the mapextra allocation but clear any extra information.if h.extra != nil { // 这里直接数据清空*h.extra = mapextra{}}_, nextOverflow := makeBucketArray(t, h.B, h.buckets)//将其中buckets数据清空,并拿到nextOverFlowif nextOverflow != nil {h.extra.nextOverflow = nextOverflow //重新更新 h.extra.nextOverflow}if h.flags&hashWriting == 0 {throw("concurrent map writes")}h.flags &^= hashWriting //将“写入位”置0}
7. 遍历
func main() {m := make(map[int]int)for key := range m {fmt.Println(key)}}
"".main STEXT size=505 args=0x0 locals=0x1b0...0x010d 00269 (main.go:7) CALL runtime.mapiterinit(SB)0x0112 00274 (main.go:7) JMP 2760x0114 00276 (main.go:7) CMPQ ""..autotmp_3+328(SP), $0...0x01d5 00469 (main.go:7) CALL runtime.mapiternext(SB) //for循环的原理是 mapiternext 后,然后重新又通过 JMP 276 ,然后再次进行 mapiternext,知道条件退出循环0x01da 00474 (main.go:7) JMP 276...
func mapiterinit(mapType *byte, hmap map[any]any, hiter *any)func mapiternext(hiter *any)
7.2 mapiterinit 源码分析
func mapiterinit(t *maptype, h *hmap, it *hiter) {...if h == nil || h.count == 0 { //如果 hmap 不存在或者没有数量,则直接返回return}...it.t = tit.h = hit.B = h.Bit.buckets = h.bucketsif t.bucket.ptrdata == 0 {h.createOverflow() //初始化数据it.overflow = h.extra.overflowit.oldoverflow = h.extra.oldoverflow}r := uintptr(fastrand()) // 从这里可以看出,起始位置上是一个随机数if h.B > 31-bucketCntBits {r += uintptr(fastrand()) << 31}it.startBucket = r & bucketMask(h.B) //找到随机开始的 bucketIndexit.offset = uint8(r >> h.B & (bucketCnt - 1))// 找到随机开始的 bucket 的 topHash 的索引it.bucket = it.startBucketif old := h.flags; old&(iterator|oldIterator) != iterator|oldIterator {atomic.Or8(&h.flags, iterator|oldIterator)//将 flags 变成迭代的情况}mapiternext(it)}
func mapiternext(it *hiter) {h := it.h...if h.flags&hashWriting != 0 { //如果正在并发写,则 throwthrow("concurrent map iteration and map write")}t := it.tbucket := it.bucket //这里的 bucket 是 bucketIndexb := it.bptri := it.icheckBucket := it.checkBucketnext:if b == nil {// wrappd 为 true 表示已经到过最后// bucket == it.startBucket 表示已经一个循环了if bucket == it.startBucket && it.wrapped {it.key = nilit.elem = nilreturn}if h.growing() && it.B == h.B {//如果表示正在迁移的途中,因此要也要遍历老的部分oldbucket := bucket & it.h.oldbucketmask()b = (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))if !evacuated(b) {//如果老的部分未迁移,还要遍历现在的 bucketIndexcheckBucket = bucket} else {b = (*bmap)(add(it.buckets, bucket*uintptr(t.bucketsize)))checkBucket = noCheck}} else {b = (*bmap)(add(it.buckets, bucket*uintptr(t.bucketsize)))checkBucket = noCheck}bucket++if bucket == bucketShift(it.B) {//如果 bucketIndex 已经到了最后一个,bucket从0开始,且用了 wrapped = true 表示已经覆盖到最后了bucket = 0it.wrapped = true}i = 0}for ; i < bucketCnt; i++ { //遍历当前 bucket 的 8 个 keyoffi := (i + it.offset) & (bucketCnt - 1)if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty {//如果为空或者是已经迁移了,则跳过continue}k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.keysize))if t.indirectkey() {k = *((*unsafe.Pointer)(k))}e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+uintptr(offi)*uintptr(t.elemsize))if checkBucket != noCheck && !h.sameSizeGrow() {//如果 oldBucket 还存在,且非等容迁移if t.reflexivekey() || t.key.equal(k, k) {hash := t.hasher(k, uintptr(h.hash0))if hash&bucketMask(it.B) != checkBucket { //如果不是相同的 key ,则跳过continue}} else {// 这里处理的是 NaN 的情况if checkBucket>>(it.B-1) != uintptr(b.tophash[offi]&1) {continue}}}// 这里表示没有进行迁移(不论是在 oldbuckets 还是 buckets)以及 NaN 的情况,都能遍历出来if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||!(t.reflexivekey() || t.key.equal(k, k)) {it.key = kif t.indirectelem() {e = *((*unsafe.Pointer)(e))}it.elem = e} else {// 这里表示非 NaN 且正在迁移的部分rk, re := mapaccessK(t, h, k) //从当前的key 对应的 oldBucket 或 bucket 寻找数据if rk == nil {continue // key has been deleted}it.key = rkit.elem = re}it.bucket = bucketif it.bptr != b { // avoid unnecessary write barrier; see issue 14921it.bptr = b}it.i = i + 1it.checkBucket = checkBucketreturn}b = b.overflow(t) //获取当前bucket 的overflowi = 0goto next}// 以下整体在上文的理解下比较简单,就不细说了func mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer) {if h == nil || h.count == 0 {return nil, nil}hash := t.hasher(key, uintptr(h.hash0))m := bucketMask(h.B)b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + (hash&m)*uintptr(t.bucketsize)))if c := h.oldbuckets; c != nil {if !h.sameSizeGrow() {m >>= 1}oldb := (*bmap)(unsafe.Pointer(uintptr(c) + (hash&m)*uintptr(t.bucketsize)))if !evacuated(oldb) {b = oldb}}top := tophash(hash)bucketloop:for ; b != nil; b = b.overflow(t) {for i := uintptr(0); i < bucketCnt; i++ {if b.tophash[i] != top {if b.tophash[i] == emptyRest {break bucketloop}continue}k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))if t.indirectkey() {k = *((*unsafe.Pointer)(k))}if t.key.equal(key, k) {e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))if t.indirectelem() {e = *((*unsafe.Pointer)(e))}return k, e}}}return nil, nil}
感谢各位大佬的输出!!!
以上是关于golang map 从源码分析实现原理(go 1.14)的主要内容,如果未能解决你的问题,请参考以下文章