JDK底层源码分析系列-你知道ConcurrentHashMap在Java 8中的实现是有bug的吗?而且还不止一处!
Posted 奇客时间
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JDK底层源码分析系列-你知道ConcurrentHashMap在Java 8中的实现是有bug的吗?而且还不止一处!相关的知识,希望对你有一定的参考价值。
点击上方蓝色“奇客时间”,选择“设为星标”
回复“面试宝典”获取美团、滴滴、阿里2020面试真题
1 简介
1 if (map.containsKey("key")) {
2 return map.get("key");
3 } else {
4 //做一些其他的处理,比如说抛出一个没有key的异常
5 }


2 构造器
1 /**
2 * ConcurrentHashMap:
3 * 无参构造器
4 * 空实现,所有参数都是走默认的
5 */
6 public ConcurrentHashMap() {
7 }
8
9 /**
10 * 有参构造器
11 */
12 public ConcurrentHashMap(int initialCapacity) {
13 //initialCapacity非负校验
14 if (initialCapacity < 0)
15 throw new IllegalArgumentException();
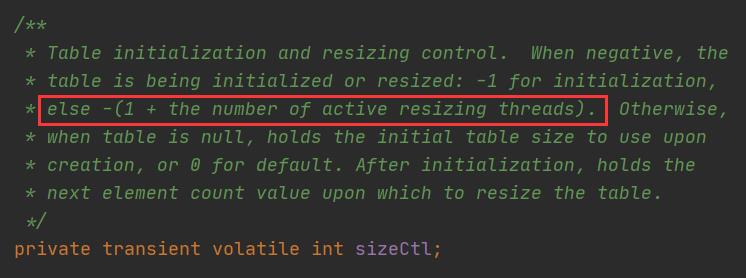
16 /*
17 与HashMap不同的是,这里initialCapacity如果大于等于2的29次方的时候(HashMap这里为超过2的30次方),
18 就重置为2的30次方
19
20 tableSizeFor方法是用来求出大于等于指定值的最小2次幂的(我在HashMap源码分析中详细解释了该方法的执行过程),
21 有意思的是,注意在第26行代码处,在HashMap中仅仅就是对设定的数组容量取最小2次幂,而这里首先对设定值*1.5+1后,
22 再取最小2次幂,后面会解释为什么会这么做
23 */
24 int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
25 MAXIMUM_CAPACITY :
26 tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
27 /*
28 sizeCtl是用来记录当前数组的状态的(类似于HashMap中的threshold):
29 1.如果为-1,代表当前数组正在被初始化
30 2.如果为其他负数,代表当前数组正在被扩容。取该负数的低16位,即(1 + n),n代表正在执行扩容操作的线程数量
31 (这里+1是为了错开-1这个值)
32 3.在调用有参构造器的时候存放的是需要初始化的容量
33 4.调用无参构造器的时候为0
34 5.当前数组已经不为空,此时存放的是下次需要扩容时的阈值
35 */
36 this.sizeCtl = cap;
37 }
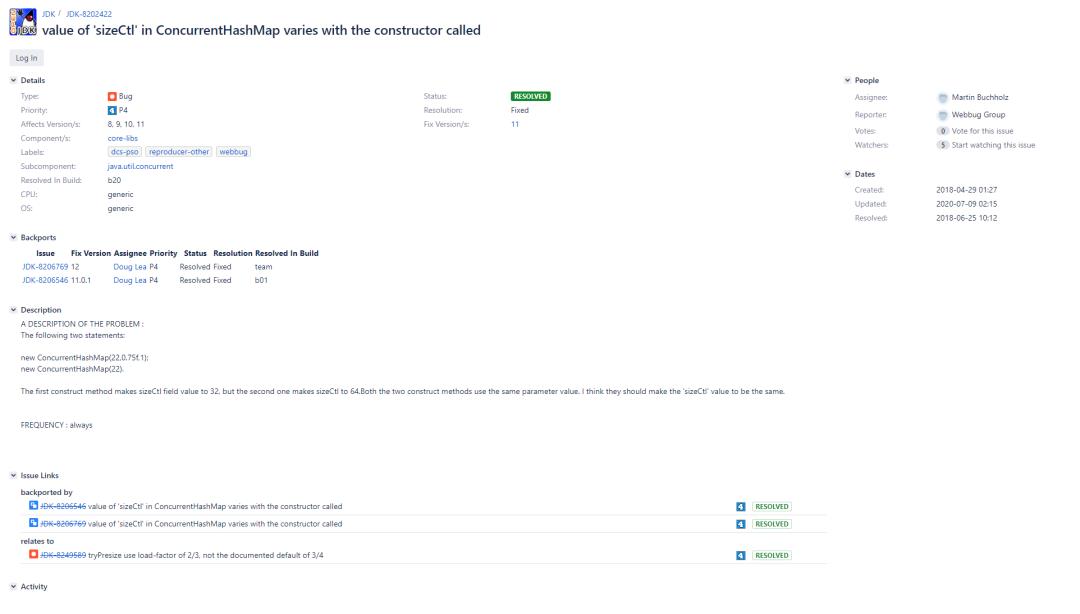
在上面的第26行代码处,首先会对设定值1.5+1后(+1是对应1.5后如果结果有小数的情况。因为最后是要取整的(传进tableSizeFor方法中的参数必须是int),也就是将所有小数部分都截掉,所以+1是为了弥补这种差异),然后再取最小2次幂,这和HashMap中的实现有所不同(HashMap中是tableSizeFor(initialCapacity)),那么这到底是为什么呢?其实传进来的容量实际上并不是存进去的桶的个数,而是需要扩容时的个数。举个例子就明白了:16 * 0.75 = 12,在HashMap中,我们传进来的其实是16,需要乘负载因子后才是实际需要扩容时的阈值点;而在ConcurrentHashMap中,传进来的值其实相当于12,也就是说我们传进来的就是需要扩容的阈值。所以在构造器阶段需要除以负载因子,以此来求出真正的桶的个数。所以在上面的第26行代码处,实际上就是在做自适应容量的工作。那么可能又会在想:不对啊,即使是在做自适应,那也应该是数组容量 / 默认值的0.75啊?*1.5是什么鬼?我猜测可能是为了提高执行速度,其实/0.75就相当于*1.333333...,这样和*1.5来对比的话似乎差别也不太大,但是/0.75的方式毕竟是除法,又带小数,而*1.5可以优化为右移操作。但是这么做的话可能会使计算出的结果导向为另一个不同的值,下面来举个例子:比方说现在传进来的容量是22,那么/ 0.75的方式结果是29.3,+1后再tableSizeFor结果是:32;而*1.5的方式结果是33,+1后再tableSizeFor结果是:64。可以看到,*1.5方式最后计算出来的容量明显是不对的,相当于多扩容了一倍(负载因子相当于默认的0.75,所以22 / 0.75后+1再取2的幂,结果肯定是32而不是64)。而实际上的结果也确实如此,这里实际上是个bug。在OpenJDK的bug提交记录上可以看到如下的JDK-8202422:
1 public ConcurrentHashMap(int initialCapacity) {
2 this(initialCapacity, LOAD_FACTOR, 1);
3 }
4
5 public ConcurrentHashMap(int initialCapacity,
6 float loadFactor, int concurrencyLevel) {
7 if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
8 throw new IllegalArgumentException();
9 if (initialCapacity < concurrencyLevel) // Use at least as many bins
10 initialCapacity = concurrencyLevel; // as estimated threads
11 long size = (long) (1.0 + (long) initialCapacity / loadFactor);
12 int cap = (size >= (long) MAXIMUM_CAPACITY) ?
13 MAXIMUM_CAPACITY : tableSizeFor((int) size);
14 this.sizeCtl = cap;
15 }
3 put方法
1 /**
2 * ConcurrentHashMap:
3 */
4 public V put(K key, V value) {
5 return putVal(key, value, false);
6 }
7
8 final V putVal(K key, V value, boolean onlyIfAbsent) {
9 //注意,ConcurrentHashMap中的key和value是不允许为null的,但在HashMap中却可以
10 if (key == null || value == null) throw new NullPointerException();
11 //计算key的hash,注意,这里必须是一个非负数,详见spread方法中的注释
12 int hash = spread(key.hashCode());
13 //binCount表示添加当前节点前,这个桶上面的节点数
14 int binCount = 0;
15 //注意这里是个死循环
16 for (Node<K, V>[] tab = table; ; ) {
17 Node<K, V> f;
18 int n, i, fh;
19 if (tab == null || (n = tab.length) == 0)
20 //如果当前数组还没有初始化的话,就进行初始化的工作(延迟初始化至该方法中)。然后会跳到下一次循环,添加节点
21 tab = initTable();
22 /*
23 tabAt方法是Unsafe类中通过volatile方式获得指定地址所对应的值,方式是通过(n - 1) & hash
24 也就是通过(n - 1) & hash的方式来找到这个数据插入的桶位置,和HashMap是一样的
25 */
26 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
27 /*
28 casTabAt方法是Unsafe类中通过CAS的方式设置值,这里的意思是如果这个桶上还没有数据存在的话,
29 就直接创建一个新的Node节点插入进这个桶就可以了,也就是快速判断。当然如果CAS失败了,会进入
30 到下一次循环中继续判断
31 */
32 if (casTabAt(tab, i, null,
33 new Node<K, V>(hash, key, value, null)))
34 break;
35 } else if ((fh = f.hash) == MOVED)
36 /*
37 如果当前桶的第一个节点是ForwardingNode节点的时候(ForwardingNode节点的hash值为MOVED),
38 也就是说当前桶正在被迁移中,就去帮助一起去扩容。等扩容完成后,就更新一下tab,下次循环还是会去插入节点的
39 */
40 tab = helpTransfer(tab, f);
41 else {
42 //走到这里说明当前这个桶上有节点
43 V oldVal = null;
44 /*
45 注意这里使用了synchronized来锁住了当前桶上的第一个节点,同时也就证明了在Java 8的
46 ConcurrentHashMap中,锁的粒度是在桶(锁住第一个节点也就是在锁住这个桶)这个级别
47 */
48 synchronized (f) {
49 /*
50 双重检查,可能的一种情况是(我的个人猜测):如果此时有两个线程走到了第48行代码处。第一个线程进入到了
51 synchronized同步语句块中,并插入了新节点,最后触发了扩容操作,此时table已经是一个newTable了
52 然后第二个线程进来,下面的判断条件发现不等(tabAt方法是Unsafe类中直接拿的主内存值,而此时table
53 已经扩容成newTable了。所以此时会找到newTable中i位置处的第一个节点,以此和旧table中i位置处的
54 第一个节点对比(f是局部变量),发现不是同一个位置),于是就会退出同步语句块,进入到下一次循环中
55 不管最终是不是这种解释,在synchronized同步语句块中加上双重检查本身就是一个好的编程习惯
56 */
57 if (tabAt(tab, i) == f) {
58 /*
59 如果节点是普通的Node节点的话(在spread方法中提到过,如果节点hash值>=0的话,
60 就是一个普通的Node节点)
61 */
62 if (fh >= 0) {
63 //设置binCount=1
64 binCount = 1;
65 /*
66 其实从下面的循环可以看出,ConcurrentHashMap中去掉了HashMap中的快速判断模式
67
68 注意,在链表上每循环一个节点,binCount就+1(for循环运行机制:第一个节点不加)
69 */
70 for (Node<K, V> e = f; ; ++binCount) {
71 K ek;
72 //如果桶上当前节点的hash值和要插入的hash值相同,并且key也是相同的话
73 if (e.hash == hash &&
74 ((ek = e.key) == key ||
75 (ek != null && key.equals(ek)))) {
76 oldVal = e.val;
77 if (!onlyIfAbsent)
78 //如果onlyIfAbsent为false,就新值覆盖旧值
79 e.val = value;
80 break;
81 }
82 Node<K, V> pred = e;
83 /*
84 e指向下一个节点,如果下一个节点为null,意味着已经循环到最后一个节点
85 还没有找到一样的,此时将要插入的新节点插到最后(pred指针指向当前节点的
86 上一个节点,因为e此时已经变成当前节点的下一个节点了)
87 */
88 if ((e = e.next) == null) {
89 pred.next = new Node<K, V>(hash, key,
90 value, null);
91 break;
92 }
93 }
94 } else if (f instanceof TreeBin) {
95 //如果节点是红黑树的话
96 Node<K, V> p;
97 //设置binCount=2,后面会解释这里设置为2的意义
98 binCount = 2;
99 //执行红黑树的插入节点逻辑(红黑树的分析本文不做展开)
100 if ((p = ((TreeBin<K, V>) f).putTreeVal(hash, key,
101 value)) != null) {
102 oldVal = p.val;
103 if (!onlyIfAbsent)
104 p.val = value;
105 }
106 }
107 }
108 }
109 //binCount != 0说明要么已经在链表上添加了一个新节点,要么在红黑树中插入了一个节点
110 if (binCount != 0) {
111 //如果链表的数量已经达到了转成红黑树的阈值的时候,就进行转换
112 if (binCount >= TREEIFY_THRESHOLD)
113 /*
114 我在之前的HashMap源码分析中已经说过,是否真正会转成红黑树,
115 需要看当前数组的桶的个数是否大于等于MIN_TREEIFY_CAPACITY,小于就只是扩容
116 */
117 treeifyBin(tab, i);
118 if (oldVal != null)
119 //返回旧值
120 return oldVal;
121 //如果上面是在链表尾新添加了一个节点的话,就跳出死循环,进入到下面的addCount方法中
122 break;
123 }
124 }
125 }
126 //添加节点后,计数器+1(在该方法中,同时会有多个线程进行扩容迁移的逻辑)
127 addCount(1L, binCount);
128 return null;
129 }
130
131 /**
132 * 第12行代码处:
133 */
134 static final int spread(int h) {
135 return (h ^ (h >>> 16)) & HASH_BITS;
136 }
-1(MOVED):代表当前节点正在迁移
-2(TREEBIN):代表当前节点是红黑树节点
-3(RESERVED):代表当前节点是用在computeIfAbsent和compute方法中的占位节点
4 initTable方法
1 /**
2 * 注意,该方法只是做初始化数组用的,不像HashMap中的resize方法除了用来初始化也用来做扩容
3 * ConcurrentHashMap中的扩容方法是transfer
4 */
5 private final Node<K, V>[] initTable() {
6 Node<K, V>[] tab;
7 int sc;
8 //如果当前数组已经不为空了,就可以退出了
9 while ((tab = table) == null || tab.length == 0) {
10 if ((sc = sizeCtl) < 0)
11 /*
12 前面说明过,如果sizeCtl为-1,代表当前数组正在被别的线程做初始化工作
13 这里的sizeCtl不用想都知道肯定是被volatile修饰的,以确保内存可见性
14 既然现在已经有别的线程在初始化了,那么当前这个线程就不用再做一遍了,
15 只需要不断让渡本线程资源,跳进下一次循环,直到初始化工作完成就行了
16 */
17 Thread.yield();
18 /*
19 这里利用Unsafe的CAS操作,将sizeCtl改为-1,代表着当前线程要去进行初始化数组的工作了,
20 其他线程只能在上面的if条件中让渡资源。当然如果CAS竞争失败,继续去循环就行了
21 */
22 else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
23 //走到这里,说明抢到了资源,准备开始做初始化工作
24 try {
25 /*
26 这里会再判断一次当前数组是否为空,避免重复的数组初始化工作。如果第一个线程已经走到第10行代码处,
27 然后此时被切出资源,注意此时sc还没有被赋值。这时候第二个线程进来了,完成了初始化工作后退出了
28 此时sizeCtl被赋值成*负载因子后的结果。而现在第一个线程又拿到资源,将sc赋值成第二个线程刚才已经
29 改过后的值,然后CAS成功了,那么此时又会开始进行初始化工作(之前已经初始化过了)。所以这里的再次判断
30 就是为了避免在高并发下,数组会被重复初始化的情况出现。这里的设计思路其实类似于单例的双重加锁模式
31 */
32 if ((tab = table) == null || tab.length == 0) {
33 /*
34 前面分析过,如果sizeCtl=0说明当前调用的是无参构造器,那么此时改成初始值16
35 n此时就代表着数组应该要创建的容量(也就是桶的个数)
36 */
37 int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
38 //用上一行得出的n的容量来创建一个新的Node数组
39 @SuppressWarnings("unchecked")
40 Node<K, V>[] nt = (Node<K, V>[]) new Node<?, ?>[n];
41 table = tab = nt;
42 /*
43 初始化工作完成后,此时计算实际的阈值:n*0.75(负载因子),然后在finally
44 子句中赋值给sizeCtl。注意这里是n - (n >>> 2),实际上也就相当于n*0.75,
45 也就是之前说过的这里的负载因子会用默认的0.75,而不是自定义的值
46 */
47 sc = n - (n >>> 2);
48 }
49 } finally {
50 /*
51 之所以要把下面这行代码放在finally子句中,是因为在上面第39行代码处,使用了@SuppressWarnings注解来
52 抑制异常,也就是说,这里可能会抛出异常(又或者是可能发生OOM)。如果抛出异常的话,sizeCtl就一直是-1了,
53 这样别的线程也不能完成初始化工作,就成为死循环了。所以sizeCtl赋值这行代码放在finally子句的意义就是:
54 确保即使发生异常的话,也要将sizeCtl赋成初始值sc,然后再让其他的线程完成初始化工作
55 */
56 sizeCtl = sc;
57 }
58 break;
59 }
60 }
61 return tab;
62 }5 多线程计数
在没有并发或者低并发的场景下:baseCount是用来记录当前节点个数的;
如果CAS设置baseCount+1失败,就代表着这里有多个线程在抢着计数,那么此时就会转而使用CounterCell数组来进行计数。每个线程都会通过随机探测(ThreadLocalRandom.getProbe() & m)的方式来找到属于它的CounterCell数组中的那个CounterCell槽位置(ThreadLocalRandom在并发的场景下性能更好),在这个CounterCell上进行计数。最后计算出baseCount与counterCells数组中所有非空值的和就是最后的结果。
1 /**
2 * ConcurrentHashMap:
3 */
4 private final void addCount(long x, int check) {
5 CounterCell[] as;
6 long b, s;
7 /*
8 如上面注释所说:在基本上没什么并发的场景下,baseCount是用来做计数用的,只要CAS设置+1成功就完事了
9 但是如果CounterCell数组不为空,说明现在是有多个线程在同时计数。抑或是CAS设置失败,就进入到下面
10 的if条件中
11 */
12 if ((as = counterCells) != null ||
13 !U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
14 CounterCell a;
15 long v;
16 int m;
17 //uncontended表示没有发生竞争的标志位
18 boolean uncontended = true;
19 /*
20 如果CounterCell数组为空,或者随机探测的槽位置处为空,又或者尝试将其中探测到的CounterCell
21 槽位置处的值+1的时候也失败了(快速尝试),就会进入到fullAddCount方法中,以此来完成+1的操作
22 */
23 if (as == null || (m = as.length - 1) < 0 ||
24 (a = as[ThreadLocalRandom.getProbe() & m]) == null ||
25 !(uncontended =
26 U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
27 //在该方法中会完成最终的计数工作
28 fullAddCount(x, uncontended);
29 /*
30 可以看到在计完数后,这里就退出了,没有走到下面的帮助扩容的逻辑中。为什么?可以想想走到
31 这里的时候,上面经历了两次CAS失败,说明当前是在一个高并发的场景下。如果此时我还去帮助
32 扩容的话,多个线程之间的锁竞争、上下文切换的开销,都会被放大
33 */
34 return;
35 }
36 /*
37 走到这里说明上面的CAS CounterCell操作成功了,check<=1(也就是传进来的binCount),
38 要么是桶里当前是空的,新加了一个节点,要么就是桶里面只有一个节点,在后面新加了一个节点
39 这两种情况下也不会走帮助扩容的逻辑,直接返回(我猜测是因为在这种情况下,节点数量并不多,
40 于是就不用帮着扩容了)。这里也揭示了在上面put方法中的第98行代码处,为什么之前在插入红黑树
41 节点的时候,会设置binCount=2,如果设置一个小于2的数,那后面就不会走帮忙扩容的逻辑了
42 (不走也无妨,走了更好)
43 */
44 if (check <= 1)
45 return;
46 //走到这里说明check > 1,计算一下此时实际的所有节点的值,赋值给局部变量s,以便下面扩容时用到
47 s = sumCount();
48 }
49 //...
50 }
51
52 /**
53 * 第28行代码处:
54 * 在该方法中完成最终的+1计数操作
55 */
56 private final void fullAddCount(long x, boolean wasUncontended) {
57 int h;
58 //如果ThreadLocalRandom还没有被初始化,就执行初始化的工作
59 if ((h = ThreadLocalRandom.getProbe()) == 0) {
60 //在初始化的过程中当前线程会被分配一个随机数probe(threadLocalRandomProbe)
61 ThreadLocalRandom.localInit();
62 h = ThreadLocalRandom.getProbe();
63 //未发生竞争标志位重置为true
64 wasUncontended = true;
65 }
66 //冲突标志位,当其值为true,说明此时CounterCell数组该扩容了
67 boolean collide = false;
68 for (; ; ) {
69 CounterCell[] as;
70 CounterCell a;
71 int n;
72 long v;
73 if ((as = counterCells) != null && (n = as.length) > 0) {
74 /*
75 CounterCell数组已经初始化了的时候,找到随机探测的槽如果为null,那么此时就
76 新创建一个CounterCell
77 */
78 if ((a = as[(n - 1) & h]) == null) {
79 /*
80 cellsBusy用来表示一个锁资源,0是无锁状态,1是上锁状态
81 当前为0表示此时没有线程在做数组放入CounterCell的过程,也没有正在扩容
82 */
83 if (cellsBusy == 0) {
84 //创建一个新的CounterCell,将1传进去
85 CounterCell r = new CounterCell(x);
86 //CAS上锁,失败了后面会将冲突标志位collide置为true
87 if (cellsBusy == 0 &&
88 U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
89 boolean created = false;
90 try {
91 CounterCell[] rs;
92 int m, j;
93 //双重检查(之前见过很多次了)
94 if ((rs = counterCells) != null &&
95 (m = rs.length) > 0 &&
96 rs[j = (m - 1) & h] == null) {
97 //上面新创建的CounterCell放在数组中
98 rs[j] = r;
99 created = true;
100 }
101 } finally {
102 /*
103 释放锁(放在finally子句中的意义在上面的initTable方法中
104 已经解释过了)
105 */
106 cellsBusy = 0;
107 }
108 //如果创建成功了,就跳出死循环(也就是该方法结束了)
109 if (created)
110 break;
111 /*
112 走到这里说明该槽已经被别的线程设置进去了(注意上面的双重检查),
113 那么此时就重新循环,找下一个位置就行了
114 */
115 continue;
116 }
117 }
118 //冲突标志位collide复位为false,避免之后可能会走到扩容逻辑中,而是继续下一次尝试
119 collide = false;
120 } else if (!wasUncontended)
121 /*
122 走到这里说明槽位置不为null,并且已经知道了上一次的CAS已经失败了(第26行代码处)
123 此时将wasUncontended重置为true,走下一遍循环即可
124 */
125 wasUncontended = true;
126 else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))
127 //此时会再尝试一次将新值插入进去,插入成功就退出了,插入失败的话也无妨,找下一个位置
128 break;
129 else if (counterCells != as || n >= NCPU)
130 /*
131 counterCells != as说明此时CounterCell数组正在扩容中,n >= NCPU说明当前数组容量已经
132 达到或超过了当前JVM可用的最大线程数,就让collide置为false,避免走到下面的扩容逻辑中,
133 而是继续下一次尝试(从这里也说明了,CounterCell数组的长度不可能无限制增大,最多为
134 当前JVM可用的最大线程数(如果再继续增大的话,剩下的线程也是多余的,徒增消耗))
135 */
136 collide = false;
137 else if (!collide)
138 /*
139 走到这里,说明上面条件都不满足。此时将冲突标志位collide由原来的false重新置为true,
140 等下次循环的时候如果前面还是不满足的话就会走到下面的扩容逻辑中去了
141 */
142 collide = true;
143 else if (cellsBusy == 0 &&
144 U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
145 //走到这里,说明上面条件都不满足。上锁,此时要进行CounterCell数组扩容的逻辑了
146 try {
147 //如果此时数组正在被别的线程扩容中,就不用本线程再扩容了
148 if (counterCells == as) {
149 //创建一个2倍容量的新数组
150 CounterCell[] rs = new CounterCell[n << 1];
151 /*
152 遍历的方式来进行数据迁移(毕竟数组的最大长度是当前JVM可用的最大线程数,不会
153 特别大,普通遍历足矣)
154 */
155 for (int i = 0; i < n; ++i)
156 rs[i] = as[i];
157 counterCells = rs;
158 }
159 } finally {
160 //释放锁(在finally子句中释放锁的写法,之前见过很多次了)
161 cellsBusy = 0;
162 }
163 //冲突标志位collide复位为false
164 collide = false;
165 //扩容后重新循环,尝试添加数据(当然,如果上面条件还是都不满足的话,还是会走到这里扩容的)
166 continue;
167 }
168 //走到这里,会生成一个新的随机数probe,进行下一次尝试
169 h = ThreadLocalRandom.advanceProbe(h);
170 } else if (cellsBusy == 0 && counterCells == as &&
171 U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
172 /*
173 此时CounterCell数组没有初始化,如果cellsBusy没有上锁,当前没有处于扩容中,那现在就CAS上锁
174 以此来执行CounterCell数组初始化的工作
175 */
176 boolean init = false;
177 try {
178 //双重检查
179 if (counterCells == as) {
180 //创建一个初始容量为2的CounterCell数组
181 CounterCell[] rs = new CounterCell[2];
182 //在槽位置处创建一个新的CounterCell
183 rs[h & 1] = new CounterCell(x);
184 counterCells = rs;
185 init = true;
186 }
187 } finally {
188 //释放锁
189 cellsBusy = 0;
190 }
191 //如果创建CounterCell数组成功,就可以退出了(此时数据也放进去了),否则继续循环
192 if (init)
193 break;
194 } else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))
195 /*
196 如果当前cellsBusy锁正在被上锁,就退而求其次,尝试对baseCount做更新
197 当然,如果也失败了,也还是会继续循环
198 */
199 break;
200 }
201 }
202
203 /**
204 * 第47行代码处:
205 * 计算baseCount与counterCells数组中所有非空值的和,
206 * 即当前ConcurrentHashMap中所有的节点数
207 * <p>
208 * 注意这里只是计算出一个近似值,如果该方法计算出结果后,
209 * 此时又有一个线程进来添加了节点,那么之前计算出来的
210 * 结果就不准了。这个是没有办法避免的,只能在后续的代码
211 * 中去考虑这种情况
212 */
213 final long sumCount() {
214 CounterCell[] as = counterCells;
215 CounterCell a;
216 long sum = baseCount;
217 if (as != null) {
218 for (int i = 0; i < as.length; ++i) {
219 if ((a = as[i]) != null)
220 sum += a.value;
221 }
222 }
223 return sum;
224 }
6 多线程扩容
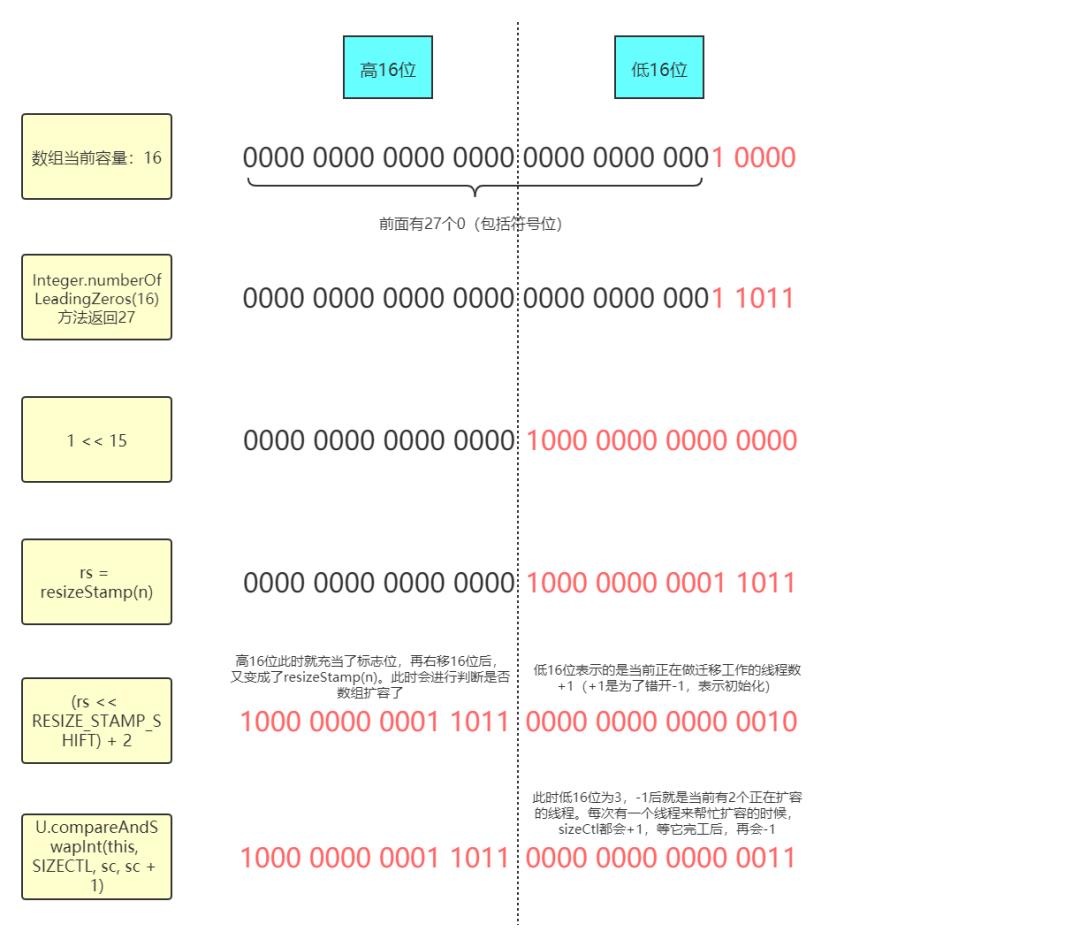
每个线程对于当前的数组长度都会生成一个扩容戳,具体是在resizeStamp方法中生成的:
1 /**
2 * ConcurrentHashMap:
3 * 该方法其实并没有什么实际意义,只是为了根据数组长度生成一个标记位,后续会拿这个标记位进行判断
4 */
5 static final int resizeStamp(int n) {
6 /*
7 Integer.numberOfLeadingZeros方法是用来计算最高位为1之前的0的个数(包括符号位),而RESIZE_STAMP_BITS
8 是16,这里也就是说,将数组长度取最高位为1之前的0的个数和2的15次方做按位或的操作,得出来的数据
9 在低16位的最高位为1(后续再左移16位后符号位就为1了),剩下的就是0的个数了(后面会举示意图)
10 这里之所以会用Integer.numberOfLeadingZeros这个方法是为了确保最后计算出的结果只能在低16位上有值,
11 高16位上不能有值,后面会说明原因
12 */
13 return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
14 }
这样每个线程都会有自己计算出来的扩容戳,如果两个线程进行扩容戳比对的时候发现相等,就说明这两个线程是在同一次扩容操作中;如果不等,则说明不在同一次扩容操作中。这是因为扩容戳是由当前数组长度决定的,如果扩容戳不等,那么这两个线程在当时获取到的数组长度就不等,也就说明这两个线程不在同一次扩容中。而判断扩容戳的相等于否也是后面判断扩容是否停止的条件之一。
这个扩容戳会在扩容时左移16位,也就是跑到了高16位上。而低16位此时表示的是正在做扩容迁移时的线程数量+1。比如说在扩容的时候有4个线程在同时做扩容的工作,那么低16位就是101(4+1=5,5的二进制是101)。每来一个线程帮助做扩容,低16位就会+1;而每一个线程帮完忙了,低16位就会-1。而扩容戳会赋值到sizeCtl上,这样低16位永远表示的是当前正在进行扩容的线程数量+1。
那么现在就来看一下addCount方法的后半部分和helpTransfer方法的实现:
1 /**
2 * ConcurrentHashMap:
3 */
4 private final void addCount(long x, int check) {
5 //...
6 //如果check不是负数,就进入到下面的帮助扩容逻辑中。在clear等方法中会传入-1,也就是说这些方法不会去扩容
7 if (check >= 0) {
8 Node<K, V>[] tab, nt;
9 int n, sc;
10 /*
11 s记录的是当前ConcurrentHashMap中所有的节点数量,如果其大于设置的阈值sizeCtl,并且数组不为空,
12 并且数组的长度小于最大长度2的30次方的话,就执行扩容操作。否则不扩容。while在此是保证一定要帮助扩容
13 */
14 while (s >= (long) (sc = sizeCtl) && (tab = table) != null &&
15 (n = tab.length) < MAXIMUM_CAPACITY) {
16 //此时会根据数组长度计算出一个标记位,详见resizeStamp方法的注释
17 int rs = resizeStamp(n);
18 /*
19 sc小于0说明此时有别的线程正在扩容(不可能为-1,因为此时初始化操作已经结束了,
20 并且上面已经判断数组不为空了),那当前线程就来帮助一起做扩容
21 */
22 if (sc < 0) {
23 /*
24 退出扩容时的条件,也就意味着此时已经做完扩容了:
25 1.(sc >>> RESIZE_STAMP_SHIFT) != rs说明当前线程不在同一次扩容中(sc右移16位的结果理论上
26 应该和rs相同,但如果不同,说明此时的数组长度已经变了,可能是当前线程还在上一次扩容中,而其它
27 线程已经在下一次了(可能是sc和tab赋值的间隙中触发了下一次扩容))
28 2.sc == rs + 1说明当前还有一个线程在做最后的检查工作(第一个线程初始为+2,但是最后是每个扩容线程
29 都会-1,实际上就相当于多减了一次,也就是这里+1的意思。而如果连检查也完成的话,sc会复位为一个正数
30 所以此时是最后一个线程正在做检查的时刻),那么本线程也不用帮忙了,直接等那个线程检查完就行了
31 (这里正确的判断条件应该为sc == (rs << RESIZE_STAMP_SHIFT) + 1,这里实际上是个bug,后面会说明)
32 3.sc == rs + MAX_RESIZERS和上面是一样的道理,MAX_RESIZERS表示最多可以帮助的线程数量+1(低16位
33 都为1,已经把低16位都占满了,不能再大了),也就是说现在已经有MAX_RESIZERS - 1个线程在帮忙做迁移了,
34 本线程就不掺和了(这里正确的判断条件应该为sc == (rs << RESIZE_STAMP_SHIFT) + MAX_RESIZERS,
35 这里实际上是个bug,后面会说明)
36 4.nextTable已经为空了(nextTable只在扩容时才有值)
37 5.transferIndex <= 0说明bound区间已经都分配完了,那么本线程也不需要扩容了
38 */
39 if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
40 sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
41 transferIndex <= 0)
42 break;
43 /*
44 此时sc<0,说明本线程当前是要帮助做迁移的。将sizeCtl+1(注意,sizeCtl此时是负数),然后进入
45 transfer方法帮忙做迁移。在transfer方法里面等该线程做完迁移工作后,会再将sizeCtl-1的。也就是说,
46 在上面我对构造器中sizeCtl所做的注释中的第2条:cizeCtl中低16位为(1+n)(高16位为标记位),
47 这里n代表正在执行扩容操作的线程数量
48 */
49 if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
50 transfer(tab, nt);
51 } else if (U.compareAndSwapInt(this, SIZECTL, sc,
52 (rs << RESIZE_STAMP_SHIFT) + 2))
53 /*
54 否则sc>=0,说明当前线程是第一个进来要进行扩容的线程,将sizeCtl初始为
55 (rs << RESIZE_STAMP_SHIFT) + 2,左移16位后,会将之前的标记位移动到高16位处,然后
56 低16位为10(+2),这里+2是为了错开1这个值,因为它代表着初始化
57 */
58 transfer(tab, null);
59 //重新计算一下此时的最新节点数,以便下一次循环时进行判断
60 s = sumCount();
61 }
62 }
63 }
64
65 /**
66 * 帮助做扩容工作
67 */
68 final Node<K, V>[] helpTransfer(Node<K, V>[] tab, Node<K, V> f) {
69 Node<K, V>[] nextTab;
70 int sc;
71 /*
72 如果此时数组不为空并且当前节点是ForwardingNode节点的时候(是ForwardingNode
73 节点就说明当前桶正在被迁移中)
74 */
75 if (tab != null && (f instanceof ForwardingNode) &&
76 (nextTab = ((ForwardingNode<K, V>) f).nextTable) != null) {
77 //此时会根据数组长度计算出一个标记位,详见resizeStamp方法的注释
78 int rs = resizeStamp(tab.length);
79 /*
80 nextTab == nextTable、table == tab和(sc = sizeCtl) < 0这三个条件都是在说如果当前
81 数组还没扩容完(注意这里是短路与),也就是正在扩容中。while在此是保证一定要帮助扩容
82 */
83 while (nextTab == nextTable && table == tab &&
84 (sc = sizeCtl) < 0) {
85 /*
86 退出扩容时的条件,也就意味着此时已经做完扩容了:
87 1.(sc >>> RESIZE_STAMP_SHIFT) != rs说明当前线程不在同一次扩容中(sc右移16位的结果理论上
88 应该和rs相同,但如果不同,说明此时的数组长度已经变了,可能是当前线程还在上一次扩容中,而其它
89 线程已经在下一次了(可能是sc赋值前触发了下一次扩容))
90 2.sc == rs + 1说明当前还有一个线程在做最后的检查工作(第一个线程初始为+2,但是最后是每个扩容线程
91 都会-1,实际上就相当于多减了一次,也就是这里+1的意思。而如果连检查也完成的话,sc会复位为一个正数
92 所以此时是最后一个线程正在做检查的时刻),那么本线程也不用帮忙了,直接等那个线程检查完就行了
93 (这里正确的判断条件应该为sc == (rs << RESIZE_STAMP_SHIFT) + 1,这里实际上是个bug,后面会说明)
94 3.sc == rs + MAX_RESIZERS和上面是一样的道理,MAX_RESIZERS表示最多可以帮助的线程数量+1(低16位
95 都为1,已经把低16位都占满了,不能再大了),也就是说现在已经有MAX_RESIZERS - 1个线程在帮忙做迁移了,
96 本线程就不掺和了(这里正确的判断条件应该为sc == (rs << RESIZE_STAMP_SHIFT) + MAX_RESIZERS,
97 这里实际上是个bug,后面会说明)
98 4.transferIndex <= 0说明bound区间已经都分配完了,那么本线程也不需要扩容了
99 注意:相比于在addCount方法中的相同此处的判断,该处代码少了一个判断,即判断nextTable
100 是否为空,可以想想为什么?因为上面的while循环中已经判断了nextTab == nextTable,
101 说明此时nextTable不为空
102 */
103 if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
104 sc == rs + MAX_RESIZERS || transferIndex <= 0)
105 break;
106 /*
107 此时将sizeCtl+1(注意,sizeCtl此时是负数),然后进入transfer方法帮忙做迁移
108 在transfer方法里面等该线程做完迁移工作后,会再将sizeCtl-1的。也就是说,在上面我对构造器
109 中sizeCtl所做的注释中的第2条:cizeCtl中低16位为(1+n)(高16位为标记位),这里n代表
110 正在执行扩容操作的线程数量
111 */
112 if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
113 transfer(tab, nextTab);
114 break;
115 }
116 }
117 //扩容完返回局部变量nextTab就行了,反正它本身就代表着下一次新的2倍容量的新数组。setTabAt方法保证内存可见性
118 return nextTab;
119 }
120 return table;
121 }
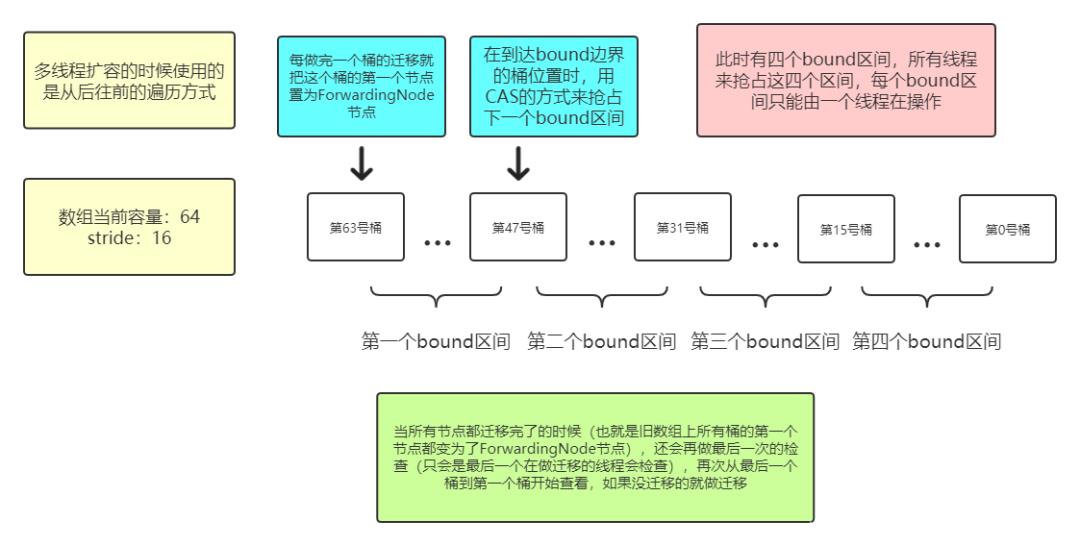
扩容时标记位的示意图:
1 /**
2 * ConcurrentHashMap:
3 * 该方法会利用多线程来分工执行扩容操作,会把迁移任务分成几个bound区间,每个bound区间中会有几个
4 * 桶,每个线程负责迁移本bound区间内的所有桶。因为只有在做完了本bound区间内的所有迁移工作后,才会
5 * 去CAS抢占下一次bound区间,在这期间不会有任何的CAS,所以多个线程之间可以并发地执行迁移工作
6 * 如果迁移工作都做完了的话,最后一个线程会再次检查一下所有的桶是否完成了迁移(后面有示意图)
7 * 当然了,如果只有一个线程,它就会完成全部的迁移工作(相当于每次都是它抢到资源)
8 * <p>
9 * (注:提前打下预防针,该方法的实现过程(尤其是前半部分)真的很不好理解,把它当作整个ConcurrentHashMap
10 * 源码中最难理解的内容也不为过。我也是debug了好几次才慢慢理解的,所以如果以下的注释看不懂的话,自己多
11 * 调试几次吧!)
12 */
13 private final void transfer(Node<K, V>[] tab, Node<K, V>[] nextTab) {
14 int n = tab.length, stride;
15 /*
16 定义bound区间的长度单位stride
17 1.stride=1:如果当前JVM最大可用线程数为1
18 2.stride=数组容量/(8*当前JVM最大可用线程数):当前JVM最大可用线程数大于1
19 3.stride=16:如果上面计算出来的值小于16,也就是说如果当前JVM最大可用线程数大于1的话,stride最小为16
20 该处计算是为了根据数组长度大小来计算出合适的stride
21 */
22 if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
23 stride = MIN_TRANSFER_STRIDE;
24 //如果nextTab是空的,意味着当前线程是第一个进来的扩容线程
25 if (nextTab == null) {
26 try {
27 //创建一个2倍旧容量的Node数组,最后旧数组上的数据会迁移到此数组中
28 @SuppressWarnings("unchecked")
29 Node<K, V>[] nt = (Node<K, V>[]) new Node<?, ?>[n << 1];
30 //将上面创建出来的新数组赋值给nextTab
31 nextTab = nt;
32 } catch (Throwable ex) {
33 //如果上面抛出异常的话(可能是OOM),就将sizeCtl设置为int的最大值,停止扩容操作
34 sizeCtl = Integer.MAX_VALUE;
35 return;
36 }
37 nextTable = nextTab;
38 //transferIndex指针初始指向旧数组容量
39 transferIndex = n;
40 }
41 int nextn = nextTab.length;
42 /*
43 创建一个新的ForwardingNode节点,注意这里将nextTab赋值进去了,此时还是一个空数组,
44 但是后续的setTabAt操作可以保证内存的可见性
45 */
46 ForwardingNode<K, V> fwd = new ForwardingNode<K, V>(nextTab);
47 //advance表示是否完成了当前桶的迁移工作
48 boolean advance = true;
49 //finishing表示是否完成了所有的迁移工作(该参数是为了最后一次检查用的)
50 boolean finishing = false;
51 //i指向当前桶的位置,bound指向当前线程所分配的区间边界点
52 for (int i = 0, bound = 0; ; ) {
53 Node<K, V> f;
54 int fh;
55 //以下是在做分配bound区间,以及更新当前桶位置i的工作
56 while (advance) {
57 int nextIndex, nextBound;
58 if (--i >= bound || finishing)
59 /*
60 每次i都会减1,表示当前线程每迁移完一个桶就迁移下一个。--i >= bound表示当前线程分配过
61 bound区域,但是还没有完成这个区域内所有桶的迁移工作;finishing为true这个条件的添加
62 是为了保证在所有迁移工作都做完后,最后的一次检查也做完后,在此也能成功退出while循环
63 ,然后会跳到第96行代码处(其实我感觉不加也可以,跳到下面if条件中也能退出,此时
64 transferIndex已经为0了。可能这样做是省了一次读取volatile变量的消耗(插入内存屏障))
65 */
66 advance = false;
67 else if ((nextIndex = transferIndex) <= 0) {
68 //小于等于0说明此时所有bound区间都被分配完了
69 i = -1;
70 advance = false;
71 } else if (U.compareAndSwapInt
72 (this, TRANSFERINDEX, nextIndex,
73 nextBound = (nextIndex > stride ?
74 nextIndex - stride : 0))) {
75 /*
76 为当前线程分配新的bound边界,如果CAS失败了,说明有其他的线程已经抢占到了本bound区间,
77 继续循环去抢下个bound区间就可以了
78 */
79 bound = nextBound;
80 i = nextIndex - 1;
81 advance = false;
82 }
83 }
84 /*
85 走到这里advance复位为false,下面这个if条件是用来判断当前线程是否迁移完了。i<0很好理解,表示所有
86 bound区间都被分配完了;i>=n我猜测是为了防止数据溢出(一个线程在上面的CAS操作中一直是失败的,但是
87 每循环一次i就-1,等减到-2147483648后再-1就变成了2147483647(在这期间transferIndex一直大于0));
88 而i+n>=nextn这个条件看起来像是在判断错次扩容的场景(nextn和n已经不是2倍的关系了),但是在本方法外面
89 已经判断过了,而且传进来的tab和nextTab都是局部变量,所以我猜测这里只是个安全性检查(这里也是我的
90 一个疑惑看不懂的点,我已经将该问题提交到StackOverFlow上,但截止到目前没有收到有效答复:
91 https://stackoverflow.com/questions/63597067/in-concurrenthashmaps-transfer-method-i-dont-understand-the-meaning-of-these)
92 */
93 if (i < 0 || i >= n || i + n >= nextn) {
94 int sc;
95 //如果迁移工作都做完了的话(最后一次检查也做完了)
96 if (finishing) {
97 //nextTable赋值为null,也就是说,nextTable只在扩容时候有值
98 nextTable = null;
99 //table此时指向两倍容量,扩容后的数组
100 table = nextTab;
101 /*
102 设置新的sizeCtl阈值(迁移结束后该值将变为正数),n是原数组长度,这里的意思是sizeCtl=n*1.5,也就是
103 sizeCtl存放的是新数组长度*0.75(n*1.5=2*n*0.75)。之前说过,这里的负载因子会用默认的0.75,而不是
104 自定义的值
105 */
106 sizeCtl = (n << 1) - (n >>> 1);
107 return;
108 }
109 /*
110 注意:走到这里说明此时还没有走最后一次检查
111 每当一个线程做完迁移工作后,就将sizeCtl-1,注意在外面帮助线程调用本方法的时候,
112 是先+1的。也就是sizeCtl低16位(1 + n)的含义
113 */
114 if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
115 /*
116 见addCount方法中的解释,sc == (rs << RESIZE_STAMP_SHIFT) + 2表示
117 当前是第一个线程在执行扩容。而如果下面的if条件不等于,说明此时还有其他的线程
118 在进行扩容,而且此时所有的bound区间都分配完了,那么本线程就可以退出了(帮完忙了)
119 */
120 if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
121 return;
122 /*
123 走到这里,说明上面的if条件是相等的,也就是说,当前线程是最后一个在执行着的迁移线程
124 注意,这里没有return,说明此时还会再次循环一遍旧数组,看其中桶头节点是否都变为了
125 FollowingNode节点。如果没有,就继续迁移。相当于最后会再做一遍检查工作,做收尾
126 */
127 finishing = advance = true;
128 i = n;
129 }
130 } else if ((f = tabAt(tab, i)) == null)
131 /*
132 如果旧数组上该桶为null,也就是说该桶上没有数据,那就说明当前这个桶不需要做迁移
133 此时只需要将头节点设置为ForwardingNode节点就行了(ForwardingNode节点上的hash
134 值为MOVED,这样别的线程在拿到这个桶的时候,就不会操作了)
135 */
136 advance = casTabAt(tab, i, null, fwd);
137 else if ((fh = f.hash) == MOVED)
138 /*
139 如果当前这个桶已经有别的线程在做迁移了(实际上是做完了迁移),就不需要本线程再做了,此时将
140 advance设置为true,进入下一次循环即可
141 */
142 advance = true;
143 else {
144 //synchronized锁住当前链表上的第一个节点,也就是锁住了这个桶,以防其他线程操作
145 synchronized (f) {
146 //双重检查,同putVal方法中synchronized同步语句块中双重检查的解释
147 if (tabAt(tab, i) == f) {
148 Node<K, V> ln, hn;
149 /*
150 如果节点是普通的Node节点的话(在spread方法中提到过,如果节点hash值>=0的话,
151 就是一个普通的Node节点)
152 */
153 if (fh >= 0) {
154 /*
155 其实下面的节点迁移的逻辑是和HashMap中是一样的,即将原桶上这个链表上每个节点hash值在数组
156 容量二进制数为1的那个位置处去按位与判断是0还是1,以此来拆分出两个链表。然后根据结果
157 如果为0的话最后就会插入到新数组的原位置,为1就插入到原位置+旧数组容量的位置(我在之前对
158 HashMap的分析中讲解了这里为什么是+旧数组容量)。但是在ConcurrentHashMap中做了进一步的
159 优化。可以试想一种情况:如果链表上所有节点计算出来的值都是0的话,那么如果还按照HashMap
160 中的方式来进行迁移,就还是会一个节点一个节点去遍历判断。其实这个时候我完全可以
161 不用去遍历,直接将原来的这个链表的头节点直接插入到新数组的原位置处就可以了,
162 在ConcurrentHashMap中就使用了这种优化思路
163 n是旧数组的容量,runBit记录的是最后一次发生计算变动的值,比如一个链表上每个节点
164 按位与计算出的结果分别是1 0 1 1 0 0,那么runBit最终记录的是倒数第二个节点的值:0
165 (因为最后一个是0,和前面这个0是一样的)
166 */
167 int runBit = fh & n;
168 //如上面的解释,lastRun最终会记录到倒数第二个节点,现在记录的都是初始位置第一个节点处
169 Node<K, V> lastRun = f;
170 /*
171 知道了上面runBit和lastRun代表了什么,那么下面的操作其实就很明朗了,就是在找最后一个
172 计算值发生变动的节点
173 */
174 for (Node<K, V> p = f.next; p != null; p = p.next) {
175 int b = p.hash & n;
176 if (b != runBit) {
177 runBit = b;
178 lastRun = p;
179 }
180 }
181 if (runBit == 0) {
182 //如果最后一个发生变动的节点是0(如果后面还有节点,就一定都为0),就将ln指针指向它
183 ln = lastRun;
184 hn = null;
185 } else {
186 //如果最后一个发生变动的节点是1(如果后面还有节点,就一定都为1),就将hn指针指向它
187 hn = lastRun;
188 ln = null;
189 }
190 /*
191 这里再次强调:ln或hn此时不一定代表的是原数组中最后一个节点,如果后面还有节点的话,
192 就跟lastRun节点的计算值是一样的
193 下面就是从第一个节点遍历到计算值发生变动的这个节点处(后面的节点不需要遍历了,
194 因为计算值都是和lastRun是一样的),逐渐去构建这两个链表的过程
195 */
196 for (Node<K, V> p = f; p != lastRun; p = p.next) {
197 int ph = p.hash;
198 K pk = p.key;
199 V pv = p.val;
200 if ((ph & n) == 0)
201 /*
202 如果计算值是0,就插入到ln链表中。注意,这里使用的是头插法,不同于HashMap
203 中的尾插法。原因就在于lastRun节点(ln指向lastRun)后面可能还有节点,如果
204 用尾插法,值就会被覆盖了。同时也就意味着,HashMap中节点的迁移是稳定的算法,
205 而在ConcurrentHashMap中则是不稳定的,不是正序也不是逆序。而将创建结果
206 再赋值给ln也是为了更新一下ln指针的位置,使ln指针始终指向第一个节点处,这点
207 很重要,因为下面要用到它
208 */
209 ln = new Node<K, V>(ph, pk, pv, ln);
210 else
211 //如果计算值是1,就使用头插法插入到hn链表中。
212 hn = new Node<K, V>(ph, pk, pv, hn);
213 }
214 /*
215 走到这里说明已经将原来的旧数组上的链表拆分完毕了,现在分成了两个链表,ln和hn。接下来需要
216 做的工作就很清楚了:将这两个链表分别插入到新数组的原位置和原位置+旧数组容量的位置就可以了
217 setTabAt方法是Unsafe类中通过volatile方式设置指定地址的值,这里将ln链表赋值在新数组
218 nextTab的i(原数组桶的位置)位置处
219 注意,这里不需要再像HashMap中将ln和hn链表中最后一个节点的next指针指向null了,可以想想
220 为什么?因为上面第196行代码处是循环到lastRun节点为止的,也就是说我不用去管lastRun的next
221 指针了,因为后面如果没有节点的话next指针肯定是null的,如果后面有节点,那next指针也都是指向
222 正确的
223 */
224 setTabAt(nextTab, i, ln);
225 //这里将hn链表赋值在新数组nextTab的i(原数组桶的位置)+旧数组容量位置处
226 setTabAt(nextTab, i + n, hn);
227 /*
228 将旧数组上这个桶的头节点置为ForwardingNode节点,这样该节点的hash值就变为了MOVED
229 也就是说,旧数组上这个桶的迁移工作,当前线程已经做完了,不再需要别的线程再做了
230 对应于第137行代码处。需要注意的是,这里只是做完了旧数组上一个桶的迁移工作,
231 并没有做完全部工作。在HashMap中,所有桶的迁移工作都是由一个线程完成的,而在
232 ConcurrentHashMap中则是由多线程来完成(要看是哪个线程抢到了资源。极端条件下,
233 由一个线程来全部完成(每次都是它抢到)),充分利用了多线程的优势
234 */
235 setTabAt(tab, i, fwd);
236 //advance设置为true,代表当前桶的迁移工作完成了
237 advance = true;
238 } else if (f instanceof TreeBin) {
239 //如果是红黑树,就执行红黑树的迁移逻辑(红黑树的分析本文不做展开)
240 TreeBin<K, V> t = (TreeBin<K, V>) f;
241 TreeNode<K, V> lo = null, loTail = null;
242 TreeNode<K, V> hi = null, hiTail = null;
243 int lc = 0, hc = 0;
244 for (Node<K, V> e = t.first; e != null; e = e.next) {
245 int h = e.hash;
246 TreeNode<K, V> p = new TreeNode<K, V>
247 (h, e.key, e.val, null, null);
248 if ((h & n) == 0) {
249 if ((p.prev = loTail) == null)
250 lo = p;
251 else
252 loTail.next = p;
253 loTail = p;
254 ++lc;
255 } else {
256 if ((p.prev = hiTail) == null)
257 hi = p;
258 else
259 hiTail.next = p;
260 hiTail = p;
261 ++hc;
262 }
263 }
264 ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
265 (hc != 0) ? new TreeBin<K, V>(lo) : t;
266 hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
267 (lc != 0) ? new TreeBin<K, V>(hi) : t;
268 setTabAt(nextTab, i, ln);
269 setTabAt(nextTab, i + n, hn);
270 setTabAt(tab, i, fwd);
271 advance = true;
272 }
273 }
274 }
275 }
276 }
277 }
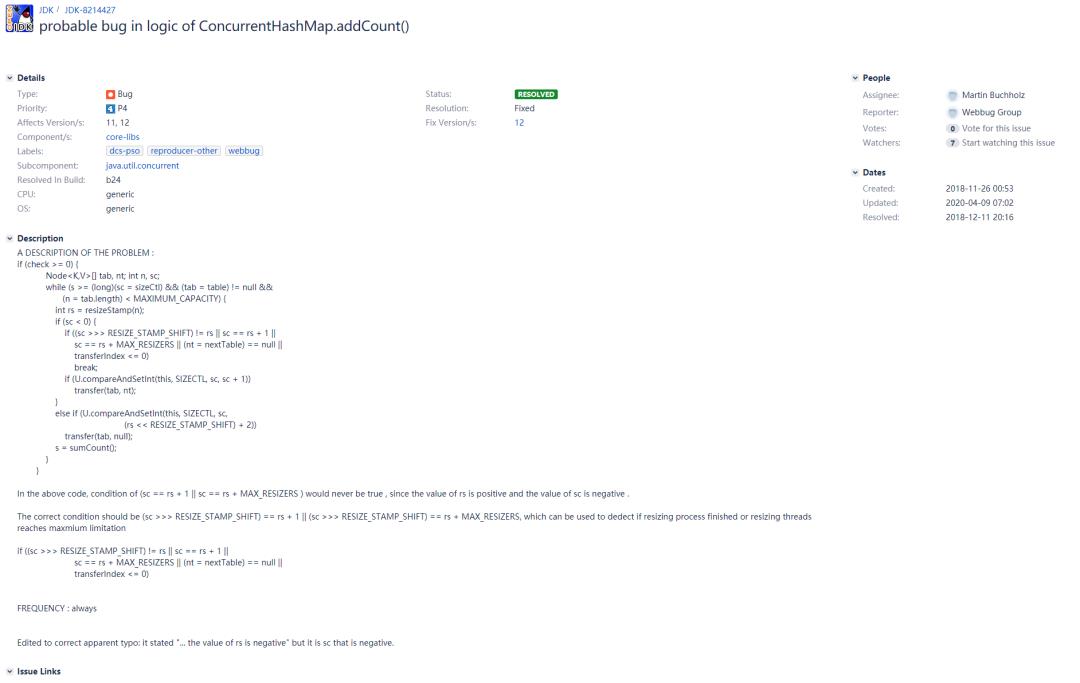
上面在addCount方法和helpTransfer方法中,我注释了两个地方是存在bug的:在判断扩容完成,准备跳出的这两个条件:sc == rs + 1和sc == rs + MAX_RESIZERS,应该改为sc == (rs << RESIZE_STAMP_SHIFT) + 1和sc == (rs << RESIZE_STAMP_SHIFT) + MAX_RESIZERS,这是为什么呢?可以想到,rs指向的是resizeStamp(n),也就是上面示意图演示的一个大于0的数,而sc指向sizeCtl,程序走到这里肯定是小于0的(注意上面一行代码:在addCount方法中是“sc < 0”,在helpTransfer方法中是“(sc = sizeCtl) < 0”,都是在sc小于0的前提下),那么如何才能做到一个大于0的数在+1或者+MAX_RESIZERS(65535)后,能变成一个负数呢?答案肯定是不可能的。数据溢出的情况也不可能出现,因为resizeStamp(n)方法保证数据只能放在低16位上(最大的情况也就是n为1的时候,此时前导0的个数也就是31而已,这也就是为什么在resizeStamp方法里面使用Integer.numberOfLeadingZeros方法的原因)。而上个判断迁移结束的条件是(sc >>> RESIZE_STAMP_SHIFT) != rs:将siztCtl右移16位后和resizeStamp(n)进行判断是否相等。能这么进行判断的前提也是因为resizeStamp方法计算出来的数据只能在低16位上。那么既然rs的值只能在低16位上,又何谈溢出一说呢?
1 private final void addCount(long x, int check) {
2 //...
3 if (check >= 0) {
4 Node<K,V>[] tab, nt;
5 int n, sc;
6 while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
7 (n = tab.length) < MAXIMUM_CAPACITY) {
8 int rs = resizeStamp(n) << RESIZE_STAMP_SHIFT;
9 if (sc < 0) {
10 if (sc == rs + MAX_RESIZERS || sc == rs + 1 ||
11 (nt = nextTable) == null || transferIndex <= 0)
12 break;
13 if (U.compareAndSetInt(this, SIZECTL, sc, sc + 1))
14 transfer(tab, nt);
15 } else if (U.compareAndSetInt(this, SIZECTL, sc, rs + 2))
16 transfer(tab, null);
17 s = sumCount();
18 }
19 }
20 }

提交者的意思是说JDK-8214427最主要的问题是要考虑新数组容量变了的情况,而不是一个正数另一个负数的问题,Java 12中所做的更改并没有解决问题。应该将sc == rs + 1改为(sc >>>RESIZE_STAMP_SHIFT) == (rs>>>RESIZE_STAMP_SHIFT) + 1(两个标记位相差1,也就是说前导0差一位,也就意味着数组容量翻倍了,和我说的(sc >>> RESIZE_STAMP_SHIFT) != (rs >>> RESIZE_STAMP_SHIFT)这个条件的意思差不多),目前Doug Lea并没有作出评论,该bug也是处于OPEN状态(不好复现,且没有提供完整报告,需要进一步评估)。其实要按照我的想法,在Java 12中应该改为(sc >>> RESIZE_STAMP_SHIFT) != (rs >>> RESIZE_STAMP_SHIFT) || sc == rs + 1,即把这两种情况都写上。
7 get方法
1 /**
2 * ConcurrentHashMap:
3 */
4 public V get(Object key) {
5 Node<K, V>[] tab;
6 Node<K, V> e, p;
7 int n, eh;
8 K ek;
9 /*
10 计算指定key的hash,注意,这里直接调用了key的hashCode方法,也就意味着如果传进来的
11 key为null的话,会抛出空指针异常
12 */
13 int h = spread(key.hashCode());
14 //如果数组没有初始化,或者计算出来的桶的位置为null(说明找不到这个key),就直接返回null
15 if ((tab = table) != null && (n = tab.length) > 0 &&
16 (e = tabAt(tab, (n - 1) & h)) != null) {
17 if ((eh = e.hash) == h) {
18 if ((ek = e.key) == key || (ek != null && key.equals(ek)))
19 /*
20 如果桶上第一个节点的hash值和要查找的hash值相同,并且key也是相同的话,
21 就直接返回(快速判断模式)
22 */
23 return e.val;
24 } else if (eh < 0)
25 /*
26 eh < 0说明eh是一个特殊节点:正在迁移中的节点或树节点,又或者是RESERVED节点,
27 此时会走find方法进行查找。而不同的节点会重写find方法。也就是说,每种特殊节点
28 都有自己的寻找方式
29 */
30 return (p = e.find(h, key)) != null ? p.val : null;
31 /*
32 走到这里说明eh >= 0,即当前桶是一个正常的Node链表,那么遍历链表上的每一个节点进行查找
33 (第一个节点不需要判断了,因为在第17和18行代码处已经判断过了)
34 */
35 while ((e = e.next) != null) {
36 if (e.hash == h &&
37 ((ek = e.key) == key || (ek != null && key.equals(ek))))
38 return e.val;
39 }
40 }
41 return null;
42 }
43
44 /**
45 * 第30行代码处:
46 * 最普通的Node节点的find方法,可以看出就是做个遍历查找,判断一下hash和key是否相同就行了
47 */
48 Node<K, V> find(int h, Object k) {
49 Node<K, V> e = this;
50 if (k != null) {
51 do {
52 K ek;
53 if (e.hash == h &&
54 ((ek = e.key) == k || (ek != null && k.equals(ek))))
55 return e;
56 } while ((e = e.next) != null);
57 }
58 return null;
59 }
60
61 /**
62 * 第30行代码处:
63 * ForwardingNode节点的find方法
64 */
65 Node<K, V> find(int h, Object k) {
66 outer:
67 /*
68 注意,找迁移节点是在nextTable上找的,之所以没有在当前数组中进行遍历,
69 是因为当前就是要查找迁移中这种场景中的节点,而在迁移时setTabAt方法能保证
70 nextTable的内存可见性。如果nextTable上找不到也无所谓,再调一次get方法,
71 等扩容结束后就能找到了
72 */
73 for (Node<K, V>[] tab = nextTable; ; ) {
74 Node<K, V> e;
75 int n;
76 if (k == null || tab == null || (n = tab.length) == 0 ||
77 (e = tabAt(tab, (n - 1) & h)) == null)
78 /*
79 如果key为null,新数组为null或者计算出来的新数组桶的位置为null
80 (说明找不到这个key),就直接返回null(快速判断模式)
81
82 注意:这里的tabAt取的是nextTable上的位置,所以说如果返回为null不代表着一定
83 就是找不到这个key,也可能是这个桶还没有做迁移。但是无妨,下次再调用一次get方法,
84 等迁移做完了就能找到了
85
86 值得一提的是:跳进该方法时是ForwardingNode节点,说明此时正在迁移中
87 而走到该处nextTable却可能为null,说明此时已经迁移完了,所以快速返回null
88 当然如果在下面的代码执行中,迁移才做完,那么这个时候的快速判断就不起作用了。但无妨,
89 后面会再次从头往下进行判断的
90 */
91 return null;
92 for (; ; ) {
93 int eh;
94 K ek;
95 if ((eh = e.hash) == h &&
96 ((ek = e.key) == k || (ek != null && k.equals(ek))))
97 //如果当前节点的hash和key都和要找的节点相同,就返回它
98 return e;
99 if (eh < 0) {
100 if (e instanceof ForwardingNode) {
101 /*
102 再次判断一下是否是ForwardingNode节点,走到这里说明当前还在迁移中(可能还是
103 这次迁移也可能是下一次迁移了),那么就继续从本方法的开头处再次往下判断(其实这里不去写这个
104 分支也是没问题的,直接走下面第128行代码处的ForwardingNode节点的find方法
105 就行了。但是这样就相当于递归了,后面会解释为什么这里不用递归)
106
107 这里想去解释一下上面说的下一次迁移的意思。如果此时正在遍历链表上的节点,突然发现某一个节点由
108 普通的Node节点变为了ForwardingNode节点,这是怎么发生的呢?我所做的一种猜测是:
109 比如说一个链表上有4个节点:0,1,2,3。我判断第一个节点的key和hash不是我想要的,
110 那么此时就会遍历到第二个节点处也就是节点1。就在此刻,这个链表发生了扩容迁移,
111 迁移结束后,节点1可能被放在了2倍容量新数组的桶的第一个位置处。而不久后,又发生了一次扩容迁移,
112 即第二次迁移(注意这里的e是局部变量,所以能一直循环下去),那么它就会被包装为ForwardingNode
113 节点(注意,虽然这里的e是局部变量,但是变成ForwardingNode节点的操作是通过Unsafe类中的
114 setTabAt方法来实现的(volatile语义,内存可见性),所以可以及时判断出来这个节点已经变为了
115 ForwardingNode节点)
116
117 此时将tab更新一下,以便下次循环时候使用,也就是在说,tab此时会指向最新的nextTable,去进行查找
118 (对应于上面所说的情况,即下一次迁移时,这个tab更新的动作才有意义)
119 */
120 tab = ((ForwardingNode<K, V>) e).nextTable;
121 continue outer;
122 } else
123 /*
124 走到这里说明已经不是ForwardingNode节点了(本次迁移结束,
125 该节点已经变成其他的节点了),可能是红黑树节点也可能是
126 RESERVED节点,那么就调用它们各自的find方法进行查找
127 */
128 return e.find(h, k);
129 }
130 /*
131 走到这里eh >= 0,说明此时本次迁移结束(注意:如上面所说,可能还会发生下一次迁移)。当然如果在遍历的过程中,
132 某个节点又变成了红黑树节点(其他线程添加节点触发转红黑树阈值)或者ForwardingNode节点(下一次扩容做迁移),
133 就又会去它们自己覆写的find方法中进行查找(ForwardingNode节点不会递归find查找)
134 这里就可以说明一下,为什么ForwardingNode节点不去走递归?其实这里更多的意义在于优化。如上面所说,如果扩容
135 非常频繁,在遍历链表上的节点的时候,就可能会有很多节点变为了ForwardingNode,如果用递归的话可能会造成
136 递归层次非常深的情况出现(这里也没有使用尾递归)。可能会出现StackOverflow,即使不出现,递归层次非常深
137 的话也不利于维护。所以为了避免这种情况的出现,就改用了标签的方式来重进
138 */
139 if ((e = e.next) == null)
140 //遍历到底也没有找到,就直接返回null
141 return null;
142 }
143 }
144 }
8 remove方法
1 /**
2 * ConcurrentHashMap:
3 */
4 public V remove(Object key) {
5 return replaceNode(key, null, null);
6 }
7
8 final V replaceNode(Object key, V value, Object cv) {
9 //计算key的hash
10 int hash = spread(key.hashCode());
11 for (Node<K, V>[] tab = table; ; ) {
12 Node<K, V> f;
13 int n, i, fh;
14 if (tab == null || (n = tab.length) == 0 ||
15 (f = tabAt(tab, i = (n - 1) & hash)) == null)
16 //如果数组没有初始化,或者计算出来的桶的位置为null(说明找不到这个key),就直接返回null
17 break;
18 else if ((fh = f.hash) == MOVED)
19 /*
20 和putVal方法一样,如果当前这个桶正在被迁移中,就去帮助一起去扩容。等扩容完成后,
21 就更新一下tab,继续下一次的循环
22 */
23 tab = helpTransfer(tab, f);
24 else {
25 //走到这里说明当前这个桶上有节点
26 V oldVal = null;
27 boolean validated = false;
28 //synchronized锁住当前链表上的第一个节点,也就是锁住了这个桶,以防其他线程操作
29 synchronized (f) {
30 //双重检查
31 if (tabAt(tab, i) == f) {
32 if (fh >= 0) {
33 //如果节点是普通的Node节点的话
34 validated = true;
35 for (Node<K, V> e = f, pred = null; ; ) {
36 K ek;
37 if (e.hash == hash &&
38 ((ek = e.key) == key ||
39 (ek != null && key.equals(ek)))) {
40 /*
41 如果桶上当前节点的hash值和要查找的hash值相同,并且key也是相同的话,
42 就记录一下该节点的value为ev
43 */
44 V ev = e.val;
45 if (cv == null || cv == ev ||
46 (ev != null && cv.equals(ev))) {
47 /*
48 如果cv为null,或者其有值并且与ev相等,就将oldVal置为ev(从这里可以看出:
49 如果传进来的cv有值的话,代表仅在要删除的节点的值是cv的时候,才能进行删除)
50 */
51 oldVal = ev;
52 if (value != null)
53 /*
54 如果value不为null,就将e的值赋值为value(这里的意思是:
55 传进来的value如果不为null,那么就需要将找到的节点值替换为value,
56 这也就是本方法名中“replace”的含义)
57 */
58 e.val = value;
59 else if (pred != null)
60 /*
61 上面的if条件不满足,说明当前是在做删除节点的操作。而pred节点
62 代表上一个节点,如果其值不为null,说明当前节点不是桶上第一个节点
63 (因为pred节点是在下面进行赋值的)所以此时就将前一个节点的next指向
64 下一个节点,也就是将e节点从链表中剔除掉,等待GC
65 */
66 pred.next = e.next;
67 else
68 /*
69 否则就是要删除的节点是当前桶上的第一个节点,此时就通过setTabAt方法
70 来将下一个节点赋值在当前桶的位置处,也就是将e节点从链表中剔除掉,等待GC
71 */
72 setTabAt(tab, i, e.next);
73 }
74 /*
75 走到这里说明传进来的cv和要删除的节点值不相等,就会返回null(在下面第116行代码处
76 发现不等,因为当前这种情况下的oldVal仍为null。然后会break跳出第11行代码处的
77 for循环从而返回null)
78 */
79 break;
80 }
81 /*
82 如果当前节点不是要删除的节点,此时pred记录的是当前节点,而下面会将当前节点指向下一个,
83 此时的pred就变为了上一个节点
84 */
85 pred = e;
86 if ((e = e.next) == null)
87 /*
88 如果链表上没有要删除的节点的话,最终也会返回null
89 (和上面第79行代码处括号内的解释是一样的)
90 */
91 break;
92 }
93 } else if (f instanceof TreeBin) {
94 //如果节点是红黑树的话,就执行红黑树的删除节点逻辑(红黑树的分析本文不做展开)
95 validated = true;
96 TreeBin<K, V> t = (TreeBin<K, V>) f;
97 TreeNode<K, V> r, p;
98 if ((r = t.root) != null &&
99 (p = r.findTreeNode(hash, key, null)) != null) {
100 V pv = p.val;
101 if (cv == null || cv == pv ||
102 (pv != null && cv.equals(pv))) {
103 oldVal = pv;
104 if (value != null)
105 p.val = value;
106 else if (t.removeTreeNode(p))
107 setTabAt(tab, i, untreeify(t.first));
108 }
109 }
110 }
111 }
112 }
113 //如果是普通节点或者是红黑树节点的话
114 if (validated) {
115 //并且找到了要替换或删除的节点
116 if (oldVal != null) {
117 /*
118 同时如果传进来的value为null,就说明此时是在做删除操作,而不是在做替换操作
119 此时调用addCount方法,传进去的第一个参数是-1,也就是将节点计数-1。而第二个参数
120 也为-1,是为了不去帮助扩容,因为在上面已经帮助扩容完成了
121 */
122 if (value == null)
123 addCount(-1L, -1);
124 //最后将旧值返回即可
125 return oldVal;
126 }
127 //如果没找到要删除的节点,就会break最终返回null
128 break;
129 }
130 }
131 }
132 return null;
133 }9 clear方法
1 /**
2 * ConcurrentHashMap:
3 */
4 public void clear() {
5 long delta = 0L;
6 int i = 0;
7 Node<K, V>[] tab = table;
8 //循环ConcurrentHashMap中的每一个桶
9 while (tab != null && i < tab.length) {
10 int fh;
11 //如前所示,通过tabAt方法来找到桶的位置
12 Node<K, V> f = tabAt(tab, i);
13 if (f == null)
14 //如果当前这个桶上没有数据存在的话,就将i+1,也就是继续清除下一个桶
15 ++i;
16 else if ((fh = f.hash) == MOVED) {
17 //和putVal方法一样,如果当前这个桶正在被迁移中,就去帮助一起去扩容。等扩容完成后,就更新一下tab
18 tab = helpTransfer(tab, f);
19 //因为迁移过后,桶上的数据就又都变了,所以重置i为0,重新开始清除每一个新桶上的数据
20 i = 0;
21 } else {
22 //synchronized锁住当前链表上的第一个节点,也就是锁住了这个桶,以防其他线程操作
23 synchronized (f) {
24 //双重检查
25 if (tabAt(tab, i) == f) {
26 /*
27 如果是普通的Node节点,p就为f;
28 否则如果是红黑树节点,就进行强转;
29 否则就为null
30 */
31 Node<K, V> p = (fh >= 0 ? f :
32 (f instanceof TreeBin) ?
33 ((TreeBin<K, V>) f).first : null);
34 //这里会遍历桶上的所有链表或红黑树节点,并记录数量在delta上
35 while (p != null) {
36 --delta;
37 p = p.next;
38 }
39 //通过setTabAt方法来将当前这个桶置为null(注意这里是i++),也就是在清除数据
40 setTabAt(tab, i++, null);
41 }
42 }
43 }
44 }
45 /*
46 清除完了数据之后,最后就是要更新一下计数了。这里会调用addCount方法,只不过这里传进去的delta为负数,
47 比如说如果当前有16个节点,delta就是-16,有32个节点,delta就是-32。这样最后计算出的节点个数就为初始值0了
48 至于这里传进去的-1,也是为了不去帮助扩容,因为在上面已经帮助扩容完成了
49 */
50 if (delta != 0L)
51 addCount(delta, -1);
52 }
点击下方我“在看”,送我一颗心
以上是关于JDK底层源码分析系列-你知道ConcurrentHashMap在Java 8中的实现是有bug的吗?而且还不止一处!的主要内容,如果未能解决你的问题,请参考以下文章
Java底层类和源码分析系列-HashTable底层架构和源码分析
Java ArrayList底层实现原理源码详细分析Jdk8