PinSAGE 召回模型及源码分析: PinSAGE 简介
Posted AINLP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PinSAGE 召回模型及源码分析: PinSAGE 简介相关的知识,希望对你有一定的参考价值。
Pinterest 推出的基于 GCN 的召回算法 PinSAGE,被誉为"GCN 在工业级推荐系统上的首次成功运用"。最近我也在搞基于 GCN 的召回算法,在学习 DGL 的过程中,发现 DGL 官方案例库中提供一个PinSAGE 的实现,赶紧下载下来,仔细研读了一番,感觉收获满满。尽管不是 Pinterest“原装”的实现,在很多技术细节上还缺乏工业级实现所必需的精雕细琢,但是 PinSAGE 的核心模块,比如基于 Random Walk 的重要邻居采样、Mini-Batch 训练、hinge loss、多模态特征接入、...,也都具备了。另外,DGL 这个 PinSAGE 实现,还演示了如何自定义 neighbor sampling、如何自定义 negative sampling、如何随机游走、...等 DGL 的高级功能,对于深入理解、熟练掌握 DGL 也极具参考价值。
本文是针对 DGL PinSAGE Example 的源码阅读笔记,先简单介绍一下 GraphSAGE 和 PinSAGE 的基础知识,接下来再按“训练数据供应”、"模型各模块"、“训练”三个环节解释其源代码。本文是第一部分。
基础知识
GCN 与 GraphSAGE
总之,如果想在推荐领域实践 GCN 或 GraphSAGE,我推荐读 Uber 的这一篇 blog <Food Discovery with Uber Eats: Using Graph Learning to Power Recommendations>就够了。GCN 或 GraphSAGE 的基本原理,用以下公式就能够解释了
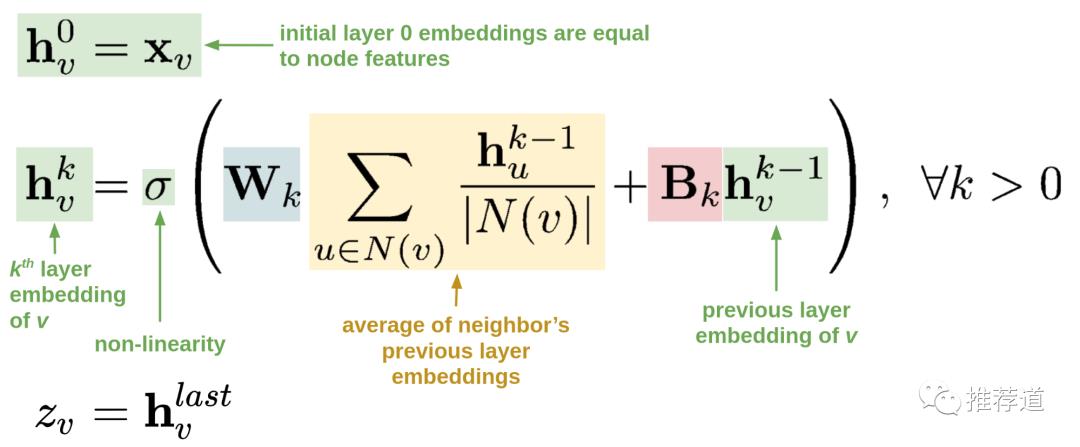
-
第一行,说明各节点 的初始表示,就等同于各节点自身的特征。这时还没有用上任何图的信息。 -
第二行,第 k 层卷积后,各节点的表示 , 和两部分有关 -
第一部分,括号中蓝色+黄色部分,即先聚合当前节点的邻居的第 k-1 层卷积结果( ),再做线性变换。这时就利用上了图的信息,即 某节点的邻居节点上的信息沿边传递到该节点并聚合(也就是卷积) -
第二部分,括号中红色+绿色部分,即当前节点的第 k-1 层卷积结果( ),再做线性变换 -
可以看到,如果不考虑括号中的第一部分, 这个公式简化为 ,是不是很眼熟?这不就是传统的 MLP 公式吗?所以, 图卷积的思想很简单,就是在做多层非线性变换之前,每个节点先聚合一次邻居的信息。 -
第三行,最后一层卷积后的结果,成为各节点最终向量表示。这个节点向量,既可以用于节点分类,也可以拿两个节点的向量来计算两节点存在边的可能性。
多层卷积的流程更可以用下图来直观表示
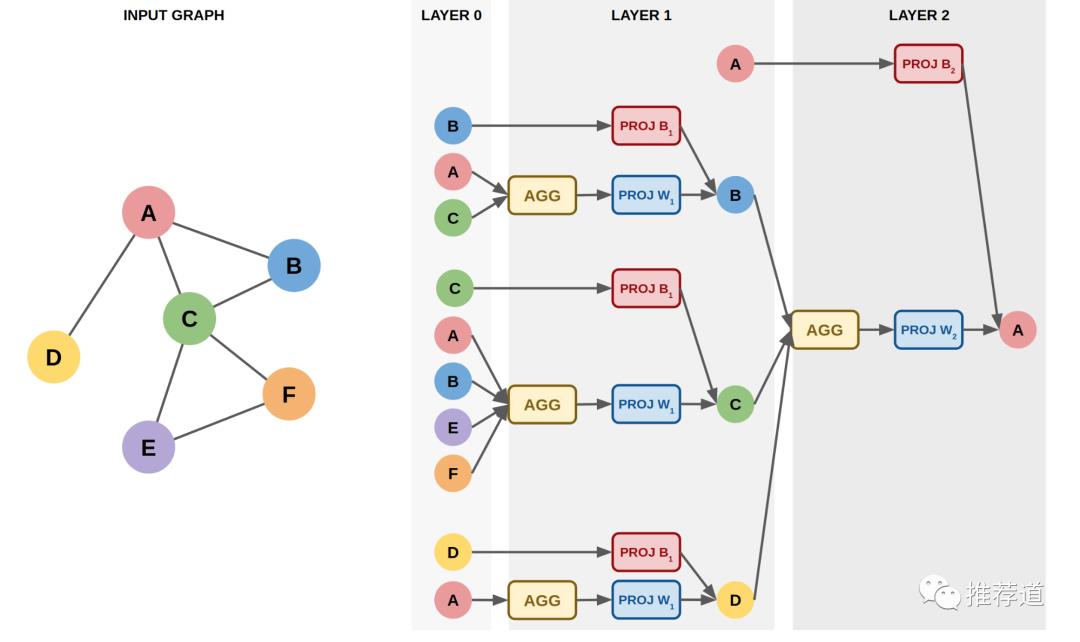
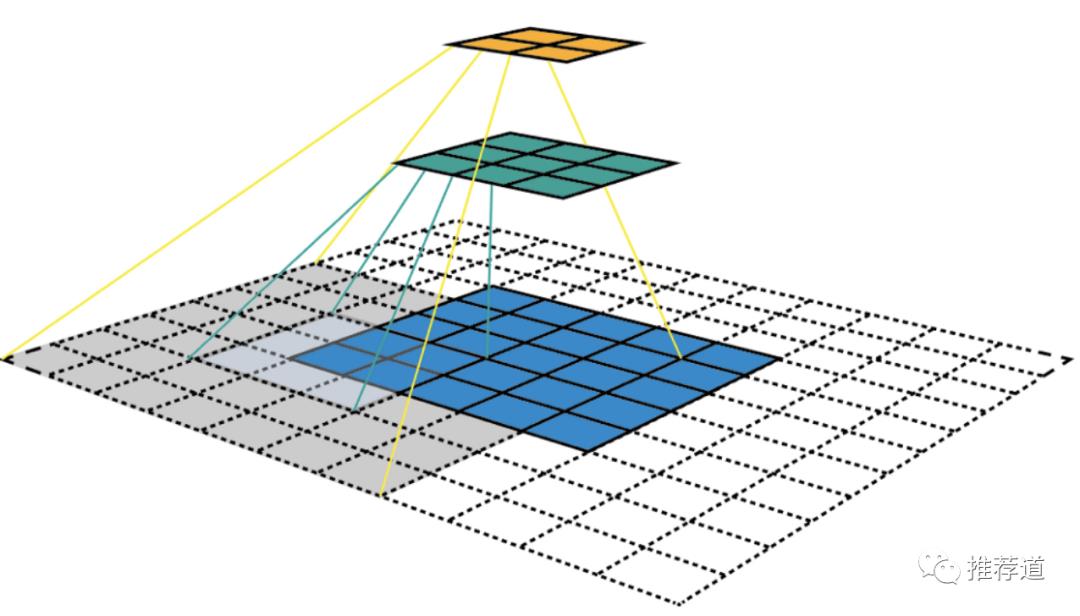
那么 GCN 相比于传统机器学习算法的优势在哪里?
-
刚才已经说了一条相比于普通 MLP 的优势:MLP 只利用了每个节点自身的特征信息;而 GCN 相当于 MLP 的扩展,在做下一层非线性变换之前,每个节点先把其邻居节点的信息聚合一波,利用节点自身特征之外,还利用了图的邻接关系。 -
相对于 word2vec 只利用了某节点局部邻居的信息,GCN 因为采用多层卷积,节点的邻居还利用各自邻居的信息,套用 CNN 的话来 说,就是“感受野”(receptive field)更大,能够利用更广域范围的信息。
PinSAGE
PinSAGE 是 Pinterest 公司基于 GraphSAGE 实现的召回算法。主要思想是通过 GraphSAGE 得到 pin(Pinterest 中的书签,可以理解为普通推荐系统中的 item)的向量表示,然后可以基于 pin embedding 做 item2item 的召回。PinSAGE 底层算法就是 GraphSAGE,只不过为了将其落地于一个 web-scale 的工业级推荐系统,PinSAGE 做了一系列的改进。PinSAGE 原文,没有复杂的数据公式,都是来源于一线实践的落地干货,满满工业风,强烈建议阅读。为了后续行文的完整性,这里将 PinSAGE 的特点(有很多也并非 PinSAGE 首创)做一个简单介绍:
单层卷积
PinSAGE 中单层卷积就是 GraphSAGE 常见手法,没什么特别的,在第二篇中我们可以直接看代码。

基于 Random Walk 的邻居采样
-
理论上,图卷积时,需要聚合某节点所有邻居节点的信息。在工业界的推荐场景中,一个 item 可能被几十万、上百万的 user 消费过,计算一个 item 上 embedding,需要聚合几十万、上百万的 user 节点,显然不现实的。 -
为此,GNN 的实战中都需要 neighbor sampling,只聚合部分邻居的信息。但是,传统的 uniform sampling,由于能够采样的邻居有限,造成较大 bias。 -
为此, PinSAGE 基于 Random Walk 找出目标节点的重要邻居,图卷积时只聚合这部分重要邻居上的信息。既减少计算量,又减少了 bias。这种 neighbor sampling 策略,已经实现在 dgl.sampling.PinSAGESampler中,下面会用到。
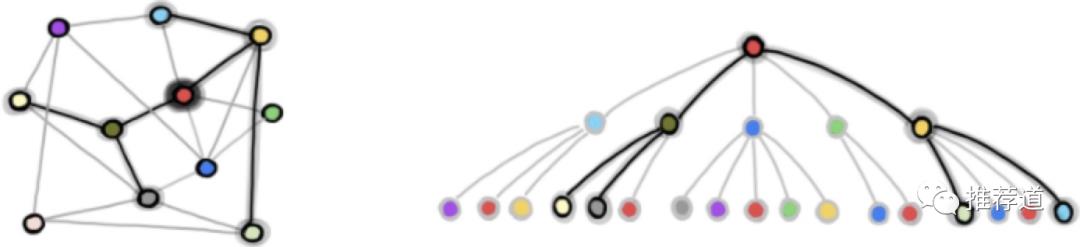
为 mini-batch 寻找所有需要参与计算的子图
-
推荐场景下的图非常大,需要将节点以 mini-batch 的方式进行训练,从而需要从原始完整图中寻找与 minn-batch 节点相关的子图 -
多层卷积时,每层都需要这样一幅子图。寻找的过程就是由最后一层的目标节点(mini-batch 中的全部节点),逐层向前“诛连”。
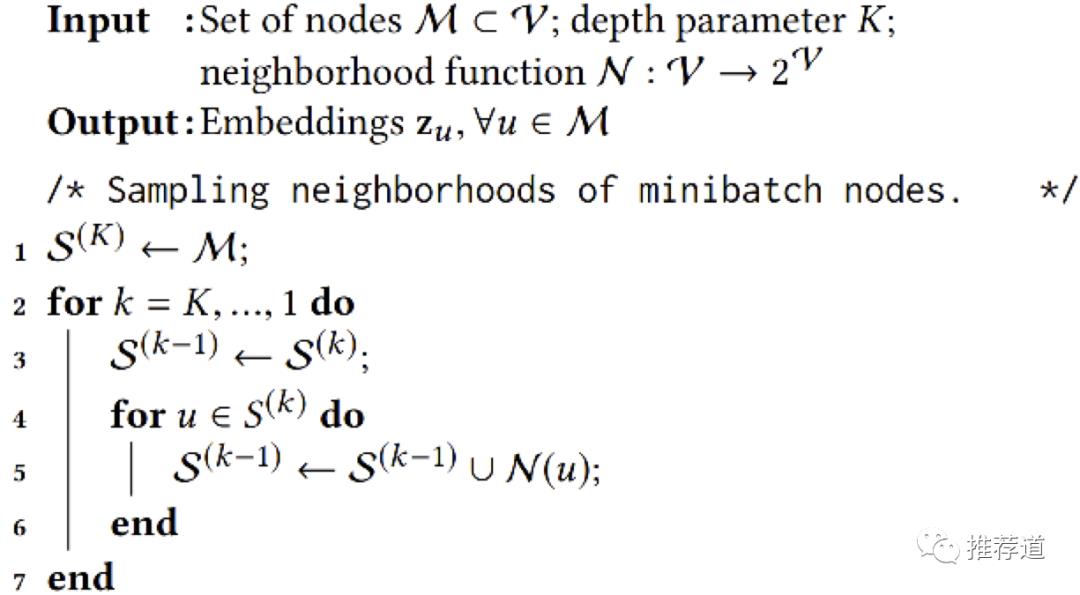
Margin Hinge Loss
训练采用了所谓 unsupervised learning,使用了 margin hinge loss。其中, 是 PinSage 得到的 query item 的 embedding, 是 PinSage 得到的"相关 item“的 embedding, 负采样得到”不相关 item“的 embedding
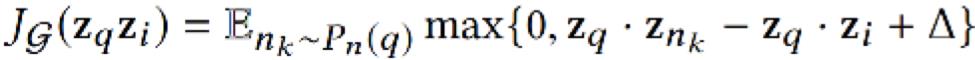
Hard Negative
提到负采样,Pinterest 团队同样注意到 hard negative sample 的重要性。对 easy negative, hard negative 不熟悉的同学,请出门左转看我之前的文章《负样本为王:评 Facebook 的向量化召回算法》。
-
PinSAGE 中实现 hard negative sampling 的方法,同样是基于在 neighbor sampling 时用到的 random walk。随机游走时给每个经过的节点都打上一个分数,这个分数就是该节点相对于源节点的 Personal PageRank (PPR)。按照 PPR 从大到小排序,选取排名中间的那部分节点就是源节点的 hard negative。 -
DGL 提供的 example 中,negaive 是在所有 item 节点中均匀采样得到的,即所谓的 easy negative, 没有实现 hard negative 的采样逻辑。
防止信息泄漏
还有一点是 DGL example 中实现了 ,但是在原论文中却没有提到的,就是如何避免“信息泄漏”
-
上述 hinge loss,可以看成一个 edge prediction 问题,即正确预测 与相关节点 之间存在边,而 与不相关节点 之间没有边 -
但是训练时提供的原图, q与i之间是实实在在存在边的,q与i节点上的信息沿着边相互传统,q与i之间的点积自然很大。这样的信息泄漏使模型根本学不到有用的信息。 -
为此,在为每个 mini-batch 生成各层需要的计算子图时, 需要将 之间的边统统删除,避免信息泄漏。
未完待续
GCN 和 PinSAGE 的基本原理就简单介绍完毕了。下一章将正式进入源码解析部分,先讲解 DGL PinSAGE Example 中是如何将训练数据喂入模型的。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
推荐阅读
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。
阅读至此了,分享、点赞、在看三选一吧 以上是关于PinSAGE 召回模型及源码分析: PinSAGE 简介的主要内容,如果未能解决你的问题,请参考以下文章