从V8源码分析一个JS 数组的内存占用问题
Posted Node地下铁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从V8源码分析一个JS 数组的内存占用问题相关的知识,希望对你有一定的参考价值。
前段时间,在排查一个问题的时候,遇到了一个有点令人困惑的情况,有下面这两段代码:
const a = new Array(99999);
a[99998] = undefined;
const b = new Array(99999);
b[99999] = undefined;
通过 node --inspect-brk 来分别运行这两段代码,在代码运行的最开始和结束的时候分别take heap snapshot,分析对应的内存占用信息如下: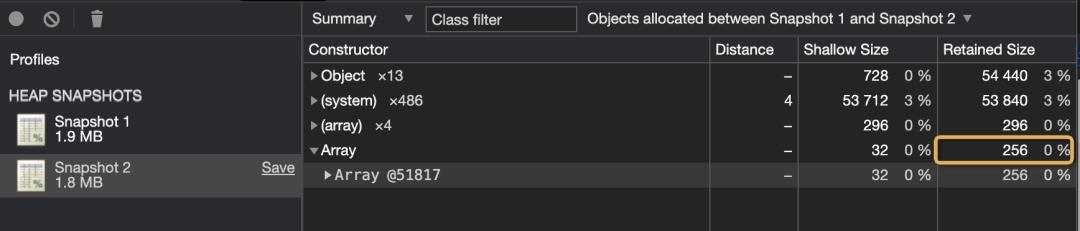 可以发现第二段代码的内存占用明显要小于第一段,那么问题就出现在这个
可以发现第二段代码的内存占用明显要小于第一段,那么问题就出现在这个 99999 的越界赋值上面。
在V8代码(v8/src/objects/js-array.h#L19)中有很明确的标注,数组有两种模式,快数组和慢数组,在数组初始化时,默认的存储方式为快数组(v8/src/objects/js-objects.h#L317),其内存占用是连续的,而慢数组会使用HashTable来进行数据存储。另外数组会分为压紧的(Packed)和有洞的(Holey)两种,例如['a', 'b', 'c'] 这样的数组长度为3,数组索引0、1、2均有值,那么就认为是Packed;而对于 ['a',,,'d'] 这样的数组,长度为4,但是索引1、2位置并没有进行初始化赋值,那么就认为是Holey。当数组出现了较大空洞的时候,内存明显是被浪费了。
V8中对于大型空洞数组进行了优化,在V8博客(https://v8.dev/blog/fast-properties)中说明了这一点,对于非常大的Holey数组来说,FixedArray会造成内存浪费,所以会使用字典来节约内存,也就是会使用慢数组模式。
使用v8-debug(可通过jsvu进行安装)分别对最开始的两段代码进行调试: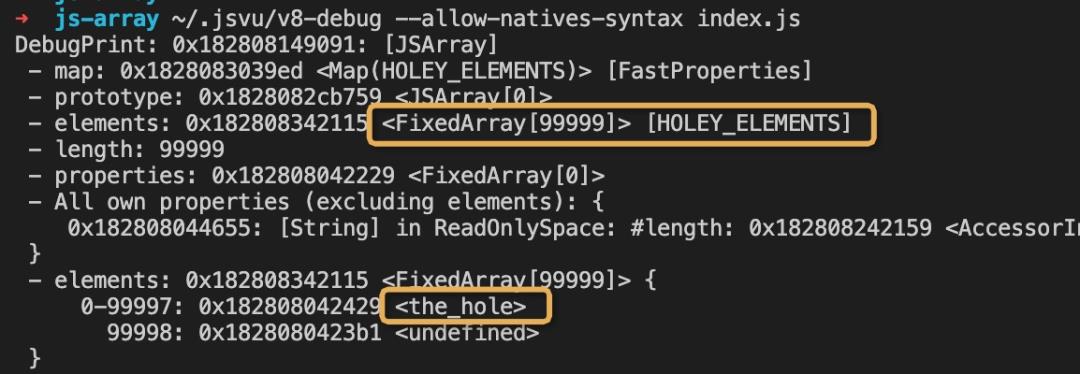
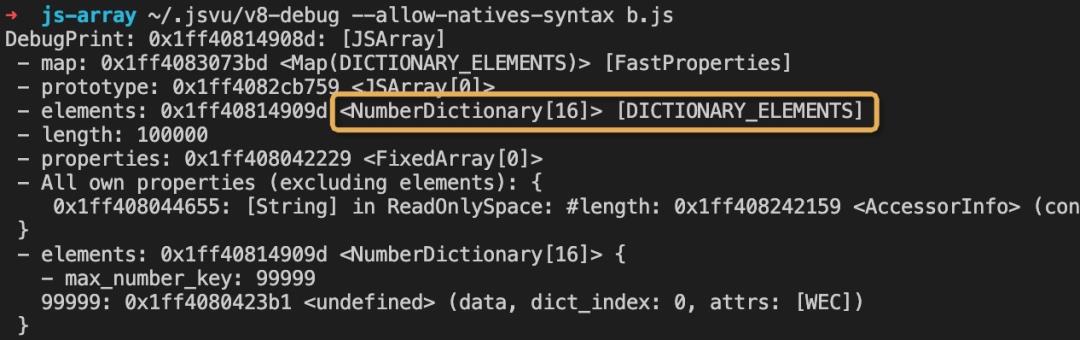 可以很明显的看到,第一个数组为FixedArray,而第二个数组为Dictionary,那么为什么只有第二个数组转换为了字典模式呢?
可以很明显的看到,第一个数组为FixedArray,而第二个数组为Dictionary,那么为什么只有第二个数组转换为了字典模式呢?
在V8中JSArray是继承于JSObject的,所以当设置属性的时候,相关的代码调用栈为 Object::SetProperty > Object::AddDataProperty > JSObject::AddDataElement > ShouldConvertToSlowElements ,在最后通过 ShouldConvertToSlowElements这个方法,来判断是否将一个数组转换为慢模式(Dictionary)(v8/src/objects/js-objects-inl.h#L794):
从上面的代码可以看到,当设置 99998 的时候,索引小于当前容量(99999)的时候,返回值为false,也就是不进行转换。
而当设置 99999 这个索引的值的时候,因为超出了原来的FixedArray容量,那么就会进行扩容,扩容的算法(v8/src/objects/js-objects.h#L540)为:容量 + 容量 /2 + 16,那么原来 99999 的容量就会扩容放大到 15万。然后会执行 GetFastElementsUsage 来获取原来的数组中非空洞(v8/src/objects/js-objects.cc#L4725)的元素数量,乘以 kPreferFastElementsSizeFactor(值为3) 与 kEntrySize (值为2) ,与新的容量长度进行对比,如果小于新的容量长度,那么就转换为慢数组。
最开始的第二段代码中,非空洞元素数量为0,计算后的乘积也为0,因此小于15万的新数组长度,于是数组转换为了慢数组,使用了Dictionary进行数据的存储,从而节省了大量的内存。
以上是关于从V8源码分析一个JS 数组的内存占用问题的主要内容,如果未能解决你的问题,请参考以下文章