JDK1.7下的HashMap的源码分析
Posted 码可思
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JDK1.7下的HashMap的源码分析相关的知识,希望对你有一定的参考价值。
源码分析jdk1.7下的HashMap
我们都知道1.7版本的hashmap的底层是数组加链表构成的,那么今天我们就来自己分析一波源码~
篇幅有点长,废话不多说,直接开始分析~
「属性声明」
//初始化容量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//最大的容量
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
int threshold;
「构造方法」
//自定义初始化容量和加载因子,会进行判断两个值合不合法
// The default initial capacity - MUST be a power of two. 容量必须是2的幂次方
public HashMap(int initialCapacity, float loadFactor)
//自定义初始化容量,使用默认的加载因子
public HashMap(int initialCapacity)
//使用默认的初始化容量和默认的加载因子
public HashMap()
//归根结底 最终都是调用了这个构造方法
public HashMap(int initialCapacity, float loadFactor) {
//判断初始化容量是否合法
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//当初始化容量大于等于最大容量时,直接赋值为最大容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//判断加载因子是否和法
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
//给加载因子赋值
this.loadFactor = loadFactor;
//这里留个问题? 这个究竟是干嘛的?为什么要赋值给它。
threshold = initialCapacity;
init(); //hashMap中该方法为空,没有实现,在LinkedList才有实现,所以这里不做研究
}
「put方法」
public V put(K key, V value) {
//当前table数组为空,则去进行初始化大小,在这里我们就能够知道在构造方法中,为什么要将初始化容量赋值给threshold了,根据我的理解其实就是起到一个懒初始化的效果吧,就是当你去put第一个值的时候,它才去进行初始化数组的大小
if (table == EMPTY_TABLE) {
inflateTable(threshold); // 跳到1
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
-
inflateTable(threshold)
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize 根据注释可以知道是找到一个大于等于toSize的2的幂次方
// 例如toSize=5 时,则capacity此时就会等于8
int capacity = roundUpToPowerOf2(toSize);
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
我们继续探究
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
// 进来看我们可以发现这是两个三目表达式嵌套
// 又出现了一个我们不认识的函数, 我们继续深究它
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
我们继续往下点
// 这个函数看上去很是简洁,全是位运算,那么它就是是在干嘛呢?
public static int highestOneBit(int i) {
// HD, Figure 3-1
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
return i - (i >>> 1);
}
❝我们举个例子来验证一下它是干嘛的?(下面图片左移为右移)
❞
❝不知道大家有没有发现一个规律,最后返回的结果跟我们传进去的i有什么关系吗?
刚刚调用highestOneBit 的roundUpToPowerOf2这个函数,官方的注释已经告诉我们是寻找一个大于等于toSize的2的幂次方
❞ 
image-20201205160747608
那我们回到 highestOneBit 这个函数,传进去5返回的是4,传进去14返回的是8,有了上面的穿插,我们应该不难发现,该函数的作用恰巧与 roundUpToPowerOf2 的目的相反,highestOneBit 它是找出小于等于i的2的幂次方的数,即5 -> 4, 15-> 8。
那么我们的疑问来了,为什么要有五次右移操作呢?而且右移的次数也不一样?下面我们一起探究~
❝第一次右移了1位,第二次右移了2位,第三次右移了4位,·····到了第五次右移16位,一共合起来总共右移了 31位。
不知道大家有没有觉得答案正在步步逼近,我们int类型在内存中占4个字节,一共32位。假设i非常的大,整整占满了32位,然后我们上面将一个整型的字整整右移了31位,这样的效果岂不是能把后31位全部置为了1,接下来下面的操作,得到的这个数再减去它无符号右移后的数,结果不就是 0010 ····(此处省略28个0)。与原来的数 1xxx ····(此处省略28个x,x代表0或1)对比,不就是找到了小于等于i的2的幂次方吗?是不是很奇妙~
❞
好了,那么现在我们要一步步往上返回去了,因为我们从刚刚函数一直往底层深究,现在要往上面返回了~
//此时我们返回到这里,highestOneBit是传进去5返回4
//然后该函数是传进去5返回8
//很明显是相反的,那么它是怎么实现的呢?
/**
假设现在number等于5,它最终回去调用这个Integer.highestOneBit((number - 1) << 1),
下面我们都用位运算表示 0000 0101 - 0000 0001 = 0000 0100 << 1 = 0000 1000 = 8
此时调用highestOneBit函数,传进去的是8,小于等于8的2幂次方的数不就是8吗?
此时roundUpToPowerOf2该函数不就得到的数不就是大于等于5的2的幂次方的数吗?
**/
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
这时候我们只能感慨,实现这几个函数的外国佬在当时早已把位运算用得出神入化!!!
继续往上返回
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
//这里先标记着,有待研究,因为与后面无关,所以先不探讨(此值与扩容有关,在最后讲)
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
//此时我们就可以看到它给table开辟了一个大小为capacity的数组了。
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
好了,来来回回游荡了这么久,我们就要又回到put函数了
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
//key为null时,调用下面的方法去将null-value加进去
//这里可以自己复习的时候点进去看因为里面很简单易懂,这里节省时间不单独
//跟下面的循环一样的
return putForNullKey(value);
//跳到下面解释1
int hash = hash(key);
int i = indexFor(hash, table.length);
//跳到下面解释2
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//当put进去的key算出来的位置此时为null时,则会执行到这里,跳到解释3
modCount++;
addEntry(hash, key, value, i);
return null;
}
int hash = hash(key); //算出key的哈希值
int i = indexFor(hash, table.length);
//这里讲一下hashmap的每一个key的存储规则,我们知道1.7它是用链表+数组去实现的,那么每次我们put进去一对k-v
//它是怎么去存储的呢? 这两行就是算出该key具体放在数组中哪个位置,它是利用key的哈希值去模上数组的长度,
//最后算出来的就是它在数组中存储的下标,indexFor的源码在下面
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1); //为什么是减1呢,因为数组的下标是从0开始的
}
由于hash()函数涉及到哈希种子方面的知识,这里就先不做解释了(因为我还没搞懂,--!)。
//这里的循环其实很容易懂,我们看下面的图就是可以知道
//当put进去的key原来已经存在时,则会替换掉原来的value然后返回旧的值
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this); //这里没有实现,在LinkedHashMap有实现,涉及LRU缓存结构
return oldValue;
}
}
❝需要注意一点的就是,每次put进去的key都是放在链表的头部,也就是将往下挤
❞
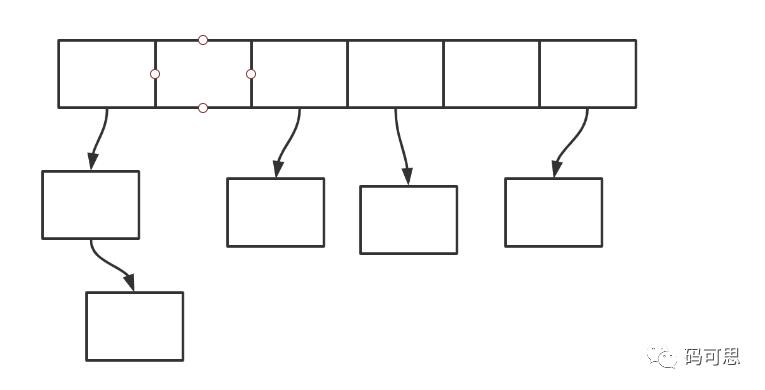
在这里,引用一下不知道谁说的一句话 Don't BB,show me the code ,我们写个demo测试一下
public class HashMapTest {
public static void main(String[] args) {
HashMap<Integer, Integer> hashMap = new HashMap<>();
System.out.println(hashMap.put(1, 10));
System.out.println(hashMap.put(1, 20));
}
}
运行输出:结果很明显,第一次put进去值,此时hashmap还是空的,将1-10put进去后,返回oldval为null
第二次put 1-20 此时就会覆盖原来的10然后返回oldval为10,此时get(1)将为等于20。

// hash为hash值 bucketIndex为上面算出来的key要放进去的下标
void addEntry(int hash, K key, V value, int bucketIndex) {
// 这里是对hashmap进行扩容下面单独讲
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
//不需要扩容则调用这个函数
createEntry(hash, key, value, bucketIndex);
}
//这个函数就是简单的将key添加进去
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++; //标记table数组中已存储key-val的个数,为了判断是否需要扩容
}
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
上面基本都把该肝的都肝完了,现在我们来探究一波扩容的问题
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
好了,在前面出现的 threshold 这个属性值,现在又出现了,我们知道size的作用是表示现在我们hashmap中所有的k-v键值对的个数,此时如果 超过了 threshold并且当前要存储的位置的下标中已经有值了(这两个条件缺一不可) ,则会进行扩容。
// threshold这个值是怎么算出来的,我们可以看这个式子
// capacity * loadFactor 初始化容量*加载因子
// 已默认的容量和加载因子为例子,
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int MAXIMUM_CAPACITY = 1 << 30;
// 可以算出 capacity * loadFactor = 16*0.75 = 12
// 取小的值赋值给 threshold,最大容量非常的大,所以此时默认情况 threshold = 12
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
也就是说当哈希表中的元素大于等于12时,此时想要put进去一个键值对,我们通过上面的解释,知道put进去值的过程,首先需要通过hash(key)算出hash值,然后再模上数组的长度,这样就算出了下标index,假设此时 table[index]!= null,则会发生扩容,不然的话则不会发生扩容。
(size >= threshold) && (null != table[bucketIndex]) //这两个条件缺一不可
下面进行代码测试:
「Test1」
public class HashMapTest {
public static void main(String[] args) throws Exception {
HashMap<String, String> map = new HashMap<>();
//我们用循环put进去15个k-v
for (int i = 1; i <= 15; i++){
map.put("test"+i,"test");
}
//下面通过反射这个骚操作取一下里面的值进行验证
//不会反射的可以去OB一下我很久之前发的文章
Class<? extends HashMap> mapType = map.getClass();
Method capacity = mapType.getDeclaredMethod("capacity");
capacity.setAccessible(true);
System.out.println("capacity : " + capacity.invoke(map));
Field size = mapType.getDeclaredField("size");
size.setAccessible(true);
System.out.println("size : " + size.get(map));
Field threshold = mapType.getDeclaredField("threshold");
threshold.setAccessible(true);
System.out.println("threshold : " + threshold.get(map));
Field loadFactor = mapType.getDeclaredField("loadFactor");
loadFactor.setAccessible(true);
System.out.println("loadFactor : " + loadFactor.get(map));
}
}
大家猜一下结果会是怎么样的呢?先不要着急往下看,理解一下代码,然后再心中或者纸上写下你的猜测
❝我猜测 capacity=16, size=15, threshold=12, loadFactor=0.75
❞
我们来看看结果:
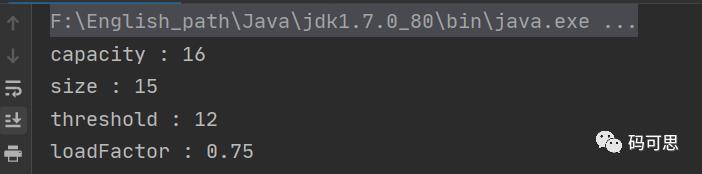
你猜对了嘛?其实结果还是很容易理解的,全是默认的值,因为此时根本就没有满足扩容的条件
再次重复下扩容的条件 size>=threshold && table[index]!=null
接下来我们进行测试:
「Test2」
//为了节省篇幅,我就仅仅贴出与上面不同的代码
//这次我还是put进去15个k-v,唯一与上个测试不一样的是put进去的k-v
for (int i = 1; i <= 15; i++){
map.put(i+"",i*10+"");
}
我们在来猜一下输出的结果?
❝结果跟上面的一样?capacity=16, size=15, threshold=12, loadFactor=0.75
❞
输出的结果肯定和上面的不一样啦,测试才有意义,不然的话就没有意义了。
运行输出我们可以发现:
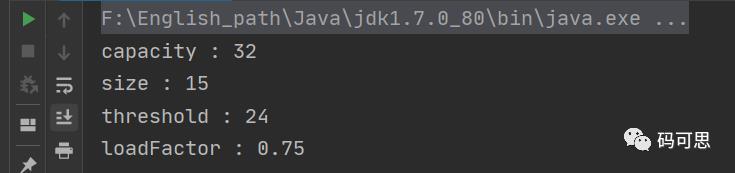
好家伙,团灭!居然和我们预想的值不一样,那究竟是怎么回事呢?
我们再回过头来分析一下扩容的条件 size>=threshold&&table[index]!=null
因为很明显它进行了扩容,说明满足了上面的两个条件。
❝那么现在我们的问题来了?Test1和Test2的区别在哪里?
我们可以看到,同样put进去15个值,15>12 很明显满足第一个条件,那么为什么Test1中不满足第二个条件,然后Test2就满足呢?下面让我画个图解答这些疑惑~
❞
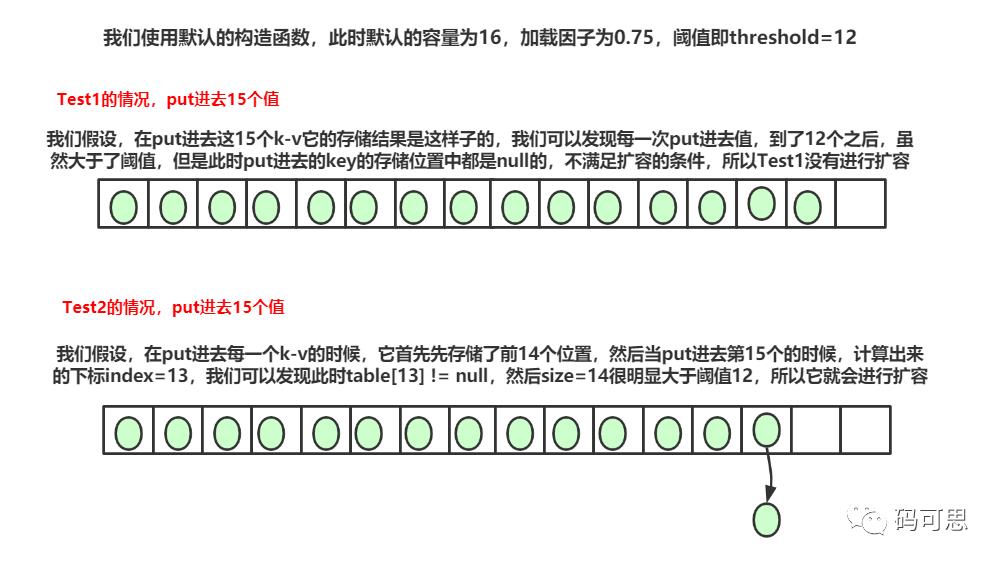
在这一引入一个名词,哈希碰撞,哈希碰撞叫什么呢?正如Test2一样,在put进去第15个key-val的时候,在经过哈希计算下标值的时候,两个不同的hash值算出来了相同的下标,就称为哈希碰撞。
「小结:」 默认的容量为16,加载因子为0.75,阈值即threshold=12。
那么,哈希表最多存储多少个值后才会进行扩容呢?最多可以存11+15+1 = 27个,怎么算出来的呢?
在极端情况下,在第一个位置,可以put进去11个k-v,此时小于阈值12,不会发生扩容,然后接下来在剩余的15个位置中put进去k-v,此时size大于阈值,但是没有发生哈希碰撞,不会扩容,接下来再put进去一个k-v,此时必定会发生哈希碰撞,所以就发生了扩容,所以才有了 11+15+1。
我们知道了,在什么情况下会发生扩容,那么接下来我们就来看一下是怎么个扩容法:
//调用resize函数
//传进去两倍的oldtable.length
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
void resize(int newCapacity) {
Entry[] oldTable = table;
//old数组容量如果等于最大容量 1<<30 这么大,直接将阈值设置为一样的大小然后返回。
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//新建一个数组,数组的长度为原来的两倍,上面传进来的参数
Entry[] newTable = new Entry[newCapacity];
//调用transfer函数 initHashSeedAsNeeded函数为初始化哈希种子的值,HashSeed
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
//算出新的阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
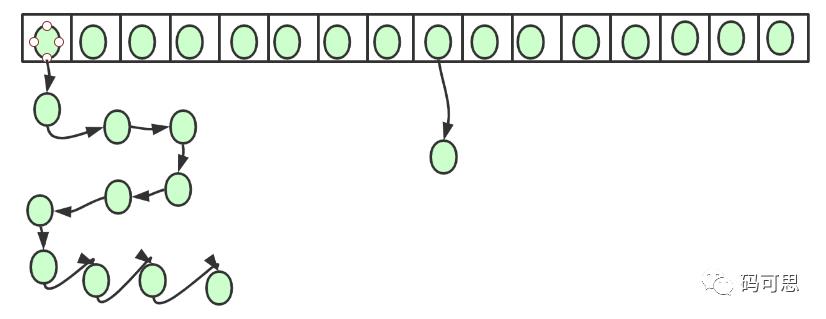
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) { //对应图中的1
while(null != e) {
Entry<K,V> next = e.next; //对应了图中的2
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i]; //对应图中的3
newTable[i] = e; //对应4
e = next; //对应5
}
}
}
下面画图理解:那个没有底色的圆圈代表null,为了画图效果而把它加上
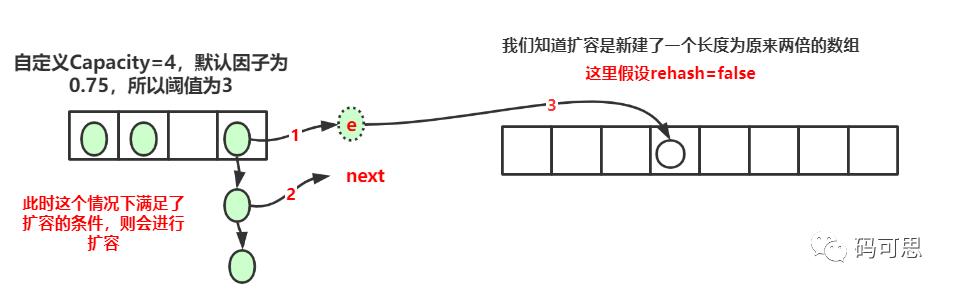
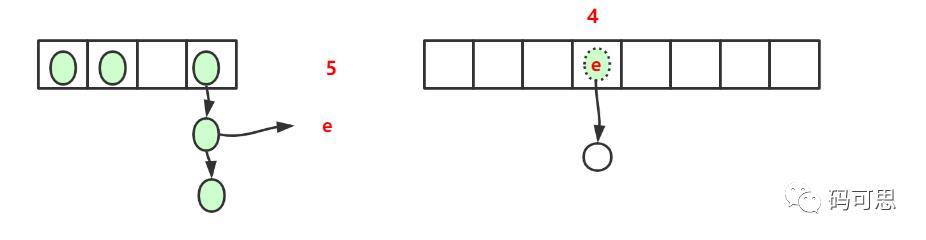
因为还不懂得怎么画动态图,就用两个静态图描述了这个动态的过程,如何往复最后变成的样子为
我们可以发现,扩容后链表发生了反转。
还有一点需要注意的是,每个k-v放在新数组中,还是原来的下标吗?要是一样的话,岂不是没有扩容的意义,所以下标还是会有所不同的情况的,这行代码就是算出新的下标
int i = indexFor(e.hash, newCapacity);
//这里做个假设原来的hash值为17,17%4 == 1 17%8 == 1,此时算出来的下标都是1
//假设hash值为21, 21%4=1 21%8=5 = 1+4,此时可以发现下标出现了不一样
//因为每次扩容都是将原来的容量*2,所以我们不难发现,key放在新数组的位置,要么就不变,要么就是原来下标+原来的容量
到这里,整个过程就已经讲完了。要是你从头看到这里,那么我为你的坚持点个赞,肝了一天,终于把jdk1.7的hashmap的源码分析透了。当你面试的时候,面试官问起,你就可以吊打面试官问的所有问题了,但是hashmap还不止于此,因为,在jdk1.8版本中,它将引用红黑树,所以jdk1.8版本的hashmap则由 链表+数组+红黑树 构成,接下来我也会进行源码分析一波,研究透彻,然后继续肝出来。
在看源码的过程中也很艰难,但是坚持下来的收获远远是你意想不到的。
「最后,以上源码分析如有错误,恳请指正。」
以上是关于JDK1.7下的HashMap的源码分析的主要内容,如果未能解决你的问题,请参考以下文章
Java中HashMap底层实现原理(JDK1.8)源码分析