runc源码分析
Posted 搜狗输入法技术团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了runc源码分析相关的知识,希望对你有一定的参考价值。
笔者日常维护和开发的服务都是将docker image部署到kubernetes集群,时常因为缺少对背后的细节和原理认知,踩过坑也走过弯路,让笔者深刻认识到实现的细节有多么重要。后端程序员接触到docker,也许是通过docker这个CLI命令,或许是通过kubernetes,也或者是想尝试一个开源工具,而这个工具提供了用docker启动的简单入门方式……而所有这些,多数开发者并不是直接接触到runc。但笔者觉得,runc在docker及整个生态中像一把关键钥匙,通过了解runc的背后实现,有助于我们更好的理解其中许多的奥秘。
笔者能力有限,无法站在一个更高的维度来更好的抽象runc的架构设计和面面俱到的阐述runc的实现细节。本文从runc实现namespace过程来抛砖引玉,从自己的理解出发,希望能给读者一些帮助。
阅读本文之前,推荐读者读一下这篇文章:
https://mkdev.me/en/posts/the-tool-that-really-runs-your-containers-deep-dive-into-runc-and-oci-specifications
runc简介
(照片来自www.pexels.com David Dibert 摄影师)
docker生态常见用航海,集装箱,航舵等等logo。马尔科姆·麦克莱恩被称为集装箱之父,自从有了这个标准尺寸的箱子,世界货运的历史从此被改变。而容器也常常被称为集装箱,巴别塔的故事告诉我们:一旦有了通用的标准,连上帝都会感觉恐怖。
runc是docker组件中的low-level runtime(与之相对应的high-level是containerd),它本身是一个创建并运行容器的命令行。它是真正实现将我们的应用运行在"沙箱"中的关键。
docker组件及进程间关系如下图所示:
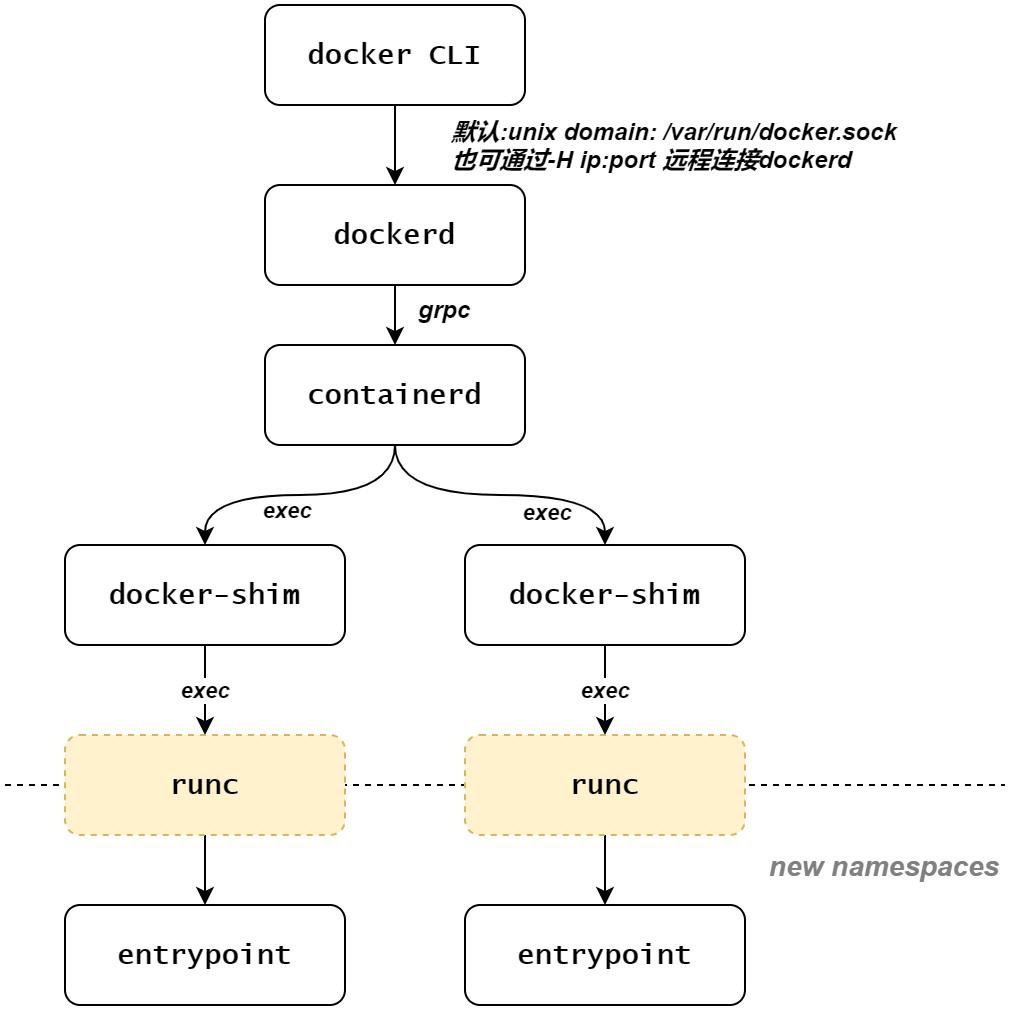
如上图: 在一系列docker组件中,runc处于最后的处理部分,也是距离用户应用最近的一环。
runc经过多次自身调用,历经新旧namespace创建和切换,最后执行entrypoint替换掉自身进程,可谓是实现容器化的幕后英雄。
本文重点放在runc的多次自身调用实现切换namespaces上面。
本文分析使用的版本:
github repo: https://github.com/opencontainers/runc/
commit: 636f23dd21bda3a7d54c134f7612e9a25522e5f5
准备工作
bundle
docker处理流程到runc阶段,所需的容器名称(container id),根文件系统(rootfs),以及配置(config.json)已经准备就绪了。其中,rootfs和config.json称为bundle。(这一点跟macos的安装包的包内容很相似: mac的软件安装包内容放在一个Contents目录中,目录下有个info.plist的描述文件) docker的bundle有一个专门为此开放的规范称之为OCI: (Open Container Initiative Runtime Specification),后期之秀像gVisor等其他容器引擎都遵循OCI规范。简单来说,docker的bundle包含了完整的根目录及docker运行时的运行时库,文件,程序等等。其中的config.json配置描述docker运行起来要执行的应用程序路径,执行的终端信息,还包括了各个操作系统平台下的一些操作细节,比如: 在Linux环境下需要开启哪些命名空间,文件的挂载点和cgoups资源限制等等。
创建方法
$ mkdir /mycontainer; cd /mycontainer
# 创建一个根目录
$ mkdir rootfs
# 以busybox镜像为例,将busybox镜像中的文件导出到rootfs目录下
$ docker export $(docker create busybox) tar -C rootfs -xvf -
# 生成 config.json 的配置模板
$ runc specrootfs是一个可以chroot的完整文件根目录:
$ tree -L 1 rootfs
rootfs
├── bin
├── dev
├── etc
├── home
├── proc
├── root
├── sys
├── tmp
├── usr
└── var如果将容器比作集装箱,那么config.json可以是这个"集装箱"的规格说明书。config.json长成这个样子:
{
"process": {
"terminal": false,
"user": { "uid": 0, "gid": 0},
"args": ["sh"],
"cwd": "/",
"capabilities": {},
"rlimits": [],
"noNewPrivileges": true
},
"hostname": "runc",
"mounts": [],
"linux": {
"resources": {},
"namespaces": [
{"type": "pid"},
{"type": "network"},
{"type": "ipc"},
{"type": "uts"},
{"type": "mount"}
],
"maskedPaths": [],
"readonlyPaths": []
}
}这个配置中的process.args就是用户在Dockfile中指定的entrypoint,linux.namespaces来指示runc生成的容器要创建的新的namespace。
调试工具
在分析开源代码时,一款调试工具有助于我们更清楚地追踪整个执行流程,掌握主体脉络。笔者这里选用delve和gdb这两款调试工具,这两个调试工具在使用上比较类似。这两款调试工具各有优劣。
dlv专职调试go程序,比如像gr/grs等可以查看goroutine信息,但dlv有一定局限性,无法对子进程进行调试。
gdb是老牌的调试器,它对c/c++等系统native程序支持完善。在调试go程序时,对go变量打印不太友好。这里选择gdb是因为gdb具有强大的follow-fork-mode特性,可以追踪runc的多个子进程。
需要说明的是,笔者的机器上安装的是gdb 8.1.1,这个版本对clone(2)的子进程进行调试时有bug(gdb follow-fork-mode bug),笔者最终下载最新的10.1版本gdb,调试过程非常流畅。
编译及调试
delve
# 进入到源码目录,debug后可跟package。这里指main包。如果想要给程序传递参数,则可跟在“--”之后。
dlv debug . -- create mycontainer -b /home/noodles/work/mydocker/
# b/break 这里在process_linux.go 315行设置断点
(dlv) b /home/noodles/codes/opensrc/runc/libcontainer/process_linux.go:315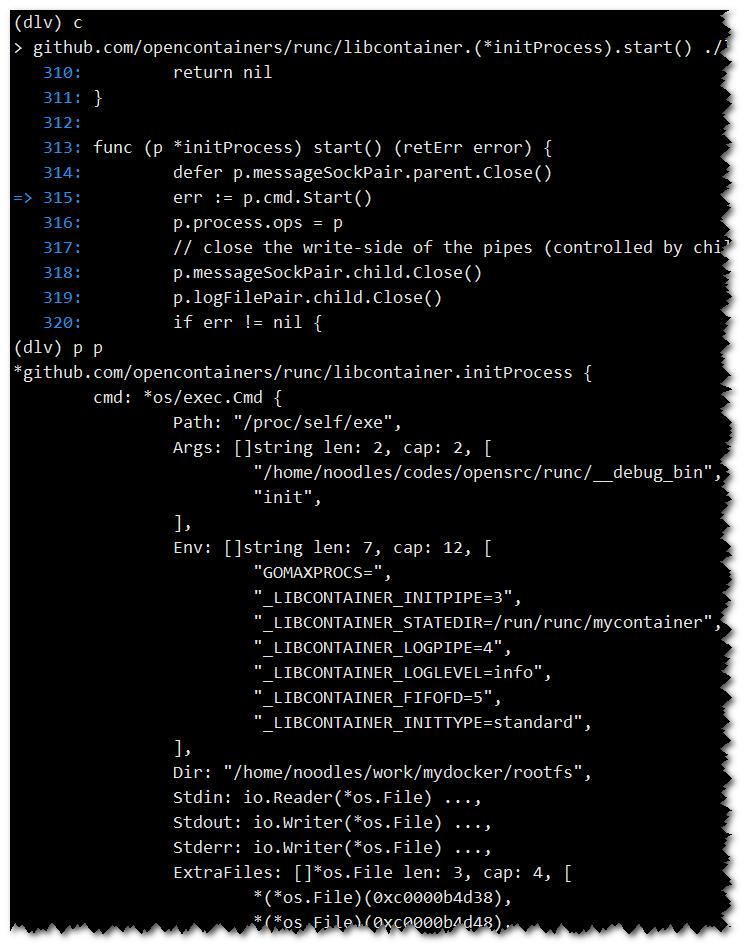
gdb
go build -gcflags=all="-N -l" # 添加调试信息,避免对一些函数进行优化内联造成调试困难gdb ./runc
(gdb) set args create mycontainer -b /home/noodles/mycontainer # 设置runc启动参数
(gdb) set follow-fork-mode child # 设置追踪fork子进程模式
(gdb) b /home/noodles/codes/opensrc/runc/utils_linux.go:249 # 设置断点
(gdb) r # run
runc源码分析
接下来的分析将runc的执行过程分为三部分:
runc create
runc init
runc start
其中,runc create为runc init做准备工作,runc init 很少被直接使用,而是被 runc create 隐式地调用,runc init是本文要分析的重点。
另外,runc run其实是将三部走变成一步走。
runc create <container-id>
runc create 调用路径
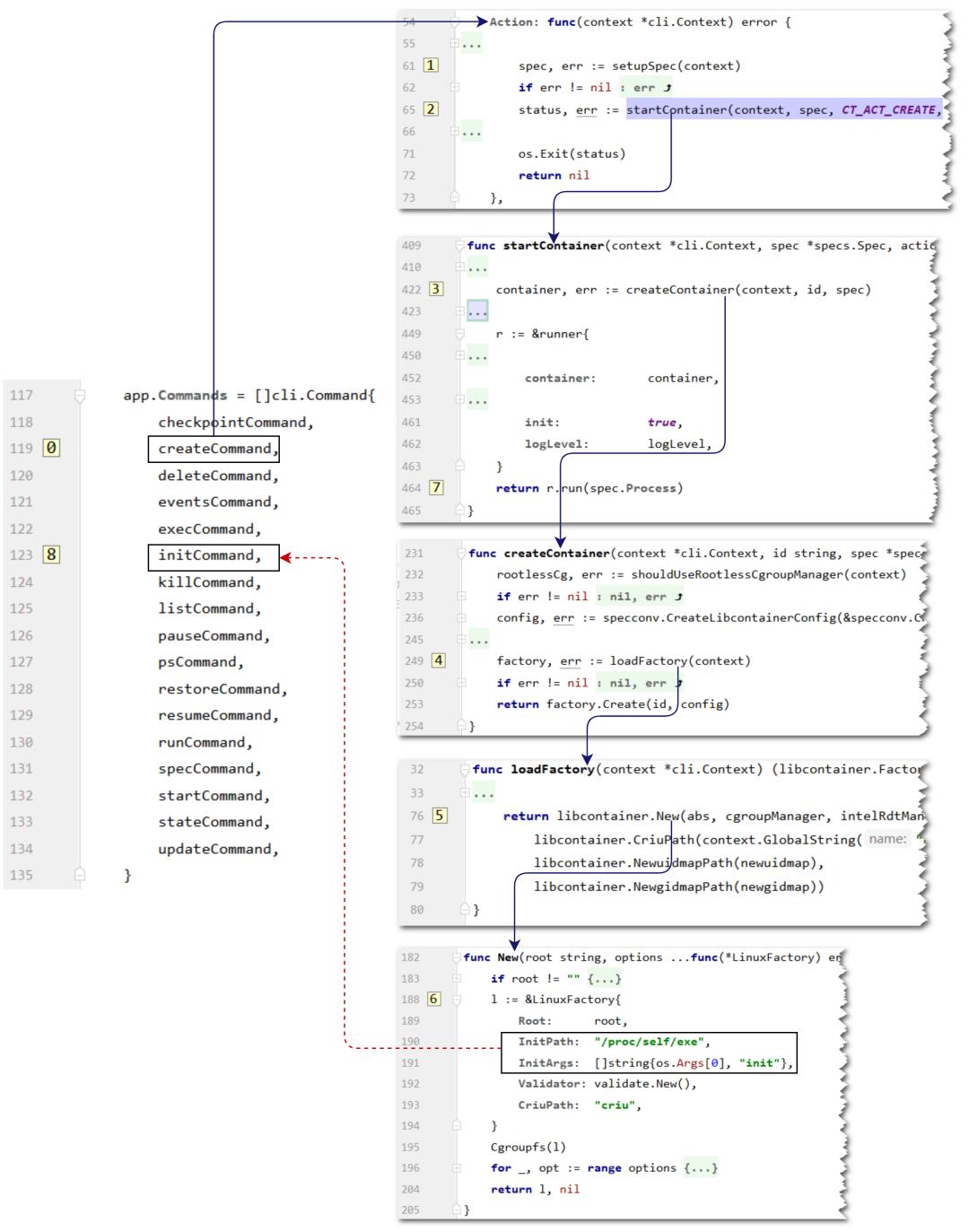
main.go:117 行是runc的所有子命令。
从createCommand开始,经过第一轮处理,runc create 会以runc init回到initCommand。过程比较清晰:
第1步中: setupSepc(context)加载bundle目录下的config.json配置。
在第5,6步,构造一个工厂函数,这个LinuxFactory的可执行文件设置为/proc/self/exe,其实就是runc自己,它的参数是init,也即,在后续过程中的某个地方执行runc init,于是整个流程又从上图中标注的第8步: initCommand子命令开始,进入到runc的init阶段。
在第7步之前,构造runner对象。在 create 阶段,runner.init为true。然后调用run()。
首先,从run()开始:
272 func(r *runner)run(config *specs.Process) (int, error) {
282 process, err := newProcess(*config, r.init)
319 switch r.action {
320 case CT_ACT_CREATE:
321 err = r.container.Start(process)
322 case CT_ACT_RESTORE:
323 err = r.container.Restore(process, r.criuOpts)
324 case CT_ACT_RUN:
325 err = r.container.Run(process)
326 default:
327 panic("Unknown action")
328 }
357 }// newProcess: 将读取到的config.json的process配置构造成libcontainer.Process。
// 例如,这里的Args就是`sh`, Env是`PATH`环境变量。
106 func newProcess(p specs.Process, init bool) (*libcontainer.Process) {
107 lp := &libcontainer.Process{
108 Args: p.Args,
109 Env: p.Env,
111 User: fmt.Sprintf("%d:%d", p.User.UID, p.User.GID),
112 Cwd: p.Cwd,
113 Label: p.SelinuxLabel,
114 NoNewPrivileges: &p.NoNewPrivileges,
115 AppArmorProfile: p.ApparmorProfile,
116 Init: init, // true
118 }
143 return lp
144 }执行libcontainer/container_linux.go中linuxContainer.Start():
252 func(c *linuxContainer) Start(process *Process) error {
258 if process.Init {
259 if err := c.createExecFifo(); err != nil {
260 return err
261 }
262 }
263 if err := c.start(process); err != nil {
264 if process.Init {
265 c.deleteExecFifo()
266 }
267 return err
268 }
269 return nil
270 }create 阶段,process.Init=true。
259行:执行createExecFifo(),创建/run/runc/mycontainer/exec.fifo的命名管道。fifo特点是读写两端不同时存在时,读写端都会堵塞。runc 以此来实现暂停效果。
263行调用start()方法。
360 func(c *linuxContainer)start(process *Process) error {
361 parent, err := c.newParentProcess(process)
365 parent.forwardChildLogs()
366 if err := parent.start(); err != nil {
367 return newSystemErrorWithCause(err, "...")
368 }
369
370 if process.Init {
371 if c.config.Hooks != nil {
372 s, err := c.currentOCIState()
377 c.config.Hooks[configs.Poststart].RunHooks(s)
383 }
384 }
385 return nil
386 }361 : 创建一个parentProcess,然后执行start()。
371 : 如果bundle下的config.json中配置了hooks, 则执行poststart这个hook点挂载的处理函数。
457 func(c *linuxContainer)newParentProcess(p *Process)(parentProcess, error) {
458 parentInitPipe, childInitPipe, err := utils.NewSockPair("init")
462 messageSockPair := filePair{parentInitPipe, childInitPipe}
463
464 parentLogPipe, childLogPipe, err := os.Pipe()
468 logFilePair := filePair{parentLogPipe, childLogPipe}
469
470 cmd := c.commandTemplate(p, childInitPipe, childLogPipe)
471 if !p.Init {
472 return c.newSetnsProcess(p, cmd, messageSockPair, logFilePair)
473 }
480 if err := c.includeExecFifo(cmd); err != nil {
482 }
483 return c.newInitProcess(p, cmd, messageSockPair, logFilePair)
484 }458 : 创建一个unix sockpair(全双工): parentInitPipe留在当前进程, childInitPipe被子进程继承。父子进程的数据交换主要通过这对套接字来完成。
464 : 创建匿名pipe(半双工)。父进程通过匿名pipe来接收子进程日志: 所以将write一端(childLogPipe)封装到cmd中,继承到子进程中。
480 : 将之前创建的exec.fifo也继承到子进程中。
此时p.Init为true,create阶段执行的是newInitProcess;如果是runc run命令,则执行的是newSetnsProcess。
470行的commandTemplate()定义:
486 func commandTemplate(p *Process, childInitPipe *os.File, childLogPipe *os.File) *exec.Cmd {
487 cmd := exec.Command(c.initPath, c.initArgs[1:]...)
488 cmd.Args[0] = c.initArgs[0]
489 cmd.Stdin = p.Stdin
490 cmd.Stdout = p.Stdout
491 cmd.Stderr = p.Stderr
492 cmd.Dir = c.config.Rootfs
493 if cmd.SysProcAttr == nil {
494 cmd.SysProcAttr = &unix.SysProcAttr{}
495 }
496 cmd.Env = append(cmd.Env, "GOMAXPROCS="+os.Getenv("GOMAXPROCS"))
497 cmd.ExtraFiles = append(cmd.ExtraFiles, p.ExtraFiles...)
498 if p.ConsoleSocket != nil {
499 cmd.ExtraFiles = append(cmd.ExtraFiles, p.ConsoleSocket)
500 cmd.Env = append(cmd.Env,
501 "_LIBCONTAINER_CONSOLE="+strconv.Itoa(stdioFdCount+len(cmd.ExtraFiles)-1),
502 )
503 }
504 cmd.ExtraFiles = append(cmd.ExtraFiles, childInitPipe)
505 cmd.Env = append(cmd.Env,
506 "_LIBCONTAINER_INITPIPE="+strconv.Itoa(stdioFdCount+len(cmd.ExtraFiles)-1),
507 "_LIBCONTAINER_STATEDIR="+c.root,
508 )
509
510 cmd.ExtraFiles = append(cmd.ExtraFiles, childLogPipe)
511 cmd.Env = append(cmd.Env,
512 "_LIBCONTAINER_LOGPIPE="+strconv.Itoa(stdioFdCount+len(cmd.ExtraFiles)-1),
513 "_LIBCONTAINER_LOGLEVEL="+p.LogLevel,
514 )
519 if c.config.ParentDeathSignal > 0 {
520 cmd.SysProcAttr.Pdeathsig = unix.Signal(c.config.ParentDeathSignal)
521 }
522 return cmd
523 }commandTemplate()创建了一个构建子进程对象: 执行的命令就是之前提到的/proc/self/exec,参数是 init。也即: runc init。
通过cmd.Env向子进程设置环境变量
添加到cmd.ExtraFiles[]中的文件描述符将被子进程继承。继承的文件描述符的具体作用通过环境变量来约定。
525 func(c *linuxContainer)newInitProcess(p *Process, cmd *exec.Cmd) (*initProcess, error) {
526 cmd.Env = append(cmd.Env, "_LIBCONTAINER_INITTYPE="+string(initStandard))
527 nsMaps := make(map[configs.NamespaceType]string)
528 for _, ns := range c.config.Namespaces {
529 if ns.Path != "" {
530 nsMaps[ns.Type] = ns.Path
531 }
532 }
533 _, sharePidns := nsMaps[configs.NEWPID]
534 data, err := c.bootstrapData(c.config.Namespaces.CloneFlags(), nsMaps)
535 if err != nil {
536 return nil, err
537 }
538 init := &initProcess{
539 cmd: cmd,
540 messageSockPair: messageSockPair,
541 logFilePair: logFilePair,
542 manager: c.cgroupManager,
543 intelRdtManager: c.intelRdtManager,
544 config: c.newInitConfig(p),
545 container: c,
546 process: p,
547 bootstrapData: data,
548 sharePidns: sharePidns,
549 }
550 c.initProcess = init
551 return init, nil
552 }526 : 设置环境变量_LIBCONTAINER_INITTYPE=standard,该变量在 runc init 被用到。
527~532: 根据config.json中namespaces配置,生成一个namespace为key,path为value的map。这个namespace的map在构造bootstrapdata时,会判断每个namespace是否配置了path,如果配置了,则之后不再创建新的namespace,而是将这种类型的namespace join 到这个path下。
533: 如果配置了PID namespace path,那么设置一个标记,标志着当后续处理流程中如果有错误,应该杀掉相关进程。
534行的bootstrapData()函数定义。函数有截取:
1991 func(c *linuxContainer)bootstrapData(cloneFlags uintptr, nsMaps ...) (io.Reader, error) {
1992 // 创建 netlink message
1993 r := nl.NewNetlinkRequest(int(InitMsg), 0)
1994
1995 // 放入 cloneflags
1996 r.AddData(&Int32msg{
1997 Type: CloneFlagsAttr,
1998 Value: uint32(cloneFlags),
1999 })
2000
2001 // 如果namespaces配置了path,则封装到消息体中
2002 if len(nsMaps) > 0 {
2003 nsPaths, err := c.orderNamespacePaths(nsMaps)
2004 if err != nil {
2005 return nil, err
2006 }
2007 r.AddData(&Bytemsg{
2008 Type: NsPathsAttr,
2009 Value: []byte(strings.Join(nsPaths, ",")),
2010 })
2011 }
2072
2073 return bytes.NewReader(r.Serialize()), nil
2074 }bootstrapData: 构造出 run init 阶段需要用到的启动参数。包括clone(2)的clone flag,uid/gid映射, oom阈值,rootless相关的设置等等。这些配置都通过netlink消息格式封装。然后通过之前的那对unix socketpair将其发送给子进程。
我们梳理一下前面几个函数设置的环境变量及打开的几个文件描述符:
环境变量 |
文件描述符 |
作用 |
GOMAXPROCS |
- |
Go runtime中影响processor数量的环境变量 |
_LIBCONTAINER_CONSOLE |
Terminal socket |
config.json中Terminal设置为false,这里子进程没有此值 |
_LIBCONTAINER_INITPIPE |
unix socketpair一端 |
父子进程进程间通信主要方式 |
_LIBCONTAINER_STATEDIR |
- |
runc执行的工作目录,跟容器id相关。默认为/run/runc/<container_id> |
_LIBCONTAINER_LOGPIPE |
pipe写端 |
子进程向父进程输出日志 |
_LIBCONTAINER_LOGLEVEL |
日志级别 |
|
_LIBCONTAINER_FIFOFD |
exec.fifo |
如果是runc create启动,在runc init执行后半段,exec entrypoint之前,进程会堵塞住,等待runc start唤醒。runc 用来实现暂停效果,也比较有意思。 |
_LIBCONTAINER_INITTYPE |
- |
值为standard或setns。如果为standard,则从_LIBCONTAINER_FIFOFD环境变量中获取到exec.fifo文件描述符,向这个描述符中写入一个"0"的字符串 |
接下来,执行流程回到libcontainer/container_linux.go:366,开始执行parent.start():
360 func(c *linuxContainer)start(process *Process) error {
361 parent, err := c.newParentProcess(process)
362 if err != nil {
363 return newSystemErrorWithCause(err)
364 }
365 parent.forwardChildLogs()
366 if err := parent.start(); err != nil {
367 return newSystemErrorWithCause(err)
368 }
385 return nil
386 }从start()开始,runc开始执行最开始提到的 runc init。
311 func(p *initProcess)start() (retErr error) {
312 defer p.messageSockPair.parent.Close()
313 err := p.cmd.Start() // 开始执行 runc init
314 p.process.ops = p
335
// 向 runc init 子进程发送 bootstrap 数据
347 if _, err := io.Copy(p.messageSockPair.parent, p.bootstrapData); err != nil {
348 return newSystemErrorWithCause(err)
349 }
350 childPid, err := p.getChildPid() // 从sockpair中获取子进程发送的子进程id
351 if err != nil {
352 return newSystemErrorWithCause(err, "...")
353 }
358 fds, err := getPipeFds(childPid) // 读取/proc/<pid>/fd中子进程的文件描述符
359 if err != nil {
360 return newSystemErrorWithCausef(...)
361 }
362 p.setExternalDescriptors(fds)
363
364 // 如果`config.json`中包含 NEWCGROUP 配置,则向子进程sockpaire中写入一个int数据"0x80"。子进程收到后创建 NEWCGROUP namespace
365 if p.config.Config.Namespaces.Contains(configs.NEWCGROUP) && p.config.Config.Namespaces.PathOf(configs.NEWCGROUP) == "" {
366 if _, err := p.messageSockPair.parent.Write([]byte{createCgroupns}); err != nil {
367 return newSystemErrorWithCause(err)
368 }
369 }
370
371 // 等待第一个子进程退出
372 if err := p.waitForChildExit(childPid); err != nil {
373 return newSystemErrorWithCause(err)
374 }
375 // 开始创建网卡。这里只是将loopback设置为up.
376 if err := p.createNetworkInterfaces(); err != nil {
377 return newSystemErrorWithCause(err, "creating network interfaces")
378 }
379 if err := p.updateSpecState(); err != nil { // 更新当前状态到 state.json中
380 return newSystemErrorWithCause(err)
381 }
382 if err := p.sendConfig(); err != nil { // 向 runc init 子进程发送配置。
383 return newSystemErrorWithCause(err)
384 }
389 // 等待子进程发送的同步数据。
390 ierr := parseSync(p.messageSockPair.parent, func(sync *syncT) error {
391 switch sync.Type {
392 case procReady:
393 /* ... */
454 sentRun = true
455 case procHooks:
456 /* ... */
486 sentResume = true
487 default:
488 return newSystemError(errors.New("..."))
489 }
490
491 return nil
492 })
493
500 if err := unix.Shutdown(int(p.messageSockPair.parent.Fd()), unix.SHUT_WR); err != nil {
501 return newSystemErrorWithCause(err)
502 }
503
504 // Must be done after Shutdown so the child will exit and we can wait for it.
505 if ierr != nil {
506 p.wait()
507 return ierr
508 }
509 return nil
510 }313行一旦开始执行,子进程开始启动,runc init 初期主要处理实际上是在nsexec()函数中完成的。
347: 向子进程发送bootstrap数据。
350: 父进程读取子进程发送的进程id数据。
365 ~ 369 : 如果config.json中的namespace配置中配置了NEWCGROUP,则向子进程再额外发送一个值为0x80的一个字节,通知子进程隔离 CGroup namespace。
372:等待子进程退出。
376:这里将默认的lo网卡设置为up。
379:更新容器的状态到state.json文件中。
382:向子进程发送配置。注意,这里的子进程并非由313行start()直接创建的子进程,这个进程在372行时已经表示退出了。接收配置的进程实际上是start()子进程创建的子进程。
390~492:等待子进程发送的同步状态,再由同步的状态或执行state.json的状态更新,或执行相应的hooks调用。
下图是start()函数与其他函数之间的通信关系。这张图涉及后续的内容介绍,读者可在后文中回过头来看具体处理关系。
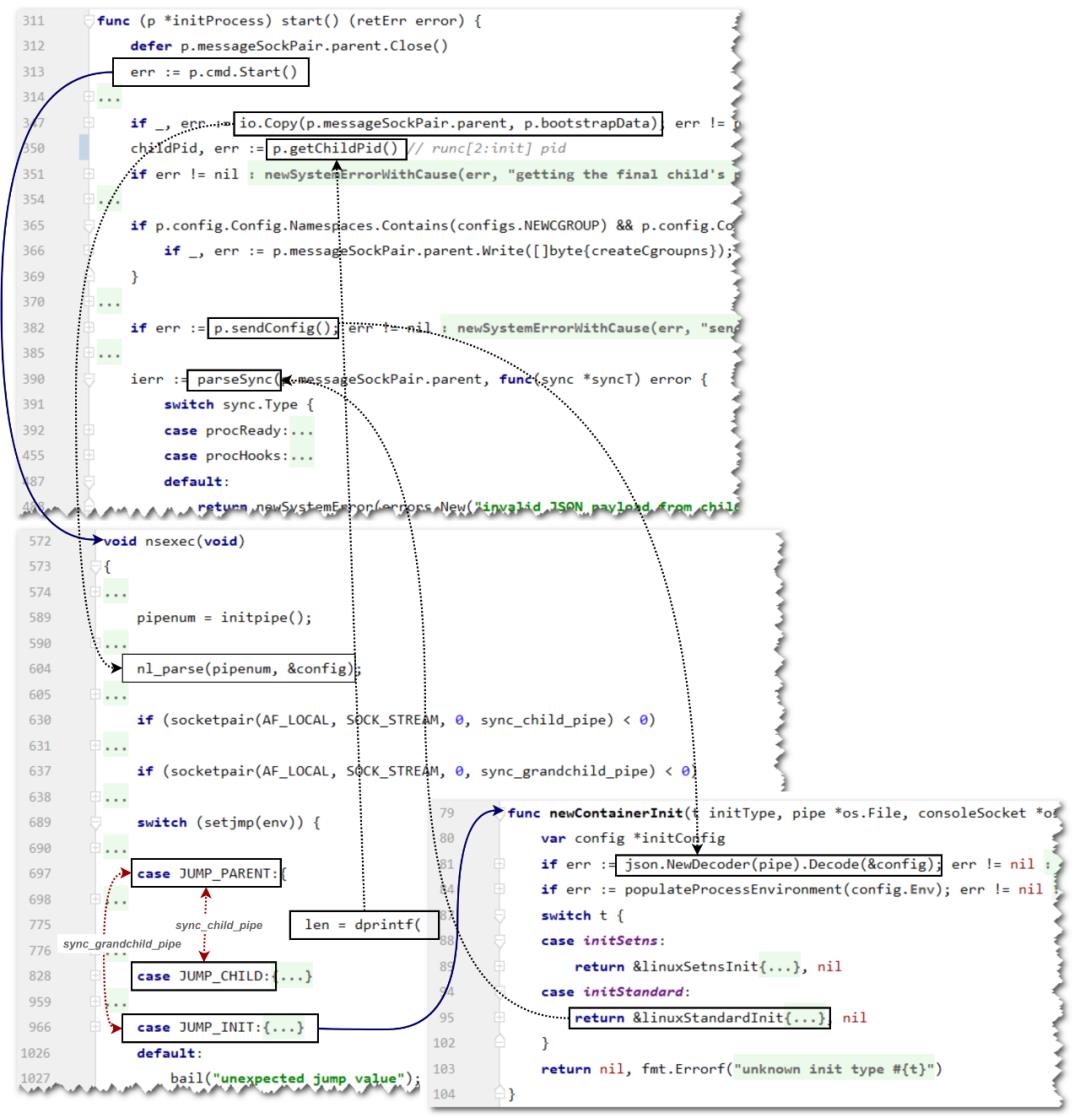
说明:
p.cmd.Start()执行后,会创建新进程调用nsexec()。
nsexec()从JUMP_INIT分支return后,C函数部分执行完成,程序会执行到go部分的newContainerInit()。这部分在后文有详细介绍。
黑色虚线部分是数据发送和接收。例如: io.Copy()将p.bootstrapData发送,被nsexec()中nl_parse()接收处理。
红色虚线是PARENT和CHILD,PARENT和INIT进程间通信。具体后文有介绍。
runc init
接下来开始本文的第二部分,这部分也是runc中最hack的一部分。
nsexec
每次执行runc时,实际上都会隐含的执行一段C代码。
package main
import _ "github.com/opencontainers/runc/libcontainer/nsenter"这是因为在main包中的init.go中,会导入nsenter的包。
在 libcontainer/nsenter/nsenter.go 中,利用cgo,调用了nsexec()函数
1 // +build linux,!gccgo
2
3 package nsenter
4
5 /*
6 #cgo CFLAGS: -Wall
7 extern void nsexec();
8 void __attribute__((constructor)) init(void) {
9 nsexec();
10 }
11 */
12 import "C"而这段cgo利用了gcc的constructor特性,使得这段C代码先于go的runtime启动之前执行。这所以这样隐蔽的来处理,其实也是无奈之举:因为go语言天然的多线程特性导致在调用linux某些系统调用时(例如:setns),会导致错误。
详情请参考:
https://gcc.gnu.org/onlinedocs/gcc-10.2.0/gcc/Common-Function-Attributes.html
https://github.com/opencontainers/runc/blob/master/libcontainer/nsenter/README.md
https://github.com/golang/go/issues/8676
在分析nsexec()函数之前,首先介绍一下跟namespace相关的三个函数:
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg)创建一个子进程。它的使用方式跟pthread_create()有点类似,但fn是工作在子进程当中。child_statck是子进程的栈;flag控制子进程的命名空间;arg是fn的参数。
int setns(int fd, int nstype)将调用进程加入以nstype方式加入到与fd关联的命名空间中。fd是与/proc/<pid>/ns/相关的打开的文件描述符。
int unshare(int flags)将调用进程或者线程脱离当前所在的namespace,并加入一个或多个新的namespace。由flags指定的namespaces会自动创建。
以上三个函数都与 namespaces相关。
三个函数需要包含头文件并定义一下 _GNU_SOURCE 宏。
三个函数当中的flags或nstype指 CLONE_NEW* 常量组合:
| 常量 | 解释 |
| CLONE_NEWCGROUP | 隔离 Cgroup 根目录 (4.6之后新增) |
| CLONE_NEWIPC | 隔离 system V IPC, POSIX message queues |
| CLONE_NEWNET | 每个命名空间可有自己独有的网络设备,端口,协议栈 |
| CLONE_NEWNS | 拥有自己的根目录 |
| CLONE_NEWPID | 拥有自己的进程id |
| CLONE_USERS | 拥有自己独有的用户/用户组ID |
| CLONE_NEWUTS | 拥有自己的主机标识 |
接下来,从nsexec.c文件中的nsexec()函数开始分析:
nsexec()一开始会调用initpipe()函数:
static int initpipe(void)
{
int pipenum;
char *initpipe, *endptr;
initpipe = getenv("_LIBCONTAINER_INITPIPE");
if (initpipe == NULL || initpipe == '�')
return -1;
pipenum = strtol(initpipe, &endptr, 10);
if (endptr != '�')
bail("unable to parse _LIBCONTAINER_INITPIPE");
return pipenum;
}之前说过,在 runc create 中留下的文件文件描述符就是通过一系列环境变量的方式告知子进程该通过何种方式来对待相应的文件描述符。在initpipe之前的setup_logpipe()使用同样的方法从_LIBCONTAINER_LOGPIPE环境变量取出发送日志的文件描述符。
为了调试方便,笔者在 libcontainer/nsenter/nsexec.c 中加入两个打印函数,这样在gdb不设置follow-fork-mode时,在父进程调试可以观察到父子进程的通信:
static void print_env() {
extern char **environ;
int idx = 0;
char *env = *environ;
for(; env; idx++) {
printf(">>> env: %s
", env);
env = *(environ + idx);
}
}
static void print_recv_data(char data, int size, char msg) {
if(msg != NULL) {
printf("%s
", msg);
}
int i = 0;
for(; i>> recv payload data from socketpair:");
/* Parse the netlink payload. */
config->data = data;
// …
}在正式介绍nsexec()之前,这里还需要介绍一对函数:
int setjmp(jmp_buf env);
void longjmp(jmp_buf env, int val);这两个函数可以实现控制流的非局部goto。在C语言中,goto语句只能在控制流所在的当前函数内跳转到不同标签中。而这对函数可以实现跨函数跳转。
具体原理是这样的 :
setjmp(jmp_buf env)在其调用点设置一个jmp_buf,也即当前的栈。保存了当前调用点的上下文信息:比如栈指针,PC指针和一些必要的寄存器值。这需要在某个时间点需要恢复当前的调用环境,重新开始执行。并且,初次调用setjmp()返回为0。
longjmp(jmp_buf env, int val)函数的env参数与setjmp()的env参数相同。调用longjmp()时,从env保存的信息中恢复,就好像setjmp()再次返回一样,但此时的返回值变成了longjmp()的第二个参数值。
这对函数常见的使用场景是: 深度嵌套的调用中遇到异常时,返回到最外层处理,实现异常处理;实现用户态协程。
runc使用这两个函数和clone()配合实现了一个状态机。
struct clone_t {
char stack[4096] attribute ((aligned(16))); // 设置一个4k大小的栈
char stack_ptr[0]; // 柔性数组。stack_ptr是数组的结束边界。其实是栈顶:栈增长方向相反
jmp_buf *env; // longjmp, setjmp 第一个参数
int jmpval; // longjump 第二个参数
};
static int child_func(void *arg)
{
struct clone_t *ca = (struct clone_t *)arg;
longjmp(*ca->env, ca->jmpval); // clone出的进程立即跳转到setjmp处,setjmp返回值为jmpval
}
static int clone_parent(jmp_buf *env, int jmpval)
{
struct clone_t ca = {
.env = env,
.jmpval = jmpval,
};
// 子进程开始clone。CLONE_PARENT表示clone出的子进程与自身的ppid相同。
return clone(child_func, ca.stack_ptr, CLONE_PARENT
SIGCHLD, &ca);
}runc实现的简化版的进程状态机:
clone_with_longjmp(int val);void nsexec(){
jump_buf env;
switch(setjump(env)){
case 0:
clone_with_longjmp(STATUS1); // clone出子进程,并且执行STATUS1
break;
case STATUS1:
clone_with_longjmp(STATUS2); // clone出子进程,并且执行STATUS2
break;
case STATUS2:
break;
}
}
铺垫完毕,看下nsexec():
void nsexec(void)
{
// 在开始处打印环境变量
print_env();
// 从 _LIBCONTAINER_LOGPIPE 环境变量中取出日志的文件描述符
setup_logpipe();
// 从 _LIBCONTAINER_INITPIPE 环境变量中读取主要通信的文件描述符
pipenum = initpipe();
if (pipenum == -1)
return;
/*通过将runc重新挂载,载入到只读的内存当中,
* 避免 /proc/self/exe 被篡改导致的 CVE-2019-5736 漏洞 */
if (ensure_cloned_binary() < 0)
bail("could not ensure we are a cloned binary");
/* 从pipenum中读取配置,解析到 config中 */
nl_parse(pipenum, &config);
/* 根据配置的oom_score_adj值调整OOM socre。说白了就是调整QOS*/
update_oom_score_adj(config.oom_score_adj, config.oom_score_adj_len);
/* 关闭进程core dump。避免在某些条件下触发异常 */
if (config.namespaces) {
if (prctl(PR_SET_DUMPABLE, 0, 0, 0, 0) < 0)
bail("failed to set process as non-dumpable");
}
/* 创建与child通信的sockpair */
if (socketpair(AF_LOCAL, SOCK_STREAM, 0, sync_child_pipe) < 0)
bail("failed to setup sync pipe between parent and child");
/* 创建与grand child进程通信的sockpair */
if (socketpair(AF_LOCAL, SOCK_STREAM, 0, sync_grandchild_pipe) < 0)
bail("failed to setup sync pipe between parent and grandchild");
/* 这里作者详细写了为什么要clone()两次的心路历程。
* https://github.com/opencontainers/runc/blob/master/libcontainer/nsenter/nsexec.c#L643
*/
switch (setjmp(env)) {
case JUMP_PARENT:{
/* 设置进程名称为runc:[0:PARENT] */
prctl(PR_SET_NAME, (unsigned long)"runc:[0:PARENT]", 0, 0, 0);
/* 创建子进程,子进程进入JUMP_CHILD分支处理 */
child = clone_parent(&env, JUMP_CHILD);
while (!ready) {
switch (s) {
case SYNC_USERMAP_PLS: /* 设置uid-map 和 gid-map */
case SYNC_RECVPID_PLS: /* 向create进程发送child pid 和 grand child pid */
case SYNC_CHILD_READY: /* 子进程就绪结束循环 */
}
}
/* 与 grandchild 通信。如果是grandchild已经就绪则结束循环 */
syncfd = sync_grandchild_pipe[1];
ready = false;
while (!ready) {
switch (s) {
case SYNC_CHILD_READY:
ready = true;
break;
}
}
exit(0); // runc[0:PARENT] 完成使命,进程退出
}
case JUMP_CHILD:{
prctl(PR_SET_NAME, (unsigned long)"runc:[1:CHILD]", 0, 0, 0);
/* 如果config.json中namespace配置了path,则这里需要将其加入到
* path指定的namesapce中。k8s的多容器的pod会调用到此处*/
if (config.namespaces)
join_namespaces(config.namespaces);
/* 如果config.json中设置了 user,则创建user namespace */
if (config.cloneflags & CLONE_NEWUSER) {
if (unshare(CLONE_NEWUSER) < 0)
bail("failed to unshare user namespace");
config.cloneflags &= ~CLONE_NEWUSER;
/* 向父进程发送创建用户映射申请 */
s = SYNC_USERMAP_PLS;
if (write(syncfd, &s, sizeof(s)) != sizeof(s))
bail("failed to sync with parent: write(SYNC_USERMAP_PLS)");
/* 成为namespace的root用户 */
if (setresuid(0, 0, 0) < 0)
bail("failed to become root in user namespace");
}
// 创建除CGruop之外其他的namespace
if (unshare(config.cloneflags & ~CLONE_NEWCGROUP) < 0)
bail("failed to unshare namespaces");
// 创建子进程,创建出的子进程执行 JUMP_INIT分支逻辑
child = clone_parent(&env, JUMP_INIT);
/* 向父进程发送自己和child pid */
s = SYNC_RECVPID_PLS;
if (write(syncfd, &s, sizeof(s)) != sizeof(s)) {
kill(child, SIGKILL);
bail("failed to sync with parent: write(SYNC_RECVPID_PLS)");
}
/* 等待父进程的ACK */
if (read(syncfd, &s, sizeof(s)) != sizeof(s)) {
kill(child, SIGKILL);
bail("failed to sync with parent: read(SYNC_RECVPID_ACK)");
}
if (s != SYNC_RECVPID_ACK) {
kill(child, SIGKILL);
bail("failed to sync with parent: SYNC_RECVPID_ACK: got %u", s);
}
/* 告诉父进程自己的工作已经完成 */
s = SYNC_CHILD_READY;
if (write(syncfd, &s, sizeof(s)) != sizeof(s)) {
kill(child, SIGKILL);
bail("failed to sync with parent: write(SYNC_CHILD_READY)");
}
/* 进程结束 */
exit(0);
}
case JUMP_INIT:{
syncfd = sync_grandchild_pipe[0];
prctl(PR_SET_NAME, (unsigned long)"runc:[2:INIT]", 0, 0, 0);
if (read(syncfd, &s, sizeof(s)) != sizeof(s))
bail("failed to sync with parent: read(SYNC_GRANDCHILD)");
if (s != SYNC_GRANDCHILD)
bail("failed to sync with parent: SYNC_GRANDCHILD: got %u", s);
// 设置CGroup namespace,从pipe中读取一个字节值为0x80
if (config.cloneflags & CLONE_NEWCGROUP) {
uint8_t value;
if (read(pipenum, &value, sizeof(value)) != sizeof(value))
bail("read synchronisation value failed");
if (value == CREATECGROUPNS) {
if (unshare(CLONE_NEWCGROUP) < 0)
bail("failed to unshare cgroup namespace");
} else
bail("received unknown synchronisation value");
}
/* 通知 runc[0:PARENT] 自己就绪,runc[0:PARENT]进程退出 */
s = SYNC_CHILD_READY;
if (write(syncfd, &s, sizeof(s)) != sizeof(s))
bail("failed to sync with patent: write(SYNC_CHILD_READY)");
/* 一切ok,nsexec()返回,开始进入 go runtime 的后续处理 */
return;
}
default:
bail("unexpected jump value");
}
}为了更清楚地理解目前几个进程之间的关系,按照进程出现的先后顺序,暂且将几个进程称为:
runc:CREATE -> runc:[0:PARENT] -> runc:[1:CHILD] -> runc:[2:INIT]。
其中,runc:[0:PARENT] clone时指定了CLONE_PARENT,后面三个进程在进程父子视图上并不是 父子关系,而是 兄弟关系。如下图所示:
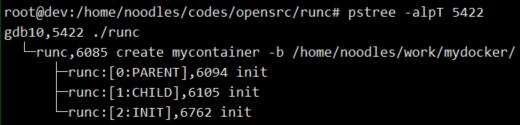
笔者以为作者这样处理的原因有两点:一次性的clone无法安全的构造出所有的namespaces,所以这里干脆一个namespaces选项也不带;第二点是过深的父子间调用关系会对进程资源回收造成麻烦。
runc create调用runc init时,打印出的环境变量如下:
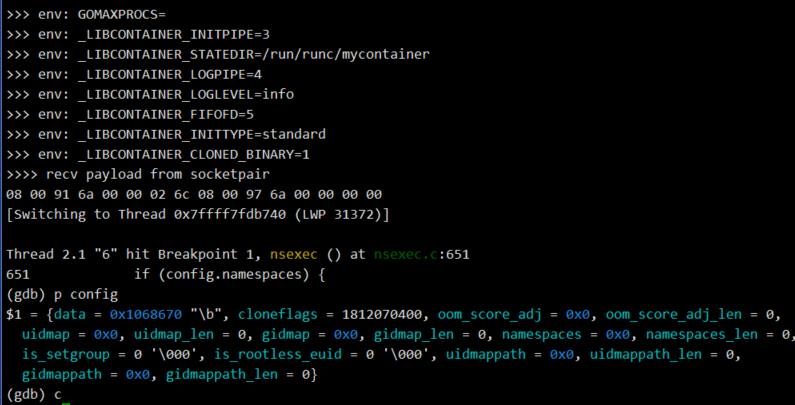
nl_parse(pipenum, &config)解析create进程发送的bootstrapData,解析后的cloneflags为1812070400,这个值正是config.json中的namespaces配置:
CLONE_NEWPID | CLONE_NEWNET | CLONE_NEWIPC | CLONE_NEWUTS | CLONE_NEWNS为了更好的理解nsexec(),笔者通过一张图将各个进程的关键点标出:
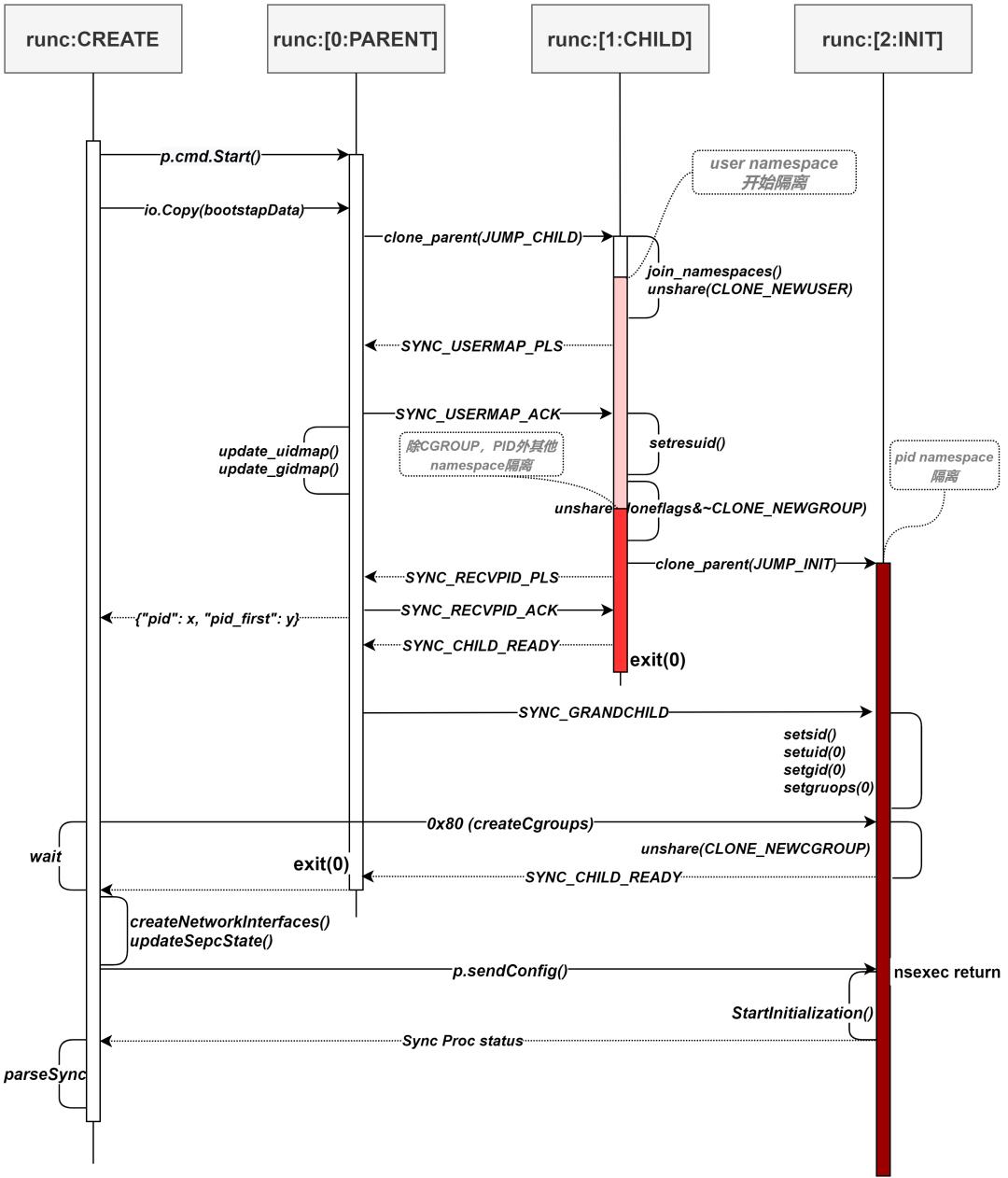
runc中实现切换新的namespace都是使用unshare()。
namespace切换发生在runc:[1:CHILD]。CLONE_NEWUSER首先需要单独做一次unshare()。CLONE_NEWUSER不能与CLONE_PARENT同时指定。具体细节读者可见:man 2 clone
runc:[1:CHILD]执行完unshare(cloneflags&~CLONE_NEWGROUP),主要的namespaces已经改变了,但CLONE_NEWPID这个namespace并未发生切换,需要再次clone()。
一旦clone_parent(JUMP_INIT)开始执行,runc:[2:INIT]进程产生,pid namespae切换。runc:[1:CHILD]进程一只脚在容器内,一只脚在容器外;而runc:[2:INIT]是完全进入到容器的进程。
runc:[1:CHILD],runc:[0:PARENT] 相继退出,runc:[2:INIT]中执行完nsexec()函数后,后续流程开始进入runc init剩下的go runtime部分。
执行JUMP_CHILD分支的unshare()之前:查看/proc/<pid>/ns目录下当前进程的namespaces信息:
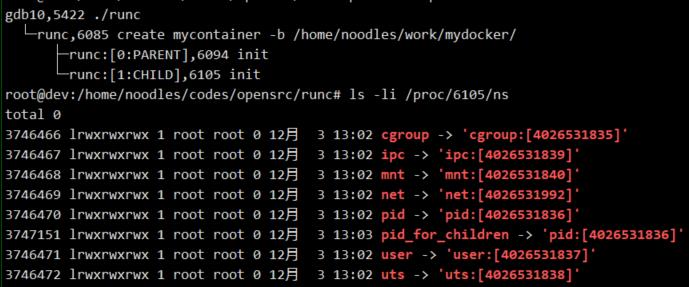
执行unshare()之后:
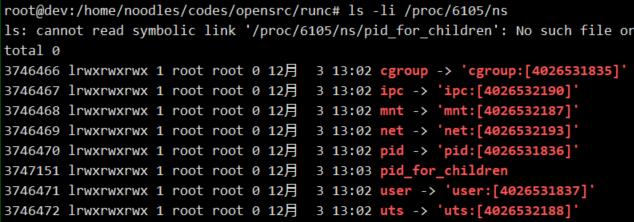
可以看到同一个进程在执行unshare()前后,进程的namespace已经发生改变。
另外,pstree -S也可以观察到namespaces的变换:如果发生改变,则在相应的进程上显示上有体现:

如上图: 一旦clone出runc:[2:INIT]进程,就会切换 PID namespace。
补充一下:
linux将不同种类的namespaces用不同的inode号来标识,这个inode号存储在一个叫做nsfs的特殊文件系统中,这个特殊的文件对用户不可见。在/proc/<pid>/ns目录下,将进程相关的namespace以软连接<ntype>:[inode]方式供上层使用。也就是说,这个inode是namespaces的ID。Linux之所以这样处理,是保证只要namespaces的软连接被打开,这个namespaces就存在,方便多个进程之间共享某个或多个namespaces。
在前文nsexec()函数分析中提到过,如果config.json中的namespace配置了"path",则就表明容器可以通过这个path进行join的。这在某些方面会比较有用,比如: k8s会使用join_namespace()来将多个container构建出所谓的Pod。它的原理是这样的:
k8s首先会创建一个Pause容器,这个容器除了处理一下信号之外,就像它的名字一样,暂停住。它的作用是"占位",等待其它容器加入它组成一个pod。
以一个实际例子来验证:
以下是笔者在k8s节点上截取的config.json。图中,network和ipc两个namespace配置了"path"。正因为network这个namespace在一个pod中是共享的,所以,我们可以使用这个特性,在pod中启动一个envoy的sidecar,这样应用容器的流量可以很方便的交给envoy来代理。

同属于一个pod的两个进程id为2719和2554。如下图,可以看到这两个进程中的ipc和net这两个namespace id是一样的。
StartInitialization
nsexec()函数调用完成后,将继续执行go部分后续流程,调用到libcontainer/factory_linux.go中的StartInitialization()方法:
333 func (l *LinuxFactory) StartInitialization() (err error) {
334 // 根据环境变量取出 sockepair pipe, fifo等描述符
365 // 清除环境变量,给用户命令环境一个干净的环境
366 os.Clearenv()
367
368 defer func() {
370 // 如果出错则将错误信息通知 runc create 进程
371 utils.WriteJSON(pipe, syncT{procError})
379 }()
385 // 读取并解析 runc create 通过sendConfig()传送的配置数据
386 i, err := newContainerInit(it, pipe, consoleSocket, fifofd)
391 // 此处调用的是 linuxStandardInit 的 Init()
392 return i.Init()
393 }/libcontainer/standard_init_linux.go
46 func (l *linuxStandardInit) Init() error {
47 runtime.LockOSThread()
48 defer runtime.UnlockOSThread()
78 // 设置网卡up
79 if err := setupNetwork(l.config); err != nil {
80 return err
81 } // 通过netlink添加路由
82 if err := setupRoute(l.config.Config); err != nil {
83 return err
84 }
103 // 根据config.json配置做相应的挂载,如果是只读,则mount之后再此作RO挂载
104 if l.config.Config.Namespaces.Contains(configs.NEWNS) {
105 if err := finalizeRootfs(l.config.Config); err != nil {
106 return err
107 }
108 }
143 /*** 省略 ***/
145 // 通知 runc create 已经准备好,开始执行execv了
146 if err := syncParentReady(l.pipe); err != nil {
147 return errors.Wrap(err, "sync ready")
148 }
182 // 关闭与create进程之间的pipe。create进程退出
183 l.pipe.Close()
184
187 // 打开fifo。此时当前进程堵塞,等待后续打开exec.fifo。
188 fd, err := unix.Open("/proc/self/fd/"+strconv.Itoa(l.fifoFd), unix.O_WRONLY|unix.O_CLOEXEC, 0)
189 if err != nil {
190 return newSystemErrorWithCause(err)
191 } // 其他进程打开后,向fifo中写入一个'0'
192 if _, err := unix.Write(fd, []byte("0")); err != nil {
193 return newSystemErrorWithCause(err)
194 }
201 unix.Close(l.fifoFd)
210
211 s := l.config.SpecState
212 s.Pid = unix.Getpid()
213 s.Status = specs.StateCreated // 当前容器状态为created
214 // 执行startContainer hook点钩子
214 l.config.Config.Hooks[configs.StartContainer].RunHooks(s)
216
217 // 执行 用户的entrypoint
218 if err := unix.Exec(name, l.config.Args[0:], os.Environ()); err != nil {
219 return newSystemErrorWithCause(err, "exec user process")
220 }
221 return nil
222 }说明:
183行: 关闭pipe,父进程就开始退出,此时runc:[2:INIT]进程被init进程接管。
188行: 打开fifo就开始堵塞,堵塞并非发生在write时。
218行: 此时唯一的runc被用户指定的entrypoint替换。
runc start <container-id>
这个子命令比较简单。它需要一个container-id作为参数。
Action: func(context *cli.Context) error {
// 根据container-id从/run/runc/<container-id>目录加载state.json获取容器信息
container, err := getContainer(context)
status, err := container.Status()
switch status {
case libcontainer.Created:
// 如果容器状态为CREATED,执行Exec()
if err := container.Exec(); err != nil {
return err
}
return nil
case libcontainer.Stopped:
return errors.New("...")
case libcontainer.Running:
return errors.New("...")
default:
return fmt.Errorf("...", status)
}
}然后调用到linuxContainer.exec():
func (c *linuxContainer) exec() error {
path := filepath.Join(c.root, execFifoFilename)
// state.json中有记录创建容器的进程id,也即 runc init的pid
pid := c.initProcess.pid()
// 打开 /run/runc/<container-id>/exec.fifo
// runc init 开始向下执行,最终容器中跑的就是我们的entrypoint了
blockingFifoOpenCh := awaitFifoOpen(path)
for {
select {
case result := <-blockingFifoOpenCh:
// 在handleFifoResult中调用 readFromExecFifo 读取fifo中的数据
return handleFifoResult(result)
// 兜底,防止过程中出现僵尸进程。
case <-time.After(time.Millisecond * 100):
stat, err := system.Stat(pid)
if err != nil || stat.State == system.Zombie {
if err := handleFifoResult(fifoOpen(path, false)); err != nil {
return errors.New("already dead")
}
return nil
}
}
}
}至此,唯一的runc进程被用户的entrypoint替换。可谓是: "事了拂衣去,深藏功与名"。
runc run <container-id>
这种方式实际是最常见的方式。它的过程其实就是 runc create + runc start 。中间不会创建exec.fifo,少了堵塞,一步到位。
总结
如果读者想要深入的学习docker或者k8s,则runc是一个很好的切入点:自下而上的路线可以更好的理解docker其他组件,包括k8s的某些实现目。回过头来看runc的容器化实现,其实背后真正支撑的无非就是clone(), unshare(), setns()这三个函数。所谓的技术革命,多数时候并非是一个全新的事务,有时候,深刻理解几个函数,经过合理的组合其实就是创新。
容器究竟是什么?笔者觉得:容器其实就是有一些特殊属性的进程而已。
以上是关于runc源码分析的主要内容,如果未能解决你的问题,请参考以下文章