Etcd 源码分析:Raft 实现
Posted Go开发大全
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Etcd 源码分析:Raft 实现相关的知识,希望对你有一定的参考价值。
(给Go开发大全加星标)
来源:xxb249
https://blog.csdn.net/xxb249/article/details/80787501
【导读】本文介绍了Etcd存储之一致性协议raft实现源码分析。
集群中最核心内容是保证数据一致性,那么如何保证数据一致性?在业界有很多算法、协议,例如:Paxos,Raft。
Raft协议相比之前协议Paxos等,算是年轻协议,而且Raft协议比较简单,容易实现。
一、Raft基础
1.1 状态机
Raft简单就在于它的状态机。由上图可知,状态机状态非常少,分别Follower、Candidate、Leader。
Raft协议简要说明:
1)在稳定状态,整个集群只有一个Leader节点,其他都是Follower节点。
2)获取大部分支持票,表示支持票至少是集群节点数/2+1。
3)在相同任期Term下,每人只有一票,先发起投票的节点,先把票投给自己。
4)Raft为了保证选举成功概率,设置了一个选举定时器,选举定时器超时后则进入选举节点。由于每个节点定时器不一致,则提升选举的成功率。在极其特殊场景,才会出现定时器设置一样。当然这种概率也是可能的,但是我们可以人工干预(修改配置文件)。
1.2 Raft中相关消息
在Raft协议中只有三种Rpc(远程过程调用)消息:AppendEntry、RequestVote、InstallSnapshot。
AppendEntry RPC 消息
参数 |
描述 |
term |
领导人的任期号 |
leaderId |
领导人的 id,为了其他服务器能重定向到客户端 |
prevLogIndex |
前一个日志的索引值 |
prevLogTerm |
前一个日志的领导人任期号 |
entries[] |
将要存储的日志条目(表示 heartbeat 时为空,有时会为了效率发送超过一条) |
leaderCommit |
领导人提交的日志条目索引值 |
返回值 |
描述 |
term |
当前的任期号,用于领导人更新自己的任期号 |
success |
如果其它服务器包含能够匹配上 prevLogIndex 和 prevLogTerm 的日志时为真 |
注意:如果AppendEntry不包含任何Entry则表示此消息为心跳消息。
RequestVote RPC消息
参数 |
描述 |
term |
候选人的任期号 |
candidateId |
请求投票的候选人 id |
lastLogIndex |
候选人最新日志条目的索引值 |
lastLogTerm |
候选人最新日志条目对应的任期号 |
返回值 |
描述 |
term |
目前的任期号,用于候选人更新自己 |
voteGranted |
如果候选人收到选票为 true |
注意:
1)选举流程中有一个限制:如果当候选人candidate的所拥有最新日志index和最新日志的term要小于follower的最新日志index和最新日志的term,则投反对票。这么做的原因是:为了保证成为leader的节点,能够拥有全部的日志。换句话说就是leader不能比follower日志少。
2)对于第三种snapshot消息,在下一篇存储中介绍。
二、Etcd定时器
2.1 定时器
raft定义了两种定时器,如下表:
定时器种类 |
默认值 |
最大值 |
选举定时器 |
1000ms |
50000ms |
心跳定时器 |
100ms |
选举定时必须要大于5倍心跳定时,建议是10倍关系 |
2.2 定时器实现
上面介绍了,Raft协议中是以定时器作为基础,来进行选举。Etcd代码这部分代码精华所在:利用一个定时器的实现,管理两个定时器逻辑(定时器是操作系统一种资源)。定时器初始化,挂载raftNode结构中,具体如下:
func newRaftNode(cfg raftNodeConfig) *raftNode {
r := &raftNode{
raftNodeConfig: cfg,
// set up contention detectors for raft heartbeat message.
// expect to send a heartbeat within 2 heartbeat intervals.
td: contention.NewTimeoutDetector(2 * cfg.heartbeat),
readStateC: make(chan raft.ReadState, 1),
msgSnapC: make(chan raftpb.Message, maxInFlightMsgSnap),
applyc: make(chan apply),
stopped: make(chan struct{}),
done: make(chan struct{}),
}
if r.heartbeat == 0 {
r.ticker = &time.Ticker{}
} else {
r.ticker = time.NewTicker(r.heartbeat) //调用内置方创建定时器
}
return r
}
我们发现,NewTicker入参是r.heartbeat,而且只有一个定时器。那么它是怎么做到的呢?用一个定时器管理两个业务逻辑?
首先看一下,处理流程:
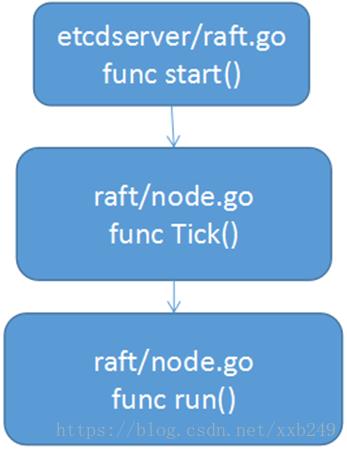
在start()接收到系统定时器超时消息,然后调用Tick方法,向channel中写入一个空数据结构,channel的另一端读取数据在,run方法中,如下:
case <-n.tickc:
r.tick() //回调函数 tickElection 触发选举 tickHeartbeat 触发发送心跳
此处的tick()定义在raft数据结构中,是一个回调函数:
/*
* 当前状态是Follower、Candidate、PreCandidate则tick取值为tickElection
* 当前状态是Leader则取值为tickHeartbeat
*/
tick func() /* 超时定时器callback 函数 */
在介绍tickHeartbeat和tickElection之前,在重新梳理一下时间配置参数:
数据结构 |
心跳时间取值 |
心跳默认值 |
选举时间取值 |
选举默认值 |
embed/config.go Config |
常量TickMs |
100ms |
常量ElectionMs |
1000ms |
etcdserver/config.go ServerConfig |
ServerConfig.TickMs取值为Config.TickMs |
100ms |
ServerConfig.ElectionTicks取值为Config.ElectionMs除以Config.TickMs |
10,此处表示逻辑时间,滴答。 |
raft/raft.go Config |
Config.HeartbeatTick |
1,此处表示逻辑时间,滴答。 |
Config.ElectionTick取值为ServerConfig.ElectionTicks |
10,此处表示逻辑时间,滴答。 |
raftNodeConfig |
raftNodeConfig.heartbeat取值为ServerConfig.TickMs |
默认值是100ms,此处为真正定时器时间 |
无 |
|
raft/raft.go raft |
raft.heartbeatTimeout取值为raft/raft.go Config.HeartbeatTick |
1,此处表示逻辑时间,滴答。 |
electionTimeout取值为raft/raft.go Config.ElectionTick |
10,此处表示逻辑时间,滴答。 |
下面来看一下,超时处理函数,tickHeartbeat和tickElection
// tickHeartbeat is run by leaders to send a MsgBeat after r.heartbeatTimeout.
func (r *raft) tickHeartbeat() {
// 逻辑时间滴答声,每次加1代表一次时间流逝
r.heartbeatElapsed++
r.electionElapsed++
if r.electionElapsed >= r.electionTimeout {//默认值10 如果大于10次则结束leader状态
r.electionElapsed = 0
if r.checkQuorum {
r.Step(pb.Message{From: r.id, Type: pb.MsgCheckQuorum})
}
// If current leader cannot transfer leadership in electionTimeout, it becomes leader again.
if r.state == StateLeader && r.leadTransferee != None {
r.abortLeaderTransfer()
}
}
// 只有leader才会发心跳消息
if r.state != StateLeader {
return
}
if r.heartbeatElapsed >= r.heartbeatTimeout {//发起心跳
r.heartbeatElapsed = 0 //重置
r.Step(pb.Message{From: r.id, Type: pb.MsgBeat})
}
}
// tickElection is run by followers and candidates after r.electionTimeout.
// 选举定时器超时后 触发选举 此方法一般由follower、candidate调用
func (r *raft) tickElection() {
r.electionElapsed++
if r.promotable() && r.pastElectionTimeout() {/* 比较是否超时,若是则发起选举 */
r.electionElapsed = 0
r.Step(pb.Message{From: r.id, Type: pb.MsgHup}) //触发选举 Term是0 在Step中会对Term的判断
}
}
// pastElectionTimeout returns true iff r.electionElapsed is greater
// than or equal to the randomized election timeout in
// [electiontimeout, 2 * electiontimeout - 1].
func (r *raft) pastElectionTimeout() bool {
return r.electionElapsed >= r.randomizedElectionTimeout
}
之前说过,raft是通过定时器来降低各个节点同时选举,但是我们在上面发现定时器时间都是一样,那么到底在哪里设置的随机时间呢?就是通过randomizedElectionTimeout。
func (r *raft) resetRandomizedElectionTimeout() {
r.randomizedElectionTimeout = r.electionTimeout + globalRand.Intn(r.electionTimeout)
}
r.electionTimeout默认值是10,然后在生成一个[0,10)随机数,所以默认范围[10,20)之间。
上述代码就是关于定时器内容,由此可见Etcd高超之处,利用逻辑时间Tick处理心跳和选举问题。
三、Etcd状态机
Etcd采用Raft协议,Raft协议中最核心内容就是状态机了。曾经深入研究状态机写法,市面一般有三种写法:switch case方式、数组方式、数组+函数指针方式。如果状态不多直接使用switch case最好,如果状态较多则参考后面两种方式。
在Etcd中则使用第一种方式,raft相关内容基本都在raft/raft.go
3.1 状态
在Etcd中,扩展了Raft状态,现在一共有4个状态:
// Possiblevalues for StateType. Raft角色
// Possible values for StateType. Raft角色
const (
StateFollower StateType = iota
StateCandidate
StateLeader
StatePreCandidate /* 预置Candidate */
numStates
)
3.2 创建Raft节点
func StartNode(c *Config, peers []Peer) Node {
r := newRaft(c) //创建Raft结构体
// become the follower at term 1 and apply initial configuration
// entries of term 1
//设置默认角色,为Follower
r.becomeFollower(1, None)
for _, peer := range peers {
//构造结构体数据
cc := pb.ConfChange{Type: pb.ConfChangeAddNode, NodeID: peer.ID, Context: peer.Context}
d, err := cc.Marshal() //排列
if err != nil {
panic("unexpected marshal error")
}
//构造结构体数据
e := pb.Entry{Type: pb.EntryConfChange, Term: 1, Index: r.raftLog.lastIndex() + 1, Data: d}
r.raftLog.append(e)
}
// Mark these initial entries as committed.
// TODO(bdarnell): These entries are still unstable; do we need to preserve (保存)
// the invariant (不变的) that committed < unstable?
r.raftLog.committed = r.raftLog.lastIndex()
// Now apply them, mainly so that the application can call Campaign (竞选)
// immediately after StartNode in tests. Note that these nodes will
// be added to raft twice: here and when the application's Ready
// loop calls ApplyConfChange. The calls to addNode must come after
// all calls to raftLog.append so progress.next is set after these
// bootstrapping entries (it is an error if we try to append these
// entries since they have already been committed).
// We do not set raftLog.applied so the application will be able
// to observe all conf changes via Ready.CommittedEntries.
for _, peer := range peers {
r.addNode(peer.ID)
}
n := newNode() //构造方法 创建Node
n.logger = c.Logger
go n.run(r) //启动node
return &n
}
下面是node.run方法的实现,该方法内容较多,分两部分介绍:
func (n *node) run(r *raft) {
var propc chan pb.Message /* 消息收发双向channel 最后一个字母c表示channel*/
var readyc chan Ready /* 数据压缩 用于持久化或者发送到对端 双向channel 每次发送一个Ready*/
var advancec chan struct{}
var prevLastUnstablei, prevLastUnstablet uint64
var havePrevLastUnstablei bool
var prevSnapi uint64
var rd Ready
lead := None
prevSoftSt := r.softState()
prevHardSt := emptyState
// readyc 和 advance 只有一个是有效值
for {
if advancec != nil {/* advance不空 则把readyc置空 */
readyc = nil
} else {/* 每次轮训都会创建一个ready对象 里面包含数据msgs */
rd = newReady(r, prevSoftSt, prevHardSt)
if rd.containsUpdates() {/* 如果raft.msgs中队列大小不为0 也会返回true 表示有数据发出 */
readyc = n.readyc
} else {
readyc = nil
}
}
if lead != r.lead {
if r.hasLeader() {//当前raft节点r中lead不为空,表示已经存在leader
if lead == None {
r.logger.Infof("raft.node: %x elected leader %x at term %d", r.id, r.lead, r.Term)
} else {
r.logger.Infof("raft.node: %x changed leader from %x to %x at term %d",
r.id, lead, r.lead, r.Term)
}
propc = n.propc
} else {
r.logger.Infof("raft.node: %x lost leader %x at term %d", r.id, lead, r.Term)
propc = nil
}
lead = r.lead
}
下面是重点内容,在之前的文章中多次介绍过此段代码,接收到网络消息则会在下方进行处理:
select {
// TODO: maybe buffer the config propose(建议) if there exists one (the way
// described in raft dissertation论文)
// Currently it is dropped in Step silently(默默地).
case m := <-propc: /* 从channel propc读出数据 */
m.From = r.id
r.Step(m) //进入raft状态机
case m := <-n.recvc: /* 从channel recvc中读出数据 进入状态机 */
// filter out response message from unknown From.
if _, ok := r.prs[m.From]; ok || !IsResponseMsg(m.Type) {
r.Step(m) // raft never returns an error 进入raft状态机
}
case cc := <-n.confc: /* 从confc中读出数据 */
if cc.NodeID == None {
r.resetPendingConf()
select {
case n.confstatec <- pb.ConfState{Nodes: r.nodes()}:
case <-n.done:
}
break
}
switch cc.Type {
case pb.ConfChangeAddNode:
r.addNode(cc.NodeID)
case pb.ConfChangeRemoveNode:
// block incoming proposal when local node is
// removed
if cc.NodeID == r.id {
propc = nil
}
r.removeNode(cc.NodeID)
case pb.ConfChangeUpdateNode:
r.resetPendingConf()
default:
panic("unexpected conf type")
}
select {
case n.confstatec <- pb.ConfState{Nodes: r.nodes()}:
case <-n.done:
}
case <-n.tickc:
r.tick() //回调函数 tickElection 触发选举 tickHeartbeat 触发发送心跳
case readyc <- rd: /* 将rd写入channel readyc中 大部分场景是由于r.msgs消息队列里面有内容 */
if rd.SoftState != nil {
prevSoftSt = rd.SoftState
}
if len(rd.Entries) > 0 {
prevLastUnstablei = rd.Entries[len(rd.Entries)-1].Index
prevLastUnstablet = rd.Entries[len(rd.Entries)-1].Term
havePrevLastUnstablei = true
}
if !IsEmptyHardState(rd.HardState) {
prevHardSt = rd.HardState
}
if !IsEmptySnap(rd.Snapshot) {
prevSnapi = rd.Snapshot.Metadata.Index
}
r.msgs = nil /* 重置msgs */
r.readStates = nil
advancec = n.advancec /* 写入advancec */
case <-advancec:
if prevHardSt.Commit != 0 {
r.raftLog.appliedTo(prevHardSt.Commit)
}
if havePrevLastUnstablei {
r.raftLog.stableTo(prevLastUnstablei, prevLastUnstablet)
havePrevLastUnstablei = false
}
r.raftLog.stableSnapTo(prevSnapi)
advancec = nil
case c := <-n.status:
c <- getStatus(r)
case <-n.stop:
close(n.done)
return
}
}
3.3 状态机核心方法
func (r *raft) Step(m pb.Message) error {
// Handle the message term, which may result in our stepping down to a follower.
// 校验Term取值 可能会改变raft角色
switch {
case m.Term == 0: //激活选举流程时 会进入此分支
// local message
case m.Term > r.Term: //当消息中Term大于本地Term说明新的一轮选举开始
lead := m.From
if m.Type == pb.MsgVote || m.Type == pb.MsgPreVote {
force := bytes.Equal(m.Context, []byte(campaignTransfer))
inLease := r.checkQuorum && r.lead != None && r.electionElapsed < r.electionTimeout
if !force && inLease {
// If a server receives a RequestVote request within the minimum election timeout
// of hearing from a current leader, it does not update its term or grant its vote
r.logger.Infof("%x [logterm: %d, index: %d, vote: %x] ignored %s from %x [logterm: %d, index: %d]
at term %d: lease is not expired (remaining ticks: %d)",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), r.Vote,
m.Type, m.From, m.LogTerm, m.Index, r.Term, r.electionTimeout-r.electionElapsed)
return nil
}
lead = None
}
switch {
case m.Type == pb.MsgPreVote:
// Never change our term in response to a PreVote
case m.Type == pb.MsgPreVoteResp && !m.Reject:
// We send pre-vote requests with a term in our future. If the
// pre-vote is granted, we will increment our term when we get a
// quorum(法定人数). If it is not, the term comes from the node that
// rejected our vote so we should become a follower at the new
// term.
default:
r.logger.Infof("%x [term: %d] received a %s message with higher term from %x [term: %d]",
r.id, r.Term, m.Type, m.From, m.Term)
r.becomeFollower(m.Term, lead)
}
case m.Term < r.Term: /* 当消息中Term小于本地存储的Term则说明曾经出现过脑裂,新的leader正在领导集群 */
if r.checkQuorum && (m.Type == pb.MsgHeartbeat || m.Type == pb.MsgApp) {
// We have received messages from a leader at a lower term. It is possible
// that these messages were simply delayed in the network, but this could
// also mean that this node has advanced(先进的) its term number during a network
// partition(网络分区), and it is now unable to either win an election or to rejoin
// the majority on the old term. If checkQuorum is false, this will be
// handled by incrementing term numbers in response to MsgVote with a
// higher term, but if checkQuorum is true we may not advance the term on
// MsgVote and must generate other messages to advance the term. The net
// result of these two features is to minimize the disruption(分裂) caused by
// nodes that have been removed from the cluster's configuration: a
// removed node will send MsgVotes (or MsgPreVotes) which will be ignored,
// but it will not receive MsgApp or MsgHeartbeat, so it will not create
// disruptive term increases
r.send(pb.Message{To: m.From, Type: pb.MsgAppResp})
} else {
// ignore other cases
r.logger.Infof("%x [term: %d] ignored a %s message with lower term from %x [term: %d]",
r.id, r.Term, m.Type, m.From, m.Term)
}
return nil
}
上面这部分代码,主要是进行Term(任期)校验,这部分属于Raft协议内容,其中脑裂是Raft协议特别提出的内容。下面这部分代码,则说明Message是当前任期的内容:
//message中term与当前raft的term一致
switch m.Type {
case pb.MsgHup: /* 默认开始激活选举流程 */
if r.state != StateLeader {/* 说明,当前节点并没有加入到任何leader之下,则切换状态,进入Candidate状态 */
ents, err := r.raftLog.slice(r.raftLog.applied+1, r.raftLog.committed+1, noLimit)
if err != nil {
r.logger.Panicf("unexpected error getting unapplied entries (%v)", err)
}
if n := numOfPendingConf(ents); n != 0 && r.raftLog.committed > r.raftLog.applied {
r.logger.Warningf("%x cannot campaign at term %d since there are still %d pending
configuration changes to apply", r.id, r.Term, n)
return nil
}
r.logger.Infof("%x is starting a new election at term %d", r.id, r.Term)
if r.preVote {
r.campaign(campaignPreElection)
} else {
r.campaign(campaignElection) /* 开始选举 进入Candidate状态 */
}
} else {
r.logger.Debugf("%x ignoring MsgHup because already leader", r.id)
}
/* 收到投票请求,则进行判断。 */
case pb.MsgVote, pb.MsgPreVote:
// The m.Term > r.Term clause is for MsgPreVote. For MsgVote m.Term should
// always equal r.Term.
if (r.Vote == None || m.Term > r.Term || r.Vote == m.From) && r.raftLog.isUpToDate(m.Index, m.LogTerm) {/* 支持票 */
r.send(pb.Message{To: m.From, Type: voteRespMsgType(m.Type)})
if m.Type == pb.MsgVote {
// Only record real votes.
r.electionElapsed = 0 //选举超时定时器 归0
r.Vote = m.From
}
} else {//反对票
r.send(pb.Message{To: m.From, Type: voteRespMsgType(m.Type), Reject: true})
}
default:
r.step(r, m) /* 回调函数,如:stepLeader stepCandidate*/
}
return nil
}
在上面的r.send方法用于将消息发送到网络对端,具体是如何一步一步发到网络对端,可参考前两篇博客。
func (r *raft) campaign(t CampaignType) { /* 竞选活动 */
var term uint64
var voteMsg pb.MessageType /* 消息类型 */
if t == campaignPreElection {
r.becomePreCandidate()
voteMsg = pb.MsgPreVote /* 预投票消息 */
// PreVote RPCs are sent for the next term before we've incremented r.Term.
term = r.Term + 1
} else {
r.becomeCandidate() /* 转变成为Candidate角色 */
voteMsg = pb.MsgVote /* 设置消息类型为:投票选举消息 */
term = r.Term /* term值已经变大 */
}
/**
* 判断投票数目: 如果大于一半则成为leader
* voteRespMsgType(voteMsg) 方法适配成对应的响应消息
* 先自己给自己投一票
*/
if r.quorum() == r.poll(r.id, voteRespMsgType(voteMsg), true) {
// We won the election after voting for ourselves (which must mean that
// this is a single-node cluster). Advance to the next state.
if t == campaignPreElection {
r.campaign(campaignElection) /* 递归调用 */
} else {
r.becomeLeader() /* 转变角色成为leader */
}
return
}
/* 给所有peer发送投票邀请 */
for id := range r.prs {
if id == r.id {
continue
}
r.logger.Infof("%x [logterm: %d, index: %d] sent %s request to %x at term %d",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), voteMsg, id, r.Term)
var ctx []byte
if t == campaignTransfer {
ctx = []byte(t)
}
//添加到队列中, 然后在什么地方发到对端呢? raft/node.go run方法中newReady对其进行引用
r.send(pb.Message{Term: term, To: id, Type: voteMsg, Index: r.raftLog.lastIndex(),
LogTerm: r.raftLog.lastTerm(), Context: ctx})
}
}
对于回调函数只介绍stepCandidate,其他两个(stepLeader 、stepFollower)则不深入介绍了,基本逻辑就是根据Raft协议,读者可依据自身情况。
// stepCandidate is shared by StateCandidate and StatePreCandidate; the difference is
// whether they respond to MsgVoteResp or MsgPreVoteResp.
func stepCandidate(r *raft, m pb.Message) {
// Only handle vote responses corresponding to our candidacy (while in
// StateCandidate, we may get stale MsgPreVoteResp messages in this term from
// our pre-candidate state).
var myVoteRespType pb.MessageType
if r.state == StatePreCandidate {
myVoteRespType = pb.MsgPreVoteResp
} else {
myVoteRespType = pb.MsgVoteResp
}
switch m.Type {
case pb.MsgProp:
r.logger.Infof("%x no leader at term %d; dropping proposal", r.id, r.Term)
return
case pb.MsgApp:
r.becomeFollower(r.Term, m.From)
r.handleAppendEntries(m)
case pb.MsgHeartbeat: /* 当前角色处于Candidate时如果收到心跳消息 则说明已经有其他节点变成leader,因此将自己角色变成follower */
r.becomeFollower(r.Term, m.From)
r.handleHeartbeat(m)
case pb.MsgSnap:
r.becomeFollower(m.Term, m.From)
r.handleSnapshot(m)
case myVoteRespType:
gr := r.poll(m.From, m.Type, !m.Reject) /* 获取支持数目 */
r.logger.Infof("%x [quorum:%d] has received %d %s votes and %d vote rejections",
r.id, r.quorum(), gr, m.Type, len(r.votes)-gr)
//以下case一个没有进入表示 投票支持率不到(集群成员个数/2+1) 所以继续等待
switch r.quorum() {
case gr: //集群成员个数/2+1
if r.state == StatePreCandidate {
r.campaign(campaignElection)
} else {
r.becomeLeader() /* 成为leader */
r.bcastAppend() /* 广播发送AppendEntry Rpc 即告诉其他节点我已经是leader */
}
case len(r.votes) - gr: //集群成员个数/2 - 1 不支持率
r.becomeFollower(r.Term, None)
}
case pb.MsgTimeoutNow:
r.logger.Debugf("%x [term %d state %v] ignored MsgTimeoutNow from %x", r.id, r.Term, r.state, m.From)
}
}
四、总结
关于etcd实践的几点说明:
1) 在实验过程中,Etcd两个网元节点也是可以组成集群,这一点和Raft协议要求不一致,如下图:
2) 假设集群有三个节点,并且在配置文件中已存在相关配置,如果只启动一个节点,那么这个节点是无法工作的(启动异常)。
至此Etcd中Raft相关内容介绍完毕,有些东西并没有深入介绍,例如在Raft协议中出现脑裂,Etcd是如何实现的?因此强烈建议看到此篇的朋友,需要深入了解一下raft协议。结合Raft协议,去看Etcd代码,会有事半功倍的效果。
- EOF -
1、
2、
3、
如果觉得本文不错,欢迎转发推荐给更多人。
分享、点赞和在看
支持我们分享更多好文章,谢谢!
以上是关于Etcd 源码分析:Raft 实现的主要内容,如果未能解决你的问题,请参考以下文章