记一次ES查询结果集失败
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次ES查询结果集失败相关的知识,希望对你有一定的参考价值。
参考技术A 使用es存储查询时有分页功能,数据量较少时并没有发现该问题。但是当数据量比较大时,要查询第101页的数据,每页数据量为100,100页数据相当于要查第10000条以后的数据,这时发现es查询报错:从字面理解,es的默认的结果集窗口是10000,但是你要查询到10025条数据;这里可以采用es的scroll api查询;或者通过改变索引的max_result_window的属性值。
上述的scroll api返回结果集为非排序的,不满足业务需求,所以不采用。
采用修改索引的max_result_window属性值。
修改方法如下:
返回结果:
然后再进行查询,发现可以正常返回了。
Elastic Search | 记一次Kibana执行ES-DSL脚本实战思考过程
目录
开篇
分而治之是大数据计算的基本思路,特分享一款天然的分布式全文搜索引擎-Elastic Search,而如何归并,是分而治之的重点难题。在HA集群节点架构中,各个节点主备分片如何分配,各分片搜索结果如何得出最终结果…

适合场景
当千万乃至更大数据量,需要像传统DBMS关系型数据库一样,实现在海量数据中作模糊搜索,全文搜索,又需要有一定程度的检索效率,突破传统DBMS性能瓶颈,那么ES很适合与关系型数据库形成互补,ES在搜索领域拥有强悍的性能,而传统DBMS关系型数据库分库分表组合查询相当麻烦,而ES组合灵活-自动路由(开发者无需在业务层作过多干涉),当然,在大数据量复杂查询的话,深度分页需要优化下,简单的查询几十亿问题不大,若超大则可上集群,再可上ES-ClickHouse.
重要考虑
虽然传统DBMS关系型数据库表中数据,可通过一系列方案-结合实际业务作数据同步至ES(数据建模),但当大批量数据同步到ES单节点,或从节点往集群迁移copy数据,基于logstash亦或是基于ES-Transport批量提交数据,数据需要实时更新亦或离线初始化,还有就是聚合的性能以及一些高级属性,比如copy to,script脚步引擎应用,mapping设计之动态模版映射动态索引或为指定索引匹配预制动态模版等等…
脚本引擎历史
一、Elasticsearch Script History-分布式全文搜索-脚本引擎历史
在ES早期的版本中,使用MVEL脚本,但为解决安全隐患问题,于是Groovy脚本诞生。
随之出现的安全漏洞跟内存泄露问题,于是在ES5.0版本之际,painless脚本官宣,距今也有数年之久,painless脚本浮现在开发者眼前。
脚本引擎应用
二、Elasticsearch Script ApplyCenarios-分布式全文搜索-脚本引擎应用场景
我们都很熟悉的认知到Elasticsearch全文搜索引擎,在其各版本系列中提供了丰富的dsl语法-增删改查-这里以6.x版本系列-6.8.6为例。
在80%以上的业务场景中作增删改查游刃有余,但应用于相对复杂的业务场景:
多字段自定义更新、自定义reindex、自定义数组字段动态添加...
https://www.elastic.co/guide/en/elasticsearch/painless/6.8/painless-regexes.html
当然基于脚本引擎手动开发插件也是可以实现的。
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-scripting-engine.html
从painless脚本的衍生意义理解是"无痛"无漏洞的,但尤其需要注意的地方-不能以root账户启动es,不要公开es路径至其他用户。
从官方Script使用的介绍来看,首要就是性能问题,其次就是使用业务场景,ebay在性能优化实践英文版中也有体现,
https://www.ebayinc.com/stories/blogs/tech/elasticsearch-performance-tuning-practice-at-ebay/
这里也mark下中文版。
https://www.infoq.cn/article/elasticsearch-performance-tuning-practice-at-ebay
其中,80%以上的业务场景:参考小编汇总Elasticsearch+Kibana+Dsl-Crud大全
DSL语法大全
#节点信息
GET _cat/nodes?v
GET _cat/master
#各节点机器存储信息
GET _cat/allocation?v
#索引信息
GET _cat/indices?v
GET /_cat/count
GET /_cat/count/yd-2021
GET _cat/indices/yd-hlht-test-2022
#分片信息
GET _cat/shards?v
GET _cat/shards/yd-hlht-test-2022
#查看所有分片的恢复状况-该命令查看initializing分片的恢复进度
GET _cat/recovery/
GET _cat/recovery/yd-hlht-test-2022
GET _cluster/health
GET _cluster/nodes/hot_threads
#查看分片未分配原因
GET /_cat/shards?h=index,shard,prirep,state,unassigned.*,unassigned.reason | grep UNASSIGNED
#查看具体分片未分配原因
GET _cluster/allocation/explain
"index":"yd-hlht-test-2022",
"shard":0,
"primary":false
#注册快照存储库-仓库共享
PUT _snapshot/my_backup
"type": "fs",
"settings":
"location": "/home/user/yxd179/es/backup"
#查看仓库信息
GET /_snapshot/my_backup?pretty
#查看快照存储库保存结果
GET _snapshot
#创建快照,这个会备份所有打开的索引到my_backup仓库下并命名为snapshot_yd的快照里。这个调用会立刻返回,然后快照会在后台运行。若是希望在脚本中一直等待到完成,可通过添加 wait_for_completion 标记实现,这个会阻塞调用直到快照完成(如果是大型快照,会花很长时间才返回),其中只会备份索引809iJpOmSI2ZmJrUqKRR0Q信息
PUT /_snapshot/my_backup/snapshot_yd?wait_for_completion=true
"indices": "809iJpOmSI2ZmJrUqKRR0Q",
"ignore_unavailable": true,
"include_global_state": false,
"metadata":
"taken_by": "phr",
"taken_because": "backup before upgrading"
#查看快照
GET /_snapshot/my_backup/snapshot_yd
#查看所有快照
GET /_snapshot/my_backup/_all
#删除快照
DELETE /_snapshot/my_backup/snapshot_yd
#监控快照创建或恢复过程
GET /_snapshot/my_backup/snapshot_yd/_status
#恢复快照
POST /_snapshot/my_backup/snapshot_yd/_restore
#动态模板
PUT /_template/yxd179_tpl
"index_patterns": [
"yxd179-2021*"
],
"settings":
"number_of_shards": 1,
"number_of_replicas": 1
,
"mappings":
"yd":
"dynamic_templates": [
"strings":
"match_mapping_type": "string",
"mapping":
"type": "text",
"index": true,
"copy_to": "full_context",
"analyzer": "ik_max_word",
"fields":
"keyword":
"type": "keyword",
"ignore_above": 256
],
"properties":
"full_context":
"type": "text",
"analyzer": "ik_max_word",
"fielddata": true,
"store": true
#副本分片分配设置
PUT /yxd179-2021/_settings
"number_of_replicas": "1"
#分页查询
GET /yxd179-2021/yd/_search
"from": 0,
"size": 30
#根据ID查询
GET /yxd179-2021/yd/647461503271768064
#bool query dsl查询
GET /yxd179-2021/yd/_search
"query":
"bool":
"must": [
"bool":
"should": [
"match":
"regNumber": "20203030651"
]
,
"term":
"status": "1"
]
,
"sort": [
"createTime":
"order": "desc"
],
"from": 0,
"size": 10
#允许ES最大滚动数目分配设置
PUT /yxd179-2021/_settings
"index":
"max_result_window": 13000000
#查看字段分词分析过程
POST /yxd179-2021/_analyze
"field": "regNumber",
"text": "国械标准20203030651号"
#模糊查询匹配
GET /yxd179-2021/yd/_search
"query":
"bool":
"must": [
"bool":
"should": [
"wildcard":
"regNumber.keyword": "*20203030651*"
]
,
"term":
"status": "1"
]
,
"sort": [
"createTime":
"order": "desc"
],
"from": 0,
"size": 10
#对指定字段设置分词器查询
GET /yxd179-2021/yd/_search
"query":
"bool":
"must": [
"match":
"hdsd0001004":
"query": "1828551417",
"analyzer": "char_analyzer"
]
,
"from": 0,
"size": 30
#模糊查询匹配
GET /yxd179-2021/yd/_search
"query":
"bool":
"must": [
"wildcard":
"hdsd0001002.keyword": "*yxd179*"
]
,
"from": 0,
"size": 30
#关闭索引:
POST yxd179-2021/_close
#打开索引:
POST yxd179-2021/_open
#对指定字段设置分词器
PUT /yxd179-2021/_mapping/yd
"properties":
"hdsd0001004":
"type": "text",
"analyzer": "char_analyzer"
#查看mapping结构体信息
GET yxd179-2021/_mapping
#设置分词分析器
PUT yxd179-2021/_settings
"analysis":
"analyzer":
"char_analyzer":
"tokenizer": "char_tokenizer",
"filter": "lowercase"
,
"tokenizer":
"char_tokenizer":
"type": "pattern",
"pattern": "|"
#minimum_should_match
GET /yxd179-2021/yd/_search
"query":
"query_string":
"query": "182855141y7",
"type": "phrase",
"operator": "AND",
"minimum_should_match": "100%",
"fields": [
"hdsd0001004"
]
#显示字段
GET /yxd179-2021/yd/_search
"_source":
"include": [
"id",
"productId"
]
,
"query":
"bool":
"must": [
"terms":
"productId": [
636654265306419462
]
]
,
"from": 0,
"size": 30
#高亮查询
GET /yxd179-2021/yd/_search
"query":
"bool":
"must": [
"bool":
"should": []
,
"term":
"status": "1"
,
"term":
"id":636662671736099971
]
,
"sort": [
"id":
"order": "asc"
],
"highlight":
"pre_tags": [
"<span class='title-key'>"
],
"post_tags": [
"</span>"
],
"fields":
"commonName":
"type": "plain"
,
"from": 0,
"size": 10
#read_only_allow_delete
PUT /yxd179-2021/_settings
"index":
"blocks":
"read_only_allow_delete":"false"
#查询模板
GET /_template
GET /yxd179-2021*/yd/_search
"from": 0,
"size": 30
#单个字段bool查询
GET /yxd179-2021/yd/_search
"query":
"bool":
"must": [
"term":
"id": "636651493706133509"
]
,
"from": 0,
"size": 30
#批量
POST /_bulk
"index":"_index":"yxd179-2021","_type":"yd","_id":"65965969996688"
"id":"65965969996688","HDSD0001002":"sdff","HDSD0001008":"fsdf","HDSD0001006":"000000000000000000","create_time":"2021-07-29","cancel_flag":0
"index":"_index":"yxd179-2021","_type":"yd","_id":"66049829996688"
"id":"66049829996688","HDSD0001002":"sdgsdg","HDSD0001008":"fsdfsdf","HDSD0001006":"000000000000000000","create_time":"2021-07-29","cancel_flag":1 更多dsl语法大全,请见->Elasticsearch进阶篇@记kibana执行dsl脚本实战过程
脚本引擎案例
三、Elasticsearch Script ActualCombat-分布式全文搜索-脚本引擎实战
这里仅以Update-By-Query为例:
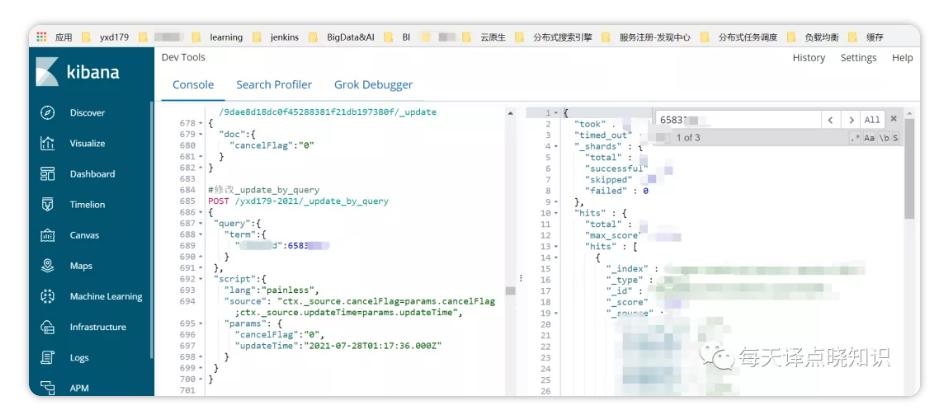
其中,lang指定脚本引擎:painless,source中为script脚本片段,params为脚本参数值。
之所以通过params传递,可突破ES对脚本编译限制,虽然也可以通过下面操作来修改该解析上限的配置:
PUT /_cluster/settings
"transient":
"script.max_compilations_per_minute": 40
重要:对于大批量数据,ES都需要单独的编译解析,当进行bulk update时,若是每一个脚本都实时编译的话,可想而知很快就会达到上限。知其然知其所以然,对于ES中都只会在第一次进行解析这个脚本,之后便无需再次解析,当脚本中有常数变量时,ES会实时编译脚本,故结合script中的param功能,设法将脚本中的变量通过param传递进去,从而可以从根本上解决脚本编译解析限制的问题。
接下来,我们看下在Java中怎么样基于6.8.6版本构建tcp client执行painless脚本引擎?

补充:对updateByQuery API的调用从获取索引快照开始,索引使用内部版本控制找到任何文档。
试想当一个文档在快照的时间和索引请求过程之间发生变化时,会发生版本冲突。当版本匹配时,updateByQuery更新文档并增加版本号。上述为了防止版本冲突导致updateByQuery中止,还可以设abortOnVersionConflict(false),之所以这么做,是有可能它试图获取在线映射更改,而版本冲突意味着在相同时间开始updateByQuery和试图更新文档的冲突文档,该更新将获取在线映射更新,updateByQuery也可以通过指定pipeline来使用ingest节点。其中UpdateByQueryRequestBuilder API可支持过滤更新的文档,限制要更新的文档总数,并使用脚本更新文档,即时刷入磁盘,重试次数等。
Retry: 当客户端A、B几乎同时获取同一个文档, 一并获得_version版本信息, 假设此时_version=1。
接着,客户端A修改文档中的部分内容, 将修改写入索引。而Elasticsearch在写入索引时, 检查客户端A提交的文档的版本信息(这里仍然是1) 和 现存的文档的版本信息(这里也是1), 发现相同后, 执行写入操作, 并修改版本号_version=2。然后客户端B也修改文档中的部分内容, 其操作写回索引的速度稍慢,此时同样执行写入过程,ES发现客户端B提交的文档的版本为1, 而现存文档的版本为2,即发生冲突,此次partial update将失败-重试。
并发控制策略:partial update并发控制策略-乐观锁
结尾
小试牛刀案例:如何通过脚本引擎指定多个字段update?
方式No.1:
ctx._source.putAll(params)
方式No.2:
for (k in params.keySet())if (!k.equals('ctx'))ctx._source.put(k, params.get(k))
末尾:后续Java框架体系,数据库技术体系,大数据体系进阶案例实战都会同时更新,微信公众号同步,旨在分享的初衷,欢迎提出宝贵建议^_^

以上是关于记一次ES查询结果集失败的主要内容,如果未能解决你的问题,请参考以下文章