性能调优案例 | 表多量大性能差,怎么破?
Posted 厦开系统联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能调优案例 | 表多量大性能差,怎么破?相关的知识,希望对你有一定的参考价值。
多张大表关联,返回的记录数多,还想要跑得快?
似乎是鱼与熊掌不可兼得?

某项目非功能测试时多支交易响应时间出现了超时(LR超时时间是120s)!测试人员很抓狂,开发人员很无奈。开发人员反馈说这些交易业务逻辑复杂,查询的表很多、数据量又大,确实会比较耗时,不知道该如何优化,希望申请性能优化专家支持。为此,项目组找到了我们寻求支持。

一、理想与现实的差距
进入项目组,初步了解情况后,跟踪交易执行情况,发现主要耗时都花在了SQL执行上: 6、7张亿级的大表关联,符合条件的结果集近30万,仅执行COUNT获取总记录就需要近百秒,更何况还有分页展示,120s太不够用啦,不超时才怪!
这么多表,这么大的数据量,耗时长似乎是必然的。但业务人员却希望交易能在2s以内响应,这能做到吗?
二、差距解决之路
既然有需求,那我们就试试看。还是依照查找问题à分析问题à解决问题的思路来。
先抓取出耗时长的SQL语句:两个,一个COUNT,一个分页。各个击破。
耗时长的COUNT查询SQL如下:

一张主表a和多张从表外关联。主表a五千万的数据,根据c_dt字段按月分区,每个月数据量150万左右。从表p表五千万左右的数据,f、e、o等表都是上亿的数据量。各表的关联都是通过id关联。
COUNT查询中的绑定变量:1和:2的查询时间区间大多是一周时间,主表a通过WHERE条件过滤后的数据约30万左右,再和多张亿级大表关联后,需要耗时100s左右!
1)化繁为简
一张主表和多张从表外关联,经确认各张表关联的id字段都是唯一的(如果不唯一可能就是数据存在问题了),因此count记录数多少是由完全由主表决定的,根本没有必要进行left join的关联。等价修改SQL如下:

SQL看起来清爽多了。A表依照c_dt字段月分区,每个分区150万左右的数据,最常见的查询一周数据的情况,顶多查询两个分区即可。
为提升COUNT性能,我们对c_dt、lsc_cd和c_id三个字段创建组合索引(加上c_id字段是因为后面会用到):

让COUNT查询通过扫描索引获得。
对绑定变量代入具体时间值,执行SQL语句,耗时仅0.23s,性能提升了三百来倍!具体如下:

COUNT查询搞定!如果想进一步了解COUNT的性能优化,欢迎翻阅之前的文章《一起带着count飞》!
另一个耗时长的SQL是分页查询,查询10条记录需要耗时300s左右,具体SQL语句如下,上百行的SQL,一眼望去,有点晕 @ @

管它晕不晕,兵来将挡,水来土掩,我们也争取将其拿下。
1)SQL逻辑和算法选择
先理一理SQL的逻辑:表关联时和前面COUNT一样,但多了很多大表的子查询。取一周时间,主表过滤后也是30万左右的数据,这些数据和多张亿级的表进行外关联,添枝加叶获得关联结果集,接着进行排序,最后取出10条数据进行展示。处理逻辑: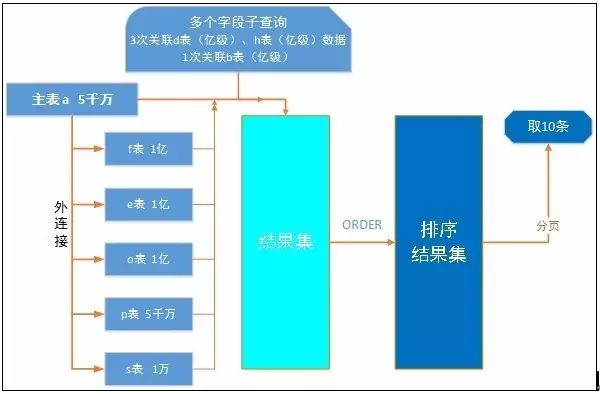 是不是有种头重脚轻的感觉?忙乎了半天就取一点点数据,算法有木有问题?是不是可以来个等价改造?
是不是有种头重脚轻的感觉?忙乎了半天就取一点点数据,算法有木有问题?是不是可以来个等价改造?
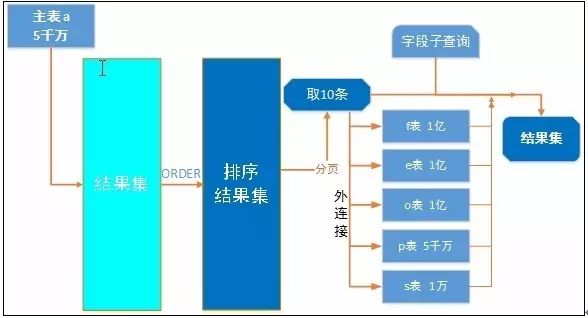
上图是不是平衡多了!先把主表的数据整出来排序,获取10条数据后,再进行多表关联,添枝加叶。
2)物尽其用
ORACLE中表是堆积存储,但索引却是有序存储。因此排序时如何能合理使用上索引将可达到事半功倍的效果。结果集排序字段(order by a.c_dt desc),正好是前面创建的c_dt、lsc_cd和c_id三个字段组合索引的前导列,因此如果查询结果集可通过扫描组合索引获得,那结果集就是已排序好的结果集,实际执行时就可省去排序的消耗。
再进行多表关联时,由于需关联的数据仅10条,外关联的大表都可使用上索引扫描,性能自然就会有大幅的提升。
3)一分为二
为了让SQL省去排序消耗和使用上索引,又可以更好的使用新一代框架的分页功能,我们将分页查询SQL,拆分为两个SQL来实现,第一个SQL先获取十条数据的ID,第二个SQL负责加工十条数据的结果集:
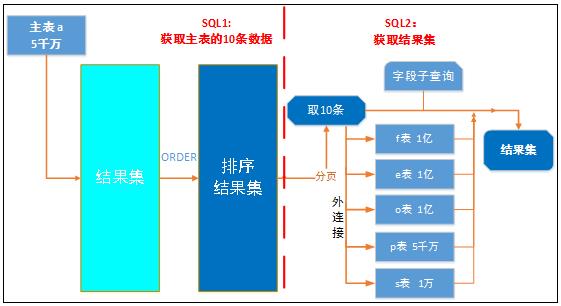
SQL1:

SQL2:
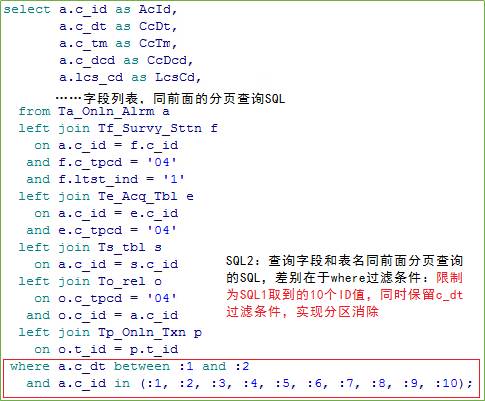
4)立竿见影
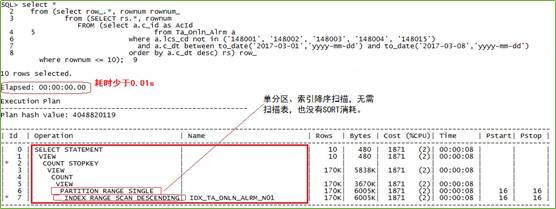
改造完成,对绑定变量代入具体值,SQL1执行耗时不到0.01s,性能杠杠的:单分区扫描新创建的索引(这就是建索引将afrd_alrm_id字段加上的原因)!
通过执行计划可以看到:没有了排序的消耗。
再将取到的10个ID值,代入SQL2查询:
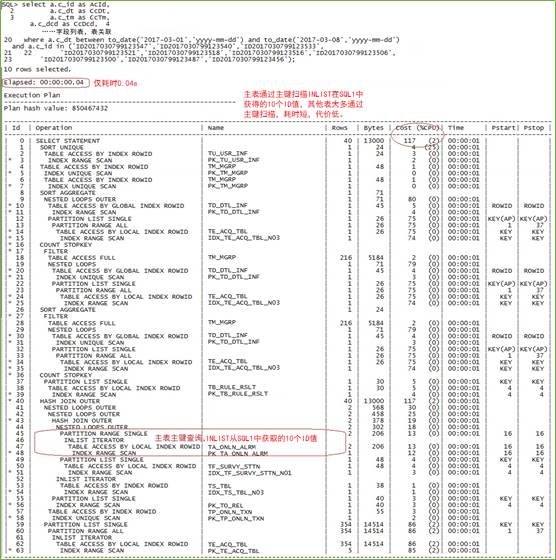
完美,三个SQL执行下来,总耗时0.23+0.01+0.04=0.28s,小于0.3s!性能提升了近千倍!业务要求的2s响应,轻松搞定!

开发人员使用我们提供的优化方法改写代码,发布新的程序版本。可是奇怪了,重新测试交易响应时间还长达23s,和我们代入具体值的查询性能差别也太大了,哪里还有问题?
继续跟踪交易执行情况,发现是我们改造的三个SQL执行耗时长:COUNT查询需要11.5s,分页SQL1需要11s,分页SQL2需要0.5s。三个SQL执行耗时都变长了,这是为何?

先分析执行计划,从COUNT查询入手:
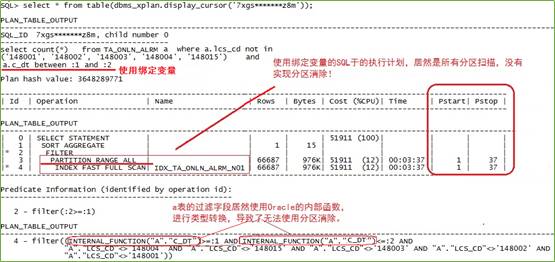
执行计划居然没有分区消除,所有分区扫描。查看语句的过滤信息(Predicate Information),分区字段使用了Oracle的内部函数(INTERNAL_FUNCTION),进行类型转换,这是为何?难道传入的变量值有问题?跟踪SQL语句绑定变量的传入值信息,传入值的类型是TIMESTAMP:

但是a表的alrm_trgr_dt字段类型,是DATE型,类型不一致!

原来问题在此:
传入的变量类型和表字段的数据类型不一致,发生了数据类型的隐式转换。由于TIMESTAMP优先级高于DATE,因此导致了alrm_trgr_dt字段需使用内部函数将数据类型转换为TIMESTAMP。分区字段使用了函数,就无法实现分区消除了。全分区扫描需扫描大量的数据块(150万上升到五千万),耗时自然就大幅上升了。

分页SQL1和SQL2耗时变长也是同样问题导致的。
解决方法:避免数据类型隐式转换。
修改SQL语句,对传入的变量值进行CAST转换,让它们转为DATE型,避免分区字段的数据类型转换。

分页SQL1和SQL2也类似修改,重新发布应用,再行测试,性能优于代入具体值的情况,整个交易耗时仅需0.25s!其他几支超时的交易也是类似情况,参照修改,超时问题完美解决!
千倍的性能提升,超额完成了业务期望的2s的性能需求!

三、知行合一
随着业务的不断发展,数据量将会越来越大,性能问题预计也将会越发突出。通过本案例,可以看到,要想解决好性能问题,就需要我们掌握和性能相关的知识,并合理地运用这些知识,开展应用设计和程序开发。

对于数据库的访问查询,建议:简单、明确,避免浪费,合理运用数据库特性,让其发挥出最大价值。
1、简单。SQL语句越简单越好,表关联越少越好。复杂的SQL费心费力,而且很容易出现不易觉察的浪费,越简单就越可控,越可靠!
比如本文的COUNT查询,没有必要的外关联就不要将其加入,表关联少了,语句简单了,性能自然就上来了。
2、明确。明确对应关系,明确要干的活,任务明确了,才不会出现偏差。本例中由于不明确数据类型的对应关系,导致隐式转换,出现了性能问题。
3、合理利用索引。除了查询少量数据,通过索引可以大幅提升查询效率外,索引还有很多其他的妙用,比如查询的字段都在索引中时,即使查询大量的数据,使用索引也会有性能的提升;索引存储的值是经过排序的,合理使用这个特性,很多时候可以帮助我们省去费时费力的排序消耗。
4、本案例最大的优化点:取得分页记录数的算法选择。从大量的结果集数据中仅取少量数据进行分页展示的情况,要想性能好,选择合适的出手时机很关键,这个过程值得我们好好的思考和设计。
厦门开发中心测试与推广支持处 系统与非功能小组出品
编辑:方妍
以上是关于性能调优案例 | 表多量大性能差,怎么破?的主要内容,如果未能解决你的问题,请参考以下文章