Spark认识及性能调优
Posted 京东成都研究院
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark认识及性能调优相关的知识,希望对你有一定的参考价值。
Spark认识
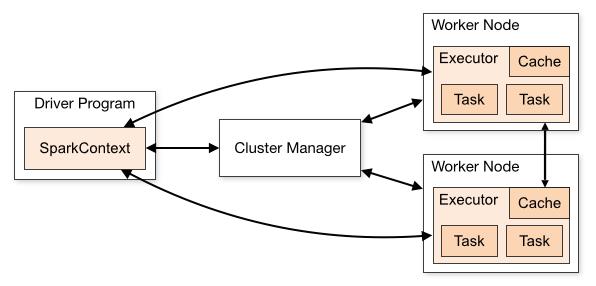
Spark历史,spark框架,模块,spark 核心对象 RDD 讲解,RDD的属性介绍等。
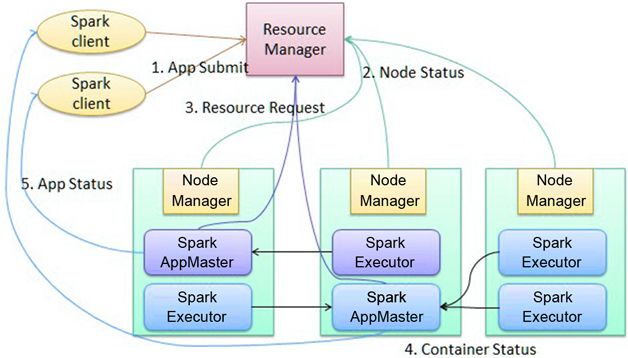



spark配置介绍
spark.default.parallelism(必选)
num-executors (必选)
executor-memory (必选)
executor-cores (必选)
driver-memory (可选)
spark.sql.shuffle.partitions (sparkSql必选)
spark.storage.memoryFraction (可选)
spark.shuffle.memoryFraction (可选)
项目中的调优实践
X项目性能优化小结
运行情况:
1)优化后两个核心任务,耗时在1小时内,优化前3小时+或者失败。
2)优化后运行2个月,稳定运行未发现异常,报错。
一、存在问题现象
1.现状:
1)数据处理链条很长,其中两个核心任务
srs_main_app_sem_X项目_image_spark:耗时3小时左右。该任务数据源10T左右,数据文件块规则。占满hdfs数据块。
srs_main_app_sem_X项目_extra_spark:耗时3小时左右,并且频繁出现OOM和lost executor异常导致时间非常长。该任务数据源2T左右,但是数据文件分块为17000多个,有非常多的小文件块。
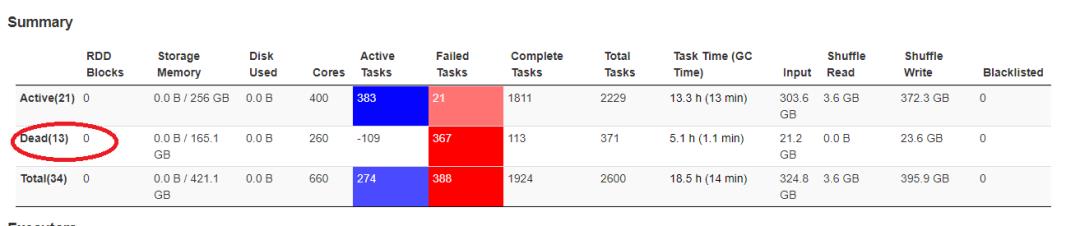
2)其他任务处理时效性较高,但也会出现spark挂起的情况。(执行到99%停挂起)
3)报OOM错,或者lostexecutor
18/03/13 16:39:00 WARN TaskSetManager: Lost task 239.0 in stage 2.0 (TID 2408, executor 30): java.lang.OutOfMemoryError:
二、解决方案
1.梳理数据处理链,资源密集任务,避开集群资源高峰时段。
观察集群,在凌晨4点~凌晨7点为业务高峰期(对gdm.item表数据使用高),调整srs_main_app_sem_X项目_ extra_spark任务在7:45开始执行,资源利用率高。
在凌晨4点运行,任务并发为50个task。
在凌晨7点运行,任务并发为800个task左右。 运算速度提高16倍
2.代码优化检查,sql优化
2.1去掉distribute by rand()函数,函数作用为:当数据的KEY倾斜时,将相同的key随机分发到不同的reduce段进行处理。避免MapReduce过程中的数据倾斜。
1)当数据KEY的确有数据倾斜问题时候,再使用。一般先观察数据源,如果某些key的数量,占总数量的5%以上,认为有数据倾斜。
2)distribute函数会导致程序先进行数据散列。会产生额外的运行开销。
使用distiribute的task数:5097个(如下截图)
不使用distribute的task数为1807个(如下截图)
2.2去掉不合理的repartition:
spark用于为数据重新分块,会产生shuffle,数据源的blocks有1.7万个,被repartition到100个,经常出现OOM或者LOSTExecutor。
在运行资源不变的条件下,repartition设置为3000个出现OOM概率降低。 将repartition去掉,不会出现OOM,运行速度也非常快。
三、hive-sql,spark-sql参数优化
hive-sql:
setmapred.output.compression.codec=com.hadoop.compression.lzo.LzopCodec;
set io.compression.codecs=com.hadoop.compression.lzo.LzopCodec;
set hive.default.fileformat=Orc;
set hive.merge.mapfiles = true;
set hive.merge.mapredfiles = true;
set hive.merge.size.per.task = 512000000;
setmapred.min.split.size.per.node = 128000000;
set mapred.min.split.size.per.rack = 128000000;
set hive.exec.reducers.bytes.per.reducer= 128000000;
set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
set hive.exec.parallel=true;
set hive.groupby.skewindata=true;
set hive.lzo.use.index=false;
spark-sql:
--confspark.sql.autoBroadcastJoinThreshold=200000000
--driver-memory 8G
--conf spark.drive.maxResultSie=6g
--conf spark.default.parallelism=3000
--conf spark.sql.autoBroadcastJoinThreshold=1048576000
--conf spark.sql.files.openCostInBytes=8388608
--conf spark.sql.files.maxPartitionBytes=268435456
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
--conf spark.network.timeout=800
--conf spark.shuffle.io.maxRetries=60
--conf spark.shuffle.io.retryWait=60
--conf spark.yarn.executor.memoryOverhead=5096
--conf spark.storage.memoryFraction=0.4
--conf spark.shuffle.memoryFraction=0.4
--conf spark.sql.shuffle.partitions=3000
红色背景参数有独特作用,重点关注。
其他优化
四、优化结果
核心任务从3.5小时+,缩短到50~60分钟之间。 优化后任务稳定执行,未发现一例OOM情况。
五、总结
数据处理过程与数据源情况密切相关:
1)数据源有数据倾斜:考虑解决数据倾斜的解决方案
2)数据源物理分块非常多,每个块数据少,导致并发高,处理慢:考虑通过参数先在MR的MAP阶段先combine数据,再做MR
3)避免shuffle,增加repartition块:shuffle代价很大,尽量避免。不能避免尽量使用带partition的算子。
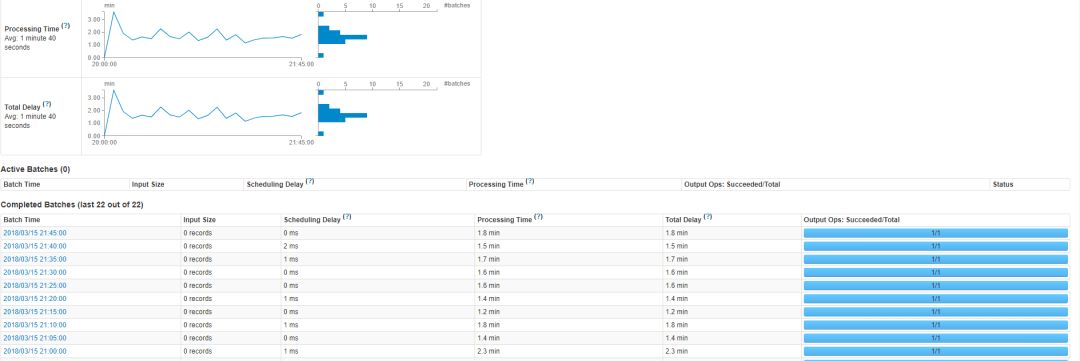
六、SparkStreaming 性能调优实践
流处理时效性要求高,提高时效性是优化的重点。
优化前:
1)优化前每个batch执行20多分钟,远远达不到5分钟的周期。
2)优化前资源没有充分利用。内存和cpu利用率不高。
优化后:
1)每个batch没有延迟,执行时间在3分钟内完成。
优化点:
1)结合在流中数据处理的特性,缓存在各batch之间公共的数据。
2)使用partition的算子,RDD面向executor共用对象,数据等。
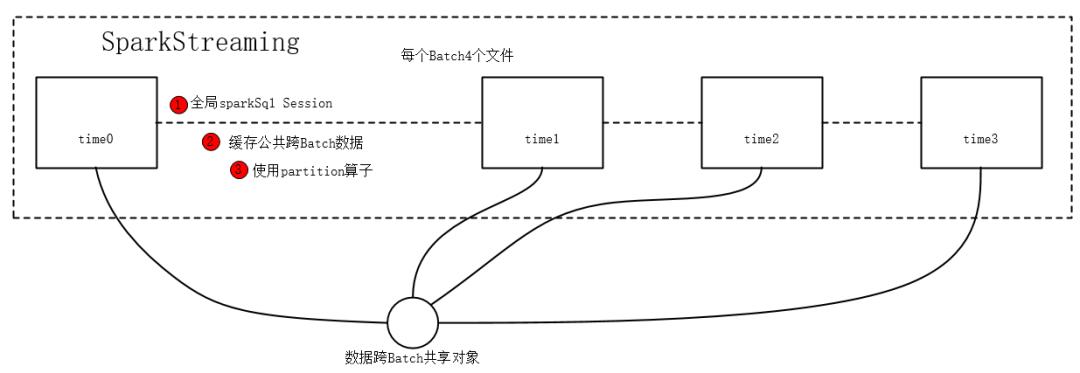
优化实现:
1)创建全局跨Batch的sparkSession,单例懒汉双检验
2)缓存跨Batch的数据依赖,提升公共数据利用率,避免每个Batch重复计算
3)工具类在partition 算子中使用,基于Eexecutor的粒度复用连接池等,提高效率。
4)其他优化
预先计算缓存使用大小,cpu和内存资源。最大化的提升资源利用率
以上是关于Spark认识及性能调优的主要内容,如果未能解决你的问题,请参考以下文章