谁还不懂分布式系统性能调优,请把这篇文章甩给他~ Posted 2021-04-05 高效运维
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了谁还不懂分布式系统性能调优,请把这篇文章甩给他~相关的知识,希望对你有一定的参考价值。
说明:本文根据 2020 GOPS 全球运维大会 · 深圳站陶辉老师的演讲整理而成。
个人简介:陶辉,毕业于西安交通大学计算机科学与技术专业,目前在杭州智链达数据有限公司担任 CTO 兼联合创始人,专注于用互联网技术帮助建筑行业实现转型升级,曾先后在华为、腾讯、思科、阿里巴巴等公司从事分布式系统下的数据处理工作,腾讯云最有价值专家TVP。对 Linux 下的高性能服务器开发、大规模分布式系统的设计有着丰富经验。著有《深入理解 nginx
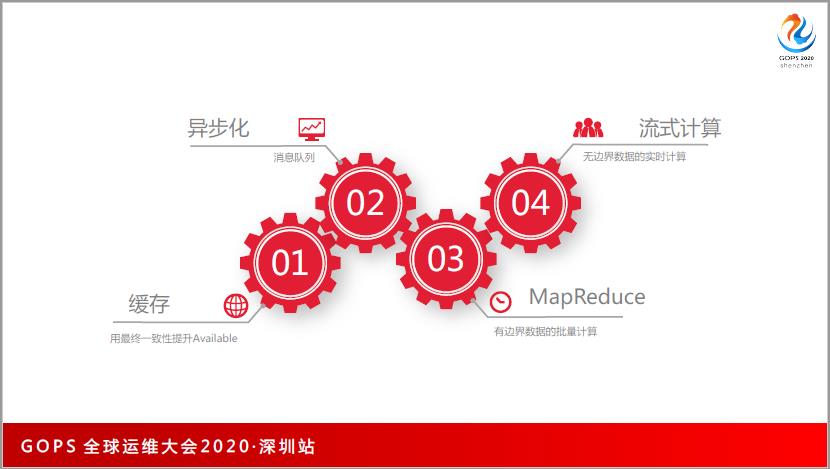
基础资源优化。不管是X86、ARM,还是 Linux、Windows,不管是脚本语言还是C语言,这种优化都有效的,相对来说收益比较大、比较普惠一些,我把它列为基础资源优化。
网络效率优化。这包含三个层面3层,一是系统层,二是应用层,三是传输效率的优化。
降低请求时延。怎么用缓存等,我们关注用户的体验,能让单次请求的速度更快一些。
吞吐量。提升系统并发,从吞吐量来说怎么提升系统的并发。
一、基础资源优化
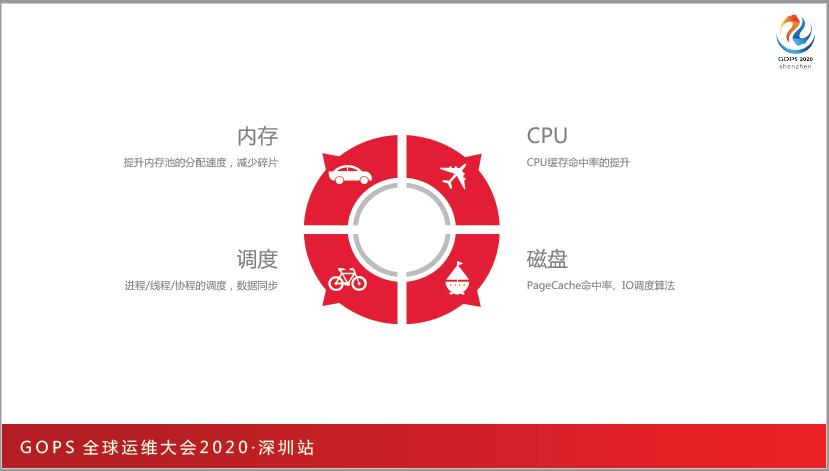
基础资源的优化,在我看来核心是提升资源的利用率,资源我们分为四块:
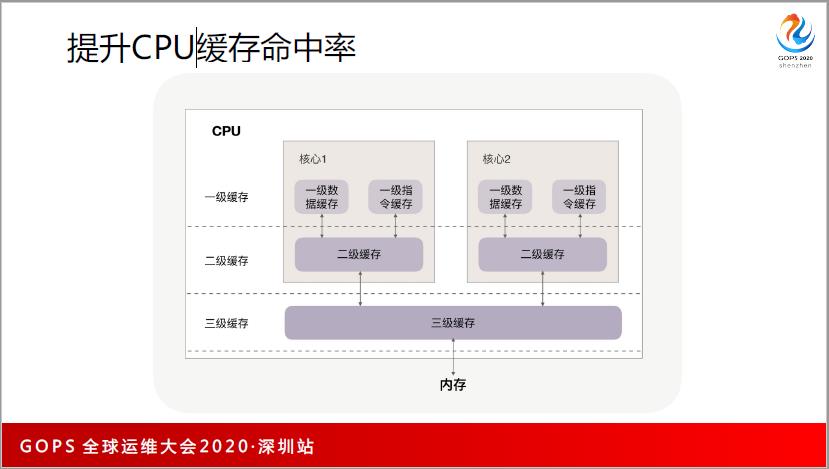
CPU 缓存。CPU 的缓存共分为3级,CPU访问缓存的时延应该在 10 纳秒左右,一级缓存可能只有 1 纳秒左右。这个时候我们非常关注怎么让 CPU 缓存命中率提升,它是一个普惠的优化方式。
内存。内存有百纳秒级别的速度,当你的频率非常高的时候也不是那么快,所以会有很多的内存池,比如说 C,JVM、Python、Golang、lua 等都有自己的内存池,这些内存池的怎么提升分配速度、减少碎片、提升内存的利用率。
磁盘。磁盘有两类,一类是HDD,机械硬盘的寻址在七八毫秒,它的磁头旋转速度是比较慢的,以往的很多软件技术都在优化这方面,特别是 PageCache 磁盘高速缓存的使用,包括电梯调度算法、零拷贝,或者 Direct IO 等等都是围绕着机械磁盘来做;另外一类SSD,SSD跟机械硬盘完全是另一种方式,包括编程方式、优化方式都跟传统的方法不一样。所以这里简单总结一下,以 PageCache 作为切入点,包括命中率、IO调度算法。
调度。分布式系统中有很多的请求,这些请求如何切换,无论是多进程、多线程,还是协程,怎么样能让它的调度性能更高、效率更高,数据的同步更快?
CPU CPU 缓存的话题比较多,这里举个例子,我相信各位都用过 Nginx,Nginx 有两个哈希表,一个是域名哈希表,如果只是用普通的3级域名,可能触碰不到它的上界,但是如果有4级、5级或者是更多级的域名,可能就会超过64字节,这时你要调大哈希表的 bucket_size。
再举个例子,Nginx 最强大的地方在于它的变量,任何功能都能够通过变量实现。变量也是存在哈希表中。当这个变量比较大的时候,一样也要调整到 64 字节。
那么,为什么是初始的 64 字节?比如想调到 100 字节可不可以,不可以的。要调到 128 字节或者是是 64 字节的整数倍。
为什么会这样?关于 CPU 缓存,我这里举一个例子。大概在2005年,CPU 的频率大概升到 3Ghz~4Ghz 后就不再提升,因为单个 CPU 的发热量太大,所以只能横向发展。
多个 CPU 有一个好处就是真正并发。操作系统中的并发是通过时间片切换完成的,微观上不是真正的并发。而多核 CPU 的并发有一个问题,当两个 CPU 同时访问了两个进程或线程,这两个数据同时落到了一个 64 字节之内,CPU 的缓存不是一个字节拉的,而是一批拉的,每一批 64 字节。
为了解决这个问题,Java 中有一个常见的词叫填充法,我刚刚讲的 Nginx 也是填充法,用不了这么多字节,但要填这么多,使得微观上真正并发。因为 CPU 要保证一致性,如果数据没有一致性就没有高性能和正确性可言。CPU 的缓存对很多代码都有影响,并不是只对写中间件的人有影响,对应用层的开发人员也是有影响的。
内存
关于内存池这一方面,我想起3年前我给华为做的一场内训。当时有一个同学问我,Nginx 要不要换成谷歌的 TCMalloc?(TCMalloc 是 Google 开发的一个内存池。)
应用程序每次要分配内存,操作系统内核提供系统调用,叫 brk 和 mmap。这些系统调用的效率不高,因为有内核态到用户态的切换,那么怎么办?
C程序有一个C库,Linux 默认叫 Ptmalloc2。 默认分配一个字节会给你预分配 64MB 字节,当你分配第二个字节的时候还从这个池子里面找,释放后会回到这个内存池。这个池子有很多的问题,比如说 Ptmalloc 非常通用的内存池,考虑的是效率特别高,比如说A线程释放的,B线程还能直接拿来用,这肯定有一个并发问题,肯定要加锁,一加锁性能就不高,像 tcmalloc和 Ptmalloc 默认了这个,什么也不改。
而谷歌的 TCMalloc 分为小内存、中内存和大内存,小于256KB字节的就是小内存,小内存不考虑共享,所以不用加锁,速度很快;对于中内存和大内存速度反而不如 Ptmalloc。如果我们做服务器的开发,特别是 Nginx 简单的服务器的开发,如果是做动态服务器,经常会分配几MB内存,但是对于只有负载均衡、简单 lua 脚本操作情况下根本不可能分配大内存,所以 TCmalloc 就非常的适合它。
这里我只是介绍了C库的内存池,其实上面还有很多的内存池,比如说 Nginx 对共享内存中有内存池 slab,这个 slab 在 openresty,是复用的,对于普通的储存里也有一个内存池,还有连接内存池和请求内存池。
如果是其他的语言,比如说 lua 虚拟机,它有自己的lua,还有自己的内存池。Java 有 JVM 内存池,golang 也有自己的内存池,像 golang 是基于 tcmalloc 改过垃圾回收机制。这是我希望能够引起大家注意的,主要是靠线下大家学习。
磁盘
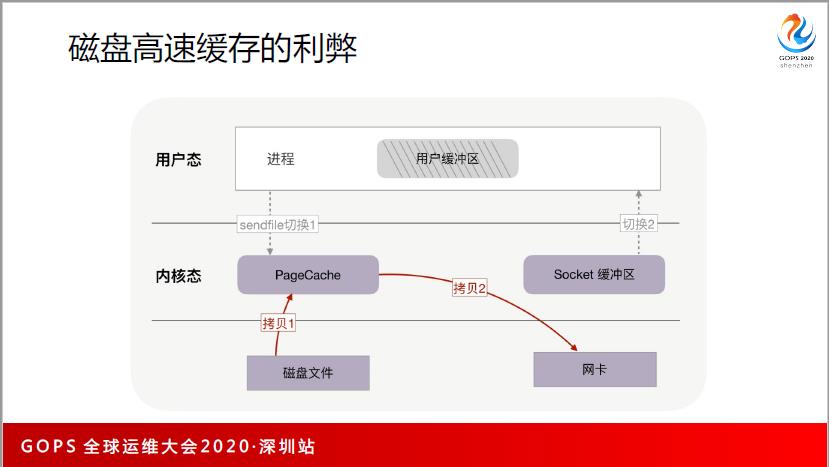
磁盘,我想围绕着 PageCache。PageCache,传统的机械硬盘,你想让它并发,它并发不了,它只蒙在那里转,所以你要通过调度算法,让它尽量往一个方向转。读的话,会考虑 PageCache 不停的缓存命中。
比如说零拷贝,零拷贝是不是一直有效呢?比如做视频的直播或者 CDN,这个文件很大,再次命中的概率不高,Pagecache 及其有限,如果文件这么大,因为有很多并发的线路正在同时获取不同的文件,所以命中的概率很低。
很难再次命中,PageCache 也给它进行了降低性能。
因为 PageCache 是 least used,只要你现在进来一个东西,一定要出去,出去的东西,本来是很有机会被再次访问到的小块资源和文件,所以就失去了再次命中的机会,所以才会有直接IO和异步IO,Linux 的作者认为接口设计很糟糕,但是这个东西是很有用的,并不是一点用也没有。
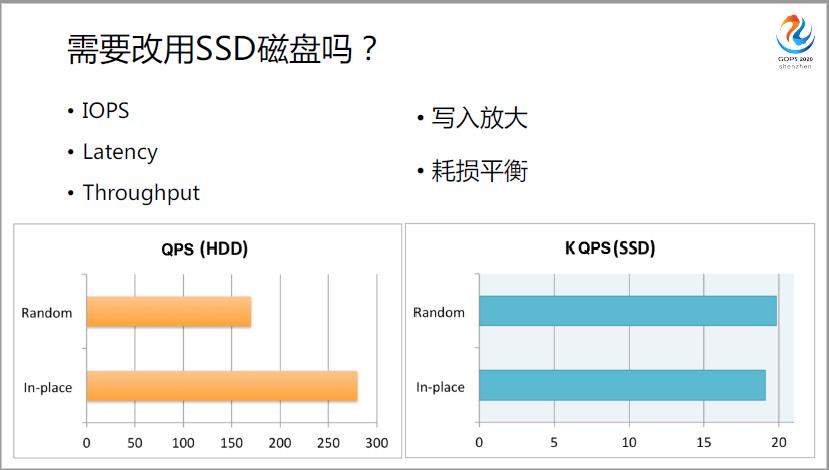
比如说SDD,SDD在我看来是另外一个物种。平时大家都认为“SDD 比机械硬盘的 IOPS 高,Latency 低,Thoughtput 更高,即总的吞吐量更高”绝对不是简简单单这么一点东西。
我举个例子:第一,SSD有个问题叫写入放大。
大家都知道 Kafka,Kafka 性能为什么这么好?一个特点就是削峰填谷,它要把数据持久化。既然是写硬盘性能为什么能这么好?因为它充分利用了磁盘的旋转速度,消息队列先天性是时序队列,一定不停的往一个文件后面追加,所以磁盘利用率非常高,只要放很多块机械磁盘,性能还可以继续提升。
如果换了SSD,还有这样的好处吗?SSD 本来就是快很多,但再采用这种方式就有问题,因为它有写入放大问题,什么叫写入放大?比如说我们本来是写日志文件,都往后面追加一些字节,但是 SSD 不行,SSD有一个页面,是它的基本单位,它是按页面来的。
比如说现在的页面上已经有了一个字节,现在还想写第二个字节,它会把整个页面读到缓存区中,然后给它加进去,最后再写到一个新的没有人写过的页面,所以有很大的放大作用。每写一个字节,可能给我写了几K,它最怕的是 inplace 这种原地写入,那像 Kafka 再采用的方式会有问题。
第二,耗损平衡。
SSD的寿命不好,什么寿命短呢?因为它不能清除,每一个存储单元清除的次数是有限制的。如果一个硬盘有一个数据特别热,比如说就是放操作系统的,经常读写,读着就坏了,这个是大家受不了的,其他地方都好。所以搞了一个GC,不停给你移,这边是热数据的,这边是冷数据的,我给你移过去,移过去之后大家就平衡,这块磁盘就不会那么快坏。
但这个机制就有问题,给应用程序带来了挑战。如果应用程序按照传统的方式去写,不停大量的写入操作进去,就会不停触发机制,当他的GC赶上过米的时候,又变成阻塞了,性能又下去了。
其实 SSD 有很多和 HDD 不一样的地方,比如说机械硬盘的时候,绝对不会考虑多开几个线程,让速度变快,因为硬盘就在那里转,多开线程最终还是排队的,但是SSD不一样,你多开几个,它就是那么快,因为它先天可以做并发。
比如说 SSD 做随机读写也做得特别好,我们在机械硬盘上尽量减少数据读写的,但到SSD就可以读写。
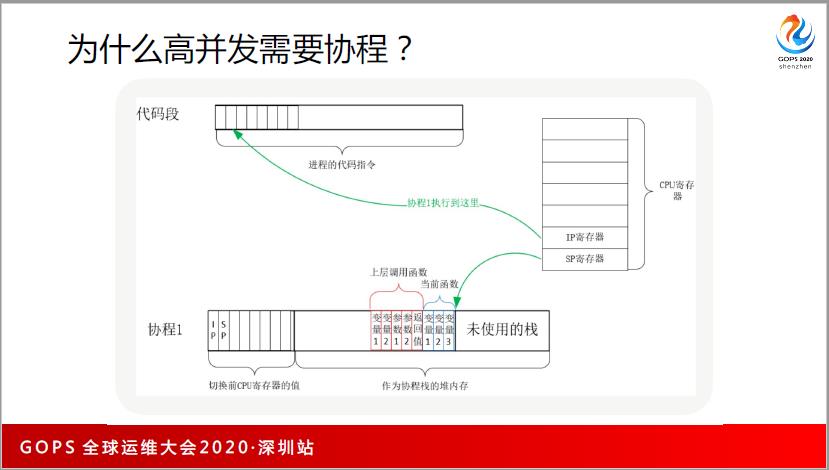
再回到高并发,为什么高并发要使用协程,为什么比多线程要快效率要高?在我看来有两个原因:
1、每一个协程消耗的内存非常低。每一个线程有多高吗?给你搞了一个堆内存池,你说一个字节搞一个内存池,线程都有栈,栈什么时候会溢出呢?栈到底有多大呢?一般是2MB到8MB,这么大的线程,可以想象有多少的内存?
如果几十G的内存上并发10000个线程,内存都不够,其他业务就做不了了。
最大的问题是同时处理一个请求消耗的内存不能多,而协程就能做到。基本上协程几KB到十几KB就可以处理一个请求。所以可以轻松通过十几G的内存并发到几万个、十几万个请求。
2、切换成本低。在线程上做切换时有一个内核态到用户态的切换,而且要做大量的拷贝。在协程的话,因为是全栈用户态,切技能器,或者是不切技能器,直接调度到代码里面切一下就可以了,所以相对来说成本也是很低的。
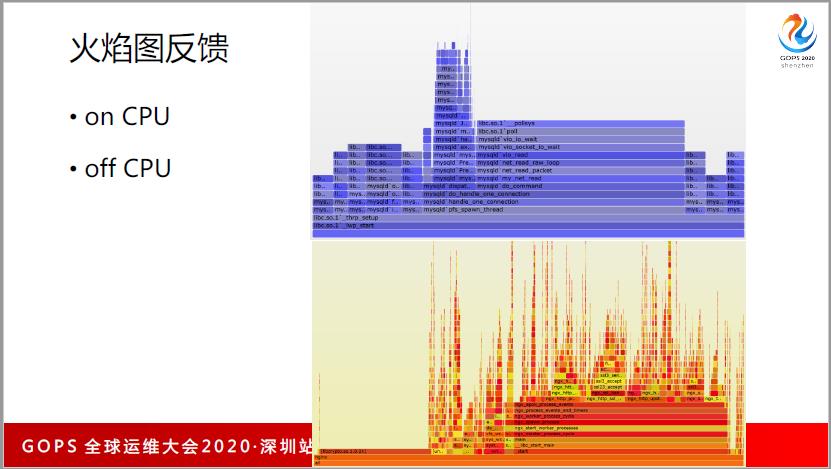
最后再总结一下,对于 CPU 这方面,有一个特别有效的工具。有时候说优化性能,要找到瓶颈,越是瓶颈的地方进行优化才最有价值。怎么找瓶颈呢?我推荐火焰图。你要自己去打点和写日志很容易遗漏,你不用装任何的东西,只需要装一个 Linux perf+FlumeGraph 两个软件就可以。
它分了两种,on CPU 和 off CPU。onCPU 它是以暖色调为主,看消耗了多少个CPU,因为把所有的函数都考虑到;而offCPU是冷色调,看每一个函数要进程或者是线程进入 sleep 的时间有多长?这两个图有一个好处,它是一个SVG的矢量图,所以可以跟各种正则表达式匹配,也可以点击放大,而且它会把同一个调用栈中的相同函数进行合并,很容易比出来哪一个函数消耗的时间最长。
二、网络效率优化
网络效率优化,主要是编解码和改进传输方式。
编解码有三部分:
系统层传输效率。系统层主要是TCP协议,它的优化包括三次握手建链优化,四次握手关闭优化。主要根据你的网络环境,丢包率高不高,时延长不长;如果丢包率非常好,重试的次数很多都可以进行调整。还有缓冲区优化,以及拥塞控制。
应用层的话,主要看 HTTP 协议。
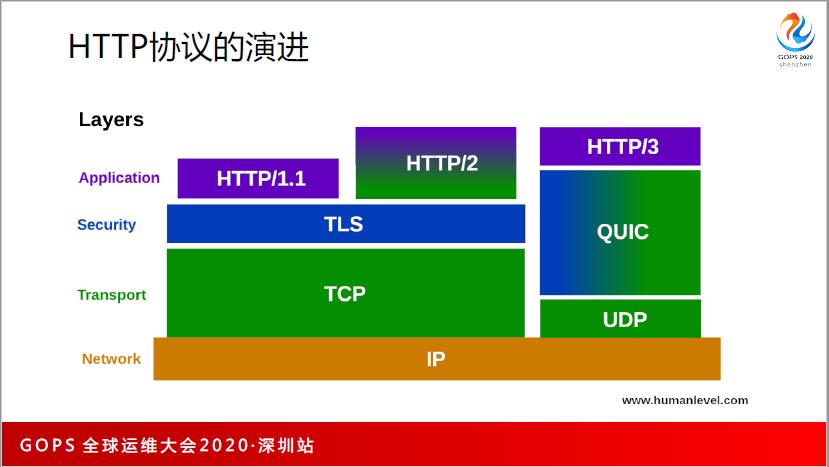
1996年是HTTP1.0,1999年是HTTP1.1,我们现在主要使用的是1.0和1.1,2015年是HTTP2,他们都是跑在TLS和TCP上,为什么呢?因为能够简化开发效率。
TCP 实现了有序字节流,TLS 也要基于有序字节流,如果没有有序字节流,现在也玩不转。比如在 QUIC 中要重新实现这点。HTTP2,有了有序字节流,很多问题不用考虑,不管文件有多大,只要正常传输就好。
这就带来了一个问题,在一个有序的字节流上,放了一个无序的东西(HTTP 是多并发的,并发肯定是无序的)。无序的东西承载在有序的字节流上,带来的问题就是队头阻塞。它有多个stream,只要出现一个 stream,TCP 就有可能丢包,后面的 stream 都玩不转了,所以只能通过 UDP 来解决。
UDP 解决以后,出现了一个 QUIC 层,这个 QUIC 层是独立的一层,把 TCP 层的很多事(丢包、重传、拥塞控制)都做了,TLS 也需重新写,把 HTTP2 中的 stream 也封装也放到了里面。
HTTP3 到底有什么好处呢?1.多路复用;2.连接迁移;3.QPACK编码;4.丢包重传。
我举个例子,比如说抓一个 HTTP3 的包就知道,抓包看完最上面是 UDP Header,UDP Header 就是一个4元组:源IP、目的IP、源端口、目的端口。接下来是 Packet Header,Packet Header 中有一个整数,叫 connection_id,为什么有 connection_id?
以前一个连接是如何定义的呢?四元组(源IP、目的IP、源端口、目的端口),只要四元组改了就需要重连。
在 IOT 时代,各种高速移动的设备会经常切换,比如经常切换的 5G 基站,或是切到一个 WIFI,这时IP地址肯定会发生变化,需要重新建立连接。重建连接的成本太高了,怎么样不重新建立连接呢?从 Packet Header 中,定义了一个 connection_id 的整数。
只要这个整数不变,这个连接就可以复用,TLS 握手也不用做了。为什么可以这样做呢?其实很简单,这些东西是加密到 HTTP3,如果能够解密的话,安全性是没有问题的。Packet Header 中,这就叫连接迁移,就是我们说的 Connection Migration,连接迁移,这是 HTTP3 的第一个用处。
HTTP3 的第二个用处多路复用。多路复用是到 QUIC Frame Header,Packet Header中定义了连接是无序的字节流连接,只管你不丢包,要是丢包了,我们有一个ID,能找到重发。
但顺序乱了,我是不管的,管顺序乱不乱是在 QUIC Frame Header,他做了一个东西,他重新定了叫 QUIC stream 的概念,就像跟 TCP 连接是一样的,这里做出来一个TCP 连接,跟 TCP 连接用起来是一模一样的。
大家都知道 TCP 三次握手时在同步 Sequence,SYN 参数的全称就是 Synchronize Sequence Numbers。在同步两边的序列号,因为在接下来的每发一个字节,序列号就会加1,对方接受确认的时候也是这么做的。他里面也有一个 Sequence,所有的都是一模一样的。
基于这个做出来的有序字节流,就完成完成解决了队头堵塞问题,所以它的多路复用是真正的多路复用。
再接下来到了 HTTP3 Frame Header,QUIC Frame Header 已经提供了一个 TCP 连接,但是 HTTP 是有自己很多独立的应用,比如说除了 request/response 以外,还有服务器推送,服务器推送就是一种新的 Frame Header,先所以前面又加了一层头部去完成这样的功能。
还包括另外一个功能,QPACK,大家知道 HTTP2 当中有一个 HPACK,功能就是压缩头部。最高的压缩就像我们看视频的时候,有关键帧和增量帧,如果经过什么压缩的视频,压缩完以后体积能减少几百倍,看起来还挺清晰的,它就是关键帧和增量帧,压缩效率特别高,HPACK 也是一模一样的。当你在一个连接上第一次传输一个 HTTP header 的时候,其实就是你的关键帧。
后面做增量帧的时候,只要传一个数字就行。但是这种方式也有一个时序效应,谁先谁后。所以就出现了 QPACK,这是基于无序的连接去实现一个功能。
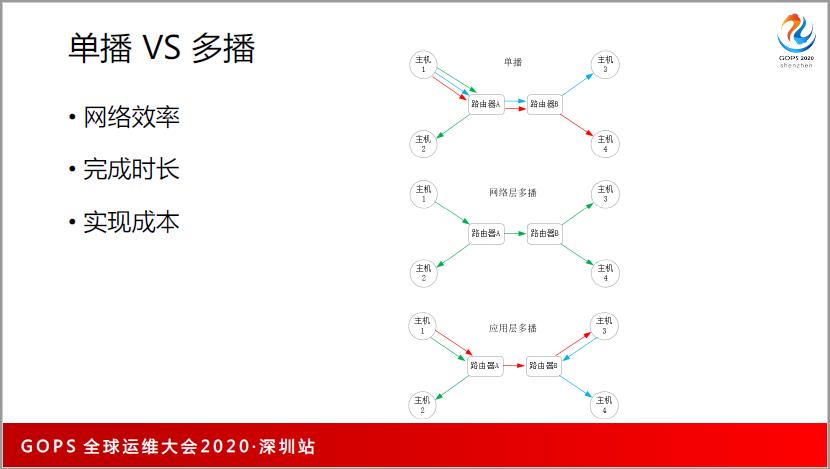
单播和多播,什么是单播?比如说主机1同时给主机2、3、4发,如果是单播就建3个TCP 连接,分别是红蓝绿。如果是网络层的多播就是这么发,比如说主机1发了以后,路由器 A 把这个报文复制了一份,一份给路由器B,一份给主机2,到路由器B以后,又复制了两份,一个给主机3,一个给主机4,所以它的网络效率应特别高。
但是它没有办法跨网络,一是安全问题,很容易造成网络风暴;二是路由器A和路由器B不是一个厂家的,很难办。所以,只在局域网内会有网络层多播( ARP 协议等)。
所以我们最好用的是应用层的多播,主机1要给2、3、4发的时候是这样发的,主机1可能成为一个中心化的节点去拉了,说先给3发,3主动去拉也可以,拉完以后,3再从中心服务器里面拉,比如说4没有,3的层面就拉给他,这里的用处很大。
在很大的集群内要发布一个几百兆的新版本,这时候如果单机向大家推,机器就打爆了,即使用10G或者是40G的外置网卡,你的下限带宽也就几个G,根本抗不住成千上万同时拉你的服务器。比如说阿里开源的蜻蜓(Dragonfly)就很好用,他只是用这个理念,怎么实现就太容易了,什么协议都能实现,用 HTTP 协议就好了,整个实践成本都会低很多。
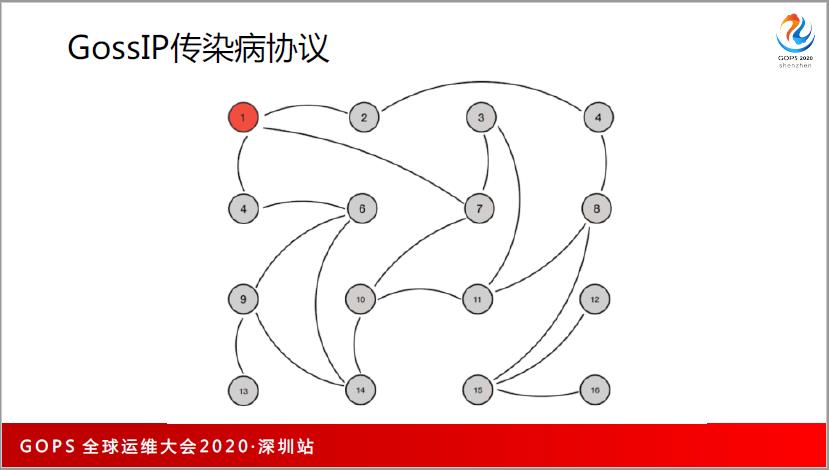
再比如说 GossIP 协议,它其实也是一个传染病协议,在 Redis 集群中管理节点都是使用GossIP 的这个协议。
三、降低请求延时
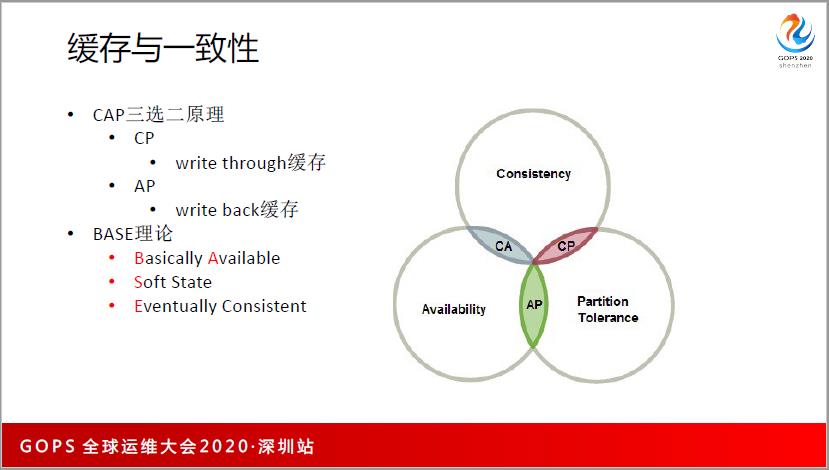
除了刚才说的读加载缓存,还有写缓存,我们知道有CAP定理,缓存一定有P,因为数据有冗余,在两台机器上都有缓存,但是关注于一致性的时候就是一个write through 方式的的缓存。AP 可能关注的是 write back 的缓存,这样单个请求的使用量会更高。
BASE 理论对缓存也有很多的用法,比如 Nginx 或 Openresty,后端挂掉了,每次访问都给返回 502 请求,你加一个东西后配 HTTP 502,它会把本来后期的缓存直接返回给客户,所以可用性也就提升了,相当于容灾了,提供了基本可用性。
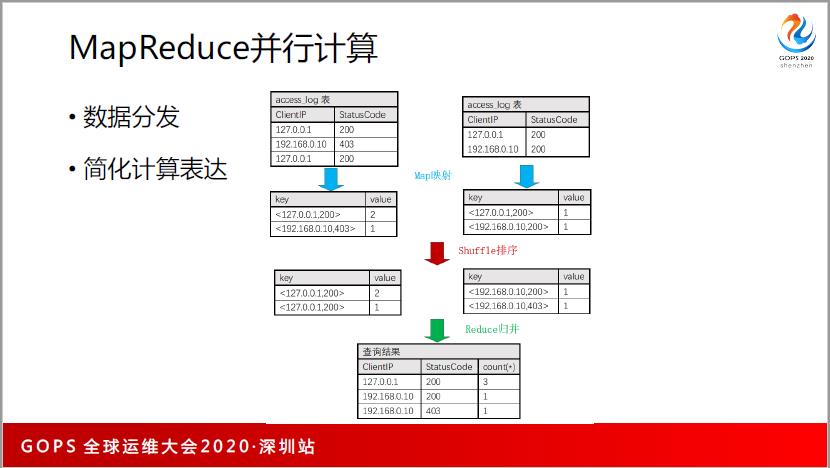
MapReduce 讲了很多,分为3步:数据分发、每个节点进行 Map 函数计算、输出以后合并。MapReduce 我们很多是在 SQL 来做,因为你用 SQL 的 Group by 的聚合计算,先天性的跟分发和规避能够对得起,无论是求标准差或者是平均值,也很容易去做并行的计算,这是可以做到的。当然如果有前后依赖关系那是没有办法做的。
MapReduce 还有一个特点,它跟数据源强相关,所以基本上 Java 生态在这块上是无敌的。原因是,大家的数据都放在中,所以数据是互联网公司的核心资产——数据都在这里,其他框架写得再好也没有用。
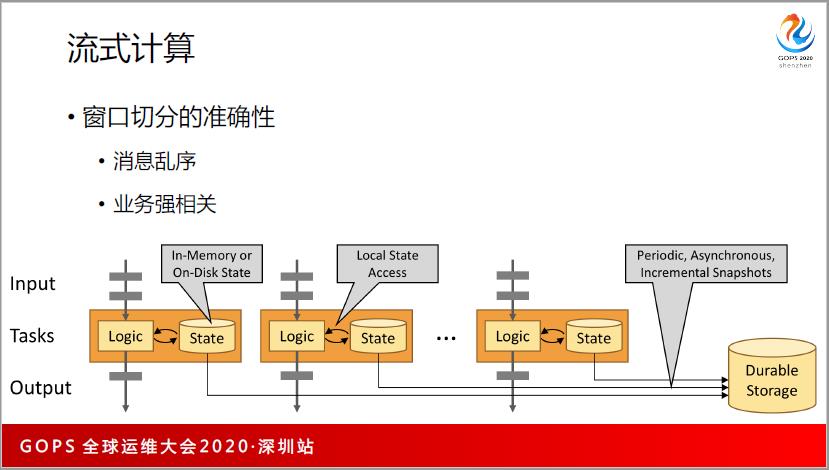
流式计算和 MapReduce 有一个很大的差别,它有时间窗口,不管你用技术的窗口,还是用时间窗口,都有时序性,但是网络报是没有时序性的,是乱序的。所以对窗口的划分是比较麻烦的。所以我们会有一个loadmark在一定程度上缓解。二是业务是强相关的,有时候窗口是固定的时间,大部分的时候可能是用户登陆的时候,它是跟 Session 强相关的情况。
四、提升系统并发
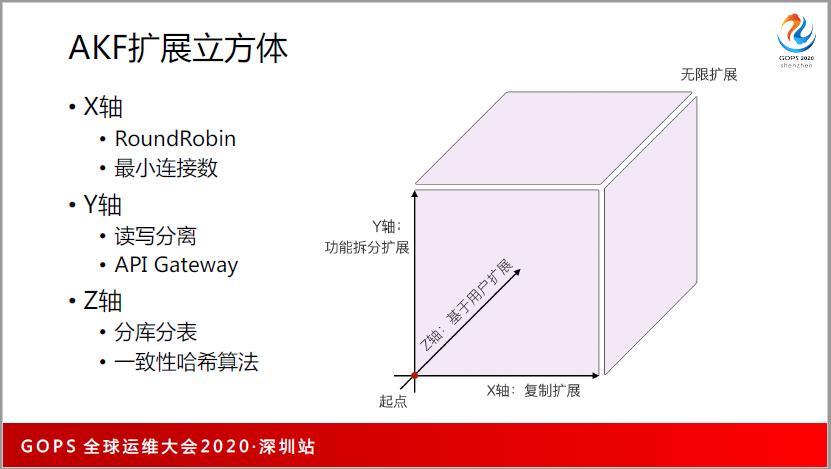
这里说一下 AKF 扩展立方体,我觉得这个东西特别的好用,所以给大家介绍一下。
比如说在 Nginx 上配了很多的上游,上游默认使用的是 RoundRobin,不管你的上游有8核16G还是4核8G的,你都会配权重,配权重似乎它俩不一样,但是任何一个请求这两台都能够处理。所以它其实是复制过来的,用最小连接数,它关注的点是上游服务器的负载。
这是X轴,X轴的成本特别低,加机器就可以。但是到了Y轴和Z轴就不一样,他们开始是基于请来。比如说 mysql
如果是一个 update,我可能就要进入主库,这就是读写分离。还有像 API Gateway 也是经常这样的,做代码重构以后,希望把用户类的、日志类的分到不同的集群去处理,这时候都是基于Y轴,Y轴的成本是非常高的。
Z轴就是分库分表,基本上是基于哈希,用户A的数据可能只能到服务器1,用户B的数据可能到服务器2。Z轴的成本不好说,比如说哈希算法,为什么说一致性哈希呢?因为你做这种基于哈希的负载均衡有很大的问题,请求的集合是近乎无限的集合,但是上游服务器的映射集合是非常有限的,有多少的服务器,你有多少个选择,就只能映射到这样的集群。
从大集群映射到小的集群,无论前面经过多少的算法,最后肯定得有求余的操作,没有求余的话,没有把它归纳到这么小的集合内。求余的话,就有一个问题,余数不能变,因为你的上游机器一旦出现宕机或者是增加的时候,余数变了,整个哈希函数就变,只要这个函数一变,那整个Z轴就会发生很大幅度的变化。
我们会使用一次性哈希,它跟哈希函数还不一样,哈希函数其实是O1复杂度的,但是一致性哈希,它不是O1复杂度,它会变成logM,它会把一个请求的关键字的信息,映射为哈希节点,哈希是32位的整型,32位整型构成了0~42亿,到42亿以后也会形成一个环,又到了0,它通过这样的有序的切分,在正常使用的时候,是是通过二分法来查找。
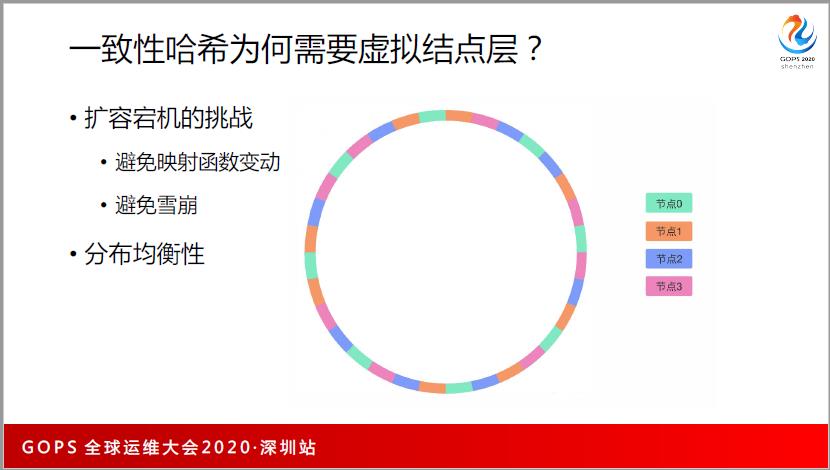
一致性哈希正常使用还是有问题,我们一般会使用虚拟节点层。为什么要使用虚拟节点层?我们要避免雪崩效果,如果上游服务器挂了,只会影响周边的节点,如果周边的节点已经达到80%的负载,这台机器所有的流量过去,它也跟着挂了,它挂了以后,下游也挂了,就全部都挂了。
我们希望的是A节点挂了以后,能让所有的节点平分流量,这是最好的,其实二次哈希就可以。所谓的虚拟节点层听起来很高大上,其实就是二次哈希。第一次哈希形成一个环,第二次哈希把这个环再做一个哈希,基本上是两层。
一般来说,我们每一层是100到200,有了这样的东西,我们避免雪崩,还有一个好处是分布的均匀性。
无论采用什么样的函数,做完以后,和你本身数据请求的分布不一致,很多的数据都很大这时候怎么解决呢?二次哈希能够使得分布更均衡。
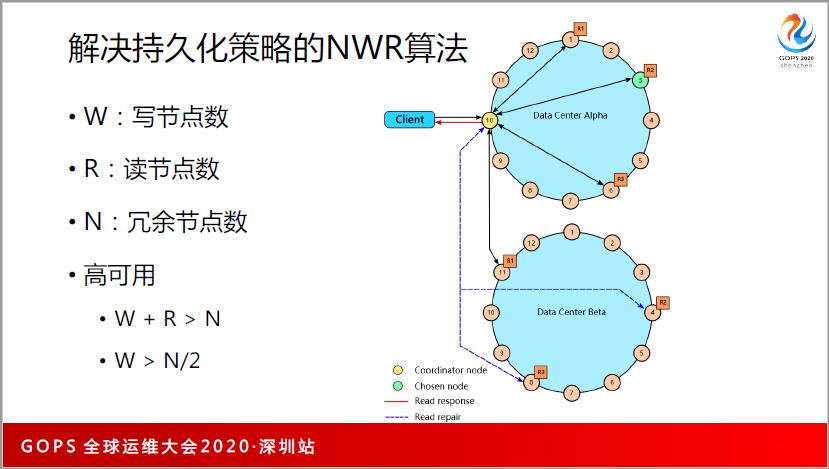
最后再说持久化,以前做持久化数据的时候,就两招,比如说一个数据有很多份冗余,就会想到两招,每次写的时候,把两台都写一遍,我写速度的性能就很差。我写的时候随便写一个,用异步的方式同步给其他的机器,一致性比较差,可能会丢数据,但是性能会比较好。到了亚马逊,零几年的时候出了一个 Quorum 论文,说了这个 NWR 算法,数据冗余份数是N,W是写节点数,R是读节点数,N是冗余节点数,所谓的高可用 W+R>N 就能实现。
W+R大于N,比如说数据有3个节点,R1R2R3,读和写,如果我们写的话,1和3返回了,2没有返回,这时候还是可以成功的。另外在读的时候,只需要读2个,一定能读到1或者是3,这个时候只要我们能够通过时间戳方式,判断谁有正确的数据,就能够保证数据的强一致性。
W大于N,本来写3个节点,现在挂了一个节点,你如果小于这个的话,比如你只有2个节点,你挂了一个节点,写就不能用了。3个节点的话,挂了一个还能用。
今天我的分享就到这里,我总结一下,从底层到高层的看法,不一定正确。
“高效运维”公众号诚邀广大技术人员投稿,
投稿邮箱:jiachen@greatops.net,或添加联系人微信:greatops1118.
以上是关于谁还不懂分布式系统性能调优,请把这篇文章甩给他~的主要内容,如果未能解决你的问题,请参考以下文章
再有人面试问你 Redis 分布式锁的实现,把这篇文章甩给他
还有人不懂分布式锁的实现就把这篇文章丢给他
再有人问你MySQL索引原理,就把这篇文章甩给他!
再有人问你Netty是啥,你就把这篇文章甩给他
面试再被问到 ConcurrentHashMap,把这篇文章甩给他!
再有人问你HashMap,把这篇文章甩给他!