Tomcat工作原理及简单模拟实现
Posted Java中文社群
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tomcat工作原理及简单模拟实现相关的知识,希望对你有一定的参考价值。
Tomcat应该都不陌生,我们经常会把写好的代码打包放在Tomcat里并启动,然后在浏览器里就能愉快的调用我们写的代码来实现相应的功能了,那么Tomcat是如何工作的?
一、Tomcat工作原理
我们启动Tomcat时双击的startup.bat文件的主要作用是找到catalina.bat,并且把参数传递给它,而catalina.bat中有这样一段话:
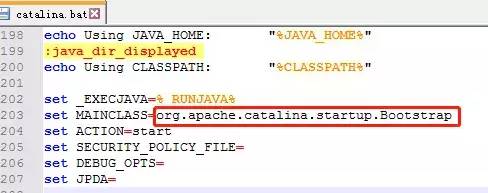
Bootstrap.class是整个Tomcat 的入口,我们在Tomcat源码里找到这个类,其中就有我们经常使用的main方法:
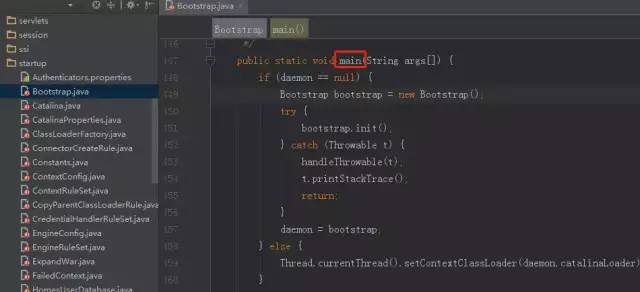
这个类有两个作用 :
初始化一个守护进程变量、加载类和相应参数;
解析命令,并执行。
源码不过多赘述,我们在这里只需要把握整体架构,有兴趣的同学可以自己研究下源码。Tomcat的server.xml配置文件中可以对应构架图中位置,多层的表示可以配置多个:
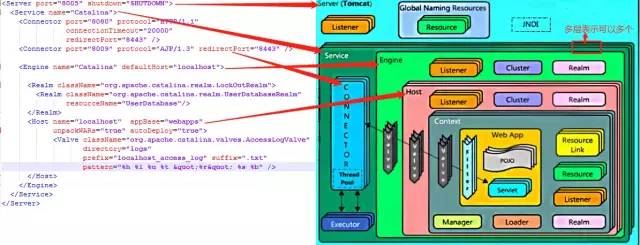
即一个由 Server->Service->Engine->Host->Context 组成的结构,从里层向外层分别是:
Server:服务器Tomcat的顶级元素,它包含了所有东西。
Service:一组 Engine(引擎) 的集合,包括线程池 Executor 和连接器 Connector 的定义。
Engine(引擎):一个 Engine代表一个完整的 Servlet引擎,它接收来自Connector的请求,并决定传给哪个Host来处理。
Container(容器):Host、Context、Engine和Wraper都继承自Container接口,它们都是容器。
Connector(连接器):将Service和Container连接起来,注册到一个Service,把来自客户端的请求转发到Container。
Host:即虚拟主机,所谓的”一个虚拟主机”可简单理解为”一个网站”。
Context(上下文 ): 即 Web 应用程序,一个 Context 即对于一个 Web 应用程序。
Context容器直接管理Servlet的运行,Servlet会被其给包装成一个StandardWrapper类去运行。Wrapper负责管理一个Servlet的装载、初始化、执行以及资源回收,它是最底层容器。
比如现在有以下网址,根据“/”切割的链接就会定位到具体的处理逻辑上,且每个容器都有过滤功能。

二、Tomcat实现思路
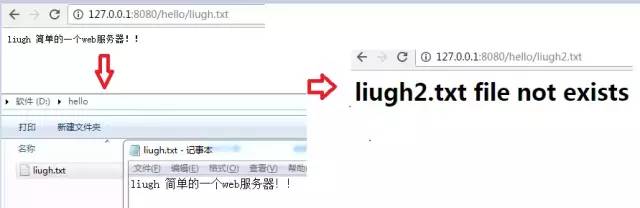
实现以上效果整体思路如下:
1.ServerSocket占用8080端口,用while(true)循环等待用户发请求。
3.读取文件,不存在构建响应报文头、html正文内容,存在则写到浏览器端。
三、实现Tomcat
工程文件结构和pom.xml文件:
1.HttpServer核心处理类,用于接受用户请求,传递HTTP请求头信息,关闭容器:
public class HttpServer {
// 用于判断是否需要关闭容器
private boolean shutdown = false;
public void acceptWait() {
ServerSocket serverSocket = null;
try {
serverSocket = new ServerSocket(8080, 1, InetAddress.getByName("127.0.0.1"));
}
catch (IOException e) {
e.printStackTrace();
System.exit(1);
}
// 等待用户发请求
while (!shutdown) {
try {
Socket socket = serverSocket.accept();
InputStream is = socket.getInputStream();
OutputStream os = socket.getOutputStream();
// 接受请求参数
Request request = new Request(is);
request.parse();
// 创建用于返回浏览器的对象
Response response = new Response(os);
response.setRequest(request);
response.sendStaticResource();
//关闭一次请求的socket,因为http请求就是采用短连接的方式
socket.close();
if(null != request){
shutdown = request.getUrL().equals("/shutdown");
}
}
catch (Exception e) {
e.printStackTrace();
continue;
}
}
}
public static void main(String[] args) {
HttpServer server = new HttpServer();
server.acceptWait();
}
}
public class Request {
private InputStream is;
private String url;
public Request(InputStream input) {
this.is = input;
}
public void parse() {
//从socket中读取一个2048长度字符
StringBuffer request = new StringBuffer(Response.BUFFER_SIZE);
int i;
byte[] buffer = new byte[Response.BUFFER_SIZE];
try {
i = is.read(buffer);
}
catch (IOException e) {
e.printStackTrace();
i = -1;
}
for (int j=0; j<i; j++) {
request.append((char) buffer[j]);
}
//打印读取的socket中的内容
System.out.print(request.toString());
url = parseUrL(request.toString());
}
private String parseUrL(String requestString) {
int index1, index2;
index1 = requestString.indexOf(' ');//看socket获取请求头是否有值
if (index1 != -1) {
index2 = requestString.indexOf(' ', index1 + 1);
if (index2 > index1)
return requestString.substring(index1 + 1, index2);
}
return null;
}
public String getUrL() {
return url;
}
}
3.创建Response类,响应请求读取文件并写回到浏览器
public class Response {
public static final int BUFFER_SIZE = 2048;
//浏览器访问D盘的文件
private static final String WEB_ROOT ="D:";
private Request request;
private OutputStream output;
public Response(OutputStream output) {
this.output = output;
}
public void setRequest(Request request) {
this.request = request;
}
public void sendStaticResource() throws IOException {
byte[] bytes = new byte[BUFFER_SIZE];
FileInputStream fis = null;
try {
//拼接本地目录和浏览器端口号后面的目录
File file = new File(WEB_ROOT, request.getUrL());
//如果文件存在,且不是个目录
if (file.exists() && !file.isDirectory()) {
fis = new FileInputStream(file);
int ch = fis.read(bytes, 0, BUFFER_SIZE);
while (ch!=-1) {
output.write(bytes, 0, ch);
ch = fis.read(bytes, 0, BUFFER_SIZE);
}
}else {
//文件不存在,返回给浏览器响应提示,这里可以拼接HTML任何元素
String retMessage = "<h1>"+file.getName()+" file or directory not exists</h1>";
String returnMessage ="HTTP/1.1 404 File Not Found " +
"Content-Type: text/html " +
"Content-Length: "+retMessage.length()+" " +
" " +
retMessage;
output.write(returnMessage.getBytes());
}
}
catch (Exception e) {
System.out.println(e.toString() );
}
finally {
if (fis!=null)
fis.close();
}
}
}
四、扩展点
1.在WEB_INF文件夹下读取web.xml解析,通过请求名找到对应的类名,通过类名创建对象,用反射来初始化配置信息,如welcome页面,Servlet、servlet-mapping,filter,listener,启动加载级别等。
2.抽象Servlet类来转码处理请求和响应的业务。发过来的请求会有很多,也就意味着我们应该会有很多的Servlet,例如:RegisterServlet、LoginServlet等等还有很多其他的访问。可以用到类似于工厂模式的方法处理,随时产生很多的Servlet,来满足不同的功能性的请求。
3.使用多线程。本文的代码是死循环,且只能有一个链接,而现实中的情况是往往会有很多很多的客户端发请求,可以把每个浏览器的通信封装到一个线程当中。
近期热门文章
以上是关于Tomcat工作原理及简单模拟实现的主要内容,如果未能解决你的问题,请参考以下文章