BACK TO SCHOOL:Tomcat设计思路
Posted 洋葱头务虚谈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BACK TO SCHOOL:Tomcat设计思路相关的知识,希望对你有一定的参考价值。
“洋葱头务虚谈”
本期由“PPT做的比演讲好的”DD同学带来的技术分享主题《Tomcat设计思路》。
· 正 · 文 · 来 · 啦 ·
如果你和我一样选择了 Java Web 开发这个方向,并且正在学习和提高的路上,可能这篇分享对你有一定用处。如果不是,那就当学习一下设计思路吧。

让我们先来简单回顾一下 Web 技术的发展历史,可以帮助你理解 Web 容器的由来。
早期的 Web 应用主要用于浏览新闻等静态页面,HTTP 服务器(比如 Apache、nginx)向浏览器返回静态 html,浏览器负责解析 HTML,将结果呈现给用户。
随着互联网的发展,我们已经不满足于仅仅浏览静态页面,还希望通过一些交互操作,来获取动态结果,因此也就需要一些扩展机制能够让 HTTP 服务器调用服务端程序。
于是 Sun 公司推出了 Servlet 技术。你可以把 Servlet 简单理解为运行在服务端的 Java 小程序,但是 Servlet 没有 main 方法,不能独立运行,因此必须把它部署到 Servlet 容器中,由容器来实例化并调用 Servlet。
而 Tomcat 和 Jetty 就是一个 Servlet 容器。为了方便使用,它们也具有 HTTP 服务器的功能,因此 Tomcat 或者 Jetty 就是一个“HTTP 服务器 + Servlet 容器”,我们也叫它们 Web 容器。
其他应用服务器比如 JBoss 和 WebLogic,它们不仅仅有 Servlet 容器的功能,也包含 EJB 容器,是完整的 Java EE 应用服务器。从这个角度看,Tomcat 和 Jetty 算是一个轻量级的应用服务器。


先来看看B和C。
由于 HTTP是无状态的协议,为了识别请求是哪个用户发过来的,出现了Cookie和Session技术。
Cookie本质上就是一份存储在用户本地的文件,里面包含了每次请求中都需要传递的信息;
Session可以理解为服务器端开辟的存储空间,里面保存的信息用于保持状态。
作为 Web容器,Tomcat负责创建和管理Session,并提供了多种持久化方案来存储Session。
请你来看下面这张图,我们过一遍一次 HTTP 的请求过程。
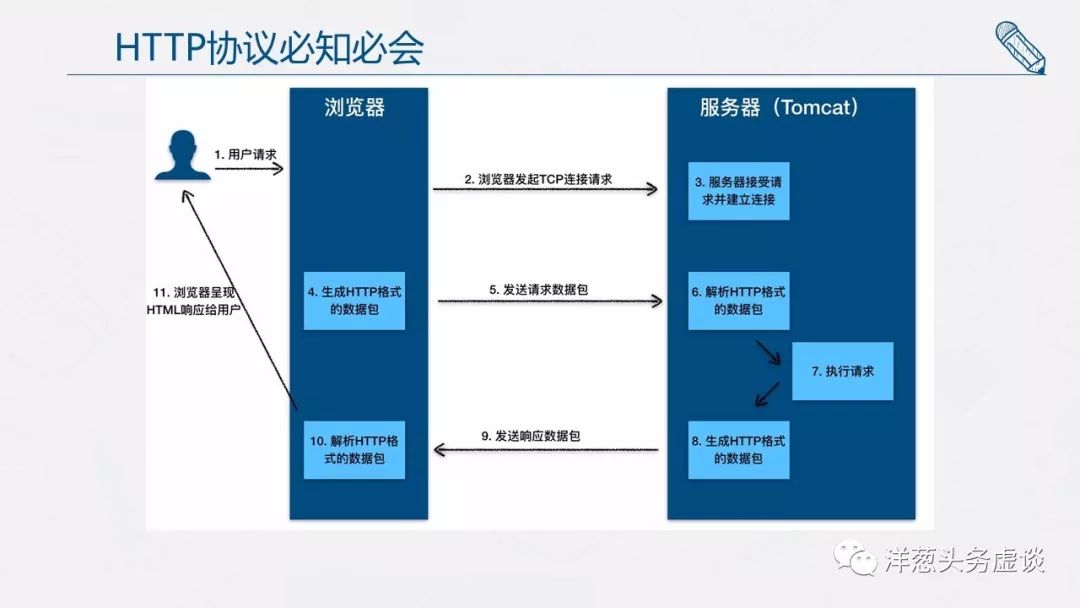
从图上你可以看到,这个过程是:
1. 用户通过浏览器进行了一个操作,比如输入网址并回车,或者是点击链接,接着浏览器获取了这个事件。
2. 浏览器向服务端发出 TCP 连接请求。
3. 服务程序接受浏览器的连接请求,并经过 TCP 三次握手建立连接。
4. 浏览器将请求数据打包成一个 HTTP 协议格式的数据包。
5. 浏览器将该数据包推入网络,数据包经过网络传输,最终达到端服务程序。
6. 服务端程序拿到这个数据包后,同样以 HTTP 协议格式解包,获取到客户端的意图。
7. 得知客户端意图后进行处理,比如提供静态文件或者调用服务端程序获得动态结果。
8. 服务器将响应结果(可能是 HTML 或者图片等)按照 HTTP 协议格式打包。
9. 服务器将响应数据包推入网络,数据包经过网络传输最终达到到浏览器。
10. 浏览器拿到数据包后,以 HTTP 协议的格式解包,然后解析数据,假设这里的数据是 HTML。
11. 浏览器将 HTML 文件展示在页面上。

浏览器发给服务端的是一个 HTTP 格式的请求,HTTP 服务器收到这个请求后,需要调用服务端程序来处理,所谓的服务端程序就是你写的 Java 类,一般来说不同的请求需要由不同的 Java 类来处理。
那么问题来了,HTTP 服务器怎么知道要调用哪个 Java 类的哪个方法呢。最直接的做法是在 HTTP 服务器代码里写一大堆 if else 逻辑判断:如果是 A 请求就调 X 类的 M1 方法,如果是 B 请求就调 Y 类的 M2 方法。但这样做明显有问题,因为 HTTP 服务器的代码跟业务逻辑耦合在一起了,如果新加一个业务方法还要改 HTTP 服务器的代码。
那该怎么解决这个问题呢?我们知道,面向接口编程是解决耦合问题的法宝,于是有一伙人就定义了一个接口,各种业务类都必须实现这个接口,这个接口就叫 Servlet 接口,有时我们也把实现了 Servlet 接口的业务类叫作 Servlet。
但是这里还有一个问题,对于特定的请求,HTTP 服务器如何知道由哪个 Servlet 来处理呢?Servlet 又是由谁来实例化呢?显然 HTTP 服务器不适合做这个工作,否则又和业务类耦合了。
于是,还是那伙人又发明了 Servlet 容器,Servlet 容器用来加载和管理业务类。HTTP 服务器不直接跟业务类打交道,而是把请求交给 Servlet 容器去处理,Servlet 容器会将请求转发到具体的 Servlet,如果这个 Servlet 还没创建,就加载并实例化这个 Servlet,然后调用这个 Servlet 的接口方法。因此 Servlet 接口其实是 Servlet 容器跟具体业务类之间的接口 。下面我们通过一张图来加深理解。
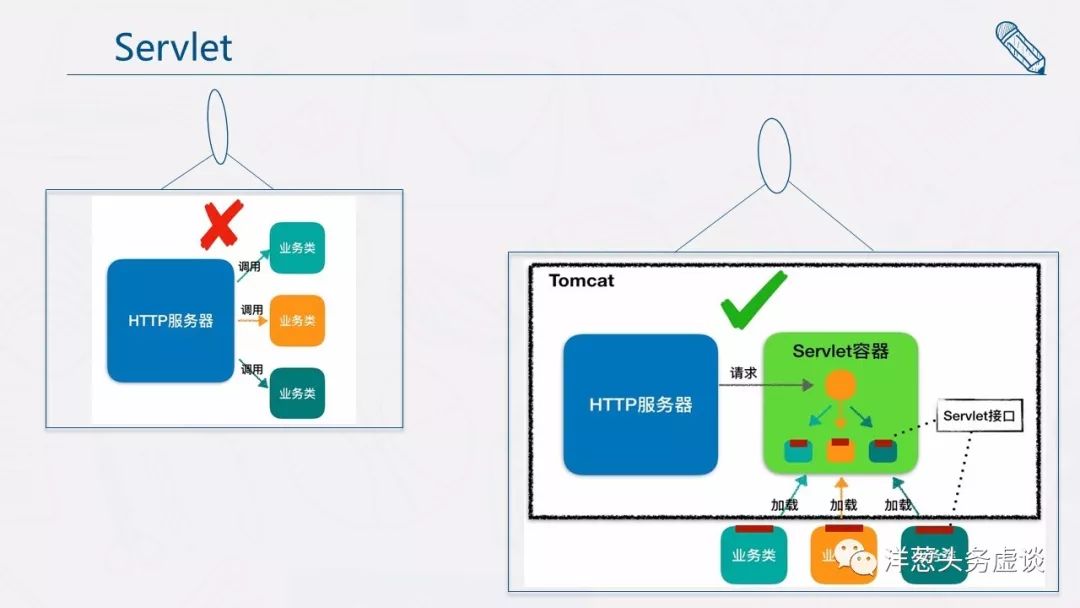
图的左边表示 HTTP 服务器直接调用具体业务类,它们是紧耦合的。再看图的右边,HTTP 服务器不直接调用业务类,而是把请求交给容器来处理,容器通过 Servlet 接口调用业务类。因此 Servlet 接口和 Servlet 容器的出现,达到了 HTTP 服务器与业务类解耦的目的。
而 Servlet 接口和 Servlet 容器这一整套规范叫作 Servlet 规范。Tomcat 和 Jetty 都按照 Servlet 规范的要求实现了 Servlet 容器,同时它们也具有 HTTP 服务器的功能。作为 Java 程序员,如果我们要实现新的业务功能,只需要实现一个 Servlet,并把它注册到 Tomcat(Servlet 容器)中,剩下的事情就由 Tomcat 帮我们处理了。

我们知道如果要设计一个系统,首先是要了解需求。我们已经了解了 Tomcat 要实现 2 个核心功能:
处理 Socket 连接,负责网络字节流与 Request 和 Response 对象的转化。
加载和管理 Servlet,以及具体处理 Request 请求。
因此 Tomcat 设计了两个核心组件连接器(Connector)和容器(Container)来分别做这两件事情。连接器负责对外交流,容器负责内部处理。
Tomcat 为了实现支持多种 I/O 模型和应用层协议,一个容器可能对接多个连接器,就好比一个房间有多个门。但是单独的连接器或者容器都不能对外提供服务,需要把它们组装起来才能工作,组装后这个整体叫作 Service 组件。这里请你注意,Service 本身没有做什么重要的事情,只是在连接器和容器外面多包了一层,把它们组装在一起。Tomcat 内可能有多个 Service,这样的设计也是出于灵活性的考虑。通过在 Tomcat 中配置多个 Service,可以实现通过不同的端口号来访问同一台机器上部署的不同应用。
到此我们得到这样一张关系图:
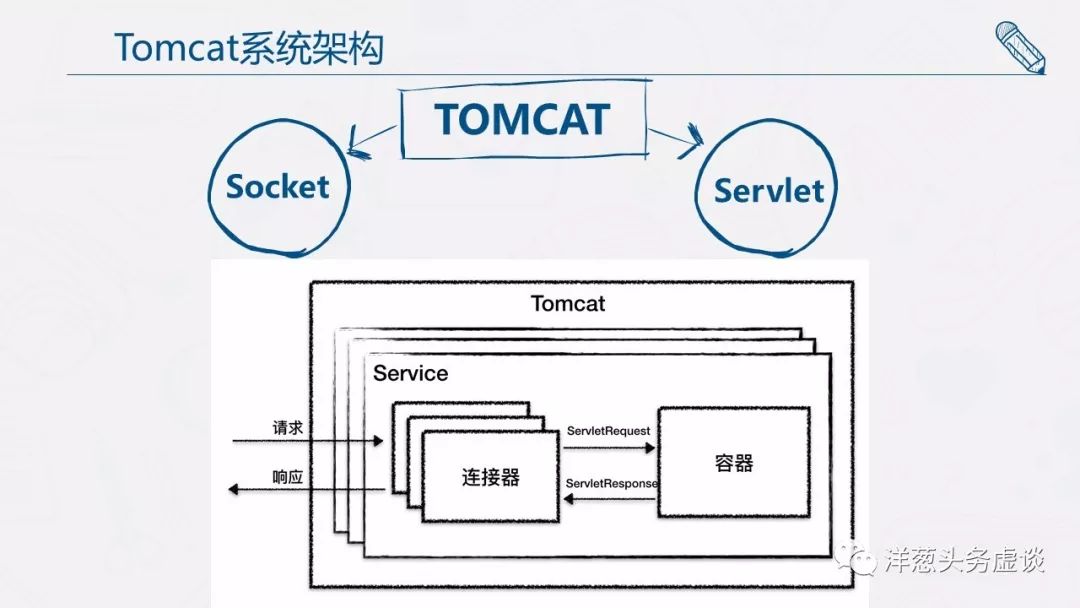
连接器对 Servlet 容器屏蔽了协议及 I/O 模型等的区别,无论是 HTTP 还是 AJP,在容器中获取到的都是一个标准的 ServletRequest 对象。
我们可以把连接器的功能需求进一步细化,比如:
监听网络端口。
接受网络连接请求。
读取请求网络字节流。
根据具体应用层协议(HTTP/AJP)解析字节流,生成统一的 Tomcat Request 对象。
将 Tomcat Request 对象转成标准的 ServletRequest。
调用 Servlet 容器,得到 ServletResponse。
将 ServletResponse 转成 Tomcat Response 对象。
将 Tomcat Response 转成网络字节流。
将响应字节流写回给浏览器。
需求列清楚后,我们要考虑的下一个问题是,连接器应该有哪些子模块?优秀的模块化设计应该考虑 高内聚、低耦合 。
高内聚 是指相关度比较高的功能要尽可能集中,不要分散。
低耦合 是指两个相关的模块要尽可能减少依赖的部分和降低依赖的程度,不要让两个模块产生强依赖。
通过分析连接器的详细功能列表,我们发现连接器需要完成 3 个 高内聚 的功能:
网络通信。
应用层协议解析。
Tomcat Request/Response 与 ServletRequest/ServletResponse 的转化。

因此 Tomcat 的设计者设计了 3 个组件来实现这 3 个功能,分别是 EndPoint、Processor 和 Adapter。
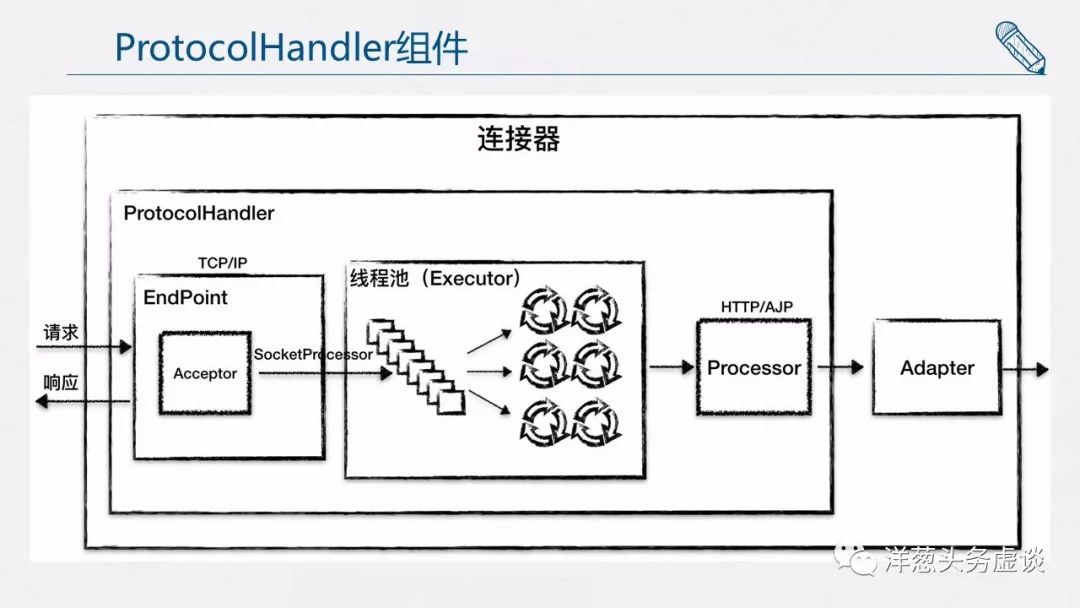
小结一下,连接器模块用三个核心组件:Endpoint、Processor 和 Adapter 来分别做三件事情,其中 Endpoint 和 Processor 放在一起抽象成了 ProtocolHandler 组件,它们的关系如下图所示。
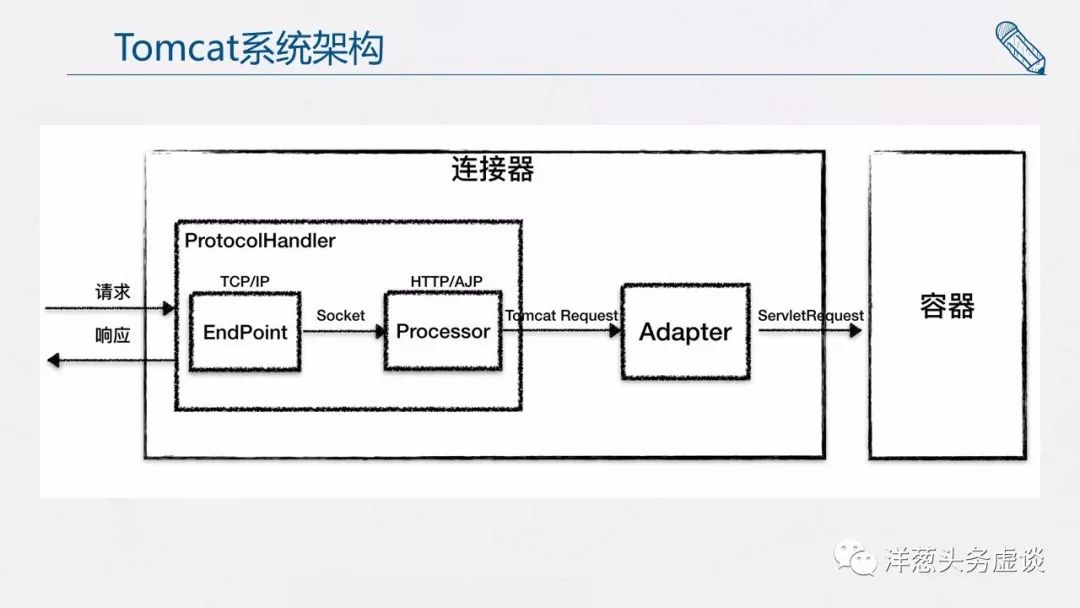
由上文我们知道,连接器用 ProtocolHandler 来处理网络连接和应用层协议,包含了 2 个重要部件:EndPoint 和 Processor,下面我来详细介绍它们的工作原理。
EndPoint
EndPoint 是通信端点,即通信监听的接口,是具体的 Socket 接收和发送处理器,是对传输层的抽象,因此 EndPoint 是用来实现 TCP/IP 协议的。
EndPoint 是一个接口,对应的抽象实现类是 AbstractEndpoint,而 AbstractEndpoint 的具体子类,比如在 NioEndpoint 和 Nio2Endpoint 中,有两个重要的子组件:Acceptor 和 SocketProcessor。
其中 Acceptor 用于监听 Socket 连接请求。SocketProcessor 用于处理接收到的 Socket 请求,它实现 Runnable 接口,在 Run 方法里调用协议处理组件 Processor 进行处理。为了提高处理能力,SocketProcessor 被提交到线程池来执行。而这个线程池叫作执行器(Executor)。
Processor
如果说 EndPoint 是用来实现 TCP/IP 协议的,那么 Processor 用来实现 HTTP 协议,Processor 接收来自 EndPoint 的 Socket,读取字节流解析成 Tomcat Request 和 Response 对象,并通过 Adapter 将其提交到容器处理,Processor 是对应用层协议的抽象。
Processor 是一个接口,定义了请求的处理等方法。它的抽象实现类 AbstractProcessor 对一些协议共有的属性进行封装,没有对方法进行实现。具体的实现有 AJPProcessor、HTTP11Processor 等,这些具体实现类实现了特定协议的解析方法和请求处理方式。
我们再来看看连接器的组件图:
我在前面说过,由于协议不同,客户端发过来的请求信息也不尽相同,Tomcat 定义了自己的 Request 类来“存放”这些请求信息。ProtocolHandler 接口负责解析请求并生成 Tomcat Request 类。但是这个 Request 对象不是标准的 ServletRequest,也就意味着,不能用 Tomcat Request 作为参数来调用容器。Tomcat 设计者的解决方案是引入 CoyoteAdapter,这是适配器模式的经典运用,连接器调用 CoyoteAdapter 的 Sevice 方法,传入的是 Tomcat Request 对象,CoyoteAdapter 负责将 Tomcat Request 转成 ServletRequest,再调用容器的 Service 方法。

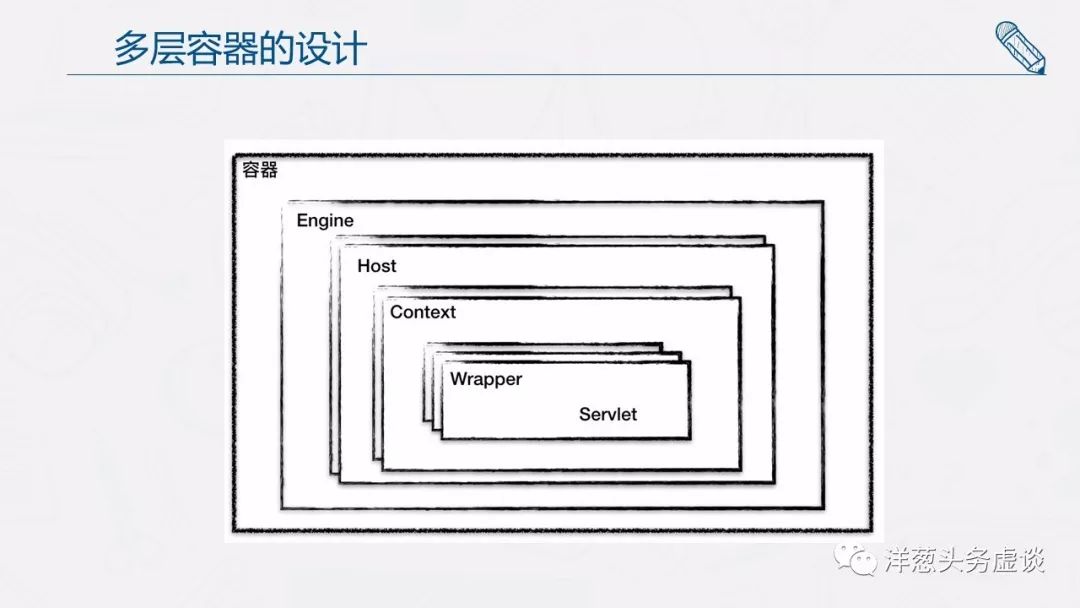
容器的层次结构
Tomcat 设计了 4 种容器,分别是 Engine、Host、Context 和 Wrapper。这 4 种容器不是平行关系,而是父子关系。
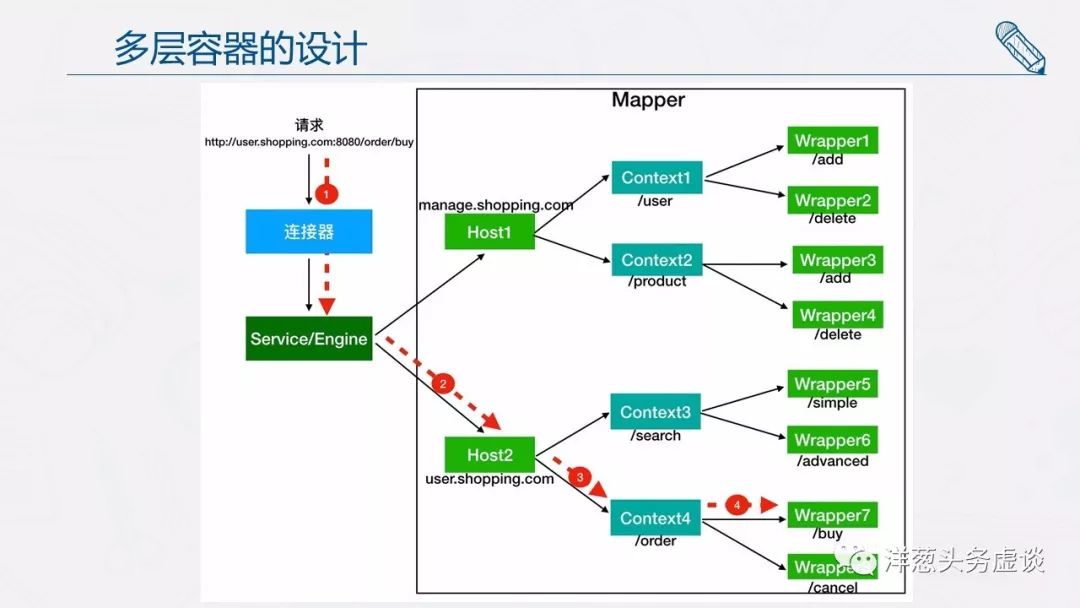
Tomcat 是怎么确定请求是由哪个 Wrapper 容器里的 Servlet 来处理的呢?答案是,Tomcat 是用 Mapper 组件来完成这个任务的。
Mapper 组件的功能就是将用户请求的 URL 定位到一个 Servlet,它的工作原理是:Mapper 组件里保存了 Web 应用的配置信息,其实就是 容器组件与访问路径的映射关系 ,比如 Host 容器里配置的域名、Context 容器里的 Web 应用路径,以及 Wrapper 容器里 Servlet 映射的路径,你可以想象这些配置信息就是一个多层次的 Map。
当一个请求到来时,Mapper 组件通过解析请求 URL 里的域名和路径,再到自己保存的 Map 里去查找,就能定位到一个 Servlet。请你注意,一个请求 URL 最后只会定位到一个 Wrapper 容器,也就是一个 Servlet。
读到这里你可能感到有些抽象,接下来我通过一个例子来解释这个定位的过程。
假如有一个网购系统,有面向网站管理人员的后台管理系统,还有面向终端客户的在线购物系统。这两个系统跑在同一个 Tomcat 上,为了隔离它们的访问域名,配置了两个虚拟域名:manage.shopping.com
和 user.shopping.com,网站管理人员通过 manage.shopping.com域名访问 Tomcat 去管理用户和商品,而用户管理和商品管理是两个单独的 Web 应用。终端客户通过 user.shopping.com域名去搜索商品和下订单,搜索功能和订单管理也是两个独立的 Web 应用。
针对这样的部署,Tomcat 会创建一个 Service 组件和一个 Engine 容器组件,在 Engine 容器下创建两个 Host 子容器,在每个 Host 容器下创建两个 Context 子容器。由于一个 Web 应用通常有多个 Servlet,Tomcat 还会在每个 Context 容器里创建多个 Wrapper 子容器。每个容器都有对应的访问路径,你可以通过下面这张图来帮助你理解。
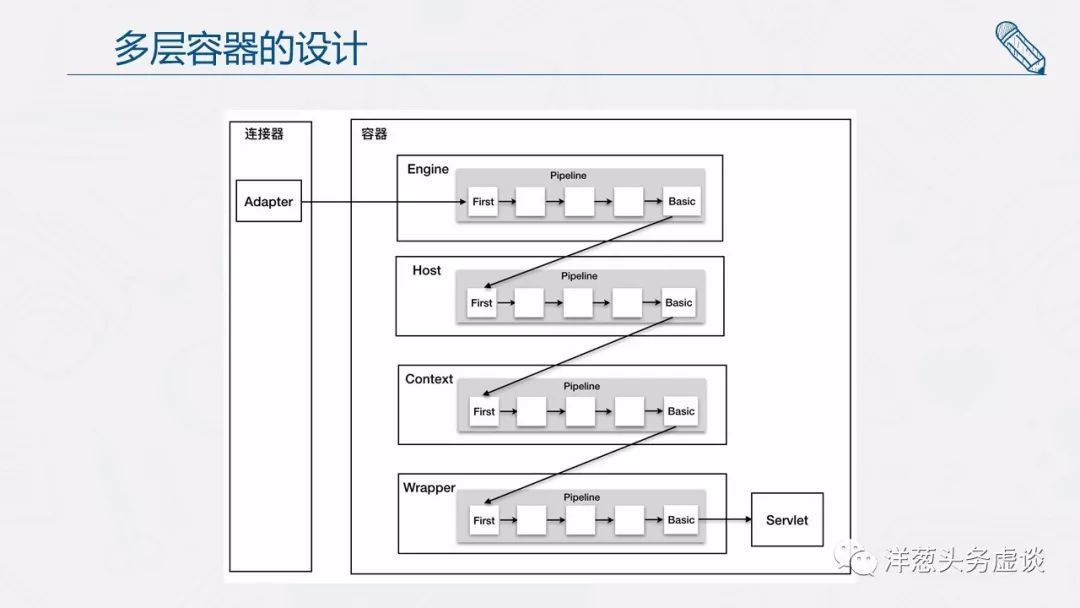
连接器中的 Adapter 会调用容器的 Service 方法来执行 Servlet,最先拿到请求的是 Engine 容器,Engine 容器对请求做一些处理后,会把请求传给自己子容器 Host 继续处理,依次类推,最后这个请求会传给 Wrapper 容器,Wrapper 会调用最终的 Servlet 来处理。那么这个调用过程具体是怎么实现的呢?答案是使用 Pipeline-Valve 管道。
Pipeline-Valve 是责任链模式,责任链模式是指在一个请求处理的过程中有很多处理者依次对请求进行处理,每个处理者负责做自己相应的处理,处理完之后将再调用下一个处理者继续处理。
每一个容器都有一个 Pipeline 对象,只要触发这个 Pipeline 的第一个 Valve,这个容器里 Pipeline 中的 Valve 就都会被调用到。但是,不同容器的 Pipeline 是怎么链式触发的呢,比如 Engine 中 Pipeline 需要调用下层容器 Host 中的 Pipeline。
这是因为 Pipeline 中还有个 getBasic 方法。这个 BasicValve 处于 Valve 链表的末端,它是 Pipeline 中必不可少的一个 Valve,负责调用下层容器的 Pipeline 里的第一个 Valve。
Tomcat如何扩展Java线程池?
你可以看到其中的两个关键点:
Tomcat 有自己的定制版任务队列和线程工厂,并且可以限制任务队列的长度,它的最大长度是 maxQueueSize。
Tomcat 对线程数也有限制,设置了核心线程数(minSpareThreads)和最大线程池数(maxThreads)。

除了资源限制以外,Tomcat 线程池还定制自己的任务处理流程。我们知道 Java 原生线程池的任务处理逻辑比较简单:
前 corePoolSize 个任务时,来一个任务就创建一个新线程。
后面再来任务,就把任务添加到任务队列里让所有的线程去抢,如果队列满了就创建临时线程。
如果总线程数达到 maximumPoolSize, 执行拒绝策略。
Tomcat 线程池扩展了原生的 ThreadPoolExecutor,通过重写 execute 方法实现了自己的任务处理逻辑:
前 corePoolSize 个任务时,来一个任务就创建一个新线程。
再来任务的话,就把任务添加到任务队列里让所有的线程去抢,如果队列满了就创建临时线程。
如果总线程数达到 maximumPoolSize, 则继续尝试把任务添加到任务队列中去。
如果缓冲队列也满了,插入失败,执行拒绝策略。
观察 Tomcat 线程池和 Java 原生线程池的区别,其实就是在第 3 步,Tomcat 在线程总数达到最大数时,不是立即执行拒绝策略,而是再尝试向任务队列添加任务,添加失败后再执行拒绝策略。
Tomcat 线程池的 execute 方法会调用 Java 原生线程池的 execute 去执行任务,如果总线程数达到 maximumPoolSize,Java 原生线程池的 execute 方法会抛出 RejectedExecutionException 异常,但是这个异常会被 Tomcat 线程池的 execute 方法捕获到,并继续尝试把这个任务放到任务队列中去;如果任务队列也满了,再执行拒绝策略。

本次BACK TO SCHOOL到此结束。
以上是关于BACK TO SCHOOL:Tomcat设计思路的主要内容,如果未能解决你的问题,请参考以下文章
8.24-8.31 Back-to-School Gift:7% off rs07 gp for Fossil Island
论文阅读:Bringing Old Photos Back to Life
UVA - 11175 From D to E and Back(思路)
There was a period when i hated to go to school .这里的period 前面为啥用a ,还有为...