mysql 解决可提交读、可重复读、幻读
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql 解决可提交读、可重复读、幻读相关的知识,希望对你有一定的参考价值。
参考技术A 这张图本人觉得总结得挺好的,在一般的互联网项目中,基本上用的都是Innodb引擎,一般只涉及到的都是行级锁,但是如果sql语句中不带索引进行操作,可能会导致锁表,这是不推荐的,性能非常低,可能会导致全表扫描等,行锁的具体实现算法有以下几种mysql特有的锁:Record Lock(记录锁):单个行记录的锁,一般是唯一索引或者主键上的加锁
Gap Lock(间隙锁):锁定一个区间,但是不包括自身,开区间的锁,RR级别才会有间隙锁,间隙锁的唯一目的是防止区间数据的插入,所以间隙锁与间隙锁之间是不会相互阻塞的
Next-key Lock(临键锁):与间隙锁的区别是包括自身,是左开右闭区间,RR级别才会有
加锁规则里面,包含了两个“原则”、两个“优化”和一个“bug”。
原则 1:加锁的基本单位是 next-key lock,希望你还记得,next-key lock 是前开后闭区间。
原则 2:查找过程中访问到的对象才会加锁。
优化 1:索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁。
优化 2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。
一个 bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止。
举例来说明上述的原则:
建表
插入数据:
INSERT INTO t ( id , c , d ) VALUES (0, 0, 0);
INSERT INTO t ( id , c , d ) VALUES (5, 5, 10);
INSERT INTO t ( id , c , d ) VALUES (10, 10, 10);
INSERT INTO t ( id , c , d ) VALUES (15, 15, 15);
INSERT INTO t ( id , c , d ) VALUES (20, 20, 20);
INSERT INTO t ( id , c , d ) VALUES (25, 25, 25);
例子1:锁表
因为d字段上没有建索引,所以涉及该字段的查询加锁会锁住整个表
因为d字段上面没有建立索引,所以事务1执行后会导致整个表被锁,后面所有的操作都会在等待整个表锁被释放
例子2:主键/唯一索引 记录锁
id字段为主键,而且事务1查询命中了唯一的记录,默认是加Next-key Lock,区间是(0,5],但是根据优化1,唯一索引/主键上的等值查询,会退化为行锁,所以只会锁5这个记录。
例子3:主键/唯一索引上的间隙锁
由于表 t 中没有 id=7 的记录,所以用我们上面提到的加锁规则判断一下的话:根据原则 1,加锁单位是 next-key lock,事务1加锁范围就是 (5,10];同时根据优化 2,这是一个等值查询 (id=7),而 id=10 不满足查询条件,next-key lock 退化成间隙锁,因此最终加锁的范围是 (5,10),所以事务2会阻塞,事务3执行成功。
例子4:普通索引上的间隙锁
c字段是普通索引,事务1执行时默认是对区间(0,5]加间隙锁,根据优化2,非唯一索引/主键会继续向右遍历,找到10,所以最终的加锁为(0,5]的Next-Key锁+(5,10)的间隙锁,所以事务2阻塞,事务3成功。
例子5:间隙锁与行锁
事务1默认的Next-Key锁区间是(0,5],根据优化2会向右遍历,找到不满足查询条件的10,退化成间隙锁,所以事务1的锁是(0,5]的Next-Key锁+(5,10)的间隙锁,这两个锁与行锁是冲突的,而事务2申请的Next-Key锁是和事务1一样,但是c=5的行锁与事务1冲突,所以产生了阻塞,如果改为update t set d=1000 where c=6;因为此时产生的间隙锁为(5,10),而间隙锁与间隙锁是不冲突的,不会产生阻塞
例子6:lock in share mode锁覆盖索引
事务1存在覆盖索引的情况,不会去回表,lock in share mode这种情况下只会锁c字段索引,而事务2是对主键加行锁,所以两者不存在冲突。
例子7:主键/唯一索引上的范围查询
开始执行的时候,要找到第一个 id=10 的行,因此本该是 Next-Key Lock(5,10],根据优化 1, 主键 id 上的等值条件,退化成行锁,只加了 id=10 这一行的行锁。范围查找就往后继续找,找到 id=15 这一行停下来,因此需要加 Next-Key Lock(10,15],所以事务3是冲突的。
例子8:普通索引上的范围查询
开始执行时,找到第一个满足条件的行10,加锁Next-Key Lock(5,10],因为不是唯一索引,所以不会退化,继续向后面找,找到15这一行停下来,因此需要加 Next-Key Lock(10,15],因为是范围查询,所以锁不会退化。
快照读: 通过MVCC实现,该技术不仅可以保证innodb的可重复读,而且可以防止幻读,但是他读取的数据虽然是一致的,但是数据是历史数据。
简单的select操作(不包括 select … lock in share mode, select … for update)
当前读: 要做到保证数据是一致的,同时读取的数据是最新的数据,innodb提供了next-key lock,即gap锁与行锁结合来实现。
select … lock in share mode
select … for update
insert
update
delete
自己理解:
简单的select是快照读,快照读实现可提交读,可重复读和幻读是通过MVCC+ReadView实现的,而当前读实现这几种是通过锁来实现的,为了说明具体原理,下面介绍下MVCC和ReadView概念,所以简单的select是通过乐观锁实现的,当前读是通过悲观锁实现的。
参考文章:
https://www.sohu.com/a/302045871_411876
https://www.jianshu.com/p/d1aba64b5c03
https://www.jianshu.com/p/32904ee07e56
MySQL 可重复读隔离级别,解决幻读了吗?
MySQL 可重复读隔离级别,解决幻读了吗?

接下来,通过几个小实验来证明这个结论吧,顺便再帮大家复习一下记录锁+间隙锁。
什么是幻读?
首先来看看 MySQL 文档是怎么定义幻读(Phantom Read)的:
The so-called phantom problem occurs within a transaction when the same query produces different sets of rows at different times. For example, if a SELECT is executed twice, but returns a row the second time that was not returned the first time, the row is a “phantom” row.
翻译:当同一个查询在不同的时间产生不同的结果集时,事务中就会出现所谓的幻象问题。例如,如果 SELECT 执行了两次,但第二次返回了第一次没有返回的行,则该行是“幻像”行。
举个例子,假设一个事务在 T1 时刻和 T2 时刻分别执行了下面查询语句,途中没有执行其他任何语句:
SELECT * FROM t_test WHERE id > 100;
只要 T1 和 T2 时刻执行产生的结果集是不相同的,那就发生了幻读的问题,比如:
- T1 时间执行的结果是有 5 条行记录,而 T2 时间执行的结果是有 6 条行记录,那就发生了幻读的问题。
- T1 时间执行的结果是有 5 条行记录,而 T2 时间执行的结果是有 4 条行记录,也是发生了幻读的问题。
MySQL 是怎么解决幻读的?
MySQL 可重复读隔离级别是解决幻读问题,查询数据的操作有两种方式,所以解决的方式是不同的:
- 针对快照读(普通 select 语句),是通过 MVCC 方式解决了幻读,因为可重复读隔离级别下,事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,即使中途有其他事务插入了一条数据,是查询不出来这条数据的,所以就很好了避免幻读问题。
- 针对当前读(select … for update 等语句),是通过 next-key lock(记录锁+间隙锁)方式解决了幻读,因为当执行 select … for update 语句的时候,会加上 next-key lock,如果有其他事务在 next-key lock 锁范围内插入了一条记录,那么这个插入语句就会被阻塞,无法成功插入,所以就很好了避免幻读问题。
实验验证
接下来,来验证「 MySQL 记录锁+间隙锁可以防止删除操作而导致的幻读问题」的结论。
实验环境:MySQL 8.0 版本,可重复读隔离级。
现在有一张用户表(t_user),表里只有一个主键索引,表里有以下行数据:
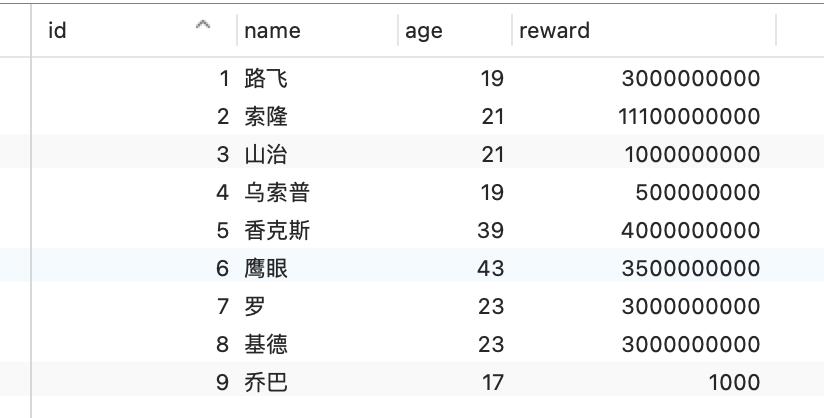
现在有一个 A 事务执行了一条查询语句,查询到年龄大于 20 岁的用户共有 6 条行记录。
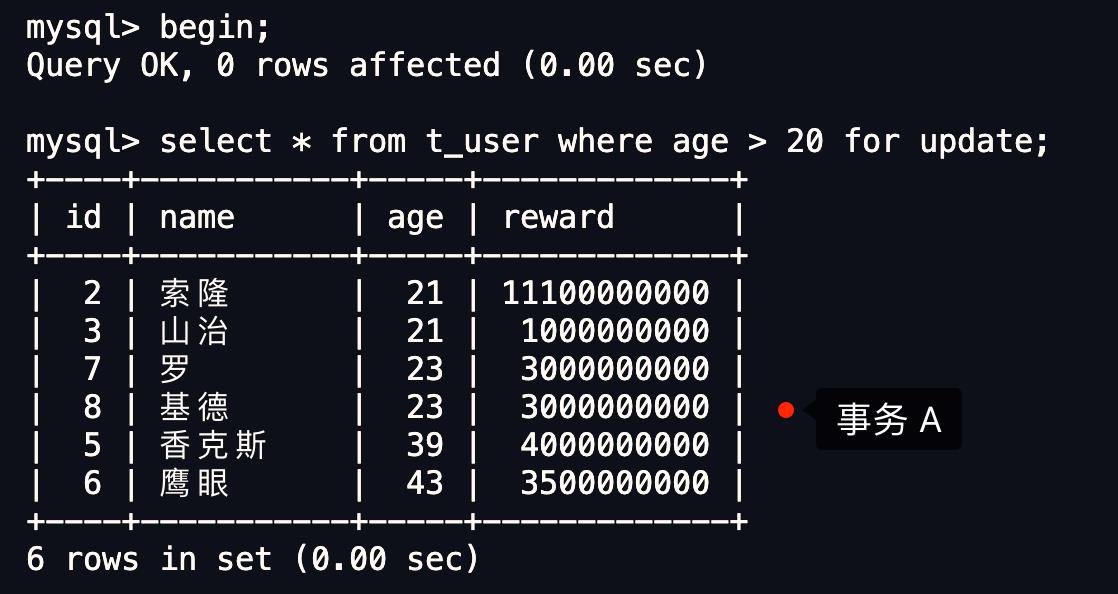
然后, B 事务执行了一条删除 id = 2 的语句:

此时,B 事务的删除语句就陷入了等待状态,说明是无法进行删除的。
因此,MySQL 记录锁+间隙锁可以防止删除操作而导致的幻读问题。
加锁分析
问题来了,A 事务在执行 select … for update 语句时,具体加了什么锁呢?
我们可以通过 select * from performance_schema.data_locks\\G; 这条语句,查看事务执行 SQL 过程中加了什么锁。
输出的内容很多,共有 11 行信息,我删减了一些不重要的信息:
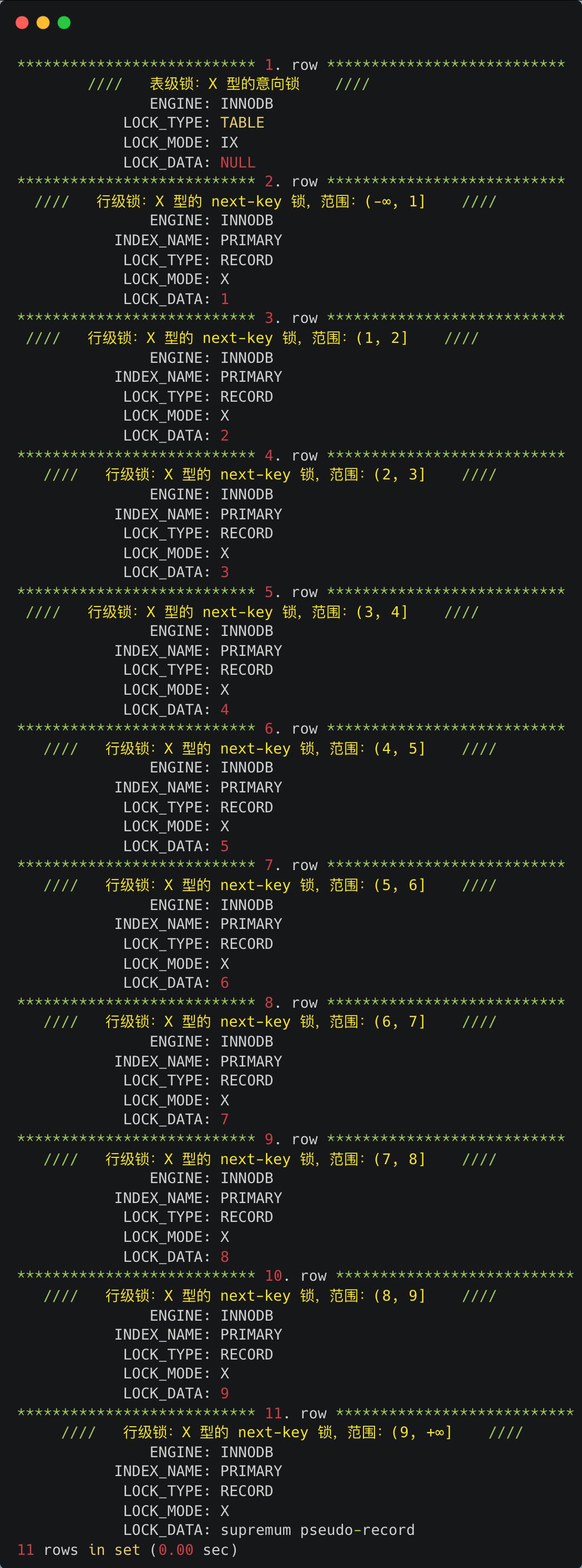
从上面输出的信息可以看到,共加了两种不同粒度的锁,分别是:
- 表锁(
LOCK_TYPE: TABLE):X 类型的意向锁; - 行锁(
LOCK_TYPE: RECORD):X 类型的 next-key 锁;
这里我们重点关注「行锁」,图中 LOCK_TYPE 中的 RECORD 表示行级锁,而不是记录锁的意思:
- 如果 LOCK_MODE 为
X,说明是 next-key 锁; - 如果 LOCK_MODE 为
X, REC_NOT_GAP,说明是记录锁; - 如果 LOCK_MODE 为
X, GAP,说明是间隙锁;
然后通过 LOCK_DATA 信息,可以确认 next-key 锁的范围,具体怎么确定呢?
- 根据我的经验,如果 LOCK_MODE 是 next-key 锁或者间隙锁,那么 LOCK_DATA 就表示锁的范围最右值,而锁范围的最左值为 LOCK_DATA 的上一条记录的值。
因此,此时事务 A 在主键索引(INDEX_NAME : PRIMARY)上加了 10 个 next-key 锁,如下:
- X 型的 next-key 锁,范围:(-∞, 1]
- X 型的 next-key 锁,范围:(1, 2]
- X 型的 next-key 锁,范围:(2, 3]
- X 型的 next-key 锁,范围:(3, 4]
- X 型的 next-key 锁,范围:(4, 5]
- X 型的 next-key 锁,范围:(5, 6]
- X 型的 next-key 锁,范围:(6, 7]
- X 型的 next-key 锁,范围:(7, 8]
- X 型的 next-key 锁,范围:(8, 9]
- X 型的 next-key 锁,范围:(9, +∞]
这相当于把整个表给锁住了,其他事务在对该表进行增、删、改操作的时候都会被阻塞。
只有在事务 A 提交了事务,事务 A 执行过程中产生的锁才会被释放。
为什么只是查询年龄 20 岁以上行记录,而把整个表给锁住了呢?
这是因为事务 A 的这条查询语句是全表扫描,锁是在遍历索引的时候加上的,并不是针对输出的结果加锁。

因此,在线上在执行 update、delete、select … for update 等具有加锁性质的语句,一定要检查语句是否走了索引,如果是全表扫描的话,会对每一个索引加 next-key 锁,相当于把整个表锁住了,这是挺严重的问题。
如果对 age 建立索引,事务 A 这条查询会加什么锁呢?
接下来,我对 age 字段建立索引,然后再执行这条查询语句:
接下来,继续通过 select * from performance_schema.data_locks\\G; 这条语句,查看事务执行 SQL 过程中加了什么锁。
具体的信息,我就不打印了,我直接说结论吧。
因为表中有两个索引,分别是主键索引和 age 索引,所以会分别对这两个索引加锁。
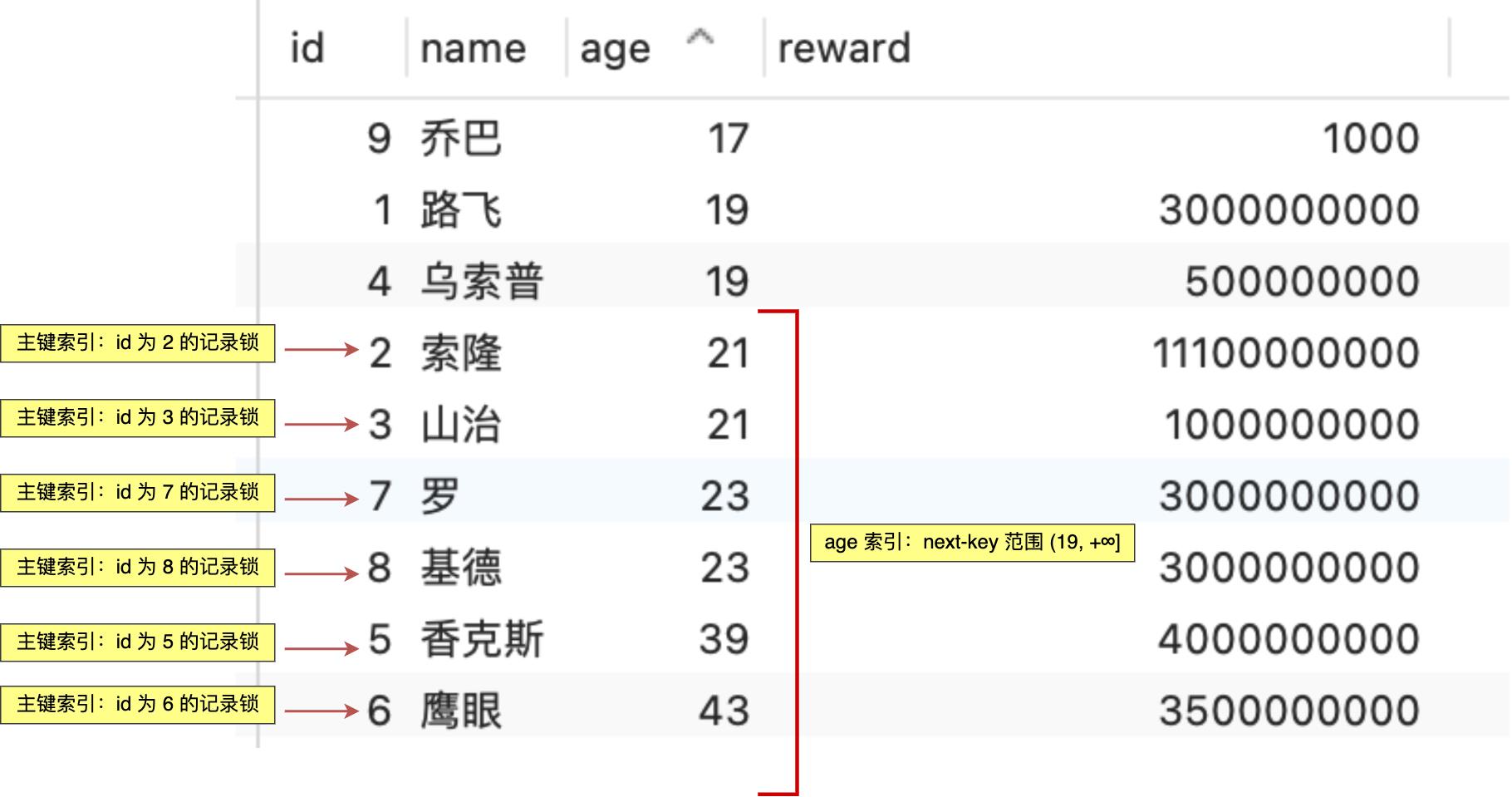
主键索引会加如下的锁:
- X 型的记录锁,锁住 id = 2 的记录;
- X 型的记录锁,锁住 id = 3 的记录;
- X 型的记录锁,锁住 id = 5 的记录;
- X 型的记录锁,锁住 id = 6 的记录;
- X 型的记录锁,锁住 id = 7 的记录;
- X 型的记录锁,锁住 id = 8 的记录;
分析 age 索引加锁的范围时,要先对 age 字段进行排序。
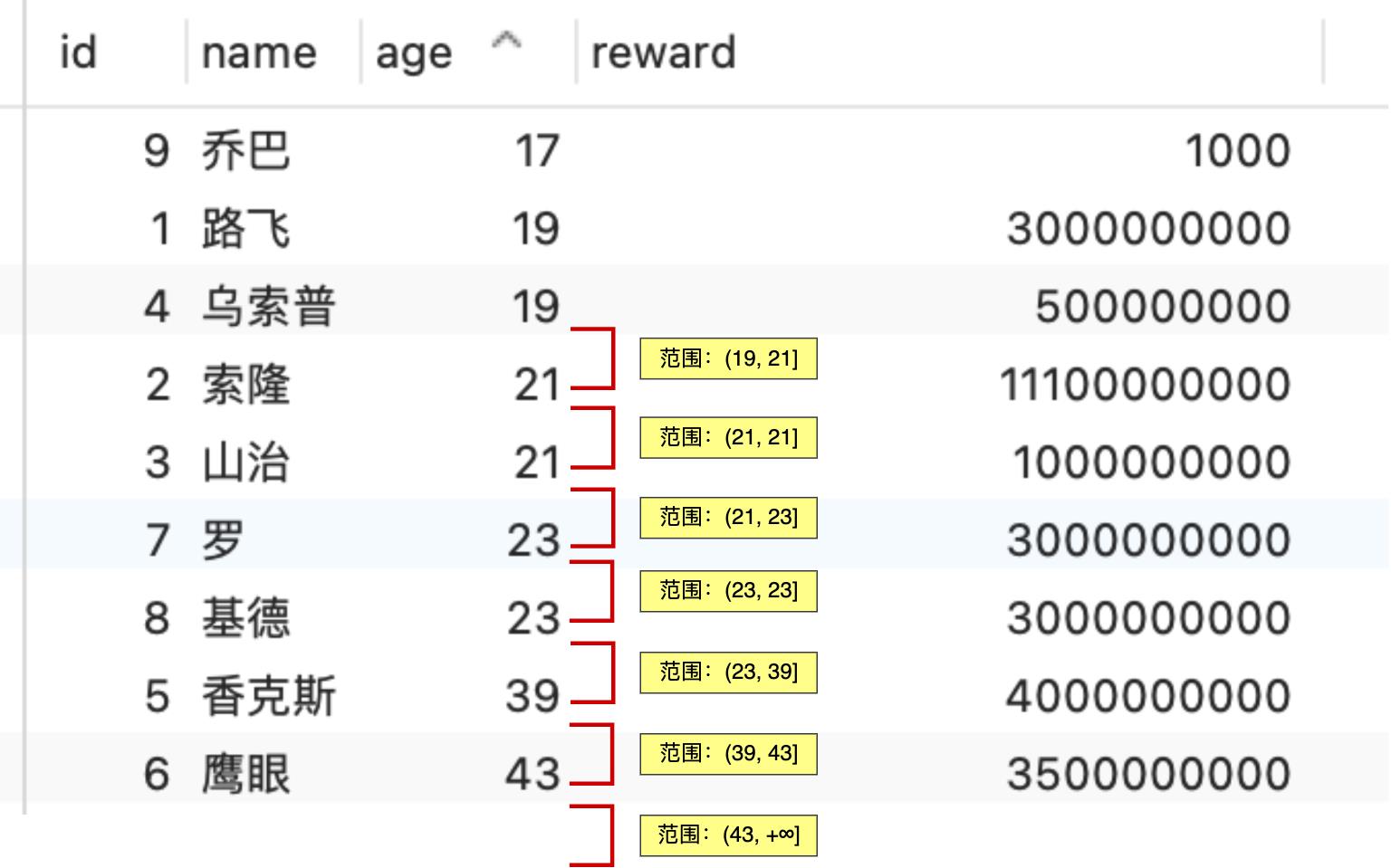
age 索引加的锁:
- X 型的 next-key lock,锁住 age 范围 (19, 21] 的记录;
- X 型的 next-key lock,锁住 age 范围 (21, 21] 的记录;
- X 型的 next-key lock,锁住 age 范围 (21, 23] 的记录;
- X 型的 next-key lock,锁住 age 范围 (23, 23] 的记录;
- X 型的 next-key lock,锁住 age 范围 (23, 39] 的记录;
- X 型的 next-key lock,锁住 age 范围 (39, 43] 的记录;
- X 型的 next-key lock,锁住 age 范围 (43, +∞] 的记录;
化简一下,age 索引 next-key 锁的范围是 (19, +∞]。
可以看到,对 age 字段建立了索引后,查询语句是索引查询,并不会全表扫描,因此不会把整张表给锁住。

总结一下,在对 age 字段建立索引后,事务 A 在执行下面这条查询语句后,主键索引和 age 索引会加下图中的锁。
事务 A 加上锁后,事务 B、C、D、E 在执行以下语句都会被阻塞。
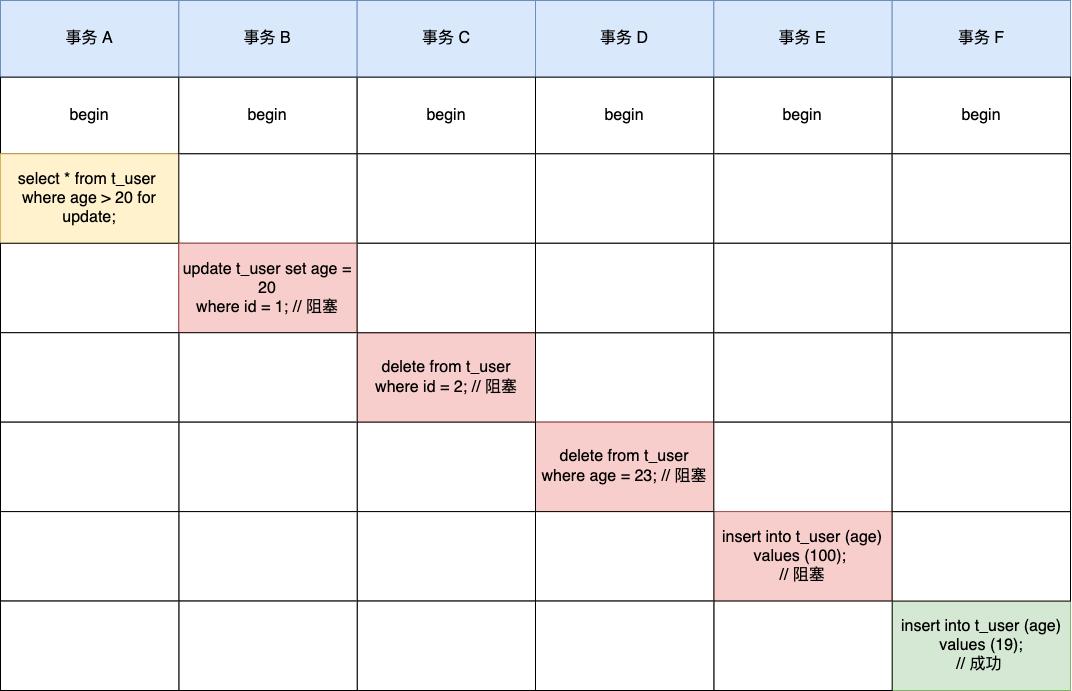
总结
在 MySQL 的可重复读隔离级别下,针对当前读的语句会对索引加记录锁+间隙锁,这样可以避免其他事务执行增、删、改时导致幻读的问题。
有一点要注意的是,在执行 update、delete、select … for update 等具有加锁性质的语句,一定要检查语句是否走了索引,如果是全表扫描的话,会对每一个索引加 next-key 锁,相当于把整个表锁住了,这是挺严重的问题。
完!
以上是关于mysql 解决可提交读、可重复读、幻读的主要内容,如果未能解决你的问题,请参考以下文章