什么库可以模拟客户端请求网页访问过程
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么库可以模拟客户端请求网页访问过程相关的知识,希望对你有一定的参考价值。
参考技术A Python。使用python模仿人为访问网站主要有以下几个方面:
1、请求发送访问后,服务器接收到的最直接的感觉就是请求了,所以,首先请求头要和浏览器的请求一样,目前主要是User-Agent、Host、Referer等。
2、请求频率,机器的访问速度一定是比人的请求速度快的多,如果你一秒有几十条请求的话,系统会分辨你是一个爬虫,可以使程序休息一会等方式。
3、cookie,用户访问网站时是伴随着cookie的,cookie中保存着登陆信息等,这种可以使用session来实现。
4、资源请求,当访问一个页面时,一般不会是一个只有一个html文件,同时伴随着一些资源的请求,比如css,jpg,json等,而爬虫一般不会把这些资源全部请求,当然可以使用浏览器自动化控制模块(selenium等)来实现操控浏览器来请求。
5、验证码等,有些页面会伴随着验证码,使用验证码来判定访问者是一个人还是机器。
爬虫-认识爬虫
爬虫 - 认识爬虫
什么是上网?爬虫要做的是什么?
我们所谓的上网便是由用户端计算机发送请求给目标计算机,将目标计算机的数据下载到本地的过程。
用户获取网络数据的方式是: 浏览器提交请求->下载网页代码->解析/渲染成页面。
而爬虫程序要做的就是: 模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中
定义
通过编写程序,模拟浏览器上网,向网站发起请求,让其去互联网上获取数据后分析并提取有用数据的程序爬虫的基本流程
"""
1、发起请求
使用http库向目标站点发起请求,即发送一个Request Request包含:请求头、请求体等
2、获取响应内容
如果服务器能正常响应,则会得到一个Response Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以b的方式写入文件
4、保存数据
数据库 文件
"""请求与响应
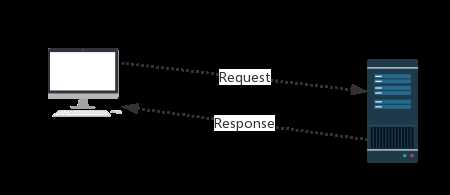
http协议:https://home.cnblogs.com/u/waller/
Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
Response:服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)
ps:浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
Request
1.请求方式:
常用的请求方式:GET,POST
其他请求方式:HEAD,PUT,DELETE,OPTHONS'''
post与get请求最终都会拼接成这种形式:k1=xxx&k2=yyy&k3=zzz
post请求的参数放在请求体内:
可用浏览器查看,存放于form data内
get请求的参数直接放在url后
'''2.请求的url
url全称统一资源定位符,如一个网页文档,一张图片
一个视频等都可以用url唯一来确定'''
url编码
https://www.baidu.com/s?wd=图片
图片会被编码(看示例代码)
'''
'''
网页的加载过程是:
加载一个网页,通常都是先加载document文档,
在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求
'''3、请求头
User-Agent:请求头中如果没有user-agent客户端配置,
服务端可能将你当做一个非法用户
host
cookies:cookie用来保存登录信息'''
一般做爬虫都会加上请求头
'''4.请求体
如果是get方式,请求体没有内容
如果是post方式,请求体是format data'''
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
'''Response
1、响应状态
200:代表成功
301:代表跳转
404:文件不存在
403:权限
502:服务器错误2、Respone header
set-cookie:可能有多个,是来告诉浏览器,把cookie保存下来3、preview就是网页源代码
最主要的部分,包含了请求资源的内容
如网页html,图片
二进制数据等爬虫分类
- 1 通用爬虫: 获取一整张页面数据
- 2 聚焦爬虫: 获取指定页面内的指定数据
- 3 增量式爬虫: 用来检测网站数据的更新情况,爬取网站最新更新出来的数据
"攻" 与 "防"
"攻":反爬机制
网站采用相关的技术手段或策略阻止爬虫程序对网站数据的爬取
- UA检测: 服务器通过对请求中的请求头里的UA的值,来判定请求载体的身份# robots协议 (君子协议)
通常用在门户网站中,声明了哪些数据可爬,哪些数据不可爬
eg:
https://www.taobao.com/robots.txt"防":反反爬策略
让爬虫程序通过破解反爬机制获取数据
# ps: 网站不同策略不同,需要分析一般使用到的头信息:
请求头
- User-Agent : 请求载体的身份标识
载体: 浏览器, 爬虫程序
- Connection : keep-alive | close
close : 当用爬虫请求成功后,这个请求对应的连接会立刻断开
响应头
- content-type : 数据响应方式, 服务器按对应方式响应数据补充
http协议: client与server进行数据交互的一种规定形式
https协议: 安全的http协议,在http基础之上加了一个安全层的操作(ssl加密)
- 对称秘钥加密:(不安全)
加密数据级密规则(私钥)发送到服务端破解
- 非对称秘钥加密:(效率低, 不安全:客户端拿到的公钥不一定是服务端的)
服务器端制定加密方式(公钥)和解密方式(私钥),客户端获取公钥加密数据再传输
- 证书秘钥加密:
公钥 -> 证书机构 -> 添加证书 -> 客户端 -> 加密数据 -> 服务端ps: 爬虫仅仅是工具,无好坏之分
以上是关于什么库可以模拟客户端请求网页访问过程的主要内容,如果未能解决你的问题,请参考以下文章