MySQL日志
Posted 爱玩大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL日志相关的知识,希望对你有一定的参考价值。
mysql系列:
简介
MySQL中有六种日志文件:重做日志(redo log)、回滚日志(undo log)、二进制日志(binary log)、错误日志(error log)、慢查询日志(slow query log)、一般查询日志(general log),中继日志(relay log)。本篇主要介绍和事务相关的redo,undo,binlog这三种日志类型,帮助更好的理解MySQL中的事务操作。
Redo Log:https://dev.mysql.com/doc/refman/8.0/en/innodb-redo-log.html
重做日志(Redo Log)
介绍
当对数据做修改的时候,需要把数据页从磁盘读到buffer pool中,然后在buffer pool中进行修改,此时buffer pool中的数据页与磁盘上的数据页内容不一致,称buffer pool中的数据页为dirty page(脏页),如果此时发生非正常的数据库服务重启,这部分修改后的数据还在内存中,并没有持久化到磁盘文件中,就会导致数据丢失,于是就引入了redo log(重做日志),当buffer pool 中的数据页发生变更时,把相应修改记录到redo log中,当非正常重启数据库服务的时候,可以根据此文件的记录内容,重新应用到磁盘文件,保持数据一致。
同步到磁盘文件是随机IO,效率低;
记录日志是顺序IO,能够提升事务处理的速度;
redo log(重做日志) : 用于记录事务变化的日志,记录变化后的值,不管事务是否提交都会记录下来。是InnoDB 存储引擎级别的日志。
redo log包括两部分:一是内存中的日志缓冲(redo log buffer),该部分日志是易失性的;二是磁盘上的重做日志文件(redo log file),该部分日志是持久的。
相关参数
innodb_log_files_in_group:redo log 文件的个数。命名方式如:ib_logfile0,iblogfile1... iblogfilen。默认2个,最大100个;
innodb_log_file_size:每个redo log文件大小,默认值为 5M。总的redo log文件最大值(innodb_log_files_in_group * innodb_log_file_size )为512G;
innodb_log_group_home_dir:redo log 文件存放路径;
innodb_log_buffer_size:redo log buffer缓冲区大小,默认8M,可设置1-8M。
innodb_flush_log_at_trx_commit:redo log buffer 的刷新到磁盘的时机,三种配置0,1,2;
0:由master 线程周期性任务刷新(下面具体介绍)。
1:在事务 commit 时,fsync写入磁盘文件。
2:在事务 commit 时,将 redo log buffer写入到文件系统缓存(file system buffer),由系统内部来fsync到磁盘文件。如果数据库实例crash,不会丢失redo log,但是如果服务器crash,由于文件系统缓存还来不及fsync到磁盘文件,所以会丢失这一部分的数据。
存在形式
redo log文件是固定大小的,在上面提到有两个参数可以设置它的个数和每个的最大容量,命名方式为:ib_logfile0,iblogfile1... iblogfilen。按照序号从头开始写,写到末尾就又回到开头循环写。
注意:redo log file的大小对innodb的性能影响非常大,设置的越大,恢复的时候时间就会越长;设置的越小,就会导致在写redo log的时候循环切换redo log file。
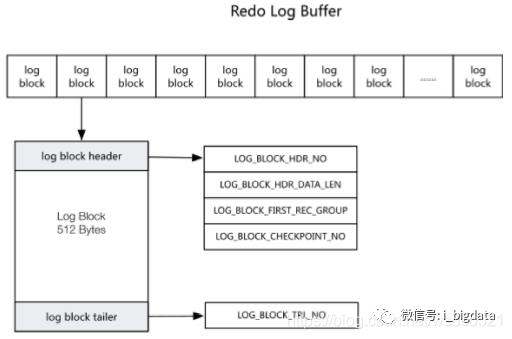
redo log以块为单位进行存储的,每个块占512字节,称为redo log block。(redo log buffer、file system buffer以及redo log file中,都是以512字节的块存储的),每个redo log block由3部分组成:日志块头、日志块尾和日志主体。其中日志块头占用12字节,日志块尾占用8字节,日志主体部分占用512-12-8=492字节。
日志块头包含四个部分:
log_block_hdr_no:(4字节)该日志块在redo log buffer中的位置ID。
log_block_hdr_data_len:(2字节)该log block中已记录的log大小。写满该log block时为0x200,表示512字节。
log_block_first_rec_group:(2字节)该log block中第一个log的开始偏移位置。
lock_block_checkpoint_no:(4字节)写入检查点信息的位置。
日志块尾只有一个部分: log_block_trl_no ,该值和块头的 log_block_hdr_no 相等;
日志主体的格式分为四个部分:
redo_log_type:占用1个字节,表示redo log的日志类型。
space:表示表空间的ID,采用压缩的方式后,占用的空间可能小于4字节。
page_no:表示页的偏移量,同样是压缩过的。
redo_log_body:表示每个重做日志的数据部分,恢复时会调用相应的函数进行解析。
例:insert语句和delete语句写入redo log的内容是不一样的:
持久化方式
redo log的持久化:
在开启事务时就会产生redo log,但不是立刻写入到redo log文件内,而是先写入redo log buffer中(redo log buffer中未刷到磁盘的日志称为脏日志(dirty log)),然后再将 redo log buffer 中的数据根据下面的策略写入到磁盘中的redo log文件内:
MySQL master 线程周期性任务:每秒一次,将 redo log buffer 刷新到磁盘(即使这个事务尚未提交)
MySQL master 线程周期性任务:每10秒一次;
redo log buffer size:缓冲区剩余空间(innodb_log_buffer_size参数)小于1/2时;
redo log file:磁盘中的redo log文件大小已经达到设置的阈值(innodb_log_files_in_group * innodb_log_file_size 参数),触发 async/sync flush checkpoint,及时将一些脏页刷新到磁盘数据页,并同时将redo log buffer刷新到redo log,然后更新redo log file 相应的 log sequence number值;
脏数据的持久化:
内存中(buffer pool)未刷到磁盘的数据称为脏数据(dirty data),内存中的脏数据页也需要持久化到磁盘内。由于数据和日志都以页的形式存在,所以脏页表示脏数据和脏日志。
在innodb中,数据刷盘的规则只有一个:检查点(checkpoint)。但是触发checkpoint的情况却有几种。不管怎样,checkpoint触发后,会将内存中脏数据页和脏日志页都刷到磁盘。
innodb存储引擎中checkpoint分为两种:
sharp checkpoint:在重用redo log文件(例如切换日志文件)的时候,将所有已记录到redo log中对应的脏数据刷到磁盘;
fuzzy checkpoint:一次只刷一小部分的日志到磁盘,而非将所有脏日志刷盘。有以下几种情况会触发该检查点:
master thread checkpoint:由master线程控制,每秒或每10秒刷入一定比例的脏页到磁盘。
flush_lru_list checkpoint:从MySQL5.6开始可通过 innodb_page_cleaners 变量指定专门负责脏页刷盘的page cleaner线程的个数,该线程的目的是为了保证LRU列表有可用的空闲页。
async/sync flush checkpoint:同步刷盘还是异步刷盘。例如还有非常多的脏页没刷到磁盘(非常多是多少,有比例控制),这时会选择同步刷到磁盘,但这很少出现;如果脏页不是很多,可以选择异步刷到磁盘,如果脏页很少,可以暂时不刷脏页到磁盘
dirty page too much checkpoint:脏页太多时强制触发检查点,目的是为了保证缓存有足够的空闲空间。too much的比例由变量innodb_max_dirty_pages_pct 控制,MySQL 5.6默认的值为75,即当脏页占缓冲池的75%后,就强制刷一部分脏页到磁盘。由于刷脏页需要一定的时间来完成,所以记录检查点的位置是在每次刷盘结束之后才在redo log中标记的。
MySQL停止时是否将脏数据和脏日志刷入磁盘,由变量 innodb_fast_shutdown 控制,默认值为1:
设置为0:会做清除脏页和插入缓冲区的合并操作,也会将脏页全部刷新到磁盘上面去,但是这个时候关闭的速度也是最慢的,但是restart的时候也是最快的;
设置为1:关闭MySQL的时候不会做清除脏页和插入缓冲区的合并操作,只会将脏页刷新到磁盘;
设置为2:不会做清除脏页和插入缓冲区的合并操作,也不会将脏页刷新到磁盘,但是会刷新到redo log里面,再下次启动mysql的时候恢复;
回滚日志(Undo Log)
介绍
在数据修改的时候,不仅记录了redo,还记录了相对应的undo,如果因为某些原因导致事务失败或回滚了,可以借助该undo进行回滚。
undo log和redo log记录物理日志不一样,它是逻辑日志:当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。
当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚。有时候应用到行版本控制的时候,也是通过undo log来实现的:当读取的某一行被其他事务锁定时,它可以从undo log中分析出该行记录以前的数据是什么,从而提供该行版本信息,让用户实现非锁定一致性读取。
Undo Log(回滚日志): 记录事务开始前的状态,用于事务失败时的回滚操作以及提供多版本并发控制(MVCC)下的非锁定读。undo log也会产生redo log,因为undo log也要实现持久性保护。
Undo Log:https://dev.mysql.com/doc/refman/8.0/en/innodb-undo-logs.html
更新删除
事务提交的时候,InnoDB不会立即删除undo log,因为后续还可能会用到undo log,如隔离级别为repeatable read时,事务读取的都是开启事务时的最新提交行版本,只要该事务不结束,该行版本就不能删除,即undo log不能删除。但是在事务提交的时候,会将该事务对应的undo log放入到删除列表中,之后通过purge线程来删除。
undo中纪录的更新删除:
delete:不会直接删除,而是将delete对象标记delete flag为删除,最终由purge线程完成删除操作。
update:
更新键为主键:先删除新纪录,再插入原纪录;
更新键为非主键:在undo log中反向记录update命令;
例:
如上图:事务中插入一条{1,'A'}的数据,更新该id的值为B,然后更新该值为C,会进行下面的操作:
id=1的数据第一次插入,因为insert时,原始的数据并不存在,所以回滚时把insert undo log丢弃即可;
更新数据时,用排他锁锁定该行;
记录redo log;
把该行修改前的值Copy到undo log,即纪录原纪录{1,'A'}的逻辑日志;
修改当前行的值,填写事务编号,使该行纪录的回滚指针指向undo log中的修改前的行({1,'A'}的undo日志行);
更新数据为{1,‘C’}时与更新{1,‘B’}相同,更新完成后此时undo log中有有两行记录({1,'B'}-->{1,'A'}),并且通过回滚指针连在一起。因此,如果undo log一直不清除,则会通过当前记录的回滚指针回溯到该行创建时的初始内容,所幸的时在Innodb中存在purge线程,它会查询那些比现在最老的活动事务还早的undo log,并删除它们,从而保证undo log文件不至于无限增长。
相关参数
innodb_undo_tablespaces:设置undo独立表空间个数,范围为0-128, 默认为0,0表示表示不开启独立undo表空间 且 undo日志存储在.ibdata文件中。该参数只能在最开始初始化MySQL实例的时候指定,如果实例已创建,这个参数是不能变动的,如果设置了该参数为n(n>0),那么就会在undo目录下创建n个undo文件(undo001,undo002 ...... undo n),每个文件默认大小为10M。
innodb_max_undo_log_size:控制最大undo tablespace文件的大小,当启动了innodb_undo_log_truncate 时,undo tablespace 超过innodb_max_undo_log_size 阈值时才会去尝试truncate。该值默认大小为1G,truncate后的大小默认为10M。
innodb_undo_log_truncate:InnoDB的purge线程根据此参数开启状态、innodb_max_undo_log_size的参数值,以及truncate的频率来进行空间回收和 undo file 的重新初始化。(该参数生效的前提是,已设置独立表空间且独立表空间个数大于等于2个)。
innodb_purge_rseg_truncate_frequency:用于控制purge回滚段的频度,默认为128。假设设置为n,则说明,当Innodb Purge操作的协调线程 purge事务n次时,就会触发一次History purge,检查当前的undo log 表空间状态是否会触发truncate。
innodb_rollback_segments:回滚段的数量,默认128;
当数据库写压力较大时,可以设置独立undo表空间(innodb_undo_tablespaces),把undo log从.ibdata文件中分离开来,指定 innodb_undo_directory目录存放,可以指定到更高速的存储介质上,加快undo log的读写性能。
存在形式
InnoDB存储引擎对undo的管理采用段的方式。rollback segment称为回滚段,每个回滚段中有1024个undo log segment。
默认支持128个rollback segment,即支持128*1024个undo操作,可以通过变量 innodb_rollback_segments 自定义回滚段的数量。
回滚段(rollback segment)分配如下:
slot 0 ,预留给系统表空间;
slot 1~32,预留给临时表空间,每次数据库重启的时候,都会重建临时表空间;
slot 33~127,如果有独立表空间,则预留给UNDO独立表空间;如果没有,则预留给系统表空间;
回滚段中除去32个提供给临时表事务使用,剩下的 96个回滚段,可执行 96*1024 个并发事务操作,每个事务占用一个undo log segment。注意,如果事务中有临时表事务,还会在临时表空间中的rollback segment slot(1~32) 再占用一个undo log segment,即占用2个undo log segment。如果错误日志中有:Cannot find a free slot for an undo log. 表示并发的事务太多了,需要考虑下是否要分流业务。
二进制日志(Binlog)
介绍
Binlog(二进制日志):MySQL服务级别的日志,用于数据恢复 和 主从复制。
Binary Log:https://dev.mysql.com/doc/refman/8.0/en/binary-log.html
事务提交的时候,一次性将事务中的SQL语句按照配置的格式记录到binlog中。
在这一步中binlog与redo log的区别是redo log是在事务开始之后就开始逐步写入磁盘有多少条记录就有多少条redo log,而binlog是在事务提交后一次性记录事务的SQL语句。
binlog的默认是保持时间由参数 expire_logs_days 配置,也就是说对于非活动的日志文件,在生成时间超过 expire_logs_days 配置的天数之后,会被自动删除。
binary log的记录格式有3种:row,statement跟mixed,不同格式记录形式不一样。(在大数据实时同步场景下经常使用ROW模式配合maxwell或canal监控数据变更)
| 模式 | 定义 | 优点 | 缺点 |
|---|---|---|---|
| statement | 记录修改的SQL语句 | 日志文件小,节约IO,提高性能 | 准确性差,会出现主从不一致的情况 |
| row | 记录每行实际数据的变更 | 准确性强,能清楚的记录每一行数据修改的细节 | 日志文件大,较大的IO |
| mixed | 上面两种模式的混合 | 准确性强,日志文件大小适中 | 会出现主从不一致的情况 |
配置binlog
修改my.cfg(/etc/my.cnf)或my.ini后重启即可生效:
[mysqld]#binlog日志名称前缀log-bin=mysql-bin#默认值未0,如果使用默认值则不能和从节点通信,这个值的区间是:1到(2^32)-1server-id=1#复制模式binlog_format = ROW ############################################################binlog路径log_bin = /var/lib/mysql/mysql-bin.log #日志过期时间,设置为0则永不过期expire_logs_days = 7 #超过max_binlog_size或超过6小时会切换到下一序号文件max_binlog_size = 100M #日志缓冲大小,通过show status like 'binlog_%';查看调整写入磁盘的次数,写入磁盘为0最好binlog_cache_size = 16M max_binlog_cache_size = 256M #当slave从库宕机后,假如relay-log损坏了,#导致一部分中继日志没有处理,则自动放弃所有未执行的relay-log,#并且重新从master上获取日志,这样就保证了relay-log的完整性。relay_log_recovery = 1 #二进制日志(binary log)同步到磁盘的频率sync_binlog = 1 #每次事务提交将日志缓冲区写入log file,并同时flush到磁盘。innodb_flush_log_at_trx_commit = 1
查看binlog日志
binlog日志有二种查看方式,具体如下:
1、mysql查看binlog
show binlog events; #只查看第一个binlog文件的内容mysql> show binlog events in 'mysql-bin.000001';#查看指定binlog文件的内容mysql> show binary logs; #获取binlog文件列表mysql> show master status;#查看当前正在写入的binlog文件
2、使用mysqlbinlog工具
binlog是二进制存储的,我们可以使用一个查看mysql二进制日志的工具(mysqlbinlog)操作binlog日志文件,该工具默认的安装路径为:/usr/local/mysql/bin/mysqlbinlog。
#基于开始/结束时间#--start-datetime 指定开始时间#--stop-datetime 指定截止时间#-d 选项,指定数据库名称mysqlbinlog --start-datetime='2020-08-01 00:00:00' --stop-datetime='2020-08-17 12:00:00' -d wyk /var/lib/mysql/mysql-bin.000001#-o 选项,o代表偏移offset,指定偏移量mysqlbinlog -o 10 mysqld-bin.000001#-j 从一个特定位置提取mysqlbinlog -j 9527 mysqld-bin.000001 > from_id_9527.sql#--stop-position 截止到一个特定位置的条目mysqlbinlog --stop-position=9527 mysqld-bin.000001 > upto_id_9527.sql#使用Linux重定向命令,将可读的输出文本存储到一个文件中mysqlbinlog mysqld-bin.000001 > output.log#也可以使用 -r选项将输出存储到一个文件中mysqlbinlog -r output.sql mysqld-bin.000001
两阶段提交
MySQL通过2PC(两阶段提交)来完成事务的一致性,即redo log和binlog的一致性:redo log在事务执行的过程中不断记录事务操作的变化,redo log有prepare和commit两种状态(来保证binlog与relog 的一致性),事务操作完成并且binlog写入完成时,redo log会从prepare状态转变为commit 状态,若在事务过程中发生系统故障时,数据库会根据redo log状态(prepare状态)恢复到事务前的状态;若事务已成功提交但数据未更新,数据库会根据redo log(此时为commited状态)更新到事务完成后的状态。
(关于2PC,3PC,TCC 会在后面的篇章中有更详细的介绍)
总结
对比redo,undo, binlog:
| redo | undo | binlog | |
| 作用 | 保持事务的持久性 | 帮助事务回滚及MVCC的功能 | 进行Point-In-Time的恢复及主从复制环境的建立 |
| 产生主体 | InnoDB | InnoDB | MySQL |
| 类型 | 物理日志 | 逻辑日志 | 逻辑日志 |
| 内容 | 每个页的修改 | 修改前的行数据 | 执行的SQL语句 |
| 每个事务的日志数量 | 修改的行数据量 | 修改的行数据量 | 事务提交后记一条SQL语句 |
| 写入方式 | 循环写 | 循环写 | 追加写 |
希望本文对你有帮助,请点个赞鼓励一下作者吧~ 谢谢!
以上是关于MySQL日志的主要内容,如果未能解决你的问题,请参考以下文章