查找算法之顺序二分二叉搜索树红黑树 详细比较总结
Posted WQTech
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了查找算法之顺序二分二叉搜索树红黑树 详细比较总结相关的知识,希望对你有一定的参考价值。
前言
一般用符号表来储存键值对,就好像字典那样,通过索引来查找值,若键重复则覆盖值。我们能希望找到一种高效的查找算法使在平均情况和最差情况下,时间复杂度都能达到O(logn)。下面会逐步介绍四种算法,最终达到我们的目的。
顺序查找
用链表实现,无法索引数据,必须遍历找数据,速度比较慢,查找插入时间复杂度都为O(n),而且无法保证有序。但是实现简单,适用于小型数据。

二分查找
用数组保存数据,保证有序。二分查找速度很快,但是仅限于查找。因为插入的时候要保证有序,所以要往后移动数据以便插入。查找复杂度O(logn),插入复杂度O(n)。

二叉搜索树
通过前面两个算法,我们可以知道链表能快速删除插入,而二分能快速查找。所以我们想找到一种结构既是链式结构,同时又能进行二分查找,同时保证查找和插入的高效性。
答案就是二叉搜索树。
定义
是二叉树
每个节点含有一个键和关联的值
且每个节点的键大于左儿子且小于右儿子
实现
其实给出定义,实现就已经很清楚了。说白了就是从无到有构造一个二叉树,每次插入都和树中的节点进行比较,小的放左边,大的放右边。就如同快速排序,用一个主元把左右两边分开。

还是直接看代码清楚点

效率问题
二叉搜索树的查找和搜索在平均情况下时间复杂度都能达到O(logn),而且能保证数据有序。二叉搜索树的中序遍历就是数据的顺序。我们貌似已经找到了一个最理想的算法。
但是这个效率只是在平均情况下。如果数据是逆序,或者顺序,那么这棵树就会发生一边倒的情况使复杂度直接达到O(n),就如同快排中选择到糟糕的主元(最大或者最小)。比快排糟糕的是,快排我们能通过随机打乱数据来避免这种情况发生。但二叉搜索树则不行,数据都是客户提供,直接插入到树中的,这种情况其实经常发生。
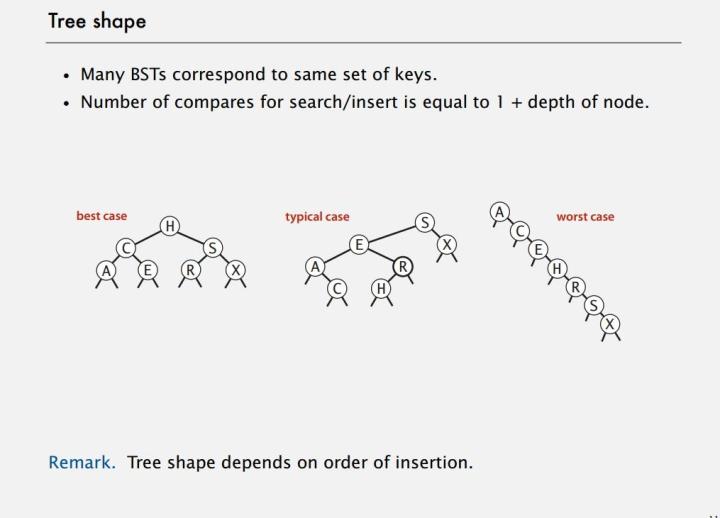
幸运的是我们有平衡二叉树可以解决这个问题。
平衡二叉树
2-3树
为了保持树平衡性,允许节点能保存两个键值对,且能连三个儿子。这样把节点分成了两种类型。
2-节点: 一个键值对,两个儿子。 (也就是标准的二叉搜索树)3-节点: 两个键值对,三个儿子。 (两个键是有序的,左小右大。左儿子小于左边的键,右儿子大于右边的键,中间的儿子在两个键之间)
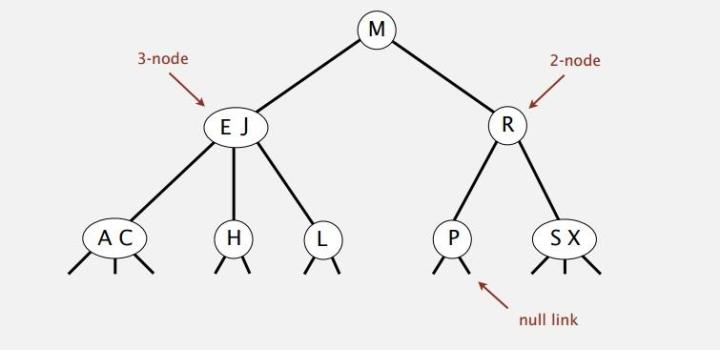
实现原理
2-3树插入比较复杂。在插入的同时保持平衡性。
向
2-节点中插入键。这种情况比较简单。直接插入即可。向
3-节点中插入键。比较特殊。先暂时把键插入到3-节点,此时这个节点中就有了三个键,然后再把这个节点分开。把中间的儿子简单当根,左右两边的键当儿子。若父节点还是3-节点,则继续递归进行。
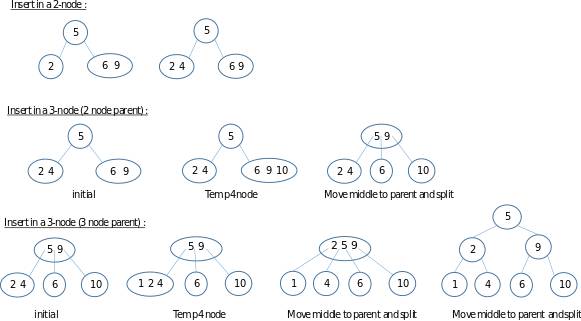
性能分析
2-3树性能可以说是比较好的。不管数据怎么样,查找删除操作时间复杂度都能达到O(logn)。
但是2-3树实现比较复杂,需要掌控的情况很多,剥离节点,传递节点等操作,都需要很复杂的代码,且也会耗费不少的时间。所以我们一般不怎么用原始的2-3树,而是用2-3树的变形红黑树.
红黑树
红黑树最方便的地方除了插入和删除操作的代码略复杂以外,另外的操作都可以直接复制二叉搜索树。
红黑树是2-3树的变形,把3-节点分离开来使之成为普通的2-节点。但是怎么表现分离开的节点之间的联系呢。我们用红线把他们连起来。
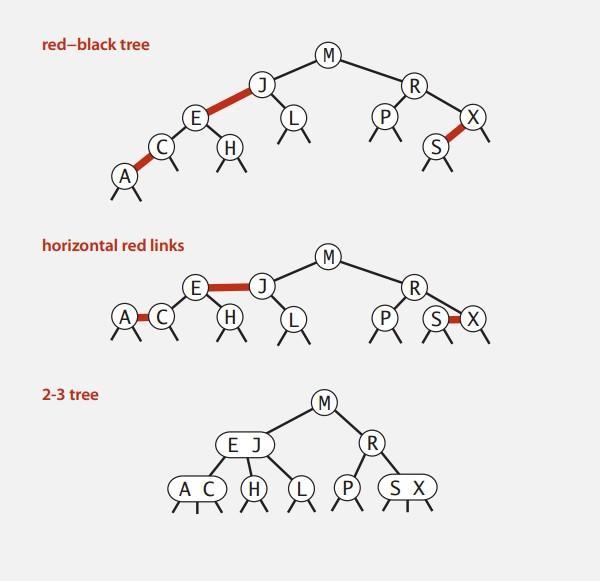
巧妙地结合二叉搜索树的高效查找操作和2-3树的平衡插入操作。
每个节点都只有一根连向父节点的线。这个线的颜色称为节点的颜色。
实现
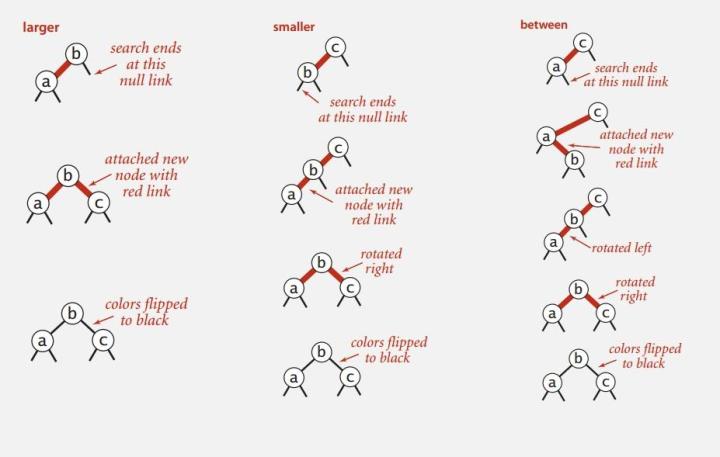
我们通过旋转来维持树的平衡。一般有两种情况需要旋转。
连续两个左节点的颜色为红色,向右转
右节点的颜色为红色,向左转
第三种情况是左右两边都为红色。最好处理,不需要旋转。只需要把左右两个儿子的颜色改成黑色,再把自己的颜色改成黑色。可以想象成把3个键值对
3-节点剥离开。


性能分析
无论数据如何,插入删除时间复杂度都为O(logn),可以说达到了理想状态,且代码简单。
性能测试
分别对四个文件进行插入搜索操作。
tale.txt(779kb)
顺序查找(7.143秒) 二分查找(0.46秒)二叉搜索树(0.191秒)红黑树(0.237秒)leipzig100k.txt(12670kb)
顺序查找(无) 二分查找(13.911秒)二叉搜索树(1.389秒)红黑树(1.442秒)leipzig300k.txt(37966kb)
顺序查找(无) 二分查找(60.222秒)二叉搜索树(2.742秒)红黑树(3.104秒)leipzig1m.txt(126607kb)
顺序查找(无) 二分查找(无)二叉搜索树(3.016秒)红黑树(2.797秒)
由上面的数据分析,顺序查找实际是非常慢的。而二分查找对小型数据还是比较快,但是数据一大就不行了。
而这里的二叉搜索树和红黑树,无论什么数据效率都是极高。而且由leipzig300k.txt到leipzig1m.txt数据几乎翻了4倍,而这两种算法的效率几乎没收什么影响。
这里因为我的数据比较平均的关系,比较不出红黑树和二叉搜索树的差异。我自己构造了一组数据进行测试。完全逆序的100000个数进行插入删除。
红黑树(0.173秒)
二叉搜索树(StackOverflow)
微信扫一扫
以上是关于查找算法之顺序二分二叉搜索树红黑树 详细比较总结的主要内容,如果未能解决你的问题,请参考以下文章