解决ANRJVMSerializable与Parcelable红黑树一道算法题
Posted 码个蛋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解决ANRJVMSerializable与Parcelable红黑树一道算法题相关的知识,希望对你有一定的参考价值。
今天是码妞给大家带来《每日一道面试题》的第十五期啦~
01
怎样避免和解决ANR
Application Not Responding,即应用无响应。
避免ANR最核心的一点就是在主线程减少耗时操作。通常需要从那个以下几个方案下手:
a)使用子线程处理耗时IO操作
b)降低子线程优先级,使用Thread或者HandlerThread时,调用Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND)设置优先级,否则仍然会降低程序响应,因为默认Thread的优先级和主线程相同
c)使用Handler处理子线程结果,而不是使用Thread.wait()或者Thread.sleep()来阻塞主线程
d)Activity的onCreate和onResume回调中尽量避免耗时的代码
e)BroadcastReceiver中onReceiver代码也要尽量减少耗时操作,建议使用intentService处理。intentService是一个异步的,会自动停止的服务,很好解决了传统的Service中处理完耗时操作忘记停止并销毁Service的问题

02
谈谈JVM的内存结构和内存分配
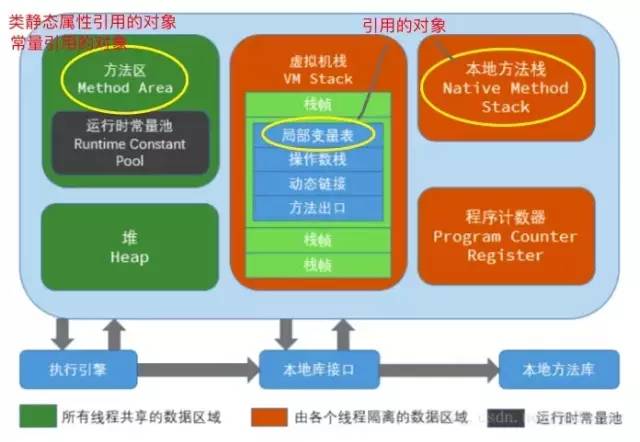
Java内存模型 Java虚拟机将其管辖的内存大致分三个逻辑部分:方法区(Method Area)、Java栈和Java堆。
方法区是静态分配的,编译器将变量绑定在某个存储位置上,而且这些绑定不会在运行时改变。
Java Stack是一个逻辑概念,特点是后进先出。一个栈的空间可能是连续的,也可能是不连续的。
Java堆分配(heap allocation)意味着以随意的顺序,在运行时进行存储空间分配和收回的内存管理模型。
数组 既在栈空间分配数组名称, 又在堆空间分配数组实际的大小!

03
Serializable和Parcelable的区别
Serializable(Java自带):Serializable是序列化的意思,表示将一个对象转换成可存储或可传输的状态。序列化后的对象可以在网络上进行传输,也可以存储到本地。
Parcelable(android 专用):除了Serializable之外,使用Parcelable也可以实现相同的效果, 不过不同于将对象进行序列化,Parcelable方式的实现原理是将一个完整的对象进行分解, 而分解后的每一部分都是Intent所支持的数据类型,这样也就实现传递对象的功能了。
区别:
在使用内存的时候,Parcelable 类比Serializable性能高,所以推荐使用Parcelable类。
Serializable在序列化的时候会产生大量的临时变量,从而引起频繁的 GC。
Parcelable 不能使用在要将数据存储在磁盘上的情况。尽管 Serializable 效率低点,但在这种情况下,还是建议你用Serializable 。
实现:
Serializable 的实现,只需要继承Serializable 即可。这只是给对象打了一个标记,系统会自动将其序列化。
Parcelabel 的实现,需要在类中添加一个静态成员变量 CREATOR,这个变量需要继承Parcelable.Creator 接口,(一般利用编译器可以自动生成)。
群友补充 @Noble_JIE
从出生来来说,Serializable 是java的方法,Parcelable 是android独有的序列化反序列化方法。
从用法上来说,Serializable 比 Parcelable 简单,所有类实现Serializable即可,Parcelable需要对对所有属性及成员变量进行Creator 。
从性能上来说,Parcelable 性能要高于Serializable。
04
有了二叉查找树,为什么还需要红黑树
二叉查找树的缺点
二叉查找树的特点就是左子树的节点值比父亲节点小,而右子树的节点值比父亲节点大,如图
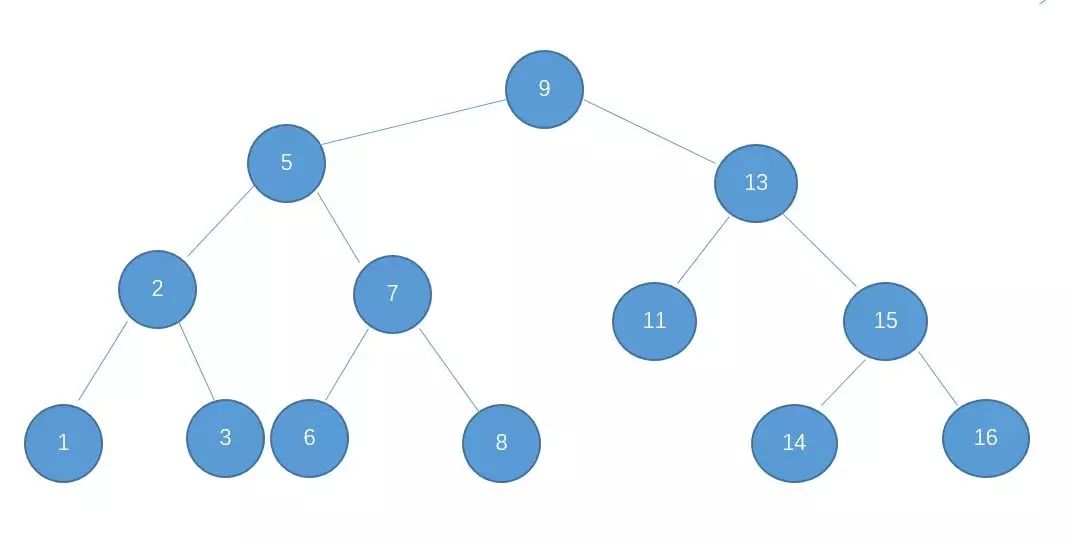
基于二叉查找树的这种特点,我们在查找某个节点的时候,可以采取类似于二分查找的思想,快速找到某个节点。n 个节点的二叉查找树,正常的情况下,查找的时间复杂度为 O(logn)。之所以说是正常情况下,是因为二叉查找树有可能出现一种极端的情况,例如
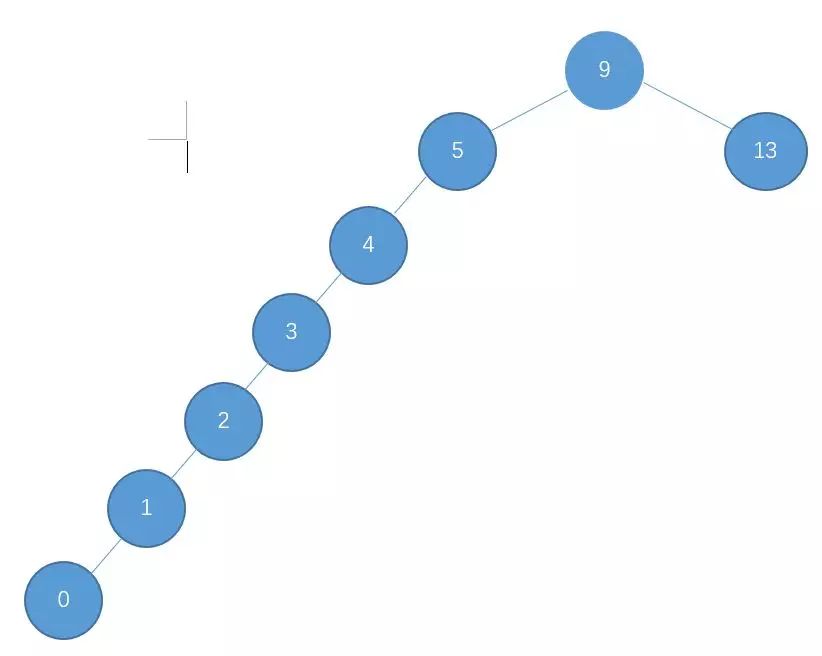
这种情况也是满足二叉查找树的条件,然而,此时的二叉查找树已经近似退化为一条链表,这样的二叉查找树的查找时间复杂度顿时变成了 O(n),可想而知,我们必须不能让这种情况发生,为了解决这个问题,于是我们引申出了平衡二叉树。
平衡二叉树
平衡二叉树就是为了解决二叉查找树退化成一颗链表而诞生了,平衡树具有如下特点:
具有二叉查找树的全部特性。
每个节点的左子树和右子树的高度差至多等于1。
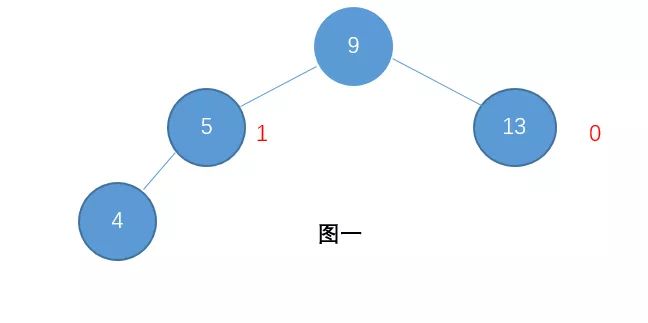
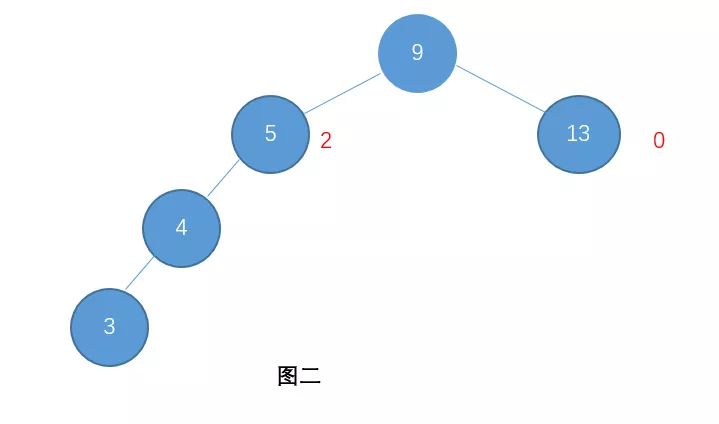
例如:图一就是一颗平衡树了,而图二则不是(节点右边标的是这个节点的高度)
对于图二,因为节点9的左孩子高度为2,而右孩子高度为0。他们之间的差值超过1了。平衡树基于这种特点就可以保证不会出现大量节点偏向于一边的情况了。关于平衡树如何构建、插入、删除、左旋、右旋等操作这里不在说明.于是,通过平衡树,我们解决了二叉查找树的缺点。对于有 n 个节点的平衡树,最坏的查找时间复杂度也为 O(logn)。
为什么有了平衡树还需要红黑树?
虽然平衡树解决了二叉查找树退化为近似链表的缺点,能够把查找时间控制在O(logn),不过却不是最佳的,因为平衡树要求每个节点的左子树和右子树的高度差至多等于1,这个要求实在是太严了,导致每次进行插入/删除节点的时候,几乎都会破坏平衡树的第二个规则,进而我们都需要通过左旋和右旋来进行调整,使之再次成为一颗符合要求的平衡树。
显然,如果在那种插入、删除很频繁的场景中,平衡树需要频繁着进行调整,这会使平衡树的性能大打折扣,为了解决这个问题,于是有了红黑树,红黑树具有如下特点:
1. 具有二叉查找树的特点。
2. 根节点是黑色的;
3. 每个叶子节点都是黑色的空节点(NIL),也就是说,叶子节点不存数据。
4. 任何相邻的节点都不能同时为红色,也就是说,红色节点是被黑色节点隔开的。
5. 每个节点,从该节点到达其可达的叶子节点是所有路径,都包含相同数目的黑色节点。
例如下面的图片(注意,图片中黑色的、空的叶子节点没有画出)(图片来自极客时间)
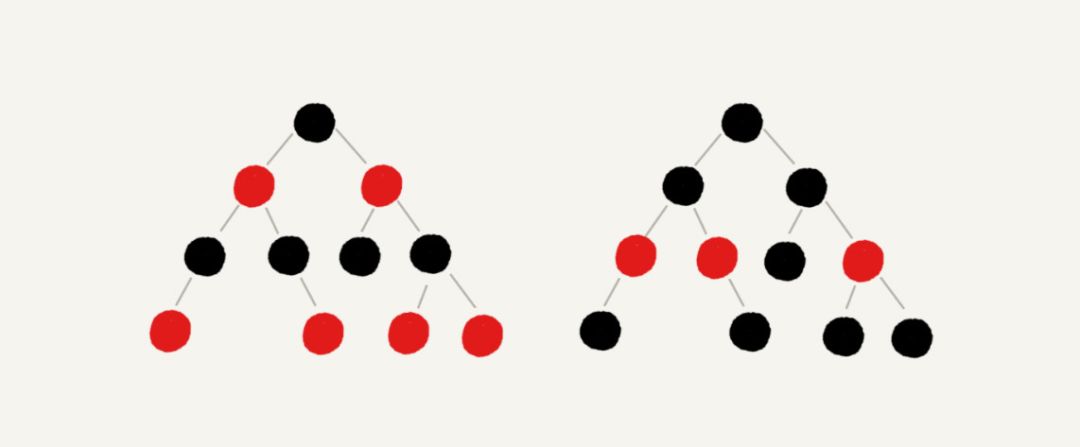
正是由于红黑树的这种特点,使得它能够在最坏情况下,也能在 O(logn) 的时间复杂度查找到某个节点。
与平衡树不同的是,红黑树在插入、删除等操作,不会像平衡树那样,频繁着破坏红黑树的规则,所以不需要频繁着调整,这也是我们为什么大多数情况下使用红黑树的原因。不过,如果你要说,单单在查找方面的效率的话,平衡树比红黑树快。所以,我们也可以说,红黑树是一种不大严格的平衡树。也可以说是一个折中发方案。
总结:
平衡树是为了解决二叉查找树退化为链表的情况,
蛋友补充 @RainFool
红黑树虽然没有完全遵循平衡二叉树的定义,但是因为其本身的设计,高度不会超过2logn,所以时间查找、插入、删除操作仍然是logn的。

05
算法 - 查找数
题目:
在有序数组[1,3,4,5,12,15,18,19,21,25,31]中,查找两个数,使得它们的和正好是30,时间复杂度O(n),说出解题思路?
参考答案:
从数组两边开始计算,一个变量从开始到结尾,另一个变量从结尾到开头,两个变量相加,大于30,第2个变量--,小于30,第一个变量++
public class Sum {
public static void main(String[] args) {
Sum sum = new Sum();
int[] a = {-3,-2,0,1,2,3,6,7,9,15,17,19};
HashMap<Integer,Integer> map = new HashMap<Integer,Integer>();
map = sum.searchSum(a,9,map); //1)查找
sum.printResult(a,map); //打印查找结果
}
//查找 ,下标从0开始
private HashMap<Integer,Integer> searchSum(int[] a, int Num, HashMap<Integer,Integer> map){
int n = a.length;
int i=0,j=n-1; //i和j分别保存当前较小的和交大的数据
//Map map = new HashMap<Integer,Integer>();
while(i<j){ //查找条件
while(i<j && (a[i]+a[j])>Num){
j--;
}
if(i<j&&(a[i]+a[j])==Num){
map.put(i, j);
i++;
//return map; //如果找到就结束的话加上这句
}
while(i<j && (a[i]+a[j])<Num){
i++;
}
if(i<j&&(a[i]+a[j])==Num){
map.put(i, j);
j--;
//return map; //如果找到就结束的话加上这句
}
}
return map;
}
//打印查找结果
private void printResult(int[] a, HashMap<Integer,Integer> map){
int n = map.size();
if(n==0){
System.out.println("没有找到!");
return;
}
System.out.println("这是找到的所有元素:");
for(Integer key: map.keySet()){
System.out.println("下标为:("+key+","+map.get(key)+"), 值为:"+a[key]+","+a[map.get(key)]);
}
}
}群友总结
二分法查找;从第一个角标开始,计算差值,然后二分法查找数组,寻找是否存在有满足需求的数,没有就向右移动角标
所有数字存进 map,遍历查找 map 中是否存在当前元素与 30 的差值,存在就说明两数之和为 30 ,共需遍历2次,复杂度为 n,map查找的时间复杂度是1,所以整体复杂度还是 n,一边存 map 一边查找的话,只需要遍历一次。

06
结束语
如果你有好的答案可以提交至:
https://github.com/codeegginterviewgroup/CodeEggDailyInterview

往期文章:
专属社群:
今日问题:
大家有什么好的面试题要分享吗?
以上是关于解决ANRJVMSerializable与Parcelable红黑树一道算法题的主要内容,如果未能解决你的问题,请参考以下文章