线上接口偶尔超时排查
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线上接口偶尔超时排查相关的知识,希望对你有一定的参考价值。
参考技术A 晚上回家后钉钉群里业务方反馈我们两个接口超时很严重,这个两个接口分别属于不同的系统,部署在不同的机器上。看到反馈会首先打开prometheus监控看下接口qps和耗时,发现接口qps很小,响应耗时也正常,于是截图给到群里说我们的接口耗时正常。后面又有一个调用我们接口的业务方反馈说超时也很严重,同时两个业务方反馈接口超时很严重,同时我们这边也有向业务方反馈说是不是中间的调用链路出了问题,因为从监控看我们的接口和平时相比挺正常的。于是我用time curl 命令调用了接口发现确实有偶尔超时的现象,耗时从1s到3s多都有,这说明我们的服务确实哪出问题了。因为此前公司的lvs别的业务方反馈出过问题,于是我们拉了下运维到群里,问了下我们的lvs当前是否正常。运维截图给我们看了下,当前的lvs连接数比之前少了接近一半,其它都挺正常。于是我登录服务器也用top命令看了下ab服务的cpu和内存占用以及负载,发现了cpu占用140%,内存和负载都是正常,于是我问了下我们的一个同事说cpu比下午高了很多,然后恢复我说和cpu没有关系。我于是又看了服务器超时日志,超时日志也不是很多,属于正常范围内。然后继续从其他角度排查问题,排查了一小会后面同事说正常了。我还问了下是做啥处理了,运维同事给我说是我们的一台机器由于安装了docker,于是会启动防火墙,于是和防火墙相关的linux内核一个参数net.netfilter.nf_conntrack_max被应用了。这个参数值防火墙能够同时处理的任务数,默认的是262144,运维把这个内核参数调成了2621440,接口调用就没有超时的现象了。后面我仔细想了下为啥这个参数会影响到我们的服务呢?安装docker的这台机器也是我们的一台nginx服务,我们线上总共有两台nginx服务,由于其中一台nginx服务的机器安装了docker,启动了防火墙,于是这个内核参数生效了。平时我们正常的接口qps总量在1500左右,由于业务方上线了几个功能都有调用的是我们的接口,整个系统的qps就接近了5000,比平时高了3倍多的qps。而所有的接口都是通过lvs到达两台nginx,那么每台nginx的调用量大概会是在2500,平时只有750大概,平时net.netfilter.nf_conntrack_max参数默认的设置值处理750左右的qps是没有问题的,qps2500默认的参数就不行了,处理不过来了,导致了很多接口请求都在队列等待处理,从而接口耗时偶尔很高,所以导致lvs的连接数量也下降了接近一半。通过这次排查问题发现了问题出现了可能是各方面的影响导致的,比如内存,cpu,磁盘,内核参数设置都有可能影响线上的服务,所以平时还是需要多多积累,操作系统,网络这块的基础要打扎实,这样出了问题才能够不慌有思路去排查。线上问题排查一接口拒绝连接排查思路
在使用feign或者HTTP形式调用接口时,有可能会出现目标接口无法调通,目标服务器拒绝连接的情况。
出现该问题的原因有:
- 目标服务器防火墙配置更改,已关闭目标端口。
- 生产者(接口提供方)服务挂掉。
排查思路:
- 检查目标服务器防火墙配置,开启目标端口,重启防火墙
- 检查目标服务器服务状态
解决过程:
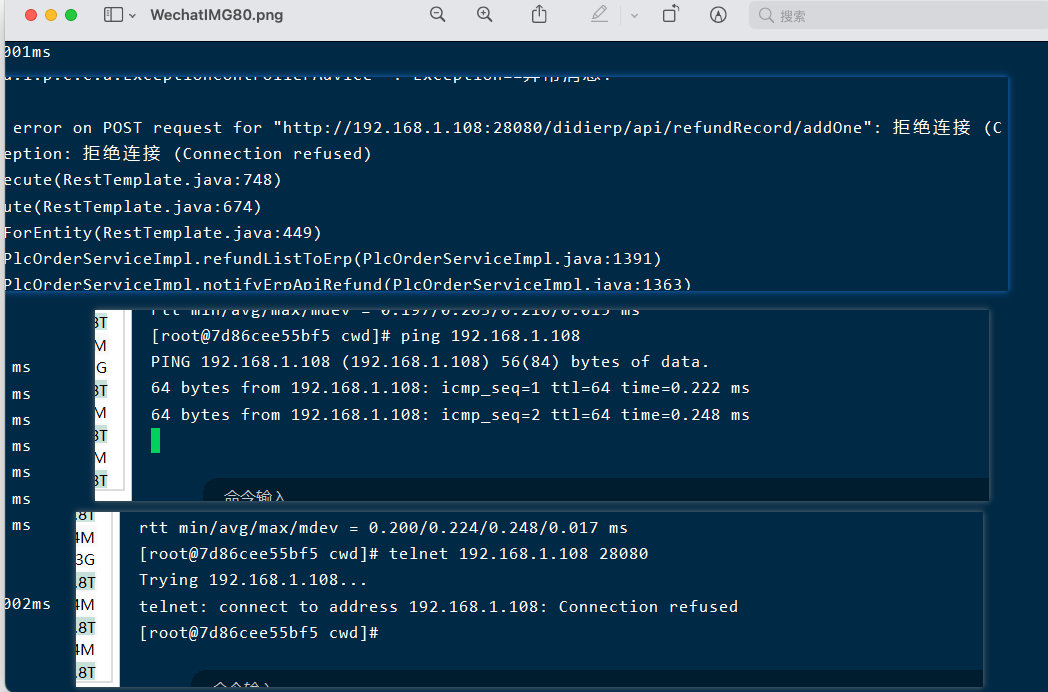
查看服务器调用者日志,当出现接口拒绝连接时,可参考以下方案:
- 使用
ping IP命令查看目标服务器是否宕机。如果可以Ping通,则可以进行下一步。如果不通需要确认目标服务器是否禁用ping命令或者联系相关运维人员或自行重启服务器。 - 使用
telnet IP Prot命令查看是否可以进行数据通信,如果出现如下结果,则需要检查服务提供方服务状态,是否挂掉,如果挂掉则需要重启目标服务。重启服务后若仍无法正常请求,则需要查看目标服务器的防火墙配置,查看通讯端口是否开启,未开启则需要开启。
Linux配置防火墙请参考:
[Linux如何配置防火墙?](
以上是关于线上接口偶尔超时排查的主要内容,如果未能解决你的问题,请参考以下文章
Kafka 异步消息也会阻塞?记一次 Dubbo 频繁超时排查过程
线上 hive on spark 作业执行超时问题排查案例分享