定制Spark SQL: 一种轻量级实现方案
Posted 比图科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了定制Spark SQL: 一种轻量级实现方案相关的知识,希望对你有一定的参考价值。
Spark SQL是Apache Spark中的最重要的功能之一。在 SQL的使用上,Spark SQL和其它适用于大规模离线数据的SQL引擎 (例如Presto/Apache Hive) 是相似的。除了SQL之外,Apache Spark还提供了更为灵活的DataFrame API。
Spark SQL和Spark DataFrame API有着不同的使用场景。
Spark DataFrame API的表达能力比Spark SQL更强,对于有良好编程基础和代码抽象能力的工程师来说,使用DataFrame来解决复杂的数据处理问题更加便捷;
Spark SQL的语法几乎和Apache Hive的SQL语法几乎一致。绝大部分数据处理需求,使用Spark SQL就能够满足。使用DataFrame API,我们需要创建一个Scala工程,编译代码并打包,最终通过spark-submit提交到集群;而Spark SQL无需构建生成中间产物,就可以通过JDBC等方式提交到集群。
我们需要定制Spark SQL
但是使用Spark SQL,我们总会遇到各种极端情况需要处理,比如:
“我有一个200列的表,我想把其中的两列排除掉,把剩下的198列保存到一个新的表里面。”
如果使用Spark DataFrame API,这个问题可以这样解决:

但是用SQL,把198个列名直接放在SQL语句里面,不具备可读性,且无法应对字段增加的情况:
select col_1, col_2, col_3, col_4, col_5, col_6, col_7, col_8, col_9, …
对于这个问题,Spark SQL有一种兼容HiveQL的解决方案,需要开启配置项,才能使用如下可读性极差的语法:
set spark.sql.parser.quotedRegexColumnNames=true;
select `(col_to_exclude_1)?+.+` from tbl
上面是从所有字段中排除一个字段的方法,如果有人问我,如何排除两个字段,我恐怕无法回答这个问题。
在Tubi,我们采用定制Spark SQL语法的方式解决这个问题:
// select all columns excluding `col_to_exclude_1`
select all_columns_except("tbl", "col_to_exclude_1")
// select all columns excluding `col_to_exclude_1` and `col_to_exclude_2`
select all_columns_except("tbl", "col_to_exclude_1", "col_to_exclude_2")
对于一些Spark SQL中易用性非常差的语法,使用宏的方式,可以很方便地规避。我们也可以使用宏来对Spark SQL的既有功能做增强,比如
select * from json.`s3://bucket/dir/dt=2020-12-12/`
如上语法是Spark SQL内置的功能,但很多时候,我们的数据并没有按照日期分目录组织,而是所有文件都在一个目录下:
s3://bucket/2020-12-12-13-00-00.json.gz
s3://bucket/2020-12-12-13-01-00.json.gz
s3://bucket/2020-12-12-13-02-00.json.gz
...
s3://bucket/2020-12-13-00-00-00.json.gz
s3://bucket/2020-12-13-00-00-01.json.gz
这个时候,我们希望使用如下语法访问2020年12月12日当天下午一点的所有数据:
select * from json.`s3://bucket/dir/2020-12-12-13*`
但Spark SQL并不支持这样的语法,我们也可以使用自定义语法的方式来解决这个问题。
但是我们不想修改Spark SQL源代码,在Tubi维护一个定制过的Spark版本
为了定制Spark SQL的语法,我们采用了一种非常轻量级的方式,来解决这个问题:
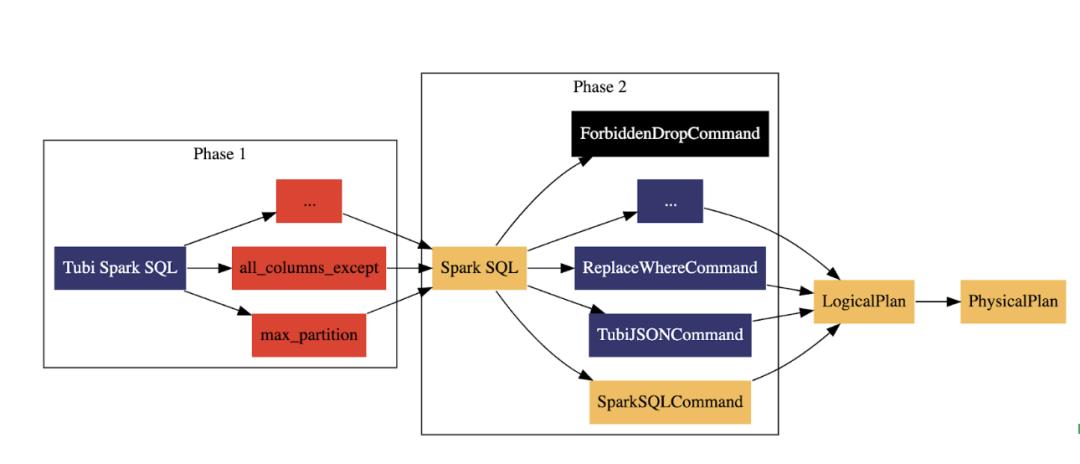
Tubi Spark SQL是在Tubi使用的能够被Spark SQL Parser解析的SQL。
在第一阶段,所有的宏都会被展开,在Tubi Spark SQL中,宏以UDF的语法形式存在,这样保证了Tubi Spark SQL的语法是能够被Spark SQL Parser解析的。值得注意的是,宏只是借用了UDF的语法形式,宏的执行是在第一阶段发生的。宏被展开之后,我们将获得一个新的Spark SQL语句。UDF可以接受column作为参数,而宏只能接受常量,通常情况下,UDF会被执行上亿次,而宏只是会在第一阶段被执行一次。
在第二阶段,通过对语法树的分析,我们可以识别Spark SQL的各种模式,比如如果是drop database或者drop table,我们就将这类SQL路由到ForbiddenDropCommand,而ForbiddenDropCommand什么都不做,只是告诉用户,这类SQL在这个SQL执行器里面无法执行。对于常规的SparkSQL,就路由到SparkSQLCommand执行,对于其它类型的SQL,我们也提供了一些必要的定制。比如,Delta Lake目前已经提供了丰富的编程接口,但是很多编程接口并没有对应的SQL语法可供使用,我们通过识别相关模式,可以将符合这些SQL模式的语法,通过Delta中丰富的编程接口实现。
案例分析:all_columns_except
对于all_columns_except这个例子,实际的执行过程如下:
// 假定tbl这个表有六个字段:col1, col2, col3, col4, col5, col6
select all_columns_except("tbl", "col1", "col5") from tbl
// ---> 第一阶段:宏展开
select col2, col3, col4, col6 from tbl
// ---> 第二阶段:路由到SparkSQLCommand执行
案例分析:tubi_json
对于json支持正则表达式这个例子,实际的执行过程如下:
select * from tubi_json.`s3://bucket/dir/2020-12-13*`
// --> 第一阶段:宏展开(里面没有宏,所以SQL保持不变)
select * from tubi_json.`s3://bucket/dir/2020-12-13*`
// --> 第二阶段:路由到TubiJSONCommand,并执行相关逻辑
1. 从 `s3://bucket/dir/2020-12-13*` 加载数据并为这些数据创建临时表`temp_vew`
2. 执行 spark.sql("select * from temp_view")
通过这种方式,我们就实现了对Spark SQL的定制,且具备以下优势:
不需要修改Spark源代码,维护自己的Spark定制版本;
不需要自定义Antlr 4的语法文件,复用既有的Spark SQL Parser和语法定义;
在Spark的基础上,无痛实现和升级各种定制语法的功能。
Antlr 4生成的Parser代码非常复杂,基于这些生成代码做研发,代码很难维护
在这个问题中,最麻烦的事情莫过于做宏的替换和SQL的模式识别。
对于宏的替换而言,只要了解Antlr 4中和Rewriter相关的API,问题就可以迎刃而解。
对于模式识别而言,我们需要分析抽象语法树,将符合特定模式的SQL路由到特定的Command执行。Antlr 4提供了两种模式来访问从SQL构建的抽象语法树:Listener和Visitor。Spark Catalyst模块所使用的是Visitor模式。对于Apache Spark这样的大型项目来说,Visitor模式是适用的,但是对于我们来说,无论是Vistor模式还是Listener模式,都过于复杂。如果是一次性的抽象树分析,我们还可以使用Antlr支持的XPath,采用XPath这种方式的和采用正则表达式做文本处理的缺陷是类似的,诘屈聱牙且难以维护。
Scala标准库中的集合,提供了大量易用的算子,比如map/filter/count/find等。Apache Spark的API设计也受到了Scala标准库中这些算子的影响,无论是偏底层的RDD还是应用层DataFrame,都会实现这些算子。
对于从SQL构建的抽象语法树,我们也可以设计类似的算子:

比如,判断一个SQL中是否存在tubi_json.`s3://xxxx/yyyy*`这种模式,基于上面的算子,相关代码如下,简洁且易于维护:

对于这个话题,在上一次Scala Meetup中,我们已经使用四则运算表达式化简这个例子,完整的讲解了其中的设计实现和技术细节。本文不再赘述,感兴趣的读者阅读的第三部分,相关视频回放也可以在“比图科技”的官方Bilibili帐号找到。
另外,此次我在Datafun的年终大会的大数据架构论坛会有更详细的一些分享,也欢迎大家一起交流:
审校:杨宇佳@Tubi
以上是关于定制Spark SQL: 一种轻量级实现方案的主要内容,如果未能解决你的问题,请参考以下文章
一个类文件搞定SQL条件映射解析,实现轻量简单实用ORM功能