SQL经典面试案例之SparkSQL和DSL风格编程实践
Posted Java之大数据开发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL经典面试案例之SparkSQL和DSL风格编程实践相关的知识,希望对你有一定的参考价值。
饱受RDD编程的折磨,如同前期编写MR程序时的煎熬,而今遇上spark sql和DSL编程,才知遇上了真爱,真宛如斯人若彩虹,遇上方知有。
SQL常见面试场景中无非逐行运算、分组聚合运算、划窗口运算三种,熟练掌握了这三种,相信在各个大数据的SQL面试当中,都不会有太大的问题。
连续活跃用户案例
有数据如下:
uid,dtguid01,2018-02-28guid01,2018-03-01guid01,2018-03-01guid01,2018-03-02guid01,2018-03-05guid01,2018-03-04guid01,2018-03-06guid01,2018-03-07guid02,2018-03-01guid02,2018-03-02guid02,2018-03-03guid02,2018-03-06
现要求连续登录天数大于或等于两天的用户记录
SparkSQL实现方式:
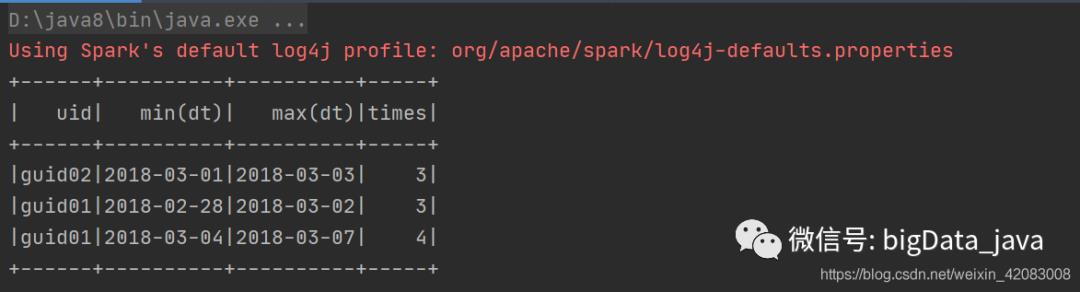
//创建SparkSessionval spark = SparkSession.builder().appName(this.getClass.getSimpleName).master("local[*]").getOrCreate()//纯sql进行查询数据val df1: DataFrame = spark.read.option("header", "true").csv("data1.txt")df1.createTempView("tb_log")//uid01,2018-03-01// 第一种实现方式写sqlval df2 = spark.sql("""||select|uid,|min(dt) as min_dt,|max(dt) as max_dt,|count(date_diff) as times|from|(select|uid,|dt,|date_sub(dt,dt_num) as date_diff| from| (| select| uid,| dt,| row_number() over(partition by uid order by dt asc) as dt_num| from| (| select| distinct(uid,dt),uid,dt| from tb_log| )t1| )t2)| group by uid,date_diff having times>=3|""".stripMargin).show()
运行结果显示:
DSL风格代码实现:
//第二种方式 使用DSL风格的代码实现import spark.implicits._import org.apache.spark.sql.functions._df1.distinct().select('uid, 'dt,(row_number() over (Window.partitionBy("uid").orderBy("dt"))) as 'rn).select('uid,'dt,date_sub('dt, 'rn) as 'date_diff).groupBy('uid, 'date_diff)//假如要多个聚合时 使用agg.agg(min("dt"),max("dt"),count("*") as "times").where('times >= 2).drop("date_diff").show()
运行结果显示:
店铺每月累计案例
现有数据如下:
sid,dt,money
shop1,2019-01-18,500
shop1,2019-02-10,500
shop1,2019-02-10,200
shop1,2019-02-11,600
shop1,2019-02-12,400
shop1,2019-02-13,200
shop1,2019-02-15,100
shop1,2019-03-05,180
shop1,2019-04-05,280
shop1,2019-04-06,220
shop2,2019-02-10,100
shop2,2019-02-11,100
shop2,2019-02-13,100
shop2,2019-03-15,100
shop2,2019-04-15,100
计算店铺的与销售额和累加到当前月的销售和
期望得到的结果为:
+--------+------+------------+--------------+--+
| sid | mth | mth_sales | total_sales |
+--------+------+------------+--------------+--+
| shop1 | 1 | 500.0 | 500.0 |
| shop1 | 2 | 2500.0 | 3000.0 |
| shop1 | 3 | 180.0 | 3180.0 |
| shop1 | 4 | 500.0 | 3680.0 |
| shop2 | 2 | 100.0 | 100.0 |
+--------+------+------------+--------------+--+
SparkSQL实现方式:
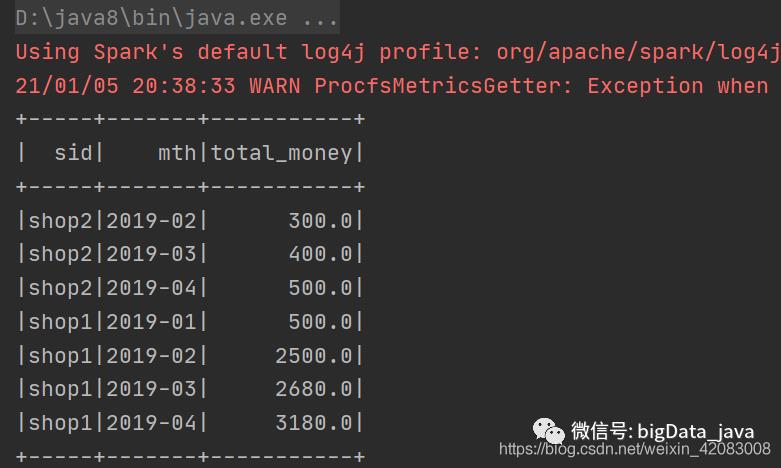
/*** @author:tom* @Date:Created in 9:42 2021/1/5*/object AccumulateDemo {Logger.getLogger("org").setLevel(Level.WARN)def main(args: Array[String]): Unit = {//创建SparkSessionval spark = SparkSession.builder().appName(this.getClass.getSimpleName).master("local[*]").getOrCreate()//纯sql进行查询数据val df1: DataFrame = spark.read.option("header", "true").csv("shop.csv")df1.createTempView("v_shop")spark.sql(s"""|select|sid,|mth,|sum(mth_money) over(partition by sid order by mth) as total_money|from|(|select|sid,|mth,|sum(money) as mth_money|from|(|select|sid,|date_format(dt,"yyyy-MM") as mth,|cast(money as double) as money|from v_shop|) t1 group by sid,mth) t2||""".stripMargin).show()
运行结果显示:
DSL风格代码实现:
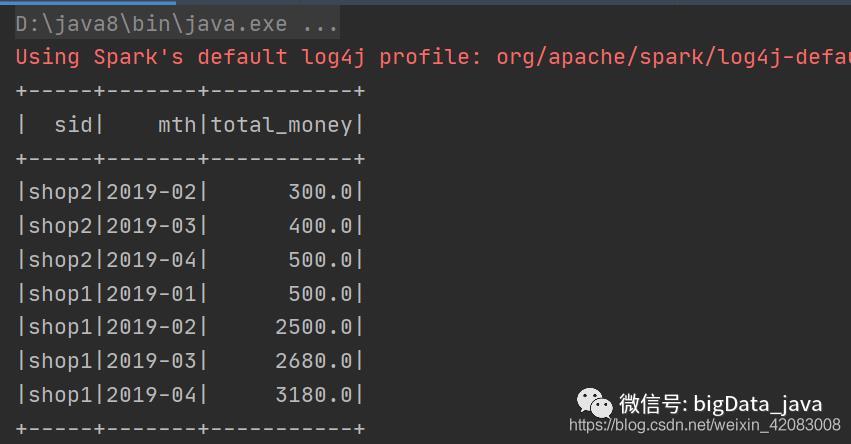
//dsl风格编程import spark.implicits._import org.apache.spark.sql.functions._df1.select($"sid",'money.cast(DataTypes.DoubleType) as "money",expr("date_format(dt, 'yyyy-MM') as mth")).groupBy("sid", "mth").sum("money").withColumnRenamed("sum(money)", "mth_money").select($"sid",$"mth",sum("mth_money").over(Window.partitionBy("sid").orderBy("mth")) as "total_money").show()
美团SQL面试题之流量统计
现有数据如下:
uid,start_dt,end_dt,flow
1,2020-02-18 14:20:30,2020-02-18 14:46:30,20
1,2020-02-18 14:47:20,2020-02-18 15:20:30,30
1,2020-02-18 15:37:23,2020-02-18 16:05:26,40
1,2020-02-18 16:06:27,2020-02-18 17:20:49,50
1,2020-02-18 17:21:50,2020-02-18 18:03:27,60
2,2020-02-18 14:18:24,2020-02-18 15:01:40,20
2,2020-02-18 15:20:49,2020-02-18 15:30:24,30
2,2020-02-18 16:01:23,2020-02-18 16:40:32,40
2,2020-02-18 16:44:56,2020-02-18 17:40:52,50
3,2020-02-18 14:39:58,2020-02-18 15:35:53,20
3,2020-02-18 15:36:39,2020-02-18 15:24:54,30
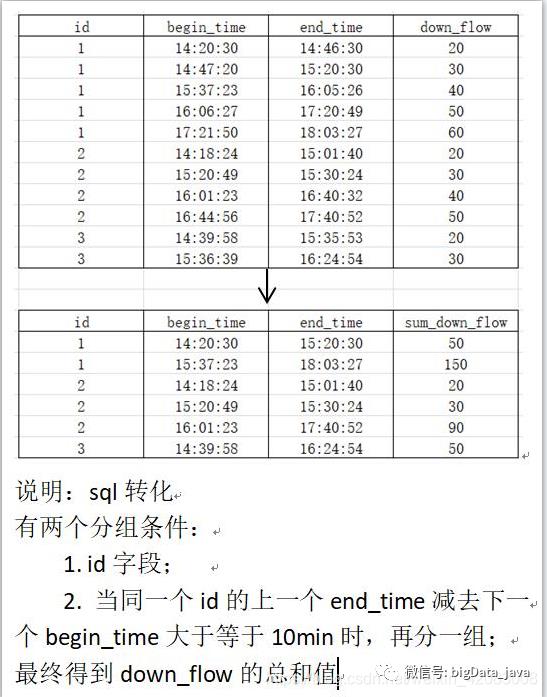
要求如下图:
SparkSQL实现方式:
/*** @author:tom* @Date:Created in 19:41 2021/1/5*/object FlowDemo {Logger.getLogger("org").setLevel(Level.WARN)def main(args: Array[String]): Unit = {//创建SparkSessionval spark = SparkSession.builder().appName(this.getClass.getSimpleName).master("local[*]").getOrCreate()//uid,start_dt,end_dt,flow//1,2020-02-18 14:20:30,2020-02-18 14:46:30,20//纯sql进行查询数据val df1: DataFrame = spark.read.option("header", "true").csv("flow.txt")df1.createTempView("v_flow")spark.sql("""||select| uid,| min(start_dt) as start_dt,| max(end_dt) as end_dt,| sum(flow) as flow|from|(|select|uid,|start_dt,|end_dt,|sum(lag_num) over(partition by uid order by start_dt)as flag,|flow|from|(|select|uid,|start_dt,|end_dt,|if((to_unix_timestamp(start_dt)-to_unix_timestamp(lag_time))/60>10,1,0) as lag_num,|flow|from|(|select|uid,|start_dt,|end_dt,|flow,|lag(end_dt,1,start_dt) over(partition by uid order by start_dt) as lag_time|from v_flow|)t1 )t2 )t3 group by uid,flag|""".stripMargin).show()
运行结果如下图:
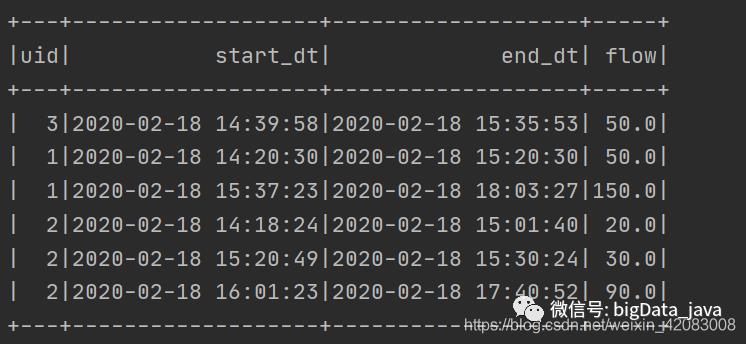
DSL风格代码实现:
import spark.implicits._import org.apache.spark.sql.functions._//dsl风格代码df1.select($"uid",$"start_dt",$"end_dt",$"flow",expr("lag(end_dt) over(partition by uid order by start_dt) as lag_time")).select($"uid",$"start_dt",$"end_dt",$"flow",expr("if((to_unix_timestamp(start_dt)-to_unix_timestamp(lag_time))/60>10,1,0) as lag_num")).select($"uid",$"start_dt",$"end_dt",$"flow",sum("lag_num").over(Window.partitionBy("uid").orderBy("start_dt")) as "flag").groupBy("uid","flag").agg(min("start_dt") as "start_dt",max("end_dt") as "end_dt",sum("flow") as "flow").drop("flag").orderBy("uid").show()
运行结果如下图:(注:和第一种方式结果不一样,是因为这种我加了排序)
(建议收藏)
以上是关于SQL经典面试案例之SparkSQL和DSL风格编程实践的主要内容,如果未能解决你的问题,请参考以下文章
spark中使用sparksql对日志进行分析(属于小案例)
经典的SparkSQL/Hive-SQL/MySQL面试-练习题