爬虫框架-crawler
Posted AllTests
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫框架-crawler相关的知识,希望对你有一定的参考价值。
第一时间关注技术干货!
crawler
目录
1、简介
2、安装部署
3、框架说明
4、使用框架
crawler采用requests+lxml的方式进行爬虫,爬取内容和url采用XPath方式一致(关于XPath可参考章节)。
GitHub网址:https://github.com/shuizhubocai/crawler
requests是Python的一个优秀第三方库,适合于人类使用的HTTP库,封装了许多繁琐的HTTP功能,极大地简化了HTTP请求所需要的代码量。
lxml是Python的一个解析库,支持html和XML的解析,支持XPath解析方式,而且解析效率非常高。
在Windows环境(64位)下Python版本为3.6.5。
1、打开官方网址进行下载,下载完成为crawler-master.zip文件。

2、解压文件到指定目录(例如D:crawler)。
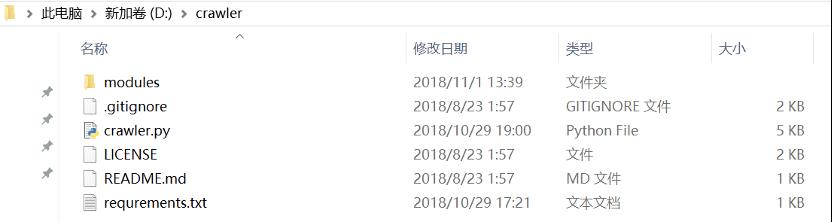
3、安装目录下,命令行运行pip install -r requrements.txt安装框架所依赖的库文件。
requrements.txt文件内容:
certifi==2018.4.16
chardet==3.0.4
idna==2.7
requests==2.19.1
urllib3==1.23
4、安装lxml,版本号为4.2.5。
下载指定版本,cp36代表Python 3.6的版本,win_amd64代表64位的系统,所以需要选择正确,否则安装过程会报错平台不匹配。

下载完成后开始安装lxml,在命令行中进入安装文件所在路径输入命令即可。
pip install lxml-4.2.5-cp36-cp36m-win_amd64.whl
1、crawler.py文件:
Download类:页面下载器
Parser类:页面解析器
Output类:导出数据到HTML
Scheduler类:爬虫调度器
2、modulesuseragent目录下的chrome.py、firefox.py等为浏览器代理。
3、data.html将爬取的数据导入到此文件里。
如图所示:要获取的帖子标题。

如图所示:获取1-10页。

1、修改脚本(crawler.py文件)。
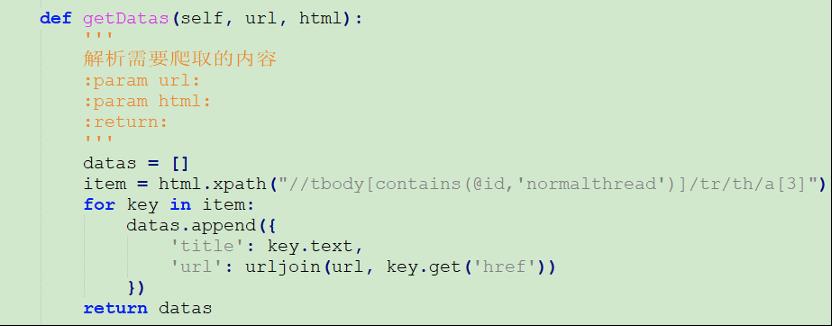
(1)修改Parser类,getDatas方法的html.xpath值。
//tbody[contains(@id,'normalthread')]/tr/th/a[3]
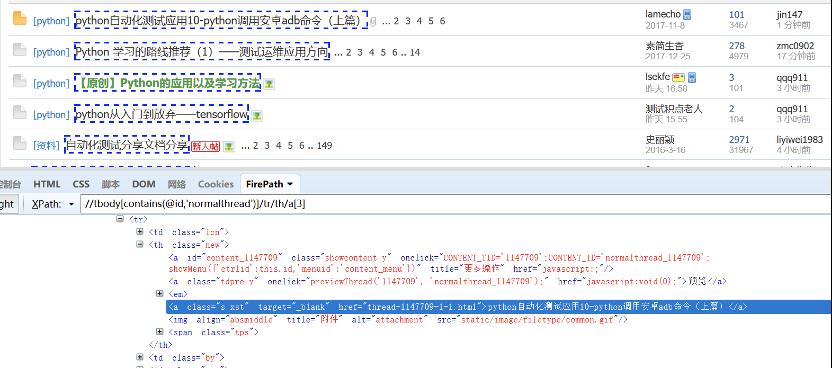
如图所示:使用Firefox+FirePath进行调试定位。
(2)修改Parser类,getUrls方法的html.xpath值。
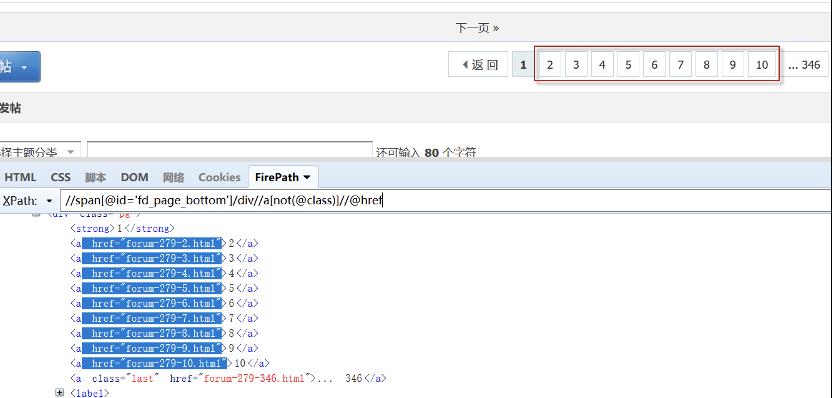
//span[@id='fd_page_bottom']/div//a[not(@class)]//@href
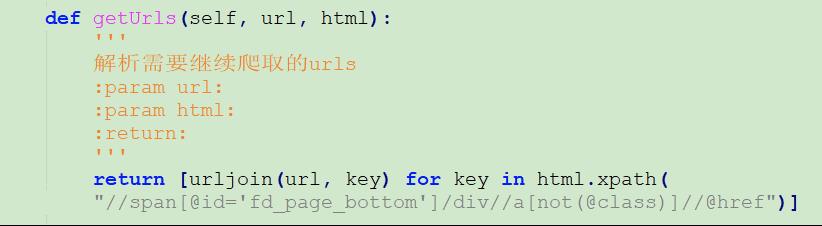
如图所示:使用Firefox+FirePath进行调试定位。
(3)实例化

2、执行脚本(crawler.py文件)。
安装目录下,命令行运行python crawler.py
3、查看爬取结果。
脚本执行完成后,在安装目录下会自动生成data.html文件。

「 爬虫框架crawler 」
即可获得全部资源!
如果您觉得文章还不错,请 点赞、分享、在看、收藏 一下,因为这将是我持续输出更多优质文章的最强动力!
没有关注的小伙伴,扫描下方二维码,获取更多精彩!
也可以在下方【写留言】进行留言讨论哦!期待!
扫码关注
获取更多精彩
AllTests


扫描作者微信,备注「 交流群 」,拉你进群交流!
(谢绝广告党,非诚勿扰!)
- End -
以上是关于爬虫框架-crawler的主要内容,如果未能解决你的问题,请参考以下文章