面试官:说说Netty断开连接的原理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试官:说说Netty断开连接的原理相关的知识,希望对你有一定的参考价值。
参考技术A 多路复用器(Selector) 接收到OP_READ事件:处理OP_READ事件: NiosocketChannel.NioSocketChannelUnsafe.read()
关闭连接,会触发OP_READ 事件:
到了最后,关闭 selection上的 selectionkey,这样selector 上就不会再发生该channel上的各种事件了。
如果发送数据的时候,突然把连接关闭掉了,这种不正常的取消连接如何执行的呢?
这里捕获
处理 IO 异常
所以正常关闭和异常关闭处理是不同的
阿里面试官:说说Redis主从复制原理
在Redis复制的基础上(不包括Redis Cluster、Redis Sentinel),使用和配置主从复制非常简单,能使得【从Redis服务器】(后文称 slave)能精确得复制【主Redis服务器】(下文称 master)的内容。
每当 slave 和 master 之间的连接断开时, slave 会自动重连到 master,并且无论这期间 master 发生了什么, slave 都将尝试让自身成为 master 的精确副本。
那这到底是怎么做到的呢?
1 依赖机制
该系统的运行依靠如下重要机制:
1.1 更新 slave
当一个 master 和一个 slave 连接正常时, master 会发送一连串命令流保持对 slave 的更新,以便将自身数据集的改变复制给 slave,这包括客户端的写入、key 的过期或被逐出等。
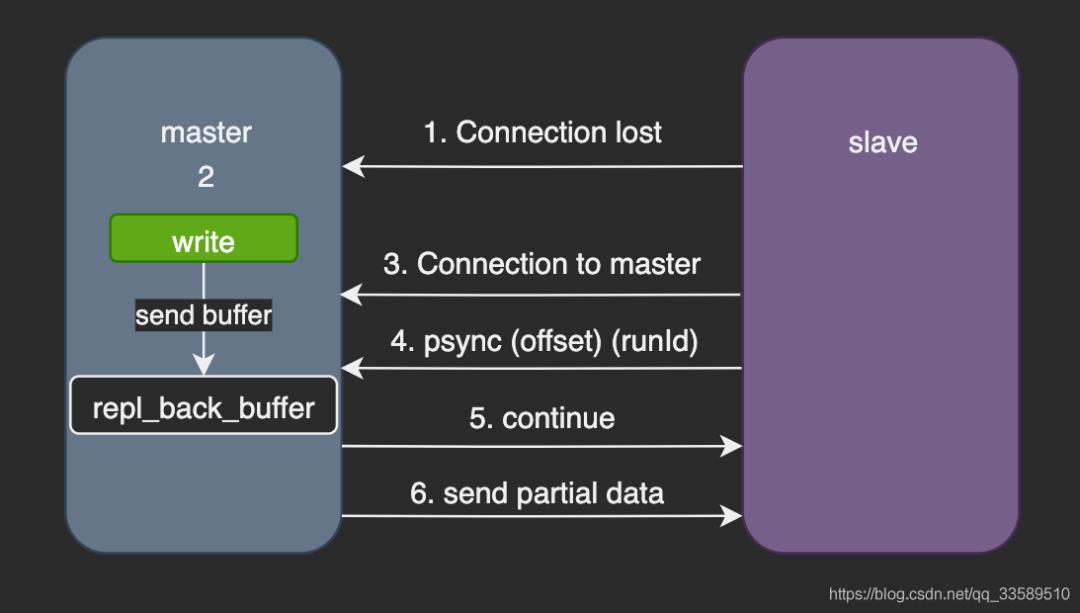
1.2 部分重同步

当 master 和 slave 断连后,由于网络问题或是主从意识到连接超时,slave 重新连接上 master 并会尝试进行部分重同步:它会尝试只获取在断开连接期间内丢失的命令流
1.3 全量重同步
当无法进行部分重同步时, slave 会请求全量重同步。这更复杂,比如master需创建所有数据的快照,将之发送给 slave ,之后在数据集更改时持续发送命令流到 slave。
Redis使用默认的异步复制,低延迟且高性能,适用于大多数 Redis 场景。但slave会异步确认从master周期接收到的数据量。
客户端可用 WAIT 命令请求同步复制某些特定的数据。但WAIT只能确保在其他 Redis实例中有指定数量的已确认的副本:在故障转移期间,由于不同原因的故障转移或由于 Redis 持久性的实际配置,故障转移期间确认的写入操作可能仍然会丢失。
2 Redis 复制的特点
Redis 使用异步复制
slave 和 master 间异步地确认处理的数据量
一个 master 可有多个 slave
slave 可接受其他 slave 的连接
除了多个 slave 可以连接到同一 master,slave 间也可以像层级连接其它 slave。Redis 4.0起,所有 sub-slave 将会从 master 收到完全一样的复制流Redis 复制在 master 侧是非阻塞的
master 在一或多 slave 进行初次同步或者是部分重同步时,可以继续处理查询请求复制在 slave 侧大部分也是非阻塞
当 slave 进行初次同步时,它可以使用旧数据集处理查询请求,假设在 redis.conf 中配置了让 Redis 这样做。否则,你可以配置如果复制流断开, Redis slave 会返回一个 error 给客户端。但在初次同步后,旧数据集必须被删除,同时加载新的数据集。slave 在这个短暂的时间窗口内(如果数据集很大,会持续较长时间),会阻塞到来的连接请求。自 Redis 4.0 开始,可以配置 Redis 使删除旧数据集的操作在另一个不同的线程中进行,但是,加载新数据集的操作依然需要在主线程中进行并且会阻塞 slave复制可被用在可伸缩性,以便只读查询可以有多个 slave 进行(例如 O(N) 复杂度的慢操作可以被下放到 slave ),或者仅用于数据安全和高可用
可使用复制来避免 master 将全部数据集写入磁盘造成的开销:一种典型的技术是配置你的 master 的
redis.conf以避免对磁盘进行持久化,然后连接一个 slave ,配置为不定期保存或是启用 AOF。但是,这个设置必须小心处理,因为重启的 master 将从一个空数据集开始:如果一个 slave 试图与它同步,那么这个 slave 也会被清空!
3 单机“危机”
容量瓶颈
机器故障
QPS瓶颈
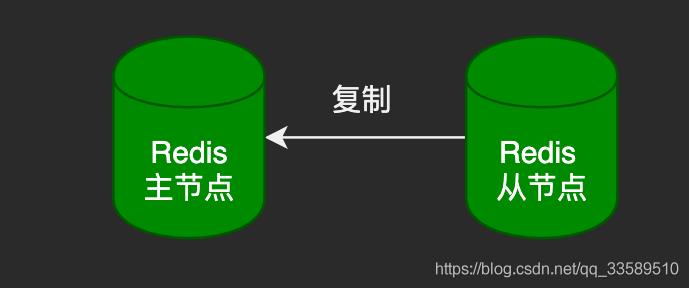
一主多从
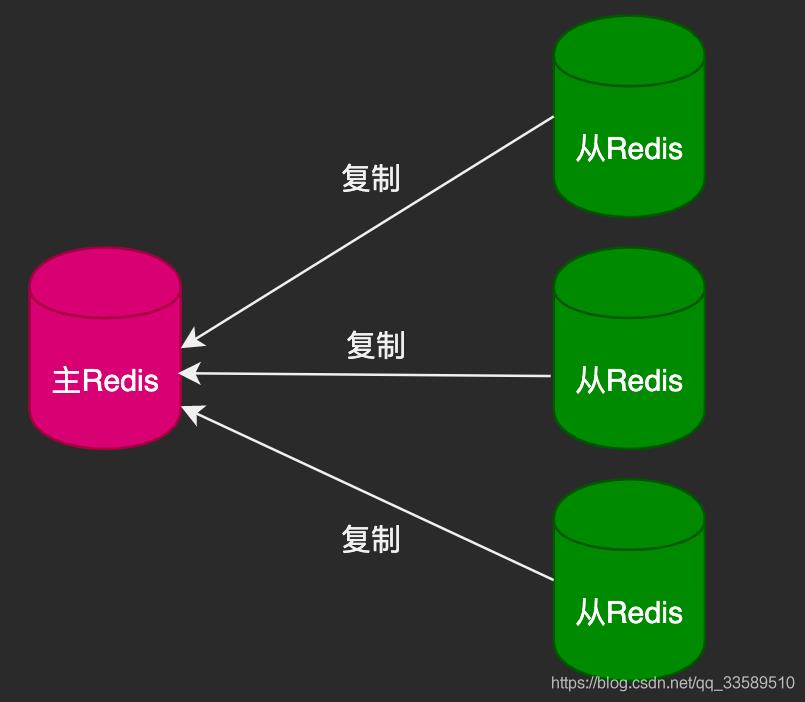
3.1 主从复制作用
数据副本
扩展读性能
3.2 总结
一个master可以有多个slave
一个slave只能有一个master
数据流向是单向的,master => slave
4 实现复制的操作
4.1 命令:slaveof
异步执行,很耗时间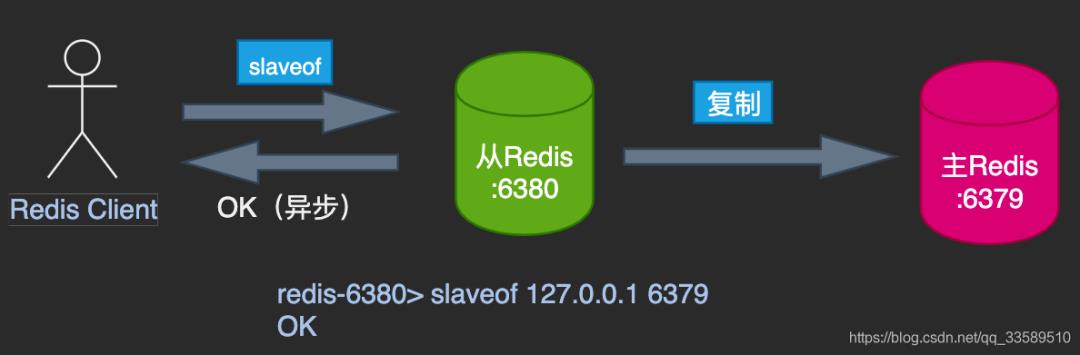
无需重启,但不便于配置的管理。
4.2 配置
slaveof ip portslave-read-only yes
虽然可统一配置,但需重启。
5 全量复制
master执行
bgsave,在本地生成一份RDB快照client-output-buffer-limit slave 256MB 64MB 60master将RDB快照发送给salve,若RDB复制时间超过60秒(repl-timeout),那么slave就会认为复制失败,可适当调大该参数(对于千兆网卡的机器,一般每秒传输100MB,6G文件,很可能超过60s)
master在生成RDB时,会将所有新的写命令缓存在内存中,在salve保存了rdb之后,再将新的写命令复制给salve
若在复制期间,内存缓冲区持续消耗超过64MB,或者一次性超过256MB,那么停止复制,复制失败
slave node接收到RDB之后,清空自己的旧数据,然后重新加载RDB到自己的内存中,同时基于旧的数据版本对外提供服务
如果slave开启了AOF,那么会立即执行BGREWRITEAOF,重写AOF
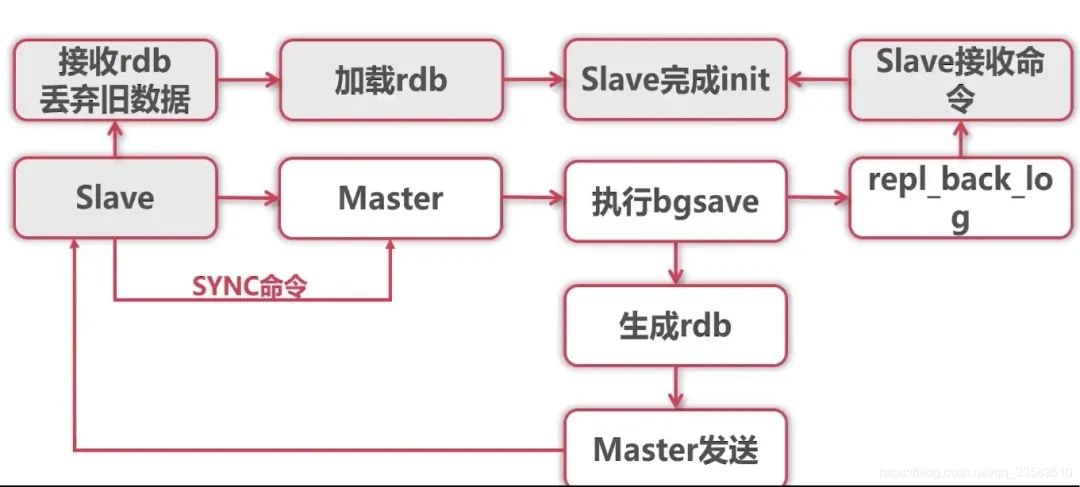
RDB生成、RDB通过网络拷贝、slave旧数据的清理、slave aof rewrite,很耗费时间
如果复制的数据量在4G~6G之间,那么很可能全量复制时间消耗到1分半到2分钟
5.1 全量复制开销
bgsave时间
RDB文件网络传输时间
从节点清空数据时间
从节点加载RDB的时间
可能的AOF重写时间
5.2 全量同步细节
master 开启一个后台save进程,以便生成一个 RDB 文件。同时它开始缓冲所有从客户端接收到的新的写入命令。当后台save完成RDB文件时, master 将该RDB数据集文件发给 slave, slave会先将其写入磁盘,然后再从磁盘加载到内存。再然后 master 会发送所有缓存的写命令发给 slave。这个过程以指令流的形式完成并且和 Redis 协议本身的格式相同。
当主从之间的连接因为一些原因崩溃之后, slave 能够自动重连。如果 master 收到了多个 slave 要求同步的请求,它会执行一个单独的后台保存,以便于为多个 slave 服务。
6 增量复制
如果全量复制过程中,master-slave网络连接中断,那么salve重连master时,会触发增量复制
master直接从自己的backlog中获取部分丢失的数据,发送给slave node
msater就是根据slave发送的psync中的offset来从backlog中获取数据的
往期推荐
喜欢文章,点个“在看、点赞、分享”素质三连支持一下~
以上是关于面试官:说说Netty断开连接的原理的主要内容,如果未能解决你的问题,请参考以下文章