JIT即时编译器(C1和C2)
Posted Different Java
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JIT即时编译器(C1和C2)相关的知识,希望对你有一定的参考价值。
上一篇文章我们已经讲述了的基本原理,今天我们看一下HotSpot虚拟机中具体的编译器。
1. Client Compiler(C1编译器)
C1编译器启动速度快,但是性能相比较Server Compiler相对来说会差一些,下面我们主要看一下C1编译器的具体步骤。
1.1 预准备工作
C1编译器会基于字节码完成部分优化,如:方法内联、常量传播。
方法内联是后面编译过程优化的关键前提。
1.2 构造HIR
C1编译器将字节码构造成一种高级代码表示(HIR),HIR使用静态单分配(SSA)的形式来代表代码值。
通过借助HIR我们可以实现冗余代码消除、死代码删除等编译优化工作,SSA的每个变量只能被赋值一次,并且只有当变量被赋值后才能使用。
1.2.1 冗余删除
a = 1;
a = 2;
b = a;
上述代码可以很容易发现a=1这一行是多余的,但是如果编译器基于字节码并不容易发现,需要借助数据流分析从后往前依次确认哪些变量的值被覆盖掉,但是借助SSA,编译器很容易识别冗余赋值,SSA的伪代码如下:
a_1=1;
a_2=2;
b_1=a_2;
借助SSA中变量的特性,原来的对a变量赋值2次转变成了对a_1、a_2变量分别赋值一次,编译器可以很容易可以发现a_1变量在赋值以后没有被使用,然后对这一行进行删除,避免多余的赋值操作。
除了进行冗余删除的优化以外,该阶段也会进行空值检查消除、范围检查消除等优化构成。
1.3 构造LIR
在构造出HIR,并且对代码优化过后,会将HIR转换成低级中间表示(LIR),LIR的表现形式也是SSA。
在LIR的基础上会进行寄存器分配、窥孔优化等操作,最终生成机器代码。
Client Compiler的编译流程大致如下图:
2. Server Compiler
Server Compiler关注的是编译耗时较长的全局优化,甚至还会根据程序运行时收集到的信息进行不可靠的激进优化。Server Compiler通常比Client Compiler启动时间长,适合用于长时间在后台运行的程序(Web服务)。
Sever Compiler几乎会执行所有经典的优化工作,如:无用代码消除、循环展开、循环表达式外提、消除公共子表达式、常量传播、基本块重排序、Java语言紧密相关的优化技术(范围检查消除、空值检查消除)、分支频率预测等。
HotSpot虚拟机目前有两种:C2和Graal。
2.1 Graal
Graal编译器是JDK 9中的编译器,相比C2编译器,Graal有以下特性:
-
Graal比C2更加青睐于分支预测,选择性的编译一些运行概率较大的分支 -
使用Java编写,对于Lambda、Stream等新特性更加友好 -
更深层次的优化,如虚函数的内联、部分逃逸分析等
2.1 C2
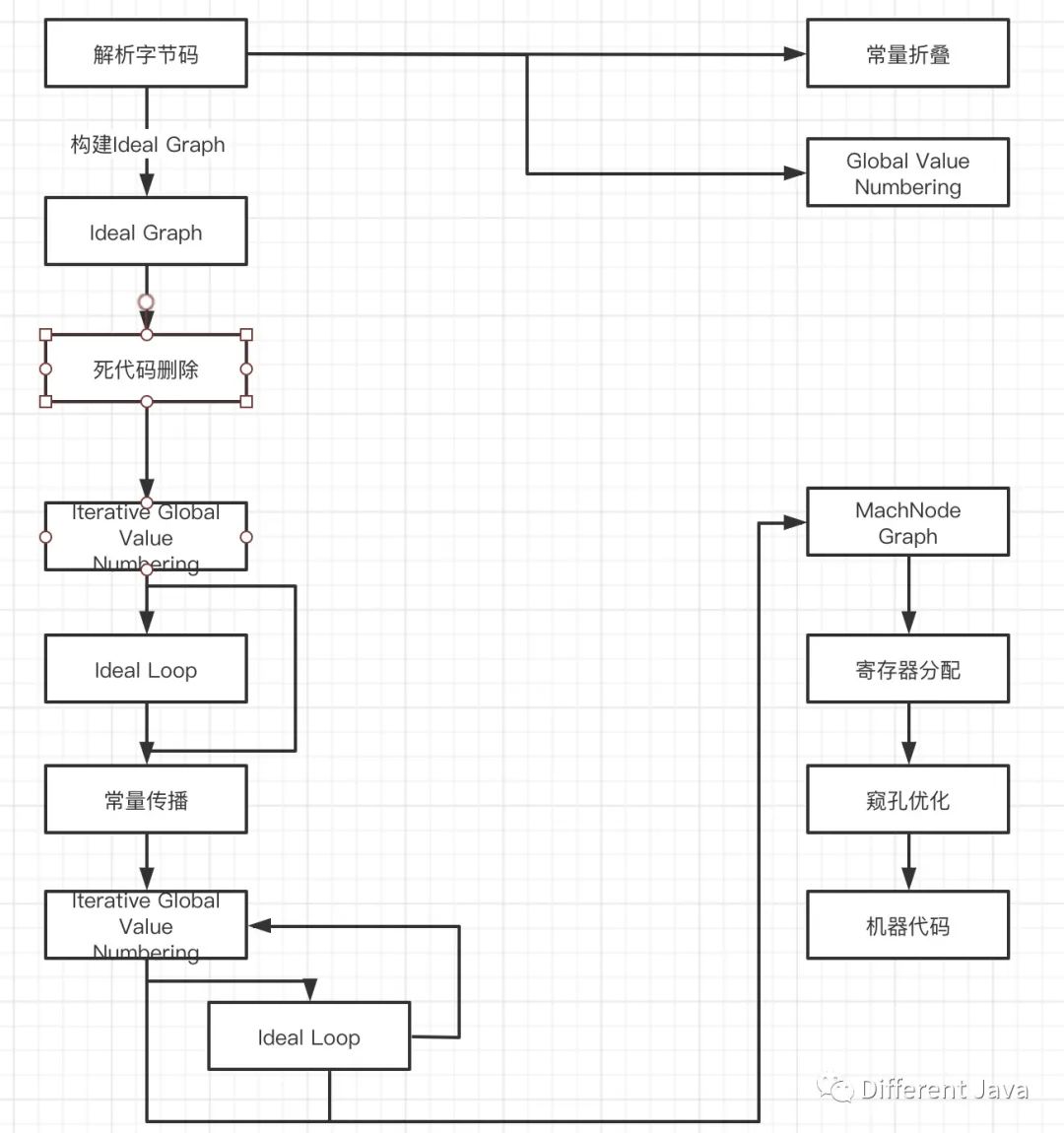
C2编译器在编译优化时,使用一种控制流与数据流结合的图数据结构,成为Ideal Graph。
Ideal Graph在解析字节码的时候,根据字节码的指令向一个空的Graph中添加节点,该节点通常对应一个指令块,每个指令块包含多条相关联的指令,JVM会利用优化技术对这些指令进行优化,比如上文中提到的一些优化以及Global Value Numbering、常量折叠等,解析结束后,还会删除死代码。
生成Ideal Graph以后,JVM会判断此时有没有全局优化的必要,如果有必要,则进行优化,否则跳过。
Ideal Graph最终会被转换成更接近机器层面的MachNode Graph,然后进行寄存器的分配、窥孔优化,最终生成机器代码。
2.1.1 Ideal Graph
Ideal Graph采用的是Sea-of-Nodes中间表达形式,同样也是SSA形式的,最大特点就是去除了变量的概念,直接采用值来进行运算。
public static int test(int count) {
int sum = 0;
for (int i = 0; i < count; i++) {
sum += i;
}
return sum;
}
我们使用Ideal Graph Visuallizer工具来查看一下上述代码的IR图。
红色加粗线条为控制流,蓝色线条为数据流,其他颜色的线条则是特殊的控制流或者数据流。控制流连接的是固定节点,其他的则是浮动节点(浮动节点只要能满足数据依赖关系,可以放在不同位置的节点,浮动节点变动的过程称为Schedule)。
2.1.2 Phi And Region Nodes
Ideal Graph是SSA IR,由于Ideal Graph没有变量的概念,不同的执行路径可能会对同一变量设置不同的值,因此需要解决根据不同的路径,读取不同的值。
为了达到上述目的,引入了Phi And Region Node的概念,可以根据不同的执行路径选择不同的值。
3. 编译优化
3.1 Global Value Numbering
GVN会为每一个计算的值分配一个唯一编号,通过GVN可以消除等价计算的指令。
a = 1;
b = 2;
c = a + b;
d = a + b;
e = d;
GVN计算a=1时假设得到编号1,计算b=2时得到编号2,计算c = a + b时得到编号3,这些编号存放在Hash表中,在计算 d = a + b时,发现a + b已经在Hash表中存在,就不会再进行计算,直接从Hash表中取出计算过的值,最后的e=d也可以从Hash表中查得进行复用。
3.2 方法内联
方法内联是指在编译过程中遇到方法调用时,将目标方法的方法体纳入编译范围之中,并取代方法调用的优化手段。方法内联可以避免栈帧的入栈和出栈。
3.3 逃逸分析
逃逸分析是一种确定指针动态范围的静态分析,分析程序中哪些地方可以访问到对象指针。即时编译器会对对象进行逃逸分析,如果对象没有发生逃逸,则可以进行栈上分配(标量替换),锁消除等优化操作。
3.4 栈上分配
Java对象通常都会在堆上分配,堆上分配的对象如果回收则需要垃圾回收器的接入。假设一个对象经过逃逸分析只可能被当前线程进行访问(线程安全),则该对象则可以直接分配在栈上,分配在栈上可以随着栈帧的弹出被销毁,不需要垃圾回收器的介入。
Java的栈上分配采用标量替换的方式,标量是存储一个值的变量,例如基本类型。编译器会把一个对象中的聚合量(多个实例字段)分解成多个标量在栈上分配。
往期推荐
以上是关于JIT即时编译器(C1和C2)的主要内容,如果未能解决你的问题,请参考以下文章