开窗函数
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开窗函数相关的知识,希望对你有一定的参考价值。
参考技术A 开窗函数需求:
既要显示聚合前的数据,又要显示聚合后的结果
rank
开窗函数:
窗口函数: 窗口 + 函数
窗口: 函数运行时计算的数据集的范围
函数:运行时的函数:
1.常用的聚合函数
2.窗口内置的函数
1.聚合函数 -》开窗
数据:
需求:
统计累计的问题,每个用户每天累计点外卖的次数
函数 over([partition by xxx,...] [order by xxx,...])
2.指定窗口大小
3.开窗 -内置函数
RANK
ROW_NUMBER
DENSE_RANK
NTILE
1.NTILE
需求:
把数据按照姓名进行分组 时间排序 结果数据分成 3份数
NTILE(N):
把数据平均分配到N中,如果不能平均分配,优先分配到较小的编号中。
2.rank相关的
RANK
ROW_NUMBER
DENSE_RANK
RANK:
从1开始,按照顺序,生成组内记录的编号,排序相同会重复,在名次中留下空位
ROW_NUMBER:
从1开始,按照顺序,生成组内记录的编号,序号没有重复的
DENSE_RANK:
从1开始,按照顺序,生成组内记录的编号,排序相同会重复,在名次中不留下空位
3.蹿行问题
lag 向上取第几行
lead 向下取第几行
4.取值问题
FIRST_VALUE(col):取分组后 截止到当前行 第一个值
LAST_VALUE(col):取分组后 截止到当前行 最后一个值
开窗函数案例:
1.我们有如下的用户访问数据
userId visitDate visitCount
u01 2017/1/21 5
u02 2017/1/23 6
u03 2017/1/22 8
u04 2017/1/20 3
u01 2017/1/23 6
u01 2017/2/21 8
U02 2017/1/23 6
U01 2017/2/22 4
要求使用SQL统计出每个用户的累积访问次数,如下表所示:
用户id 月份 小计 累积
u01 2017-01 11 11
u01 2017-02 12 23
u02 2017-01 12 12
u03 2017-01 8 8
u04 2017-01 3 3
每个用户的累积访问次数=》
每个用户每个月累计访问次数
维度: 用户、月
指标:次数、累计访问次数
1.etl:
2017/2/22 =》 2017-02 日期函数 ,string函数 sql里面
2017/2/22=>2017-2-22
2.
1.先求 每个月 次数
2. 1结果 =》 累计
也可以使用str_to_date
date_format(str_to_date(visitdate,'%Y/%m/%d') ,'%Y-%m')as month
2.有50W个京东店铺,每个顾客访客访问任何一个店铺的任何一个商品时都会产生一条访问日志,
访问日志存储的表名为Visit,访客的用户id为user_id,被访问的店铺名称为shop,数据如下:
u1 a
u2 b
u1 b
u1 a
u3 c
u4 b
u1 a
u2 c
u5 b
u4 b
u6 c
u2 c
u1 b
u2 a
u2 a
u3 a
u5 a
u5 a
u5 a
请统计:
(1)每个店铺的UV(访客数) 、pv(访问量)
维度:店铺
指标:uv =》user_id
(2)每个店铺访问次数top3的访客信息。输出店铺名称、访客id、访问次数
维度:店铺、 访客id
指标:访问次数 、访问次数的top3
uv pv :
pv => page 次数 不需要去重
uv => user 次数 需要去重
2.行转列 &&& 列转行
1.列转行
||
v
zuoshao,<王者荣耀,黑丝,看小视频>
xuanxuan,<姐姐,天天,杰伦>
mysql没有collection_list(hobby)
可以使用group_concat(hobby)
-- hive
select
name,
concat_ws(",",collection_list(hobby)) as hobbyies
from t1
group by
name;
concat_ws
concat
2.行转列
hive爆破函数实现
mysql没有爆破函数(免费版本没有)
开窗函数_2
开窗函数
与聚合函数一样,开窗函数也是对行集组进行聚合计算,但是它不像普通聚合函数那样每组只返回一个值,
开窗函数可以为每组返回多个值,因为开窗函数所执行聚合计算的行集组是窗口。
ISO SQL 规定了这样的函数为开窗函数(在 Oracle 中则被称为分析函数,而在 DB2 中则被称为 OLAP 函数)
--要求:查询每个工资小于 5 000 元的员工信息(城市及年龄),并且在每行中都显示所有工资小于 5 000 元的员工个数
-- 意味要列出3个字段: 城市、年龄、个数(薪资<5000)
--先建立一个表结构、例子数据 CREATE TABLE T_Person ( FName VARCHAR(20), FCity VARCHAR(20), FAge INT, FSalary INT) GO INSERT INTO T_Person(FName,FCity,FAge,FSalary) VALUES(‘Tom‘,‘BeiJing‘,20,3000), (‘Tim‘,‘ChengDu‘,21,4000), (‘Jim‘,‘BeiJing‘,22,3500), (‘Lily‘,‘London‘,21,2000), (‘John‘,‘NewYork‘,22,1000), (‘YaoMing‘,‘BeiJing‘,20,3000), (‘Swing‘,‘London‘,22,2000), (‘Guo‘,‘NewYork‘,20,2800), (‘YuQian‘,‘BeiJing‘,24,8000), (‘Ketty‘,‘London‘,25,8500), (‘Kitty‘,‘ChengDu‘,25,3000), (‘Merry‘,‘BeiJing‘,23,3500), (‘Smith‘,‘ChengDu‘,30,3000), (‘Bill‘,‘BeiJing‘,25,2000), (‘Jerry‘,‘NewYork‘,24,3300) --delete from T_Person --select * from T_Person
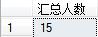
select count(*) as [汇总人数] from T_Person
运行结果: -----------------因为窗口函数时建立在聚合函数之上的,所以此处只是显示一下
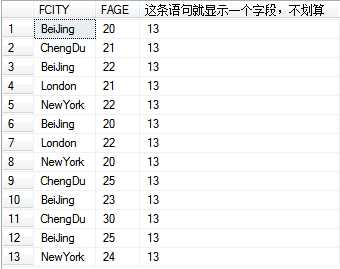
--每行中都显示所有员工薪资<5000的员工的个数 select FCITY,FAGE, ( SELECT COUNT(*) FROM T_Person ----------------->>>这个部分,只是显示了一个字段,不划算 WHERE FSALARY < 5000 ) FROM T_Person WHERE FSALARY < 5000
运行结果:
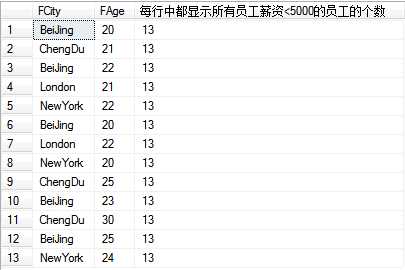
--使用开窗函数统计(每行中都显示所有员工薪资<5000的员工的个数) --开窗函数在聚合函数后增加了一个over关键字 select FCity,FAge,count(*) over() [每行中都显示所有员工薪资<5000的员工的个数] ------>此处OVER()括号中为空,表示对所有行进行聚合计算 from T_Person where FSalary < 5000
运行结果:
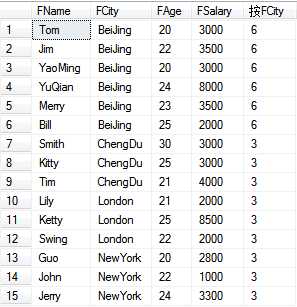
--定义行的分区,从而进行聚合计算 --select * from T_Person select FName,FCity,FAge,FSalary, count(*) over(partition by FCity) as [按FCity] from T_Person
运行结果:
----定义行的分区,从而进行聚合计算 --select * from T_Person select FName,FCity,FAge,FSalary, count(*) over(partition by FAge) as [按FAge] from T_Person
运行结果:
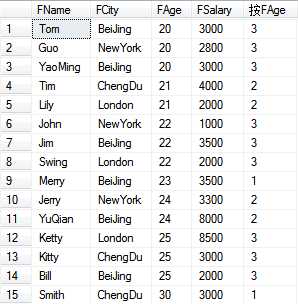
----定义行的分区,从而进行聚合计算 --select * from T_Person select FName,FCity,FAge,FSalary, count(*) over(partition by FAge) as [按FAge] from T_Person
运行结果:
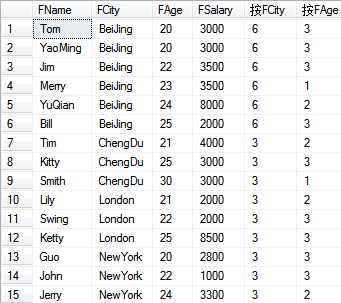
以上是关于开窗函数的主要内容,如果未能解决你的问题,请参考以下文章