C++搞懂char与wchar_t字符串
Posted 原来是个程序猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++搞懂char与wchar_t字符串相关的知识,希望对你有一定的参考价值。
C++里的字符串类型是比较二的,因为有太多表示方法:char*、string、字符串数组、wchar_t*、wstring,今天就来缕一缕这些玩意。
1. char*
char* 貌似是C++字符串最基础最核心的。
看以下四个字符串声明及输出结果:
先说说核心,C里面的字符串就是一连串内存,以内存为0的字节作为结尾。
来分析一下代码,其中str1、str3、str4是一个东西(str3区别只是内存在堆上),str2是字面值常量,str5是单纯的字符数组。
1.1. 常规字符串
对于str1、str3、str4这种正常的字符串,就可以随意拿字符串函数和下标访问,进行各种操作。
在windows下,char*的字符串编码是多字节,用的本地编码,就是我们的GBK。linux下char*直接就是utf8,所以两个平台char*字符串直接交流是不行的。。。
1.2. 字符数组
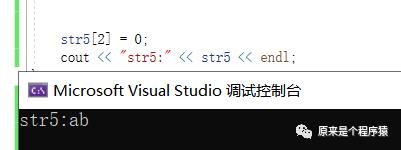
对于str5这种字符数组,因为末尾没有0,所以把他当作字符串直接输出就会有内存里其他数据,就出现了“烫”。。
当我们把字符数组里的某个位置改成0,就可以截断出一个字符串。比如以下代码,把第三个位置设置为0,然后就是字符串“ab”。
1.3. 字面值
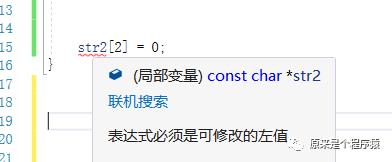
对于str2这种在写代码的时候就是一个常量,当你对这个数据的内存操作的时候就会报错。
比如直接修改str2的元素,ide环境就可以给你报错:
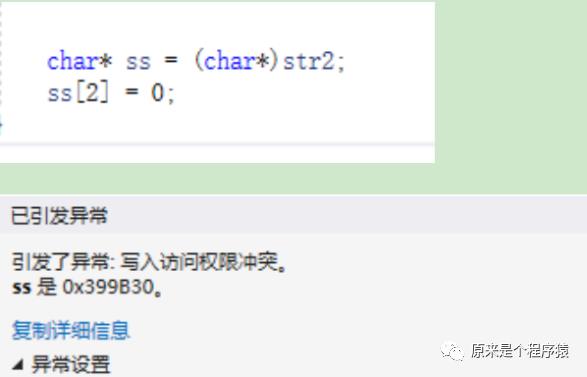
如果我们来硬的,运行的时候就会错误:
2. wchar_t*
首先我们再敲一下重点:C里面的字符串就是一连串内存,以内存为0的字节作为结尾。
记住,这非常重要!!!
wchar_t*与char*字符串主要不同,那就是字符的编码而已。
先看下以下代码和输出:
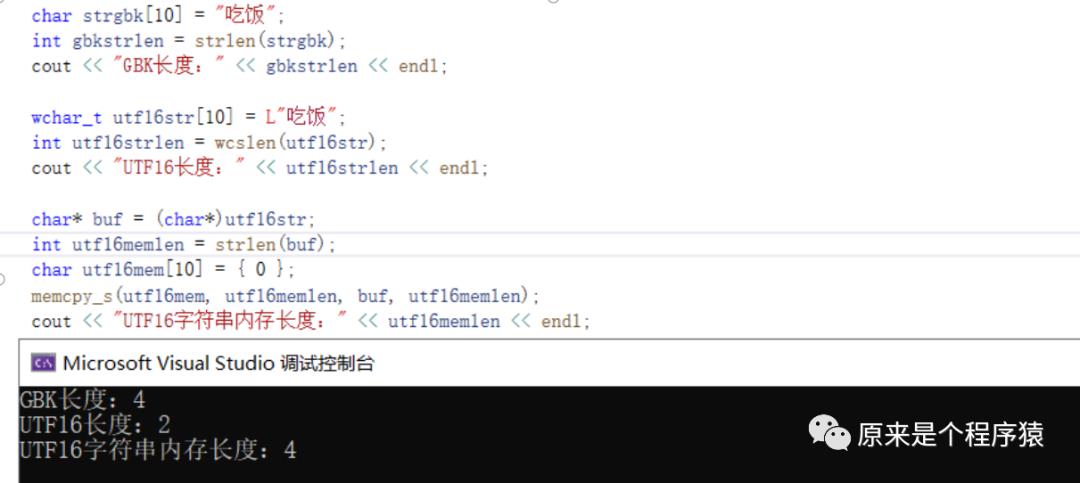
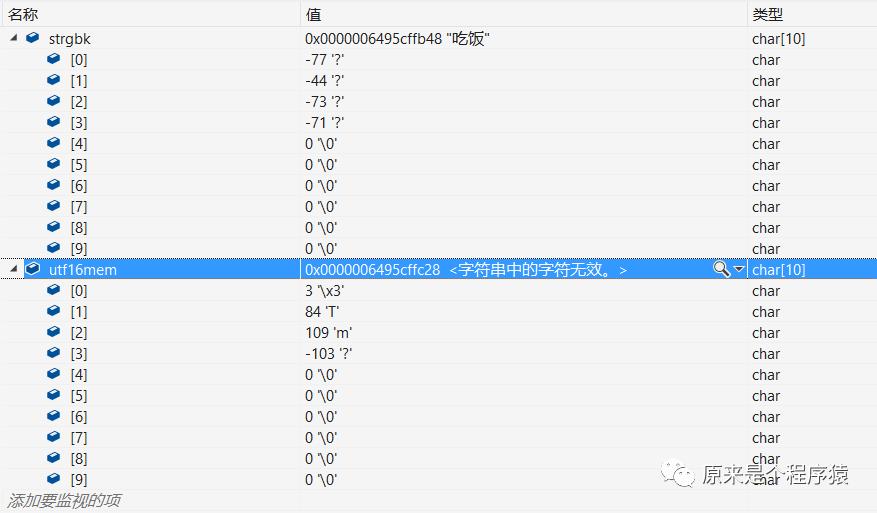
“吃饭”这个字符串,用GBK编码后一共占了5个字节,其中4个字节是用来存放字符串内容的,最后末尾为0。
strlen这个函数,他是一个字节统计一次,出现0就停止,所以gbkstrlen就是4。
对于纯字母来说这没毛病,但对于中文来说,显然“吃饭”这是两个字符。
utf16是用unicode编码(全世界所有字符都有唯一一个数字表示),每个字符都用两个字节来存储unicode编码数字。
C++里utf16字符串需要用L开头,所以得写成 L"吃饭" 这种。
这时,我们用wcslen函数就可以计算出"吃饭"的长度是2。
哎,其实这也真的挺二的。。。因为简单来说utf16一定是每个字符2个字节,所以用strlen计算到末尾长度一定是2的倍数。除以2就肯定是实际长度了。
所以当我们用char* buf = (char*)utf16str;强转成char*然后用strlen计算出的utf16memlen就是4。
看一下内存里的情况,两个字符串都是占用4个字节,但是每个字节里存储的内容是不一样的。
其实C++里的wchar_t*挺鸡肋的感觉,现在utf8比较普遍。因为一刀切地用2个字节表示,对于纯英文字符那直接是浪费一倍的空间。所以utf8这种变长编码就比较合适。
utf8也是Unicode编码数字,就是根据每个字节前面的二进制位决定后面使用几个字节来表示一个unicode编码。
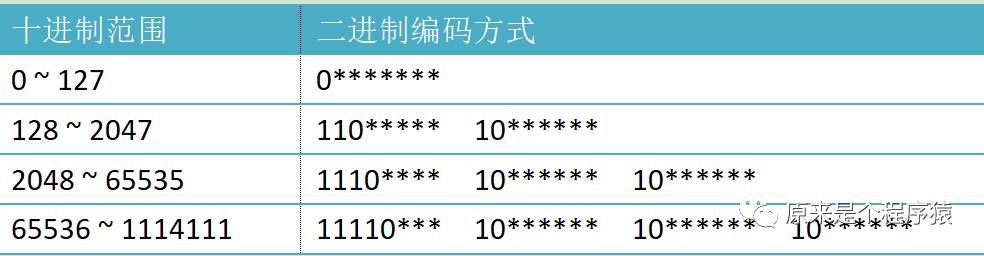
比如对于0到127,因为第一个字节第一个位是0,所以后面不使用任何字节,就一个字节表示Unicode编码。
对于128-2047,因为第一个字节0之前出现2个1,所以后面再使用两个字节(每个字节最前面都是10)。
我们用windowsAPI将wchar_t*字符串转utf8看下:
可以看出来用WideCharToMultiByte得出的内存占用大小和强制按照char*算出的utf8字符串的一样长。
对比看下,内存中和gbk与utf16的都不一样:
可惜的是VC++中没法显示utf8字符串,不过在linux下就用char*就够了,直接utf8。
3. string和wstring
这俩就是char*和wchar_t*的封装,变成了类对象管理字符串。
以上是关于C++搞懂char与wchar_t字符串的主要内容,如果未能解决你的问题,请参考以下文章