Scala从零起步:变量和标识符
Posted 小数志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scala从零起步:变量和标识符相关的知识,希望对你有一定的参考价值。
导读
上周,开启了作为大数据分析师学习,旨在提纲挈领的介绍Scala理念、特性及开发环境安装。今天开始进入Scala从零起步正题:变量和标识符。
在学习一门编程语言过程中,变量应该是继输出“hello,world”之后的第一个核心概念:在计算机程序的世界里,变量可看做是连接程序员和二进制字节码之间的桥梁。一般而言,程序员所说的变量是通常是指代一个或一组数据,然而按照Scala的价值观,函数其实也可算作变量。甚至广义的辩证来讲,一段程序代码中绝大多数部分都是由各种变量组成的。作为入门第一课,本文所指代变量当然仅特指狭义的“变量”——即指代一个或一组数据的变量。
本文主要分享三个问题:
如何定义一个变量
变量的数据类型
变量/标识符命名规范
个人有过C/C++语言学习的经历,当前主要应用的是Python语言,相较于这两者,Scala其变量定义方式与二者都全然不同。比如C/C++中崇尚先定义后使用,所以一般是先声明一个变量并明确指定变量类型,诸如:
int i = 1; // C
其中int 用于声明了具体的变量类型,而Python中则要简洁得多,由于动态类型的特性,所以在创建变量时无需指定变量类型,直接简单粗暴地直接声明变量即可:
i = 1 # Python当然,随着Python的不断发展,变量声明也开始支持明确变量类型,例如:
i:int = 1 # python虽然上述语句中明确了变量i是int类型数据,但实际上其效果与C/C++中全然不同:Python的变量类型声明在变量名之后,仅用于提示使用者该变量的预期类型,且声明是这个类型后续也可能改变(毕竟Python的特性之一是动态类型);而C/C++中的变量类型声明在变量名之前,是一种真正的明确和指定变量类型,且一旦指定则后续不可变更。
在简单对比完了Python和C/C++变量类型定义之后,则可引出本文的主角:Scala变量类型定义。Scala变量类型定义,个人理解来看可以看做是综合了C与Python变量类型二者的特点:既追求变量定义的简洁性(无需具体制定变量类型),又带有一定的类型声明的味道。所以,Scala变量定义由三部分组成:
必须冠以val/var作为关键字开头
随后承接变量名
在变量名之后支持声明或缺省变量类型
例如:
val i = 1 // scala变量类型方式一var j:Int = 1 // scala变量类型方式二
在上述两种变量定义方式中,变量i是一个val类型,未显示指定变量类型,所以交由scala解释器自动推断,此处可推断为Int类型;变量j是一个var类型,显示指定变量类型为Int。值得注意的是Scala中的类型关键字均为大写开头的单词,例如整型写作Int。
变量类型推断是Scala语言的一大特色,在前篇入门介绍文章中也给予解释,后续也将多次提及,此处暂且略过。重点解读val和var的含义:
val:即value,用以表达在程序中无需再次赋值的变量,某种程度上象征着该变量因不可变而更为安全——当然,这话不绝对,后续将随时发现明明是val定义的变量却可以各种“改变”的打脸案例,注意这里的改变是引号下的改变;
var:即variable,真正的变量,可能在程序中多次发生变化或者说再次赋值,所以用变量。
需要指出的是,scala中变量类型要么是val要么是var,且虽然val是不可变类型,但也仍然属于变量——这看似矛盾,实则需要辩证的看待此问题:一方面,变量本身就是一个广义的术语,在这段代码中不可变变量a表示的是一个整数,而在另一段代码中变量a可能表达的却可能是一个字符串,所以当然是变量;另一方面,前面也提及val定义的变量也可能发生改变,例如val定义的一个数组b,虽然由于val的限制b是不可变的数组,数组就还是这个数组,但数组里的每个元素其实可以随时改变,所以其实仍然是一个变量!
那为什么直觉上val会给我们一种"变量不可变"的感觉呢?其实多半是潜意识里将其与常量发生了混淆:常量才是真真正正的不会发生改变,例如圆周率π,它不会因为在这段代码或者那段代码中而存在不同(至少目前来看是确切的常数)。
辩证理解了scala中大费周章的搞出了val/var两类变量声明的含义,那么自然会存在疑惑:这么做的目的是什么呢?这是一个好问题,甚至个人认为某种程度上可以管窥一豹的了解Scala的价值观:
val声明的变量相较var类型而言,更利于内存回收,所以应尽可能使用val类型
val变量跟Scala函数式编程思想一脉相承,即尽量保证函数不带来副作用(包括不改变函数内部的变量本身),而多用输入输出来模块化封装
这一部分围绕Scala中的变量定义做以介绍,虽然有些冗长,但个人觉得深入理解Scala的变量定义价值观还是很有必要的。尤其是理解val/var的哲学理念将伴随Scala整个学习周期……,
前文提到,在Scala变量定义中,支持显示声明或缺省变量类型,当缺省时则交由解释器自动推断。其实这里暗含了一个细节,即与Python中的动态语言特性不同,Scala中的变量是有明确数据类型的!那么,这就自然引出第二个话题,Scala中支持哪些变量类型呢?对此,个人援引Scala变量类型的一张经典图例:
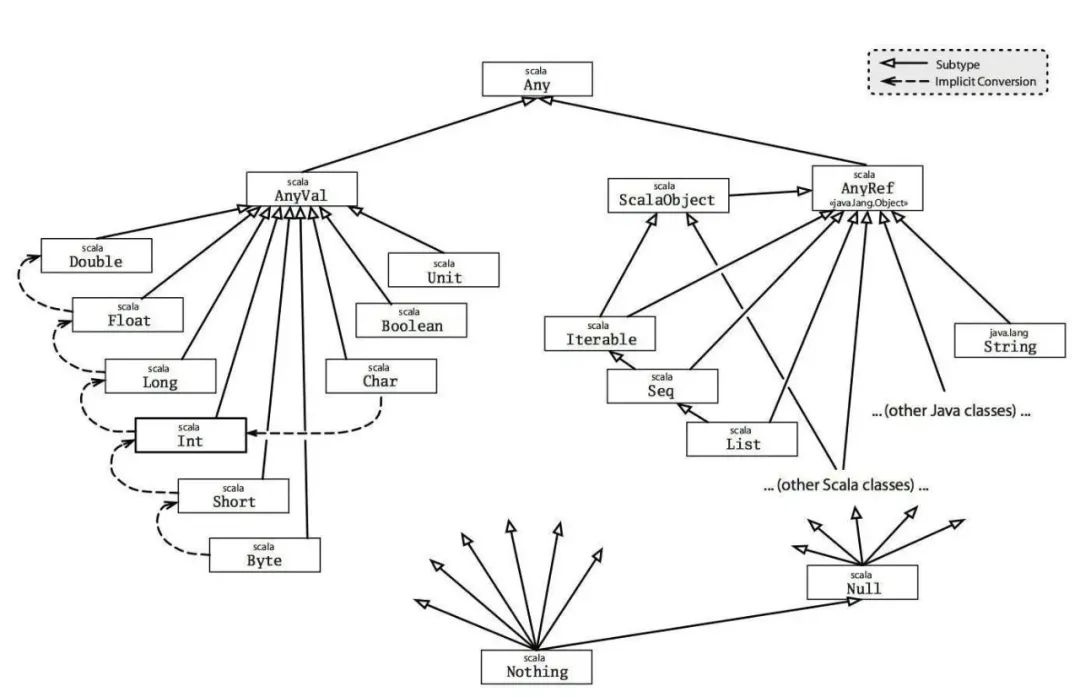
上图中,从上到下(实线箭头的反方向)是父类和子类的关系,即数据类型不断细化;而左右区分来看,左半部分是值类型(value),例如数值型、字符型和布尔型,右半部分是引用类型(reference),例如数组、列表、集合等。两半部分相当于分布源自于一个父类型:AnyVal和AnyRef,而AnyVal和AnyRef则又均源自于共同的父类Any类型。
除了实箭头之外,还标识了一些虚线箭头,这是表达了允许隐式转换的数据类型,当然这里的隐式转换肯定是以不丢失精度为前提——丢失精度的转换肯定是强制转换!例如,Byte是单字节整数,由8bit组成,自然能表达的数值区间要小于Short类型(16bit),依此类推。
还需注意的一个类型是Char类型。如果熟悉Python的话,那么肯定知道Char(单字符)和String(多字符,即字符串)其实都是属于字符串的一种,而且表达方式也都通用(Python中支持单引号、双引号、三单引号、三双引号四种表达Char和String的方式),而在Scala中二者则截然不同:String类型是一个字符串,用双引号表示,即便双引号之内仅有单个字符时也是一个String类型;而Char类型仅能是单个字符,用单引号表示,例如一个Char变量c='C'除了字面量表示一个字母之外,其实还隐式的对应整数67(大写字母C的ascii值),所以下面的语句也就不例外:
// Scalascala> val c = 'C'val c: Char = Cscala> c + 1val res1: Int = 68scala> val d = "C"val d: String = Cscala> d + 1 # 这里是将数值1隐式转换为了字符串"1",而后完成字符串拼接val res2: String = C1
最后,值得补充的是,Scala中所有类型的顶级父类(超类)是Any,而所有类型的子类是Nothing。不针对二者的具体含义展开过多理解,单论二者命名本身还是很具象的:能容纳所有数据类型的类型不就是Any吗?而所有类型的公共交集,则自然是Nothing,因为不存在一种数据既是字符串、又是数值,同时还是布尔类型等等。
相较于Python中的变量蛇形命名,个人更喜欢驼峰命名的紧凑
除了变量命名的书写规范,变量命名的组成也与其他语言存在一定不同,例如其他编程语言一般是要求字母、数字和下划线组成(不能由数字开头),而Scala则要相对更加开放,主要遵循以下几条原则:
首字符为字母,后续字符任意字母和数字,美元符号,可后接下划线_
数字不可以开头。
首字符为操作符(比如+ - * / ),后续字符也需跟操作符 ,至少一个
操作符(比如+-*/)不能在标识符中间和最后.
用反引号`....`包括的任意字符串,即使是关键字(39个)也可以 [true]
简单画下重点:scala中除了字母、数字和下划线之外,操作符和美元符也可利用;系统关键字也可以通过加反引号``来用作变量标识符。
例如:
scala> val * = 3 // 操作符当做变量名val *: Int = 3scala> * * * // 试着接收一下,这几个*都是什么意思val res3: Int = 9scala> val `Int` = 2 // 系统关键字加反引号后当做变量名val Int: Int = 2scala> `Int`val res5: Int = 2
不过,一个好的变量命名对于自己和他人阅读代码都是至关重要的,既然英文单词那么广泛(汉语拼音也提供了无限可能……),谁会无聊到用可能会产生解释报错和理解歧义的美元符、操作符乃至系统关键字来命名变量呢?
相关阅读:
以上是关于Scala从零起步:变量和标识符的主要内容,如果未能解决你的问题,请参考以下文章
linux打开终端如何启动scala,如何在终端下运行Scala代码片段?