Spark全方位性能调优-- 参数调优与应用调优 Posted 2021-04-03 勾叔谈大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark全方位性能调优-- 参数调优与应用调优相关的知识,希望对你有一定的参考价值。
大家好,我是勾叔。今天继续和大家聊聊Spark全方位性能调优 -- 参数调优与应用调优。
在作业并行程度不高的情况下,最有效的方式就是提高作业并行程度。改变并行程度只有一个办法,就是提高同时运行 Executor 的个数。
通常集群的资源总量是一定的, Executor 数量增加,必然会导致单个 Executor 所分得的资源减少,在每个分区不变的情况下,有可能引起性能方面的问题。所以,我们可以增大分区数来降低每个分区的大小,从而避免这个问题。
RDD 一开始的分区数与该份数据在 HDFS 上的数据块数量一致,后面我们可以通过 coalesce 与 repartition 算子进行重分区,这其实改变的是 Map 端的分区数。有两个办法:
修改配置 spark.default.parallelism。该配置设定所有 Reduce 端的分区数,会对所有 Shuffle 过程生效。
直接在算子中将分区数作为参数传入,绝大多数算子都有分区数参数的重载版本,如 groupByKey(600) 等。在 Shuffle 过程中,Shuffle 相关的算子会构建一个哈希表,Reduce 任务有时会因为这个表过大而造成内存溢出,这时就可以试着增大并行程度。
Shuffle 是 Spark 作业中关键的一环,也是性能调优的重点。先来看 Spark 中与 Shuffle 性能有关的参数:
spark.shuffle.file.buffer spark.reducer.maxSizeInFlight spark.shuffle.compress
在 Shuffle Read 的过程中,Reduce Task 所在的 Executor 会按照 spark.reducer.maxSizeInFlight 的设置大小去拉取文件,这需要创建内存缓冲区来接收。在内存足够大的情况下,可以考虑提高 spark.reducer.maxSizeInFlight 的值来提升 Shuffle Read 的效率。spark.shuffle.compress 配置项默认为 true,表示会对 Map 端输出进行压缩。
Spark Shuffle 会将中间结果写入到 spark.local.dir 配置的目录下,将该目录配置多路磁盘目录,以提升写入性能。
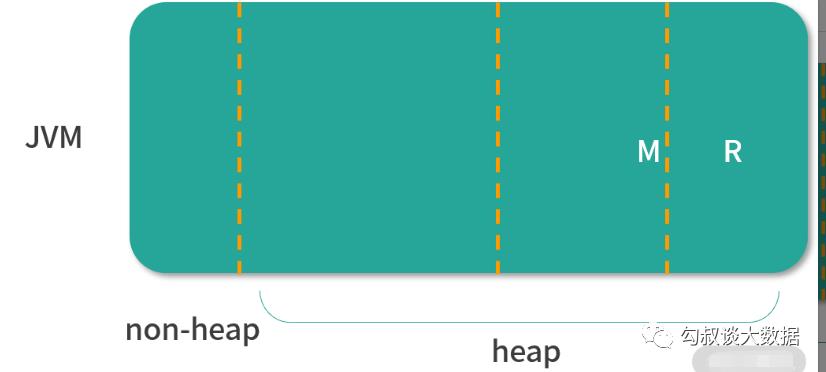
Spark 作业中内存主要有两个用途:计算和存储。
用计算内存时,存储部分可获取所有可用内存,反之亦然。
此设计是为了对不使用缓存的作业尽可能使用全部内存;而需使用缓存的作业会有一个区域始终用来缓存数据。这样用户就可以不需知道背后复杂原理根据实际内存需求来调节 M 与 R 的值,以达到最好效果。下面是决定 M 与 R 的两个配置:
上面两个默认值基本满足绝大多数作业使用。特殊情况可考虑设置 spark.memory.fraction 的值以适配 JVM 老年代的空间大小。默认 JVM 老年代在不经过设置的情况下占 JVM 的 2/3。
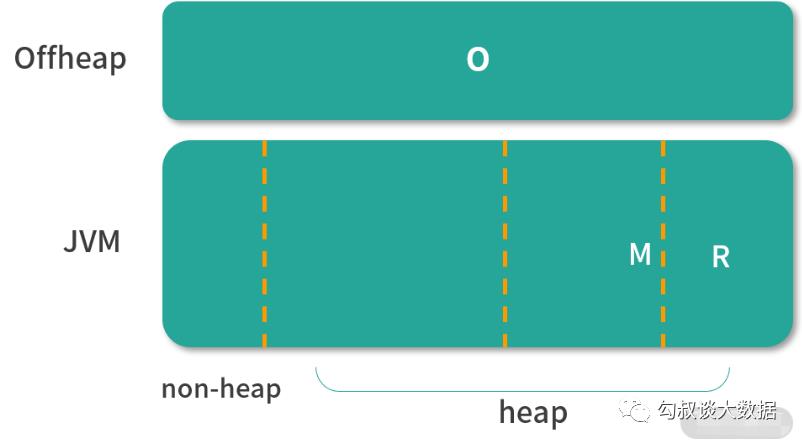
Spark Executor 除了堆内存以外,还有非堆内存空间。这部分通过参数spark.yarn.executor.memoryoverhead 进行配置,最小为 384MB,默认为 Executor 内存的 10%。所以整个Executor JVM 消耗的内存为:
spark .yarn .executor .memoryoverhead + spark .executor .memory
M = spark.executor.memory * spark.memory.fraction R = M * spark.memory.storageFraction
O = spark.memory.offHeap.size
用户需要知道每个部分的大小应如何调节,针对场景进行调优。
序列化是以时间换空间的一种内存取舍方式。根本原因是内存比较吃紧,优先选择对象数组或者基本类型而不是那些集合类型来实现自己的数据结构。fastutil 包提供了与 Java 标准兼容的集合类型。除此之外,还应该避免使用大量小对象与指针嵌套的结构。
可以使用数据 ID 或枚举对象来代替字符串键。如果内存小于 32GB,可以设置 Java 选项 -XX:+UseCompressedOops 来压缩指针为 4 字节,以上是需要用到序列化之前可以做的调优工作,以节省内存。
对于大对象来说,可以使用 RDD 的 persist 算子并选取 MEMORY_ONLY_SER 级别进行存储,更好的方式则是以序列化的方式进行存储。
要想使用 Kyro 序列化库,要将需要序列化的类在 Kyro 中注册方可使用。使用步骤如下:
public static class YourKryoRegistrator implements KryoRegistrator { public void registerClasses(Kryo kryo) { ////在Kryo序列化库中注册自定义的类 kryo.register(YourClass.class, new FieldSerializer(kryo, YourClass.class)); } }
…… spark.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer") spark.config("spark.kryo.registrator", YourKryoRegistrator.class.getName())
通常只读取RDD 一次,而后对其进行各种操作的作业不太会引起 GC 问题。当 Java 需要将老对象释放,为新对象腾出空间时,需要追踪所有 Java 对象,然后在其中找出没有使用的那些对象。
GC 的成本与 Java 对象数量成正比,使用较少对象的数据结构会大大减轻 GC 压力。如直接使用整型数组,而不选用链表。通常在出现 GC 问题时,序列化缓存是首先应该尝试的方法。
由于执行计算任务需要的内存和缓存 RDD 的内存互相干扰,GC 也可能成为问题。这可以控制分配给 RDD 缓存空间来缓解这个问题。
GC 调优的第 1 步是搞清楚 GC 的频率和花费的时间,这可以通过添加 Java 选项来完成:
-verbose :gc -XX :+PrintGCDetails -XX :+PrintGCTimeStamps
在 Spark 运行时,一旦发生 GC,就会被记录到日志里。
为了进一步调优 JVM,先来看看 JVM 如何管理内存。Java 的堆空间被划分为 2 个区域:年轻代、老年代,顾名思义,年轻代会保存一些短生命周期对象,而老年代会保存长生命周期对象。年轻代又被划分为 3 个区域:一个 Eden 区,两个 Supervisor 区,如下图所示。简单来说,GC 过程是这样的:当 Eden 区被填满后,会触发 minor GC,然后 Eden 区和 Supvisor1 区还存活的对象被复制到 Supervisor2 区,如果某个对象太老或者 Supervisor2 区已满,则会将对象复制到老年代中,当老年代快满了,则会触发 full GC。
在 Spark 中,GC 调优的目的是确保只有长生命周期的对象才会保存到老年代中,年轻代有充足的空间来存储短生命周期对象。这会有助于避免执行 full GC 来回收任务执行期间生成的临时对象。
如果某份数据经常会被使用,可以尝试用 cache 算子将其缓存,有时效果极好。
在进行连接操作时,可以尝试将小表通过广播变量进行广播,从而避免 Shuffle,这种方式也被称为 Map 端连接。
在使用 filter 算子后,通常数据会被打碎成很多个小分区,这会影响后面的执行操作,可以先对后面的数据用 coalesce 算子进行一次合并。
很多算子都能达到相同的效果,但是性能差异却比较大,例如在聚合操作时,选择 reduceByKey 无疑比 groupByKey 更好;在 map 函数初始化性能消耗太大或者单条记录很大时,mapPartition 算子比 map 算子表现更好;在去重时,distinct 算子比 groupBy 算子表现更好。
数据倾斜是数据处理作业中的一个非常常见也是非常难以处理的一个问题。正常情况下,数据通常都会出现数据倾斜的问题,只是情况轻重有别而已。数据倾斜的症状是大量数据集中到一个或者几个任务里,导致这几个任务会严重拖慢整个作业的执行速度,严重时甚至会导致整个作业执行失败。可以采取以下几种办法处理:
很多情况下,数据倾斜通常是由脏数据引起的,这个时候需要将脏数据过滤。
这种方式只尽可能地将数据分散到多个任务中去,提升作业的执行速度,但不能解决数据倾斜的问题。
可以将小表进行广播,避免了 Shuffle 的过程。这就使计算相对均匀地分布在每个 Map 任务中,但对数据倾斜严重的情况,还会出现作业执行缓慢的情况。
在连接操作时,可先从大表中将集中分布的连接键找出来,与小表单独处理,再与剩余数据连接的结果做合并。这种方式可以将倾斜的数据打散,从而避免数据倾斜。
对于分组统计的任务,可通过两阶段聚合的方案来解决:
大家如果想进行更深入的了解和学习,请关注 勾叔谈大数据参与更多互动。
以上是关于Spark全方位性能调优-- 参数调优与应用调优的主要内容,如果未能解决你的问题,请参考以下文章
Spark性能优化--数据倾斜调优与shuffle调优
Spark学习笔记6:Spark调优与调试
Spark性能调优——扩展篇
spark性能调优指南——高级篇
原创 Hadoop&Spark 动手实践 8Spark 应用经验调优与动手实践
Spark性能优化指南——高级篇