Posted NewBeeNLP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了相关的知识,希望对你有一定的参考价值。
NewBeeNLP鍘熷垱鍑哄搧
鎮犻棽浼?nbsp;路 淇℃伅妫€绱?/p>
涓婃鎴戜滑鐪嬩簡銆庢帹鑽愮郴缁?+ GNN銆?nbsp;
浠婂ぉ鏉ョ湅鐪?span>銆庢帹鑽愮郴缁?+ 鐭ヨ瘑鍥捐氨銆?/strong>锛屽張浼氭湁鍝簺鏈夎叮鐨勭帺鎰忓効鍛?nbsp;馃摦
Knowledge Graph
鐭ヨ瘑鍥捐氨鏄竴绉嶈涔夊浘锛屽叾缁撶偣锛坣ode锛変唬琛ㄥ疄浣擄紙entity锛夋垨鑰呮蹇碉紙concept锛夛紝杈癸紙edge锛変唬琛ㄥ疄浣?姒傚康涔嬮棿鐨勫悇绉嶈涔夊叧绯伙紙relation锛夈€備竴涓煡璇嗗浘璋辩敱鑻ュ共涓笁鍏冪粍锛坔銆乺銆乼锛夌粍鎴愶紝鍏朵腑h鍜宼浠h〃涓€鏉″叧绯荤殑澶寸粨鐐瑰拰灏捐妭鐐癸紝r浠h〃鍏崇郴銆?/p>
寮曞叆鐭ヨ瘑鍥捐氨杩涘叆鎺ㄨ崘绯荤粺棰嗗煙鐨勪紭鐐瑰湪浜庯細
-
銆岀簿纭€э紙precision锛夈€?/strong>锛氫负鐗╁搧item寮曞叆浜嗘洿澶氱殑璇箟鍏崇郴锛屽彲浠ユ繁灞傛鍦板彂鐜扮敤鎴峰叴瓒? -
銆屽鏍锋€э紙diversity锛夈€?/strong>锛氭彁渚涗簡涓嶅悓鐨勫叧绯昏繛鎺ョ绫伙紝鏈夊埄浜庢帹鑽愮粨鏋滅殑鍙戞暎锛岄伩鍏嶆帹鑽愮粨鏋滃眬闄愪簬鍗曚竴绫诲瀷 -
銆屽彲瑙i噴鎬э紙explainability锛夈€?/strong>锛氳繛鎺ョ敤鎴风殑鍘嗗彶璁板綍鍜屾帹鑽愮粨鏋滐紝浠庤€屾彁楂樼敤鎴峰鎺ㄨ崘缁撴灉鐨勬弧鎰忓害鍜屾帴鍙楀害锛屽寮虹敤鎴峰鎺ㄨ崘绯荤粺鐨勪俊浠汇€?
浣嗘槸鐭ヨ瘑鍥捐氨闅句互涓庣缁忕綉缁滅洿鎺ョ粨鍚堬紝鎵€浠ュ紩鍑轰簡銆宬nowledge representation learning銆?/strong>锛岄€氳繃瀛︿範entity鍜宺elation鐨別mbedding涔嬪悗锛屽啀宓屽叆鍒扮缁忕綉缁滀腑銆俥mbedding鏂规硶涓昏鍙互鍒嗕负銆宼ranslational distance銆?/strong>鏂规硶鍜?span>銆宻emantic matching銆?/strong>鏂规硶涓ょ锛屽墠鑰呮槸瀛︿範浠庡ご瀹炰綋鍒板熬瀹炰綋鐨勭┖闂村叧绯诲彉鎹紙濡俆ransE绛夌郴鍒楋級锛屽悗鑰呭垯鏄洿鎺ョ敤绁炵粡缃戠粶瀵硅涔夌浉浼煎害杩涜璁$畻銆?/p>
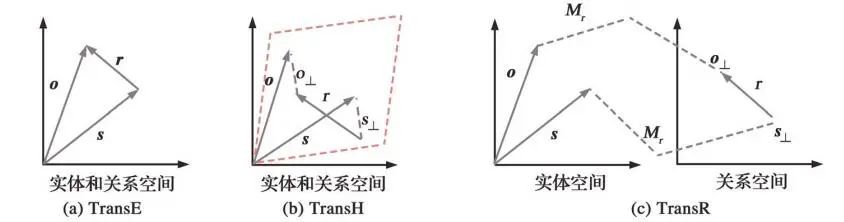
灏嗗叾缁撳悎鍒版帹鑽愰噷闈㈡瘮杈冨洶闅剧殑鍦版柟浠嶇劧鏈夛細 鍦ㄤ粙缁嶈鏂囦箣鍓嶏紝鍏堢畝瑕佺湅鐪嬩竴鑸涔犵煡璇嗗浘璋辩殑鏂规硶锛屼竴鑸湁鍑犵濡備笅鐨勫鐞嗘柟寮忥細 銆孴ransE銆?/strong>锛屽嵆浣垮叾婊¤冻 h + r 鈮?t锛屽熬瀹炰綋鏄ご瀹炰綋閫氳繃鍏崇郴骞崇Щ(缈昏瘧)寰楀埌鐨勶紝浣嗗畠涓嶉€傚悎澶氬涓€鍜屽瀵瑰锛屾墍浠ュ鑷碩ransE鍦ㄥ鏉傚叧绯讳笂鐨勮〃鐜板樊銆傚叕寮忓涓?/p>
銆孴ransH妯″瀷銆?/strong>锛屽嵆灏嗗疄浣撴姇褰卞埌鐢卞叧绯绘瀯鎴愮殑瓒呭钩闈笂銆傚€煎緱娉ㄦ剰鐨勬槸瀹冩槸闈炲绉版槧灏?/p>
銆孴ransR妯″瀷銆?/strong>锛岃妯″瀷鍒欒涓哄疄浣撳拰鍏崇郴瀛樺湪璇箟宸紓锛屽畠浠簲璇ュ湪涓嶅悓鐨勮涔夌┖闂淬€傛澶栵紝涓嶅悓鐨勫叧绯诲簲璇ユ瀯鎴愪笉鍚岀殑璇箟绌洪棿锛屽洜姝ransR閫氳繃鍏崇郴鎶曞奖鐭╅樀锛屽皢瀹炰綋绌洪棿杞崲鍒扮浉搴旂殑鍏崇郴绌洪棿銆?/p>
銆孴ransD妯″瀷銆?/strong>锛岃妯″瀷璁や负澶村熬瀹炰綋鐨勫睘鎬ч€氬父鏈夋瘮杈冨ぇ鐨勫樊寮傦紝鍥犳瀹冧滑搴旇鎷ユ湁涓嶅悓鐨勫叧绯绘姇褰辩煩闃点€傛澶栬繕鑰冭檻鐭╅樀杩愮畻姣旇緝鑰楁椂锛孴ransD灏嗙煩闃典箻娉曟敼鎴愪簡鍚戦噺涔樻硶锛屼粠鑰屾彁鍗囦簡杩愮畻閫熷害銆?/p>
銆孨TN妯″瀷銆?/strong>锛屽皢姣忎竴涓疄浣撶敤鍏跺疄浣撳悕绉扮殑璇嶅悜閲忓钩鍧囧€兼潵琛ㄧず锛屽彲浠ュ叡浜浉浼煎疄浣撳悕绉颁腑鐨勬枃鏈俊鎭€?/p>
鎺ヤ笅鏉ヤ富瑕佹暣鐞?绡囪鏂囷紝CKE鍜孯ippleNet銆?/p>
鍙戣嚜16骞碖DD锛屽皢KG涓嶤F铻嶅悎鍋氳仈鍚堣缁冦€?img data-ratio="0.5303571428571429" src="/img?url=https://mmbiz.qpic.cn/mmbiz_jpg/DHibuUfpZvQfUor9UJIChhTZNVWOpiclZz0Mj8Q3RVBPNQ6EHJbKVkDM9ibaaBrlsYf1IZO8uWZ0Va8JXa2MKIJwQ/640?wx_fmt=jpeg" data-type="jpeg" data-w="1120" _width="368px" class="mq-65" alt="娣卞害铻嶅悎 | 褰撴帹鑽愮郴缁熼亣瑙佺煡璇嗗浘璋?>棣栧厛涓轰簡浣跨敤鐭ヨ瘑搴擄紝浣滆€呰璁′簡涓変釜缁勪欢鍒嗗埆浠庣粨鏋勫寲鐭ヨ瘑锛屾枃鏈煡璇嗗拰瑙嗚鐭ヨ瘑涓彁鍙栬涔夌壒寰侊紝濡備笂鍥句腑鐨勫彸鍗婇儴鍒嗭紝鐭ヨ瘑搴撶殑澶勭悊鍒嗗埆涓猴細 鐭ヨ瘑搴撲腑鐨勫疄浣撲互鍙婂疄浣撶殑鑱旂郴銆備娇鐢═ransR鎻愬彇鐗╁搧鐨勭粨鏋勫寲淇℃伅锛堝悓鏃惰€冭檻nodes鍜宺elations锛夛紝瀹冪殑缁撴瀯濡備笅鍥撅紝瀵逛簬姣忎釜鍏冪粍锛坔锛宺锛宼锛夛紝棣栧厛灏嗗疄浣撶┖闂翠腑鐨勫疄浣撳悜鍏崇郴r鎶曞奖寰楀埌
鍜?span class="mq-74">
瀵瑰疄浣撶殑鏂囧瓧鎬ф弿杩般€傜敤澶氬眰闄嶅櫔鑷紪鐮佸櫒鎻愬彇鏂囨湰琛ㄨ揪锛圫DAE锛夛紝鍥句腑鍐欑殑鏄疊ayesian SDAE锛屾剰鎬濆氨鏄鏉冮噸锛屽亸缃紝杈撳嚭灞傜鍚堢壒瀹氱殑姝f€佸垎甯冿紝瀵硅瑙夌殑澶勭悊涔熸槸涓€鏍风殑銆?/p>
瀵瑰疄浣撶殑鍥剧墖鎻忚堪濡傛捣鎶ョ瓑銆傜敤澶氬眰鍗风Н鑷紪鐮佹彁鍙栫墿鍝佽瑙夎〃杈撅紙SCAE锛?/p>
鏈€鍚庡緱鍒扮殑item鐨勮〃绀轰负offset鍚戦噺浠ュ強缁撴瀯鍖栫煡璇嗭紝鏂囨湰鐭ヨ瘑锛屽浘鐗囩煡璇嗙殑鍚戦噺锛?/p>
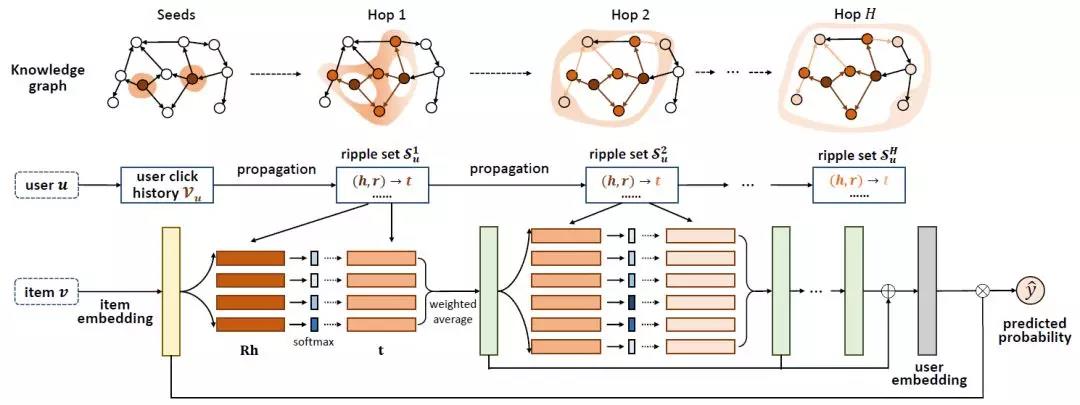
鍚戞潵涓嶅悓鎶€鏈箣闂村鏋滆兘铻嶅悎鐨勬洿娣卞叆锛岃嚜鐒舵槸鑳藉緱鍒版洿濂界殑淇℃伅銆俁ipple Network妯℃嫙浜嗙敤鎴峰叴瓒e湪鐭ヨ瘑鍥捐氨涓婄殑浼犳挱杩囩▼锛屾暣涓繃绋嬬被浼间簬姘存尝鐨勪紶鎾紝濡備笂鍥句粠瀹炰綋Forrest Gump寮€濮嬩竴璺砲op1锛屼簩璺砲op2鍋氫紶鎾紝鍚屾椂鏉冮噸閫掑噺銆?img data-ratio="0.5915300546448088" src="/img?url=https://mmbiz.qpic.cn/mmbiz_png/DHibuUfpZvQfUor9UJIChhTZNVWOpiclZza3ib4zMx0ICwBH4mtRtnGctEMiaA99eNjz7xR7jht4ZGS6oWTSexvagA/640?wx_fmt=png" data-type="png" data-w="732" _width="368px" class="mq-127" alt="娣卞害铻嶅悎 | 褰撴帹鑽愮郴缁熼亣瑙佺煡璇嗗浘璋?>妯″瀷鍥惧涓嬪浘锛屽浜庣粰瀹氱殑鐢ㄦ埛u鍜岀墿鍝乿锛屽浣曟ā鎷熺敤鎴峰叴瓒e湪KG涓婄殑浼犳挱鍛紵 v鏄墿鍝佸悜閲忥紝r鏄叧绯伙紝h鏄ご鑺傜偣锛屼笁鑰呰绠楃浉浼煎害锛堝緱鍒颁簡鍥剧墖涓璕h鍚庨潰鐨勭豢鑹叉柟鏍硷級銆傜劧鍚庣敤杩欎釜鏉冮噸瀵硅瀹炰綋涓殑灏捐妭鐐箃鍔犳潈灏卞緱鍒颁簡绗竴璺?鎵╂暎鐨勭粨鏋滐細 鎵€鏈夎烦鏈€鍚庣殑鐢ㄦ埛鐗瑰緛涓烘墍鏈夎烦鐨勬€诲拰锛岄渶瑕佹敞鎰忕殑鏄紝Ripple Network涓病鏈夊鐢ㄦ埛鐩存帴浣跨敤鍚戦噺杩涜鍒荤敾锛岃€屾槸鐢ㄧ敤鎴风偣鍑昏繃鐨勭墿鍝佺殑鍚戦噺闆嗗悎浣滀负鍏剁壒寰侊紙浠g爜涓篃鍙互鍙娇鐢ㄦ渶鍚庣殑o锛夛細 瀹為檯涓婃眰鍜屽緱鍒扮殑缁撴灉鍙互瑙嗕负v鍦╱鐨勪竴璺崇浉鍏冲疄浣撲腑鐨勪竴涓搷搴斻€傝杩囩▼鍙互閲嶅鍦╱鐨勪簩璺炽€佷笁璺崇浉鍏冲疄浣撲腑杩涜锛屽姝わ紝v鍦ㄧ煡璇嗗浘璋变笂渚夸互V涓轰腑蹇冮€愬眰鍚戝鎵╂暎銆傛渶鍚庡啀鐢ㄧ敤鎴风壒寰佽绠楀鐗╁搧鐨勭浉浼煎害寰楀埌棰勬祴缁撴灉锛?/p>
鐒跺悗鏉ョ湅涓€涓嬫ā鍨嬬被鐨勪唬鐮侊細杩欓儴鍒嗙殑浠g爜鍒嗕负锛氭暟鎹甶nput锛屽緱鍒板祵鍏ョ壒寰侊紝渚濇璁$畻姣忎竴璺崇殑缁撴灉骞舵洿鏂帮紙鎸夌収鍏紡渚濇璁$畻锛夛紝棰勬祴銆傛渶鍚庢槸鎹熷け鍑芥暟锛堢敱涓夐儴鍒嗙粍鎴愶級鍜岃缁冦€佹祴璇曞嚱鏁般€?/p>
瀹屾暣鐨勯€愯涓枃娉ㄩ噴绗旇鍦細https://github.com/nakaizura/Source-Code-Notebook/tree/master/RippleNet 鍗氫富鍦ㄨ鏂囩珷鐨勬椂鍊欙紝濮嬬粓涓嶆槑鐧藉璺虫槸鎬庝箞瀹炵幇鐨勶紝涓嬮潰鎴戜滑鐪嬬湅浠g爜鏄€庝箞鍐欙細 鍗冲垱閫犱簡涓€涓猺ipple_set锛岃繖涓猻et鐩稿綋浜庡氨寰楀埌鏁翠釜澶氳烦搴旇璁块棶鍒扮殑鑺傜偣锛屽湪姣忎竴璺抽噷闈㈤兘浼氫负姣忎釜鐢ㄦ埛閲囨牱鍥哄畾澶у皬鐨勯偦灞咃紝鐒跺悗瀛樺鍒皊et涓€傛墍浠ュ湪model妯″瀷鐨勯儴鍒嗭紝鍙互鐩存帴閬嶅巻澶氳烦璁$畻銆?/p>
鎯冲拰浣犱竴璧峰涔犺繘姝ワ紒鎴戜滑鏂板缓绔嬩簡銆庢帹鑽愮郴缁熴€佺煡璇嗗浘璋便€佸浘绁炵粡缃戠粶銆忕瓑 涓撻璁ㄨ缁勶紝娆㈣繋鎰熷叴瓒g殑鍚屽鍔犲叆涓€璧蜂氦娴併€備负闃叉灏忓箍鍛婇€犳垚淇℃伅楠氭壈锛岄夯鐑︽坊鍔犳垜鐨勫井淇★紝鎵嬪姩閭€璇蜂綘锛堥夯鐑﹀娉ㄥ枖锛?/span> - END - 以上是关于的主要内容,如果未能解决你的问题,请参考以下文章
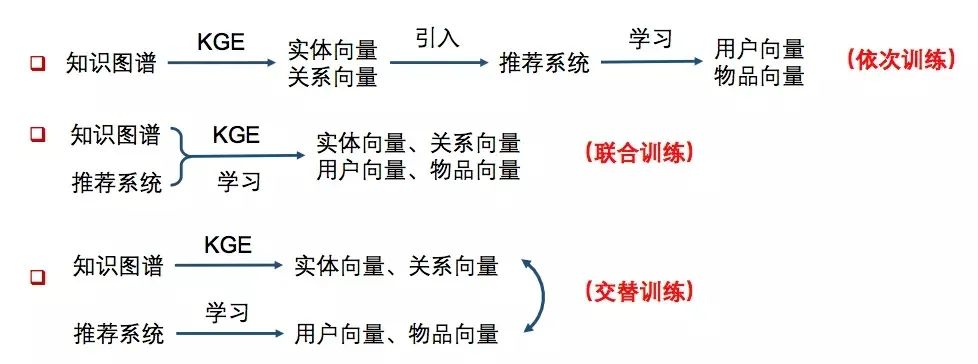 涓€鑸娇鐢ㄧ煡璇嗗浘璋辨湁涓夌妯″紡锛屽涓婂浘锛?/p>
涓€鑸娇鐢ㄧ煡璇嗗浘璋辨湁涓夌妯″紡锛屽涓婂浘锛?/p>
CKE
缁撴瀯鍖栫煡璇?/span>
鏂囨湰鐭ヨ瘑
瑙嗚鐭ヨ瘑
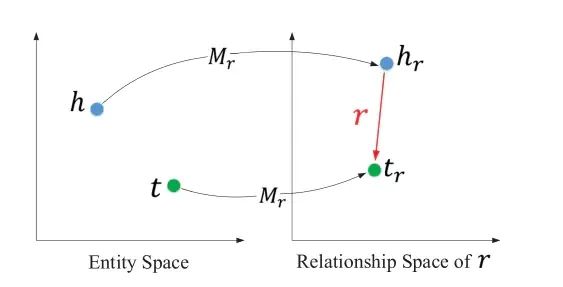
#TransR
def projection_transR_pytorch(original, proj_matrix):
ent_embedding_size = original.shape[1]
rel_embedding_size = proj_matrix.shape[1] // ent_embedding_size
original = original.view(-1, ent_embedding_size, 1)
#鍊熷姪涓€涓姇褰辩煩闃靛氨琛?/span>
proj_matrix = proj_matrix.view(-1, rel_embedding_size, ent_embedding_size)
return torch.matmul(proj_matrix, original).view(-1, rel_embedding_size)RippleNet
class RippleNet(object):
def __init__(self, args, n_entity, n_relation):
self._parse_args(args, n_entity, n_relation)
self._build_inputs()
self._build_embeddings()
self._build_model()
self._build_loss()
self._build_train()
def _parse_args(self, args, n_entity, n_relation):
self.n_entity = n_entity
self.n_relation = n_relation
self.dim = args.dim
self.n_hop = args.n_hop
self.kge_weight = args.kge_weight
self.l2_weight = args.l2_weight
self.lr = args.lr
self.n_memory = args.n_memory
self.item_update_mode = args.item_update_mode
self.using_all_hops = args.using_all_hops
def _build_inputs(self):
#杈撳叆鏈塱tems id锛宭abels鍜岀敤鎴锋瘡涓€璺崇殑ripple set璁板綍
self.items = tf.placeholder(dtype=tf.int32, shape=[None], name="items")
self.labels = tf.placeholder(dtype=tf.float64, shape=[None], name="labels")
self.memories_h = []
self.memories_r = []
self.memories_t = []
for hop in range(self.n_hop):#姣忎竴璺崇殑缁撴灉
self.memories_h.append(
tf.placeholder(dtype=tf.int32, shape=[None, self.n_memory], name="memories_h_" + str(hop)))
self.memories_r.append(
tf.placeholder(dtype=tf.int32, shape=[None, self.n_memory], name="memories_r_" + str(hop)))
self.memories_t.append(
tf.placeholder(dtype=tf.int32, shape=[None, self.n_memory], name="memories_t_" + str(hop)))
def _build_embeddings(self):#寰楀埌宓屽叆
self.entity_emb_matrix = tf.get_variable(name="entity_emb_matrix", dtype=tf.float64,
shape=[self.n_entity, self.dim],
initializer=tf.contrib.layers.xavier_initializer())
#relation杩炴帴head鍜宼ail鎵€浠ョ淮搴︽槸self.dim*self.dim
self.relation_emb_matrix = tf.get_variable(name="relation_emb_matrix", dtype=tf.float64,
shape=[self.n_relation, self.dim, self.dim],
initializer=tf.contrib.layers.xavier_initializer())
def _build_model(self):
# transformation matrix for updating item embeddings at the end of each hop
# 鏇存柊item宓屽叆鐨勮浆鎹㈢煩闃碉紝杩欎釜涓嶄竴瀹氭槸蹇呰鐨勶紝鍙互浣跨敤鐩存帴鏇挎崲鎴栬€呭姞鍜岀瓥鐣ャ€?/span>
self.transform_matrix = tf.get_variable(name="transform_matrix", shape=[self.dim, self.dim], dtype=tf.float64,
initializer=tf.contrib.layers.xavier_initializer())
# [batch size, dim]锛屽緱鍒癷tem鐨勫祵鍏?/span>
self.item_embeddings = tf.nn.embedding_lookup(self.entity_emb_matrix, self.items)
self.h_emb_list = []
self.r_emb_list = []
self.t_emb_list = []
for i in range(self.n_hop):#寰楀埌姣忎竴璺崇殑瀹炰綋锛屽叧绯诲祵鍏ist
# [batch size, n_memory, dim]
self.h_emb_list.append(tf.nn.embedding_lookup(self.entity_emb_matrix, self.memories_h[i]))
# [batch size, n_memory, dim, dim]
self.r_emb_list.append(tf.nn.embedding_lookup(self.relation_emb_matrix, self.memories_r[i]))
# [batch size, n_memory, dim]
self.t_emb_list.append(tf.nn.embedding_lookup(self.entity_emb_matrix, self.memories_t[i]))
#鎸夊叕寮忚绠楁瘡涓€璺崇殑缁撴灉
o_list = self._key_addressing()
#寰楀埌鍒嗘暟
self.scores = tf.squeeze(self.predict(self.item_embeddings, o_list))
self.scores_normalized = tf.sigmoid(self.scores)
def _key_addressing(self):#寰楀埌olist
o_list = []
for hop in range(self.n_hop):#渚濇璁$畻姣忎竴璺?/span>
# [batch_size, n_memory, dim, 1]
h_expanded = tf.expand_dims(self.h_emb_list[hop], axis=3)
# [batch_size, n_memory, dim]锛岃绠桼h锛屼娇鐢╩atmul鍑芥暟
Rh = tf.squeeze(tf.matmul(self.r_emb_list[hop], h_expanded), axis=3)
# [batch_size, dim, 1]
v = tf.expand_dims(self.item_embeddings, axis=2)
# [batch_size, n_memory]锛岀劧鍚庡拰v鍐呯Н璁$畻鐩镐技搴?/span>
probs = tf.squeeze(tf.matmul(Rh, v), axis=2)
# [batch_size, n_memory]锛宻oftmax杈撳嚭鍒嗘暟
probs_normalized = tf.nn.softmax(probs)
# [batch_size, n_memory, 1]
probs_expanded = tf.expand_dims(probs_normalized, axis=2)
# [batch_size, dim]锛岀劧鍚庡垎閰嶅垎鏁扮粰灏捐妭鐐瑰緱鍒皁
o = tf.reduce_sum(self.t_emb_list[hop] * probs_expanded, axis=1)
#鏇存柊Embedding琛紝骞朵笖瀛樺ソo
self.item_embeddings = self.update_item_embedding(self.item_embeddings, o)
o_list.append(o)
return o_list
def update_item_embedding(self, item_embeddings, o):
#璁$畻瀹宧op涔嬪悗锛屾洿鏂癷tem鐨凟mbedding鎿嶄綔锛屽彲浠ユ湁澶氱绛栫暐
if self.item_update_mode == "replace":#鐩存帴鎹?/span>
item_embeddings = o
elif self.item_update_mode == "plus":#鍔犲埌涓€璧?/span>
item_embeddings = item_embeddings + o
elif self.item_update_mode == "replace_transform":#鐢ㄥ墠闈㈢殑杞崲鐭╅樀
item_embeddings = tf.matmul(o, self.transform_matrix)
elif self.item_update_mode == "plus_transform":#鐢ㄧ煩闃佃€屼笖鍐嶅姞鍒颁竴璧?/span>
item_embeddings = tf.matmul(item_embeddings + o, self.transform_matrix)
else:
raise Exception("Unknown item updating mode: " + self.item_update_mode)
return item_embeddings
def predict(self, item_embeddings, o_list):
y = o_list[-1]#1鍙敤olist鐨勬渶鍚庝竴涓悜閲?/span>
if self.using_all_hops:#2鎴栬€呬娇鐢ㄦ墍鏈夊悜閲忕殑鐩稿姞鏉ヤ唬琛╱ser
for i in range(self.n_hop - 1):
y += o_list[i]
# [batch_size]锛寀ser鍜宨tem绠楀唴绉緱鍒伴娴嬪€?/span>
scores = tf.reduce_sum(item_embeddings * y, axis=1)
return scores
def _build_loss(self):#鎹熷け鍑芥暟鏈変笁閮ㄥ垎
#1鐢ㄤ簬鎺ㄨ崘鐨勫鏁版崯澶卞嚱鏁?/span>
self.base_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=self.labels, logits=self.scores))
#2鐭ヨ瘑鍥捐氨琛ㄧず鐨勬崯澶卞嚱鏁?/span>
self.kge_loss = 0
for hop in range(self.n_hop):
h_expanded = tf.expand_dims(self.h_emb_list[hop], axis=2)
t_expanded = tf.expand_dims(self.t_emb_list[hop], axis=3)
hRt = tf.squeeze(tf.matmul(tf.matmul(h_expanded, self.r_emb_list[hop]), t_expanded))
self.kge_loss += tf.reduce_mean(tf.sigmoid(hRt))#涓篽Rt鐨勮〃绀烘槸鍚﹀緱褰?/span>
self.kge_loss = -self.kge_weight * self.kge_loss
#3姝e垯鍖栨崯澶?/span>
self.l2_loss = 0
for hop in range(self.n_hop):
self.l2_loss += tf.reduce_mean(tf.reduce_sum(self.h_emb_list[hop] * self.h_emb_list[hop]))
self.l2_loss += tf.reduce_mean(tf.reduce_sum(self.t_emb_list[hop] * self.t_emb_list[hop]))
self.l2_loss += tf.reduce_mean(tf.reduce_sum(self.r_emb_list[hop] * self.r_emb_list[hop]))
if self.item_update_mode == "replace nonlinear" or self.item_update_mode == "plus nonlinear":
self.l2_loss += tf.nn.l2_loss(self.transform_matrix)
self.l2_loss = self.l2_weight * self.l2_loss
self.loss = self.base_loss + self.kge_loss + self.l2_loss #涓夎€呯浉鍔?/span>
def _build_train(self):#浣跨敤adam浼樺寲
self.optimizer = tf.train.AdamOptimizer(self.lr).minimize(self.loss)
'''
optimizer = tf.train.AdamOptimizer(self.lr)
gradients, variables = zip(*optimizer.compute_gradients(self.loss))
gradients = [None if gradient is None else tf.clip_by_norm(gradient, clip_norm=5)
for gradient in gradients]
self.optimizer = optimizer.apply_gradients(zip(gradients, variables))
'''
def train(self, sess, feed_dict):#寮€濮嬭缁?/span>
return sess.run([self.optimizer, self.loss], feed_dict)
def eval(self, sess, feed_dict):#寮€濮嬫祴璇?/span>
labels, scores = sess.run([self.labels, self.scores_normalized], feed_dict)
#璁$畻auc鍜宎cc
auc = roc_auc_score(y_true=labels, y_score=scores)
predictions = [1 if i >= 0.5 else 0 for i in scores]
acc = np.mean(np.equal(predictions, labels))
return auc, acc鍏充簬澶氳烦鐨勫疄鐜?/span>
#ripple澶氳烦鏃讹紝姣忚烦鐨勭粨鏋滈泦
def get_ripple_set(args, kg, user_history_dict):
print('constructing ripple set ...')
# user -> [(hop_0_heads, hop_0_relations, hop_0_tails), (hop_1_heads, hop_1_relations, hop_1_tails), ...]
ripple_set = collections.defaultdict(list)
for user in user_history_dict:#瀵逛簬姣忎釜鐢ㄦ埛
for h in range(args.n_hop):#璇ョ敤鎴风殑鍏磋叮鍦↘G澶氳烦hop涓?/span>
memories_h = []
memories_r = []
memories_t = []
if h == 0:#濡傛灉涓嶄紶鎾紝涓婁竴璺崇殑缁撴灉灏辩洿鎺ユ槸璇ョ敤鎴风殑鍘嗗彶璁板綍
tails_of_last_hop = user_history_dict[user]
else:#鍘婚櫎涓婁竴璺崇殑璁板綍
tails_of_last_hop = ripple_set[user][-1][2]
#鍘婚櫎涓婁竴璺崇殑涓夊厓缁勭壒寰?/span>
for entity in tails_of_last_hop:
for tail_and_relation in kg[entity]:
memories_h.append(entity)
memories_r.append(tail_and_relation[1])
memories_t.append(tail_and_relation[0])
# if the current ripple set of the given user is empty, we simply copy the ripple set of the last hop here
# this won't happen for h = 0, because only the items that appear in the KG have been selected
# this only happens on 154 users in Book-Crossing dataset (since both BX dataset and the KG are sparse)
if len(memories_h) == 0:
ripple_set[user].append(ripple_set[user][-1])
else:
#涓烘瘡涓敤鎴烽噰鏍峰浐瀹氬ぇ灏忕殑閭诲眳
replace = len(memories_h) < args.n_memory
indices = np.random.choice(len(memories_h), size=args.n_memory, replace=replace)
memories_h = [memories_h[i] for i in indices]
memories_r = [memories_r[i] for i in indices]
memories_t = [memories_t[i] for i in indices]
ripple_set[user].append((memories_h, memories_r, memories_t))
return ripple_set涓€璧蜂氦娴?/span>

