ECMWF已经开展的机器学习算法应用情况(Observations)
Posted 阿宗的科研备忘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ECMWF已经开展的机器学习算法应用情况(Observations)相关的知识,希望对你有一定的参考价值。

先来看看欧洲中心目前已经在开展或者在计划中的机器学习算法图:
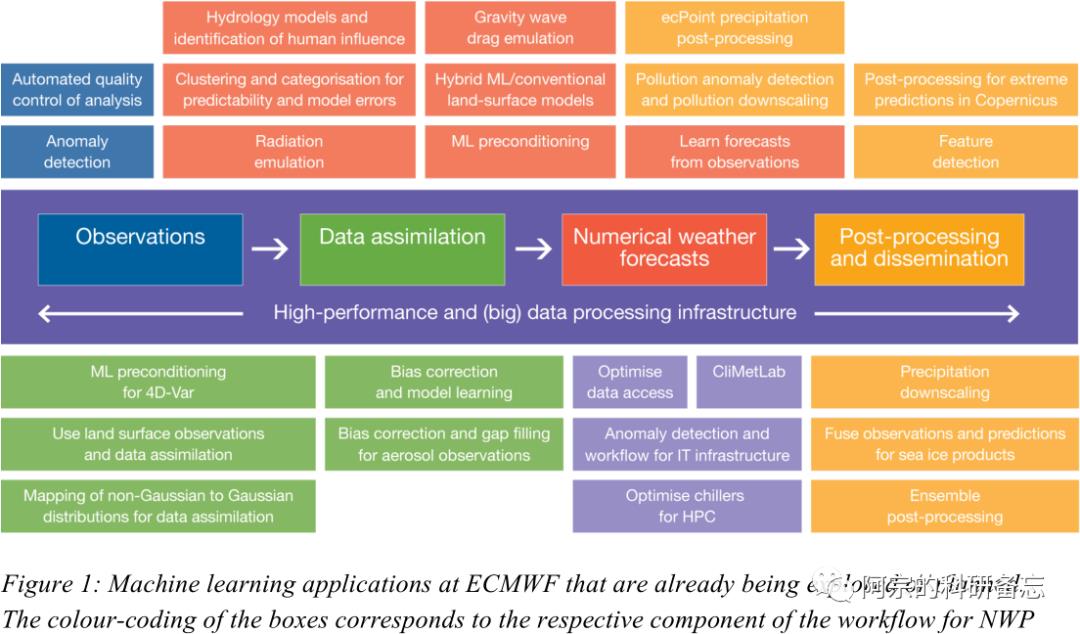
以温度为例,我们以南京本站测试过,在不引入其他任何气象条件,单纯以小时温度的时间序列,利用循环神经网络RNN进行建模,在没有明显寒潮过程或者晴雨天气切换的前提下,RNN模型预报得出的小时温度基本都是正确的(与实况偏差2℃以内)。也就是说,如果错误的温度值发生在一个与前几日天气现象没有明显变化的情况下,完全可以将周边测站的观测值和RNN预测值相结合,进行联合修正。
突然想起来我们还做过一次3小时能见度预报试验,当时引入了大量的预报因子,包括前期地面及高空气象要素实况,前期环境监测站观测大气污染物浓度,模式预报的各种气象要素和环境产品,结果无论是随机森林还是Adaboost的因子重要性排序,排第一的都是前一天的3小时能见度。。。
所以其实也用不着这么复杂的网络,就按照前一天的情况调整一下当日的分布是不是就可以了
系统偏差的矫正,一般常见于变换观测手段或者观测仪器,又或者是迁站的情况。比如说,2014年中国气象局推进自动化改革,能见度的人工观测逐渐为自动化能见度仪所取代。通过人工同步观测与能见度仪观测的长时间对比,就可以得出自动观测与人工观测的系统偏差。
针对自动观测与人工观测的能见度,目前国内外都是使用比较简单的1:0.75倍换算。而事实上,它们并不是简单的线性关系。如果要深入分析本地自动观测与人工观测的偏差,则使用深度学习算法,比如卷积神经网络,又或者是比较方便快捷的随机森林、Adaboost等算法对二者进行建模,挖掘它们之间更加深入的关系,这样也更具科学性。
除了气象要素的观测资料之外,针对多通道卫星云图、雷达回波的质控则困难很多,而且对于短临预报也更具指导意义。对于雷达基数据的质量控制,重点在于抑制地物杂波、距离去折叠和速度退模糊。这方面我们国内已经有了比较成熟的技术,虽然有时会残留地物杂波,又或者需要人工去折叠、退模糊的情况,但是基本不影响预报员的使用。
但是,如果要将雷达回波引入人工智能模型,那么尽量完全地去除杂波,就显得尤为重要。比如要用光流法来外推雷达回波,总不能连着地物杂波一起推走啊。。我们曾经参加过的解放军总装备部“天智杯”人工智能挑战赛,他们给出的训练集就是一整年的卫星云图、雷达回波和自动站降水资料,而整个预报区域囊括了华东和华南,地形杂波、海浪和云雨杂波的存在,对于雷达回波外推之后反演降水,带来了较大的误差。这里就需要利用卫星云图和降水,通过卷积神经网络,学习杂波的特征,对雷达回波进行联合质控,去除各种光有反射率但不下雨的杂波。
Anomaly detection: 异常检验。
还有些特征则涉及到了一些统计学上的分布特征,比如气温的概率分布是大概符合高斯分布的,某地某个季节不同降水量的频率分布一般都不会跟历史平均差太多,风速基本符合韦伯(Weibull)分布。
现在我们会用机器学习算法通过对长时间观测数据的学习,来得到观测数据的特征。用机器学习算法来归纳特征,其主要目的就在于探索出我们现有的知识体系内没有发现的规律,因此我们通常会选用无监督学习的方法,通过快速迭代不同的算法来进行不停地试错,得出数据的特征。不过这些特征就更难以用数字或者是函数来表达了。想到前阵子有个同学,非追着我问模型到底是个什么东西,它到底是个长什么样的方程?于是我截了一段长长的图给她,大概就长这样:(这是我最近做的一个图像识别的残差网络,这里没截全,有那个意思就行。。)
不管这些特征是怎么来的,只要它是经过长期检验的,是大概合理的就行。因为利用机器学习进行异常检验,最重要的就是特征的选取了。然后将近期的观测数据按照特征的要求进行计算,最终与特征比对,看是否符合。如果不符合的话,就报高异常,提示需要修正啦~
以上是关于ECMWF已经开展的机器学习算法应用情况(Observations)的主要内容,如果未能解决你的问题,请参考以下文章