机器学习被过度炒作?分析全球 1400 家数据公司有了这些发现
Posted CSDN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习被过度炒作?分析全球 1400 家数据公司有了这些发现相关的知识,希望对你有一定的参考价值。
【CSDN 编者按】在数据迅速膨胀及不断增多的如今,数据领域成为了新兴的 热门行业,而这个领域行情如何?在数据专家的众多岗位中,数据科学家和数据工程师谁更吃香?
原文链接:https://www.mihaileric.com/posts/we-need-data-engineers-not-data-scientists/
本文已获得原作者授权,CSDN 翻译,转载请注明出处。
作者 | Mihail Eric,机器学习科学家@亚马逊Alexa AI。斯坦福大学计算机科学硕士,曾担任斯坦福大学自然语言处理(NLP)研究助理。
数据,无处不在,且在不断增加。在过去 5~10 年间,数据科学吸引了越来越多的新人,人们纷纷前来品尝这一禁果。
然而,如今的数据科学招聘市场的行情究竟如何呢?
为了各位忙碌的读者能迅速掌握本文的要旨,我们通过如下两句话来概括全文:
在各家公司公开招聘的数据科学职位中,70% 面向的是数据工程师。在培训下一代数据与机器学习从业人员时,我们更加注重工程技能。
在从事面向数据专业人员的教育平台的开发工作期间,我思考了很多有关数据驱动(机器学习与数据科学)职位的市场的发展情况。
我曾与数十名数据领域新晋的佼佼者交谈过,其中不乏全球顶尖机构的学生,但我发现很多人未能真正理解哪些才是最重要的技术,他们并不清楚哪些技术能够帮助自己从人群中脱颖而出,并为自己的职业生涯做好准备。

众所周知,数据科学家主要负责以下各项工作:机器学习建模、可视化、数据的清理和处理(与 SQL 打交道)、工程以及生产部署。
但你给新手推荐的学习课程都有哪些?
数据胜于雄辩。因此,我决定分析一下 2012 年以来 Y-Combinator 发布的各家公司数据相关工作岗位的招聘信息。我研究的主要问题包括:
与数据相关的最常见的招聘岗位都有哪些?
我们讨论的数据科学家的市场需求有多大?
数据革命之初使用的技术是否至今仍然很流行?
如果你想了解完整的细节与分析经过,请继续阅读下面的内容。

方法论
我选择的分析对象是 Y-Combinator 孵化的一些公司,即声称要将某些数据工作作为其价值主张的一部分的公司。
为什么只分析 Y-Combinator 的公司?因为他们提供的公司名录(https://www.ycombinator.com/companies/)非常易于搜索(而且可以爬取)。
另外,作为一个颇有远见的孵化器,十余年以来他们为来自全球各个领域的公司提供了大量资金,我认为他们提供的市场样本非常具有代表性,可供我分析。话虽如此,你应该对我所说的内容持保留态度,因为毕竟我没有分析大型科技公司。
我抓取了 2012 年以来每家 Y-Combinator 公司的首页 URL,拿到手的用于分析的公司大约有 1400 家。
为什么没有考虑 2012 年以前的数据?因为正是在这一年,AlexNet 赢得了 ImageNet 大赛,并掀起了机器学习与数据建模的热浪,且这股热浪一直延续至今。可以说,这个事件催生了最早的一批从事数据工作的公司。
以这批公司为基础,我利用关键字进行了过滤,减少了需要处理的公司数量。具体来说,我只考虑了主页至少包含下列词语之一的公司:AI、CV、NLP、natural language processing(自然语言处理)、computer vision(计算机视觉)、artificial intelligence(人工智能)、machine(机器)、ML、data(数据)。另外,我忽略了那些网站链接无效的公司。
这一步处理会产生大量的假阳性(即包含上述词语但实际上不从事数据工作的公司)吗?肯定会!但是,我希望尽可能提高召回率,因为我知道我可以手动检查各个网站的相关职位。
在过滤掉一些公司之后,我遍历了每个网站,找到了他们的招聘广告(通常在求职、工作或招聘页面中),并记录下了每个头衔中包含data(数据)、machine learning(机器学习)、NLP 或 CV 的职位。最后,我得到了大约 70 个正在招聘数据相关职位的公司。
注意:我有可能漏掉了一些公司,因为有些网站上的招聘信息非常少。此外,有些公司没有正式的招聘页面,他们希望求职人员直接通过电子邮件与他们联系。
我忽略了上述两种公司,所以他们不属于此次分析的一部分。
另外:这项研究的大部分工作是在 2020 年底完成的。随着各个公司主页的定期更新,公开招聘的职位可能已发生变化。但是,我认为这不会严重影响最后的结论。

数据从业者的职责
在深入研究结果之前,我们先花点时间来澄清每个数据岗位常见的职责有哪些。我们将重点介绍以下四个职位,并简要说明他们的工作内容:
数据科学家:使用各种统计与机器学习的技术来处理和分析数据。通常负责构建模型,调查可以从数据源中学习到哪些内容,尽管大多数模型都是原型,而非生产级别。
数据工程师:开发一套健壮且可扩展的数据处理工具/平台。必须熟悉 SQL/NoSQL 数据库,以及构建/维护 ETL 流水线。
机器学习(ML)工程师:通常需要同时负责模型的训练与生产化。需要熟悉一些高级 ML 框架,此外还需要掌握构建可扩展的训练技术,以及模型的推理与部署流水线。
机器学习(ML)科学家:主要从事最尖端的研究。一般负责探索可以在学术会议上发布的新观点。通常只需要将最新的模型制作成原型,然后移交给 ML 工程师,将其投入生产。

与数据相关的职位有多少?
如果我们将各个公司正在招聘的数据相关职位的频率绘制成图表,结果会怎样?这个图表大致如下:
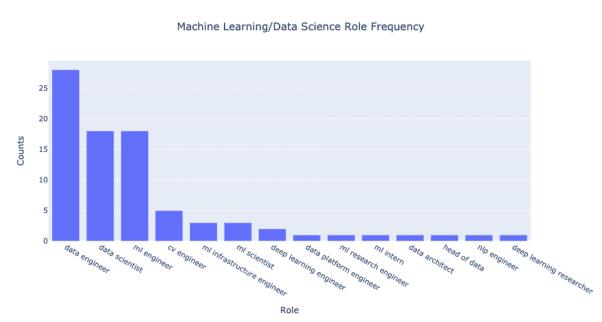
最惹人注目的莫过于,数据工程师的招聘岗位远远多于传统的数据科学家。在我们这个例子中,招聘数据工程师的公司的绝对数量要比招聘数据科学家的公司多大约 55%,而招聘机器学习工程师的公司数量与招聘数据科学家的公司大致相同。
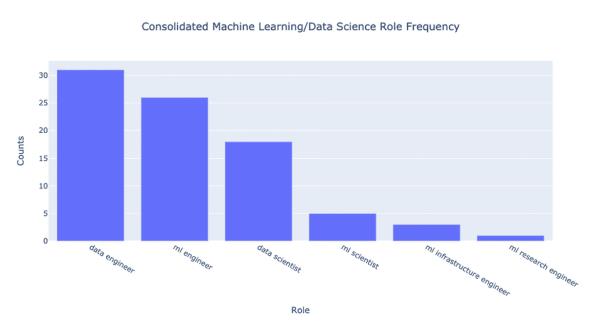
我们可以做进一步的分析。看一看各个职位的头衔,似乎有很多重复。
我们可以通过合并职位来粗略地分类。也就是说,找出描述大致相同的职位,然后将其合并到一个头衔下。
这一步使用了以下等价关系:
NLP engineer ≈ CV engineer ≈ ML engineer ≈ Deep Learning engineer(NLP 工程师 ≈ CV 工程师 ≈ ML 工程师 ≈ 深度学习工程师。虽然领域可能不同,但职责大致相同)。
ML scientist ≈ Deep Learning researcher ≈ ML intern(ML 科学家 ≈ 深度学习研究员 ≈ ML 实习岗位。其中 ML 实习岗位的描述非常注重研究)。
Data engineer ≈ Data architect ≈ Head of data ≈ Data platform engineer(数据工程师 ≈ 数据架构 ≈ 数据总监 ≈ 数据平台工程师)。
如果你不喜欢绝对数量的话,那么可以看一看下面的百分比:
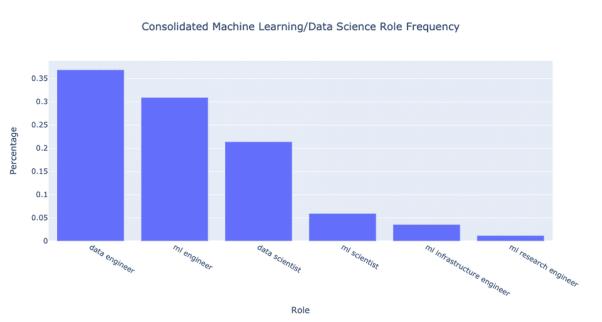
我可以将 ML research engineer(MLL 研究工程师)归到 ML scientist(ML 科学家)或 ML engineer(ML 工程师)一栏,但是鉴于这是一个混合职位,所以我将其保留了下来。
总的来看,合并后的差异性更加显著!开放的数据工程师职位比数据科学家多 70%;ML 工程师的职位也比数据科学家职位多 40%;此外,机器学习科学家的数量只有数据科学家的 30%。

重点总结
与其他数据专业人士相比,数据工程师的需求越来越高。从某种意义上说,这代表了更广阔领域的发展。
大约在 5~8 年前机器学习刚刚兴起的时候,各个公司都需要从事数据分类的工作人员。然而,随着 Tensorflow 和 PyTorch 等框架的出现,深度学习和机器学习的技术开始走向大众化。
这导致数据建模技能的需求增加。
如今,各个公司通过机器学习和建模洞悉产品的瓶颈集中在了数据的问题上。
如何标注数据?如何处理和清理数据?如何将数据从 A 移动到 B?如何快速完成这些日常工作?
所有这些工作都需要良好的工程技术。
虽然这些工作听起来很无聊,而且很没趣,但是侧重于数据的传统软件工程可能才是我们目前真正需要的。
多年以来,我们一直很迷恋数据专家的工作,他们通过出色的演示和媒体炒作为原始数据注入了生命力。想想看,你最后一次在科技网站上看到有关ETL流水线的文章,是多久以前的事?
我认为,在数据科学的培训与教育项目中,没有什么比数据工程得到的重视更少了。除了学习如何使用 linear_regression.fit() 之外,我们也应该学习如何编写单元测试!
那么,是否意味着你不应该学习数据科学?其实不然。
这只是意味着竞争会越来越激烈。市场上数据科学的职位会越来越少,不足以为所有新手提供这样的机会。
但是,能够有效分析数据,并从中提取可行见解的需求依然存在。只不过,这些人的技术必须过关。
只会从 Tensorflow 网站下载经过 Iris 数据集预训练的模型,不足以胜任数据科学的工作。
然而,很明显,市场上有大量的机器学习工程师职位,各个公司都需要混合型的数据人才:既能够构建模型,也能够部署模型。或者更直接地说,不仅能够使用 Tensorflow,而且还能够利用源代码构建模型的人。
另外有一点需要注意,机器学习研究的职位也不是很多。
机器学习研究也被大肆宣传,因为最尖端的技术都诞生于此,包括 AlphaGo、GPT-3 以及其他等等。
但是,对于许多公司来说,尤其是处于创业初期的公司,最尖端的新技术可能不是必需的。对于他们来说,把一个九成完美的模型扩展到上千名用户可能更有价值。
我并不是说机器学习研究并不重要。绝对没有这个意思。
但是,这类的职位可能大多出现在该行业的研究实验室内,因为这些机构有能力承担长时间的大量投资,而不像处于种子阶段的创业公司,在 A 轮融资中就需要向投资者证明,他们的产品非常适合市场。
我认为,让新手对数据领域建立合理且正确的期望,这一点无比重要。我们必须知道如今的数据科学已大不相同。我希望你能够通过这篇文章,对该领域的当前状况有所了解。只有了解自己身处何地,才能知道朝着何方前进。
THE END

更多精彩推荐
“分享、点赞、在看”
以上是关于机器学习被过度炒作?分析全球 1400 家数据公司有了这些发现的主要内容,如果未能解决你的问题,请参考以下文章
区块链产业月报丨中国区块链企业已达1400家,专利申请数量全球领先!