Spark——算子之间的区别
Posted Java学习基地Java毕设定制
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark——算子之间的区别相关的知识,希望对你有一定的参考价值。
coalesce与repartition的区别
1)关系:
两者都是用来改变 RDD 的 partition 数量的,repartition 底层调用的就是 coalesce 方法:coalesce(numPartitions, shuffle = true)
2)区别:
repartition 一定会发生 shuffle,coalesce 根据传入的参数来判断是否发生 shuffle
一般情况下增大 rdd 的 partition 数量使用 repartition,减少 partition 数量时使用coalesce
sortBy 和 sortByKey的区别
sortBy既可以作用于RDD[K] ,还可以作用于RDD[(k,v)]
sortByKey 只能作用于 RDD[K,V] 类型上。
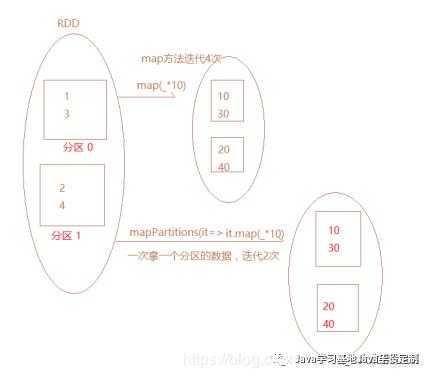
map和mapPartitions的区别
数据存入Redis 优先使用map mapPartitions foreach foreachPartions哪个
使用 foreachPartition
1,map mapPartition 是转换类的算子, 有返回值
2, 写mysql,redis 的连接
foreach * 100万 100万次的连接
foreachPartions * 200 个分区 200次连接 一个分区中的数据,共用一 个连接
foreachParititon 每次迭代一个分区,foreach每次迭代一个元素。
该方法没有返回值,或者Unit
主要作用于,没有返回值类型的操作(打印结果,写入到mysql数据库中)
在写入到redis,mysql的时候,优先使用foreachPartititon
reduceByKey和groupBykey的区别
val words = Array("one", "two", "two", "three", "three", "three")val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))val wordCountsWithReduce = wordPairsRDD.reduceByKey(_ + _)val wordCountsWithGroup = wordPairsRDD.groupByKey().map(t => (t._1, t._2.sum))
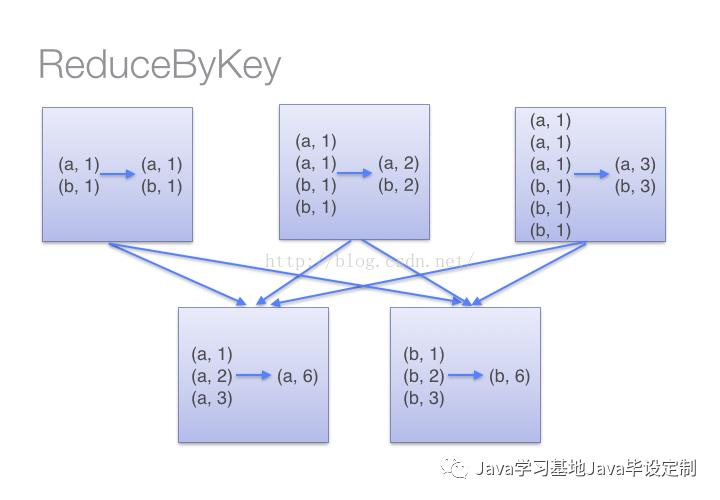
当采用reduceByKeyt时,Spark可以在每个分区移动数据之前将待输出数据与一个共用的key结合。借助下图可以理解在reduceByKey里究竟发生了什么。注意在数据对被搬移前同一机器上同样的key是怎样被组合的(reduceByKey中的lamdba函数)。然后lamdba函数在每个区上被再次调用来将所有值reduce成一个最终结果。整个过程如下:
当采用groupByKey时,由于它不接收函数,spark只能先将所有的键值对(key-value pair)都移动,这样的后果是集群节点之间的开销很大,导致传输延时。整个过程如下:
以上是关于Spark——算子之间的区别的主要内容,如果未能解决你的问题,请参考以下文章